







एमेजॉन कैसे स्क्रैप करें: 2026 का गाइड नैतिक डेटा निष्कर्षण & कैप्चा समाधान

Emma Foster
Machine Learning Engineer
10-Apr-2026

TL;Dr:
- 2026 में अमेज़न डेटा एक्सट्रैक्ट करना जटिल एंटी-बॉट मेकैनिज़म के खिलाफ उन्नत तकनीकों की आवश्यकता होती है।
- नैतिक डेटा एक्सट्रैक्शन अभ्यास, जैसे
robots.txtका सम्मान करना और मांग दर का प्रबंधन, महत्वपूर्ण हैं। - अन्यता बनाए रखने और आईपी ब्लॉकिंग से बचने के लिए प्रॉक्सी और रोटेटिंग यूजर-एजेंट आवश्यक हैं।
- कैप्चा चुनौतियां, विशेष रूप से AWS WAF, आम होती हैं और CapSolver जैसी विशेषज्ञ सेवाओं के साथ उन्हें प्रभावी ढंग से हल किया जा सकता है।
- वातावरण सेटअप, API एम्बेडिंग, मांग प्रबंधन और डेटा प्रसंस्करण के लिए एक चरण-दर-चरण दृष्टिकोण डेटा निकालने के लिए सफलता सुनिश्चित करता है।
- समानांतरता और वितरित डेटा एक्सट्रैक्शन के माध्यम से प्रदर्शन अनुकूलन दक्षता में महत्वपूर्ण वृद्धि कर सकता है।
परिचय
ई-कॉमर्स के गतिशील वातावरण में, अमेज़न से डेटा एक्सट्रैक्ट करना व्यापार और अनुसंधानकर्ता के लिए एक महत्वपूर्ण कार्य रहा है। प्रतिस्पर्धी विश्लेषण, मूल्य निगरानी, उत्पाद अनुसंधान या बाजार प्रवृत्ति की पहचान के लिए, अमेज़न डेटा एक्सट्रैक्शन अमूल्य दृष्टिकोण प्रदान करता है। हालांकि, वेब स्क्रैपिंग तकनीकों के विकास के साथ, अमेज़न जैसे प्रमुख प्लेटफॉर्म द्वारा उपयोग किए जाने वाले एंटी-बॉट तकनीक भी विकसित हो गए हैं। यह 2026 का गाइड नैतिक और कुशल अमेज़न डेटा एक्सट्रैक्शन के लिए एक व्यापक, कार्यान्वयन ढांचा प्रदान करता है, जो व्यावहारिक कदम, कोड उदाहरण और सामान्य चुनौतियों के समाधान पर केंद्रित है, जैसे कि व्यापक AWS कैप्चा। WAF ब्लॉक के लिए एक अतिरिक्त दृष्टिकोण के लिए, इस अमेज़न डेटा एक्सट्रैक्शन गाइड के लिए विचार करें। हम आवश्यक उपकरणों, तकनीकों और अच्छे अभ्यासों में गहराई से जांच करेंगे जो आपके डेटा एक्सट्रैक्शन प्रयासों को सफल और टिकाऊ बनाए रखेंगे।
अमेज़न के एंटी-स्क्रैपिंग तकनीकों को समझें
अमेज़न, जैसे कि कई बड़े ऑनलाइन प्लेटफॉर्म, अपने डेटा की रक्षा करने और न्यायसंगत उपयोग सुनिश्चित करने के लिए जटिल एंटी-स्क्रैपिंग तकनीकों के एक सूट का उपयोग करता है। इन युक्तियां ऑटोमेटेड एक्सेस की पहचान और रोकने के लिए डिज़ाइन की गई हैं, जैसे कि आईपी ब्लॉकिंग से लेकर जटिल कैप्चा चुनौतियों तक। इन रक्षात्मक उपायों को समझना एक जटिल और टिकाऊ [वेब स्क्रैपिंग एंटी-डिटेक्शन तकनीक](https://www.capsolver.com/blog/web scraping/web-scraping-anti-detection-techniques) समाधान के निर्माण के पहले कदम है।
सामान्य एंटी-स्क्रैपिंग तकनीक:
- आईपी ब्लॉकिंग और दर सीमा: एक छोटे समय अंतराल में एक ही आईपी पते से बार-बार मांग करने से अस्थायी या स्थायी ब्लॉक हो सकता ह। अमेज़न अपनी मांग आवृत्ति और पैटर्न की निगरानी करता है ताकि ऑटोमेटेड ट्रैफिक की पहचान की जा सके।
- यूजर-एजेंट और हेडर जांच: वेबसाइट आमतौर पर HTTP हेडर, विशेष रूप से
User-Agentस्ट्रिंग की जांच करती है ताकि वास्तविक ब्राउज़र ट्रैफिक की पहचान की जा सके। अनियमित या अनुपलब्ध यूजर-एजेंट चेतावनी दे सकते हैं। - कैप्चा चुनौतियां: कैप्चा (पूर्ण रूप से स्वचालित सार्वजनिक ट्यूरिंग परीक्षा जो कंप्यूटर और मानव के बीच अंतर करती है) मशीन के बजाय मानव उपयोगकर्ता के अंतर को पहचानने के लिए डिज़ाइन किए गए हैं। अमेज़न अक्सर AWS WAF कैप्चा का उपयोग करता है, जिसमें जटिल जावास्क्रिप्ट-आधारित चुनौतियां या चित्र पहचान कार्य होते हैं।
