Raspado de web con Selenium y Python | Resolver Captcha al realizar el raspado de web

Rajinder Singh
Deep Learning Researcher
Imagina que puedes obtener fácilmente toda la información que necesitas de Internet sin tener que navegar manualmente por la web ni copiar y pegar. Esa es la belleza del scraping de web. Ya seas analista de datos, investigador de mercados o desarrollador, el scraping de web abre una nueva world de recolección de datos automatizada.
En esta era orientada a los datos, la información es poder. Sin embargo, extraer manualmente información de cientos e incluso miles de páginas web no solo es tiempo consumidor, sino también propenso a errores. Afortunadamente, el scraping de web proporciona una solución eficiente y precisa que permite automatizar el proceso de extracción de datos de Internet, mejorando así significativamente la eficiencia y la calidad de los datos.
Índice
- ¿Qué es el scraping de web?
- Comenzando con Selenium
- Evitar las protecciones contra scraping
- Conclusión
¿Qué es el scraping de web?
El scraping de web es una técnica para extraer información de forma automática de páginas web mediante la escritura de programas. Esta tecnología tiene una amplia gama de aplicaciones en muchos campos, incluyendo análisis de datos, investigación de mercados, inteligencia competitiva, agregación de contenido y más. Con el scraping de web, puedes recopilar y consolidar datos de un gran número de páginas web en un corto período de tiempo, en lugar de depender de operaciones manuales.
El proceso de scraping de web generalmente incluye los siguientes pasos:
- Enviar solicitud HTTP: Enviar programáticamente una solicitud a un sitio web objetivo para