- होनीपॉट और फंसाने की गोदाम: एक चुनौती के रूप में छिपे लिंक या तत्व जो मानव उपयोगकर्ता के लिए अदृश्य होते हैं, लेकिन ऑटोमेटेड स्क्रैपर्स द्वारा निर्देशित किए जा सकते हैं, बॉट की पहचान और ब्लॉक करने के लिए उपयोग किए जा सकते हैं।
- डायनामिक सामग्री लोडिंग: अमेज़न के कई भाग जावास्क्रिप्ट के साथ डायनामिक रूप से लोड होते हैं, जिसके कारण सरल HTTP मांग आधारित स्क्रैपर्स के लिए सभी डेटा तक पहुंचना कठिन हो जाता है।
नैतिक स्क्रैपिंग: अच्छे अभ्यास और पालन करना
किसी भी वेब स्क्रैपिंग प्रयास में नैतिक और कानूनी विचारों को महत्वपूर्ण माना जाता है। इन नियमों का पालन करने से न केवल अनुपालन सुनिश्चित होता है बल्कि आपके स्क्रैपिंग ऑपरेशन के लंबे समय तक विकास के लिए भी योगदान होता है। हमेशा जिम्मेदार डेटा संग्रह को प्राथमिकता दें ताकि कानूनी जिम्मेदारी न हो और डेटा स्रोतों के साथ एक सकारात्मक संबंध बनाए रखा जा सके।
मुख्य नैतिक निर्देशावली:
robots.txtकी समीक्षा करें: हमेशाrobots.txtफ़ाइल (जैसेhttps://www.amazon.com/robots.txt) देखें ताकि आप वेबसाइट के कौन से हिस्से ब्राउज़र के लिए अनुमति नहीं हैं, इसकी पहचान कर सकें। इन निर्देशों का सम्मान करना नैतिक अभ्यास का मूल भाग है।- सेवा की शर्तों का सम्मान करें: अमेज़न की सेवा की शर्तों के साथ परिचित हों। कुछ शर्तें स्क्रैपिंग को रोक सकती हैं, लेकिन उनकी समझ आपके निर्णय लेने में मदद करती है और जोखिम को कम करती है।
- मांग दर की सीमा रखें: मांग के बीच देरी शामिल करें ताकि अमेज़न के सर्वर को अत्यधिक भार न दिया जा सके। इससे आईपी ब्लॉकिंग रोकी जा सकती है और लक्ष्य वेबसाइट पर भार कम हो सकता है। एक सामान्य अभ्यास है 5 से 15 सेकंड के बीच यादृच्छिक देरी शामिल करना।
- अपने आप को पहचानें (जिम्मेदारी से): एक विवरणात्मक
User-Agentस्ट्रिंग का उपयोग करें जो आपकी संपर्क जानकारी शामिल करता है। इससे वेबसाइट प्रबंधक आपसे संपर्क कर सकते हैं अगर उन्हें कोई समस्या होती है, जो पारदर्शिता बनाए रखता है। - केवल सार्वजनिक उपलब्ध डेटा स्क्रैप करें: लॉगिन आवश्यकताओं के बिना उपलब्ध डेटा पर ध्यान केंद्रित करें। निजी या संवेदनशील जानकारी के स्क्रैपिंग से बचें।
2026 में अमेज़न स्क्रैपिंग के लिए चरण-दर-चरण गाइड
इस खंड में आपके स्क्रैपिंग वातावरण की स्थापना, मांग प्रबंधन और डेटा प्रसंस्करण के लिए विस्तृत, कार्यान्वयन गाइड का विवरण दिया गया है, जिसमें कैप्चा हल करने के साथ विशेष ध्यान दिया गया है।
चरण 1: वातावरण की तैयारी
कोड लिखने से पहले, अपने विकास वातावरण की सही तरह से स्थापना सुनिश्चित करें। वेब स्क्रैपिंग के लिए पायथन एक लोकप्रिय विकल्प है क्योंकि इसके पुस्तकालयों के समृद्ध परिवेश हैं।
उद्देश्य: अपने स्क्रैपिंग परियोजना के लिए एक स्थिर और कुशल आधार स्थापित करना।
कार्य:
-
पायथन स्थापित करें: अगर अभी तक स्थापित नहीं है, तो आधिकारिक वेबसाइट से पायथन 3.8+ डाउनलोड और स्थापित करें।
-
एक वर्चुअल वातावरण बनाएं: इससे आपके परियोजना निर्भरताओं की आइसोलेशन होती है।
bashpython3 -m venv amazon_scraper_env source amazon_scraper_env/bin/activate # विंडोज़ पर, `amazon_scraper_env\Scripts\activate` का उपयोग करें -
आवश्यक पुस्तकालय स्थापित करें:
requests: HTTP मांग बनाने के लिए।BeautifulSoup4: HTML सामग्री के पार्सिंग के लिए।lxml: तेज़ HTML पार्सर, आमतौर पर BeautifulSoup के साथ उपयोग किया जाता है।selenium(वैकल्पिक): जब आवश्यकता हो तो डायनामिक सामग्री रेंडरिंग के लिए।webdriver_manager(वैकल्पिक): Selenium के लिए ब्राउज़र ड्राइवर प्रबंधन के लिए।
bashpip install requests beautifulsoup4 lxml # अगर Selenium उपयोग कर रहे हैं: # pip install selenium webdriver_manager
नोट्स: अपने पुस्तकालयों के नियमित अपडेट करें ताकि आपको नवीनतम विशेषताओं और सुरक्षा पैच के लाभ मिल सकें।
चरण 2: प्रारंभिक मांग बनाना और आधुनिक एंटी-स्क्रैपिंग का प्रबंधन करना
आधुनिक एंटी-स्क्रैपिंग के प्रबंधन के साथ आसान मांग शुरू करें, जो यूजर-एजेंट घूमाने और मांग के बीच देरी शामिल करने पर ध्यान केंद्रित करता है ताकि मानव ब्राउज़िंग पैटर्न के समान बनाए रखा जा सके।
उद्देश्य: अमेज़न को मांग भेजना और HTML सामग्री प्राप्त करना, लेकिन तुरंत ब्लॉकिंग के जोखिम को कम करना।
कार्य:
- यूजर-एजेंट घूमाएं: आम ब्राउज़र यूजर-एजेंट की सूची बनाएं और प्रत्येक मांग के साथ घूमाएं। इससे आपका स्क्रैपर अलग-अलग ब्राउज़र के रूप में दिखाई देता है।
- देरी शामिल करें: मांग के बीच यादृच्छिक देरी शामिल करें ताकि दर सीमा को ट्रिगर न किया जा सके।
python
import requests
import time
import random
from bs4 import BeautifulSoup
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 13_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15',
]
def fetch_amazon_page(url):
headers = {'User-Agent': random.choice(user_agents)}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # HTTP त्रुटि के लिए एक अपवाद उठाएं
time.sleep(random.uniform(5, 15)) # यादृच्छिक देरी
return response.text
except requests.exceptions.RequestException as e:
print(f"मांग विफल रही: {e}")
return None
# उदाहरण उपयोग:
# product_page_url = "https://www.amazon.com/dp/B08XYZ123"
# html_content = fetch_amazon_page(product_page_url)
# अगर html_content:
# soup = BeautifulSoup(html_content, 'lxml')
# # soup ऑब्जेक्ट के प्रसंस्करणनोट्स: अधिक जटिल परिस्थितियों के लिए, अमेज़न स्क्रैपिंग के समय आईपी पतों के एक जाल के प्रबंधन के लिए प्रॉक्सी घूमाने सेवा का उपयोग करने के बारे में विचार करें, जो अधिक अनामिकता प्रदान करता है। अधिक जानकारी के लिए, कैप्चा हल करने के लिए प्रॉक्सी एम्बेडिंग के बारे में रुचि रखें। यह बड़े पैमाने पर ऑपरेशन के लिए आवश्यक है।
चरण 3: कैप्चा चुनौतियों का प्रबंधन कैपसॉल्वर के साथ
अमेज़न ऑटोमेटेड मांगों को रोकने के लिए AWS WAF कैप्चा का अक्सर उपयोग करता है। इन चुनौतियों को टोकन-आधारित (वास्तविक ब्राउज़र वातावरण की आवश्यकता होती है) या चित्र वर्गीकरण आधारित हो सकता है। कैपसॉल्वर दोनों प्रकार के लिए मजबूत समाधान प्रदान करता है, जो अमेज़न स्क्रैपिंग के प्रक्रिया में कैप्चा हल करने के लिए बिना बाधा के एकीकरण की अनुमति देता है।
उद्देश्य: AWS WAF कैप्चा चुनौतियों को स्वचालित रूप से हल करें और बिना किसी बाधा के डेटा निकालें।
कार्य:
कैपसॉल्वर द्वारा AWS WAF कैप्चा के लिए दो मुख्य कार्य प्रकार प्रदान किए गए हैं:
AntiAwsWafTask: टोकन-आधारित चुनौतियों के लिए, आमतौर परawsKey,awsIv,awsContextऔरawsChallengeJSजैसे पैरामीटर की आवश्यकता होती है।AwsWafClassification: चित्र वर्गीकरण चुनौतियों के लिए, जहां आप एक चित्र और प्रश्न प्रदान करते हैं।
टोकन-आधारित AWS WAF कैप्चा (पायथन उदाहरण)
इस उदाहरण में कैपसॉल्वर के AntiAwsWafTask प्रकार का उपयोग करके टोकन-आधारित AWS WAF कैप्चा के हल करने के तरीके को दर्शाया गया है। यह अमेज़न द्वारा जावास्क्रिप्ट-आधारित चुनौतियों के साथ उपयोगी होता है।
python
import requests
import time
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY" # अपने वास्तविक कैपसॉल्वर API की चाबी से बदलें
def create_aws_waf_task(website_url, aws_key, aws_iv, aws_context, aws_challenge_js, proxy=None):
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiAwsWafTask", # अगर आप अपने स्वयं के प्रॉक्सी का उपयोग नहीं करना चाहते हैं, तो `AntiAwsWafTaskProxyless` का उपयोग करें
"websiteURL": website_url,
"awsKey": aws_key,
"awsIv": aws_iv,
"awsContext": aws_context,
"awsChallengeJS": aws_challenge_js
}
}
if proxy:
payload["task"]["proxy"] = proxy # अगर प्रदान किया गया है तो प्रॉक्सी जोड़ें
response = requests.post("https://api.capsolver.com/createTask", json=payload)
response.raise_for_status()
return response.json().get("taskId")
def get_task_result(task_id):
payload = {
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
while True:
response = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
response.raise_for_status()
result = response.json()
if result.get("status") == "ready":
return result.get("solution")
elif result.get("status") == "failed":
raise Exception(f"कैपसॉल्वर कार्य विफल रहा: {result.get('errorDescription')}")
time.sleep(3) # प्रत्येक 3 सेकंड पर पूछताछ करें
# उदाहरण उपयोग (अमेज़न चुनौती पृष्ठ से वास्तविक मानों के साथ बदलें):
# website_url = "https://efw47fpad9.execute-api.us-east-1.amazonaws.com/latest"
# aws_key = "अमेज़न पृष्ठ से मान"
# aws_iv = "अमेज़न पृष्ठ से मान"
# aws_context = "अमेज़न पृष्ठ से मान"
# aws_challenge_js = "जावास्क्रिप्ट चुनौती स्क्रिप्ट के लिए पता"
# proxy_string = "http://user:pass@प्रॉक्सी:पोर्ट" # अगर AntiAwsWafTask का उपयोग कर रहे हैं तो वैकल्पिक है
# अनुमति:
# task_id = create_aws_waf_task(website_url, aws_key, aws_iv, aws_context, aws_challenge_js, proxy_string)
# print(f"कैपसॉल्वर टास्क आईडी: {task_id}")
# solution = get_task_result(task_id)
# aws_waf_token = solution.get("cookie")
# print(f"AWS WAF टोकन: {aws_waf_token}")
# # इस टोकन का उपयोग अगले मांग में कुकी के रूप में करें:
# # कुकी = {'aws-waf-token': aws_waf_token}
# # response = requests.get(target_url, headers=headers, cookies=cookies)
# except Exception as e:
# print(f"कैप्चा हल करने में त्रुटि: {e}")नोट्स: कैपसॉल्वर के साथ एकीकरण करते समय, अमेज़न चुनौती पृष्ठ से सभी आवश्यक पैरामीटर (awsKey, awsIv, awsContext, awsChallengeJS) को एकत्र करें। ये आमतौर पर 405 स्थिति कोड लौटाए जाने पर चुनौती पृष्ठ के HTML स्रोत में पाए जा सकते हैं। अधिक विवरण के लिए, कैपसॉल्वर के AWS WAF निर्देशात्मक के बारे में दस्तावेज़ देखें।
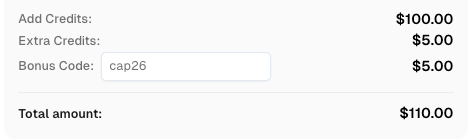
कैपसॉल्वर में पंजीकरण करते समय कोड
CAP26का उपयोग करें ताकि अतिरिक्त क्रेडिट प्राप्त करें!
चित्र वर्गीकरण AWS WAF कैप्चा (पायथन उदाहरण)
चित्र आधारित कैप्चा के लिए, कैपसॉल्वर के AwsWafClassification कार्य प्रकार का उपयोग किया जा सकता है। इसमें चित्र और संबंधित प्रश्न कैपसॉल्वर को भेजे जाते हैं ताकि चित्र की पहचान की जा सके।
python
import requests
import base64
import time
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY" # अपने वास्तविक कैपसॉल्वर API की चाबी से बदलें
def solve_aws_waf_classification(image_path, question):
with open(image_path, "rb") as f:
image_base64 = base64.b64encode(f.read()).decode("utf-8")
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AwsWafClassification",
"image": image_base64,
"question": question
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
response.raise_for_status()
task_id = response.json().get("taskId")
get_payload = {"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
while True:
res = requests.post("https://api.capsolver.com/getTaskResult", json=get_payload)
res.raise_for_status()
data = res.json()
if data.get("status") == "ready":
return data.get("solution")
elif data.get("status") == "failed":
raise Exception(f"कैपसॉल्वर वर्गीकरण कार्य विफल रहा: {data.get('errorDescription')}")
time.sleep(2)
# उदाहरण उपयोग:
# मान लीजिए 'captcha_image.png' डाउनलोड किया गया कैप्चा चित्र फ़ाइल है
# question_text = "एक साइकिल वाले सभी चित्र चुनें" # चित्र के साथ जुड़ा प्रश्न
# अनुमति:
# result = solve_aws_waf_classification("captcha_image.png", question_text)
# print(f"Selected indices: {result}")
# # The result will be a list of indices corresponding to the selected images.
# # You would then use these indices to interact with the Amazon page.
# except Exception as e:
# print(f"Error solving image CAPTCHA: {e}")टिप्पणियाँ: इस विधि के लिए आपको पहले अमेज़न पेज से CAPTCHA छवि और संबंधित प्रश्न को पकड़ना आवश्यक होता है। इसके लिए अक्सर सेलेनियम जैसे हेडलेस ब्राउज़र का उपयोग करके पेज को रेंडर करना और CAPTCHA तत्व के छवि के स्क्रीनशॉट लेना आवश्यक होता है। CapSolver स्क्रीनिंग प्रक्रिया को सरल बनाता है, जिससे अमेज़न स्क्रैपिंग अधिक विश्वसनीय हो जाती है।
चरण 4: डेटा निकालना और प्रसंस्करण
जब आप सफलतापूर्वक HTML सामग्री प्राप्त कर लेते हैं, तो अगला चरण इसे पार्स करना और आवश्यक डेटा निकालना होता है। BeautifulSoup इस उद्देश्य के लिए एक उत्कृष्ट प per है।
उद्देश्य: HTML संरचना से विशिष्ट डेटा बिंदुओं को संस्कृत करना।
संचालन:
- HTML संरचना की जांच करें: ब्राउज़र डेवलपर टूल्स का उपयोग करके अमेज़न पेज की HTML संरचना की जांच करें और आपके लिए आवश्यक डेटा (उदाहरण के लिए, उत्पाद का नाम, मूल्य, समीक्षाएं) के लिए CSS सेलेक्टर या XPath अभिव्यक्तियां पहचानें।
- BeautifulSoup के साथ पार्स करें: HTML सामग्री को एक BeautifulSoup ऑब्जेक्ट में लोड करें और इसकी विधियों (find, find_all, select) का उपयोग डेटा निकालने के लिए करें।
python
# ... (पिछला कोड HTML सामग्री बाहर निकालने के लिए)
def parse_amazon_product_page(html_content):
soup = BeautifulSoup(html_content, 'lxml')
product_data = {}
# उदाहरण: उत्पाद शीर्षक निकालें
title_element = soup.select_one('#productTitle')
if title_element:
product_data['title'] = title_element.get_text(strip=True)
# उदाहरण: उत्पाद मूल्य निकालें
price_element = soup.select_one('.a-price .a-offscreen')
if price_element:
product_data['price'] = price_element.get_text(strip=True)
# उदाहरण: उत्पाद रेटिंग निकालें
rating_element = soup.select_one('#acrCustomerReviewText')
if rating_element:
product_data['reviews_count'] = rating_element.get_text(strip=True)
# आवश्यकतानुसार अन्य डेटा बिंदुओं के लिए अधिक निकालने की तकनीक जोड़ें
return product_data
# उदाहरण उपयोग:
# html_content = fetch_amazon_page("https://www.amazon.com/dp/B08XYZ123")
# if html_content:
# data = parse_amazon_product_page(html_content)
# print(data)टिप्पणियाँ: अमेज़न की HTML संरचना बदल सकती है, इसलिए नियमित रूप से अपने सेलेक्टर्स की समीक्षा करें और अपडेट करें। डेटा गुणवत्ता सुनिश्चित करने के लिए निर्माण और वैधता के लिए विश्वसनीय त्रुटि संभालना आवश्यक है।
चरण 5: डेटा संग्रहीत करें और प्रबंधित करें
निकालने के बाद, आप डेटा को संरचित रूप में संग्रहीत करें जिससे आगे के विश्लेषण के लिए उपलब्ध हो सके। सामान्य रूपों में CSV, JSON, या डेटाबेस शामिल हैं।
उद्देश्य: निकाले गए डेटा को एक व्यवस्थित और उपलब्ध तरीके से संग्रहीत करना।
संचालन:
- एक भंडारण रूप चुनें: छोटे डेटासेट के लिए, CSV या JSON फाइलें उपयोगी होती हैं। बड़े, जटिल डेटासेट के लिए, एक डेटाबेस (उदाहरण के लिए, SQLite, PostgreSQL, MongoDB) का उपयोग करें।
- भंडारण तकनीक कार्यान्वित करें: निकाले गए डेटा को अपने चयनित रूप में सहेजने के लिए कोड लिखें।
python
import json
import csv
def save_to_json(data, filename):
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print(f"डेटा {filename} में सहेजा गया")
def save_to_csv(data, filename, fieldnames):
with open(filename, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(data)
print(f"डेटा {filename} में सहेजा गया")
# उदाहरण उपयोग:
# all_product_data = [
# {'title': 'उत्पाद A', 'price': '$10.99', 'reviews_count': '1,234 समीक्षाएं'},
# {'title': 'उत्पाद B', 'price': '$25.00', 'reviews_count': '567 समीक्षाएं'},
# ]
# save_to_json(all_product_data, 'amazon_products.json')
# save_to_csv(all_product_data, 'amazon_products.csv', ['title', 'price', 'reviews_count'])टिप्पणियाँ: बड़ी मात्रा में डेटा के साथ काम करते समय, अपने भंडारण में अपडेट करें ताकि पहले से स्क्रैप की गई जानकारी को फिर से स्क्रैप न करें। इससे आपकी अमेज़न स्क्रैपिंग प्रक्रिया अधिक कुशल हो जाती है।
अमेज़न स्क्रैपिंग में सामान्य समस्याओं का समाधान
सबसे अच्छी तैयारी के बावजूद, आपको अमेज़न स्क्रैपिंग के दौरान समस्याओं का सामना करना पड़ सकता है। यहां कुछ सामान्य समस्याएं और उनके समाधान हैं।
समस्या 1: IP ब्लॉक कर दिया गया या दर सीमित है
विवरण: आपके स्क्रैपर को HTTP 403 (अस्वीकृत) या 429 (बहुत अधिक अनुरोध) त्रुटि मिलती है, या अनुरोध बस समाप्त हो जाते हैं।
समाधान:
- प्रॉक्सी का उपयोग करें: अपने अनुरोधों को कई IP पतों पर वितरित करने के लिए एक घूर्णन प्रॉक्सी सेवा का उपयोग करें। यह अमेज़न स्क्रैपिंग के लिए आईपी ब्लॉकिंग से बचने के लिए सबसे प्रभावी तरीका है। अधिक जानकारी के लिए, वेब स्क्रैपिंग के बिना ब्लॉक होने के बारे में पढ़ें।
- अवधि बढ़ाएं: अनुरोधों के बीच
time.sleep()के अवधि बढ़ाएं और अधिक यादृच्छिकता जोड़ें। - सत्र प्रबंधन:
requests.Session()का उपयोग करके अपने अनुरोधों के माध्यम से कुकीज़ और हेडर्स को स्थिर रखें, जो एक अधिक प्राकृतिक ब्राउज़िंग सत्र के समान होता है।
समस्या 2: CAPTCHA का सामना किया गया
विवरण: अमेज़न एक CAPTCHA चुनौती प्रस्तुत करता है, जो आपकी स्क्रैपिंग प्रक्रिया रोक देता है।
समाधान:
- CapSolver का एकीकरण करें: चरण 3 में दिखाए गए अनुसार, AWS WAF CAPTCHA के लिए CapSolver के API का उपयोग करके स्वचालित रूप से हल करें। अमेज़न स्क्रैपिंग के दौरान सामना की गई जटिल चुनौतियों के लिए यह एक विश्वसनीय समाधान है।
- हेडलेस ब्राउज़र: बहुत जटिल जावास्क्रिप्ट-आधारित CAPTCHA के लिए, आपको सेलेनियम के साथ क्रोम/फायरफॉक्स जैसे हेडलेस ब्राउज़र का उपयोग करके पेज को रेंडर करना और CAPTCHA को पकड़ना आवश्यक हो सकता है, फिर इसे CapSolver के पास भेजें।
समस्या 3: HTML संरचना में बदलाव
विवरण: अमेज़न ने अपने वेबसाइट की HTML संरचना अपडेट कर दिया है, जिसके कारण आपकी डेटा निकालने की तकनीक बर्बाद हो गई है।
समाधान:
- नियमित समीक्षा: अपने स्क्रैपर के आउटपुट और लक्षित अमेज़न पृष्ठों की समीक्षा करें। अपेक्षित डेटा फॉर्मेट या कम फील्ड के लिए चेतावनी सेट करें।
- लचीले सेलेक्टर्स: अधिक सामान्य CSS सेलेक्टर या XPath अभिव्यक्तियां उपयोग करें जो बदलाव के कम संभावना है। अधिक विशिष्ट या स्वचालित रूप से बनाए गए वर्ग नामों पर निर्भर न करें।
- त्रुटि संभालना: अपने पार्सिंग तकनीक के चारों ओर
try-exceptब्लॉक लगाएं ताकि अनुपलब्ध तत्वों के साथ बर्खास्त करने के लिए बर्खास्त करें और बाद में समीक्षा के लिए त्रुटि लॉग करें।
समस्या 4: डायनामिक सामग्री नहीं लोड हो रही है
विवरण: आप जिस डेटा को स्क्रैप करना चाहते हैं, वह प्रारंभिक HTML उत्तर में उपलब्ध नहीं है।
समाधान:
- हेडलेस ब्राउज़र: सेलेनियम या प्लेयराइट का उपयोग करके पूरी पृष्ठ रेंडर करें, जिससे जावास्क्रिप्ट-लोड की गई सामग्री तक पहुंच प्राप्त हो सके। इससे अमेज़न स्क्रैपिंग के लिए पूर्ण DOM तक पहुंच प्राप्त होती है।
- API निगरानी: ब्राउज़र डेवलपर टूल्स में नेटवर्क अनुरोधों की जांच करें ताकि डेटा एक आंतरिक API कॉल द्वारा लोड किया जा रहा है। यदि ऐसा है, तो आप बस उस API को सीधे कॉल कर सकते हैं।
बड़े पैमाने पर अमेज़न स्क्रैपिंग के लिए कार्यक्षमता अनुकूलन
बड़े पैमाने पर अमेज़न स्क्रैपिंग ऑपरेशन के लिए, कार्यक्षमता महत्वपूर्ण है। अपने स्क्रैपर के कार्यक्षमता को अनुकूलित करना समय और संसाधन बचा सकता है।
1. समानांतरता और समानांतरता
पृष्ठों को क्रमिक रूप से स्क्रैप करने के बजाय, थ्रेडिंग या असिंक्रोनस प्रोग्रामिंग के साथ बहुत सारे पृष्ठों को एक साथ प्रसंस्करण करें।
- थ्रेडिंग: आईओ-बाउंड कार्य (जैसे, नेटवर्क उत्तर की प्रतीक्षा) के लिए पायथन के
threadingमॉड्यूल का उपयोग करें। - Asyncio: आईओ-बाउंड ऑपरेशन के लिए
asyncioके साथaiohttpबहुत प्रभावी हो सकता है।
चेतावनी: समानांतरता का उपयोग करते समय, अमेज़न की दर सीमाओं के बारे में अत्यधिक सावधान रहें। अपने अनुरोधों को ध्यान से वितरित करें ताकि सर्वर को अत्यधिक भार न दिया जाए और ब्लॉकिंग न हो।
2. वितरित स्क्रैपिंग
अत्यधिक बड़े परियोजनाओं के लिए, अपने स्क्रैपिंग कार्यों को कई मशीनों या बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में बाद में ब
अनुपालन अस्वीकरण: इस ब्लॉग पर प्रदान की गई जानकारी केवल सूचनात्मक उद्देश्यों के लिए है। CapSolver सभी लागू कानूनों और विनियमों का पालन करने के लिए प्रतिबद्ध है। CapSolver नेटवर्क का उपयोग अवैध, धोखाधड़ी या दुरुपयोग करने वाली गतिविधियों के लिए करना सख्त वर्जित है और इसकी जांच की जाएगी। हमारे कैप्चा समाधान उपयोगकर्ता अनुभव को बेहतर बनाने के साथ-साथ सार्वजनिक डेटा क्रॉलिंग के दौरान कैप्चा कठिनाइयों को हल करने में 100% अनुपालन सुनिश्चित करते हैं। हम अपनी सेवाओं के जिम्मेदार उपयोग की प्रोत्साहना करते हैं। अधिक जानकारी के लिए, कृपया हमारी सेवा की शर्तें और गोपनीयता नीति पर जाएं।
अधिक
क्या एआई कैप्चा हल कर सकता है? डिटेक्शन और हल कैसे काम करते हैं
एक्सप्लोर करें कि आर्टिफिशियल इंटेलिजेंस कैप्चा चुनौतियों की पहचान कैसे करता है और हल करता है, चित्र पहचान से व्यवहार विश्लेषण तक। आर्टिफिशियल इंटेलिजेंस कैप्चा सॉल्वर्स के पीछे के तकनीक को समझें और कैपसॉल्वर कैसे स्वचालित वर्कफ़्लो की सहायता करता है। आर्टिफिशियल इंटेलिजेंस और मानव प्रमाणीकरण के बीच विकसित होते संघर्ष के बारे में जानें।

Sora Fujimoto
14-Apr-2026

कैप्चा त्रुटि 600010: इसका क्या अर्थ है और इसे तेजी से कैसे ठीक करें
600010 कैपचा त्रुटि का सामना कर रहे हैं? जानें कि इस क्लाउडफ़्लेयर टर्नस्टाइल त्रुटि का क्या अर्थ है और उपयोगकर्ता और विकासकर्ता के लिए चरण-दर-चरण समाधान प्राप्त करें, अटोमेशन के लिए कैपसॉल्वर एकीकरण सहित।

Anh Tuan
14-Apr-2026
कैसे हल करें AWS WAF चुनौतियां एक्सटेंशन का उपयोग करके: एक व्यापक गाइड
सीखें कैसे कैपसॉल्वर एक्सटेंशन के उपयोग से AWS WAF CAPTCHAs और चुनौतियां स्वचालित रूप से हल करें। इस गाइड में छवि पहचान, टोकन मोड और n8n स्वचालन शामिल हैं।

Rajinder Singh
13-Apr-2026

एमेजॉन कैसे स्क्रैप करें: 2026 का गाइड नैतिक डेटा निष्कर्षण & कैप्चा समाधान
2026 में अमेज़न स्क्रैपिंग के लिए इस व्यापक गाइड के साथ सीखें। चरण-दर-चरण तकनीक, कोड उदाहरण और AWS CAPTCHA चुनौतियों को पार करने के तरीके सीखें, जिनका उपयोग कुशल और नैतिक डेटा निकालने के लिए CapSolver के साथ किया जाता है।
Emma Foster
10-Apr-2026
AWS WAF CAPTCHA हल करना: उपकरण, API एकीकरण और मूल्य निर्धारण गाइड
जानें कि कैसे सही उपकरण, API एकीकरण चरण और पूर्ण लागत विवरण के साथ AWS WAF CAPTCHA हल करने के लिए स्वचालित करें। शीर्ष सेवाओं की तुलना करें और तेजी से शुरू करें।

Ethan Collins
10-Apr-2026
रीकैप्चा के लिए विश्वसनीय CAPTCHA हल करने वाला API: क्या देखना है
reCAPTCHA के लिए भरोसेमंद CAPTCHA हल करने वाला API खोज रहे हैं? गति, लागत और सफलता दर पर शीर्ष प्रदाताओं की तुलना करें। अपनी स्वचालन आवश्यकताओं के लिए सबसे अच्छा समाधान खोजें।
Rajinder Singh
09-Apr-2026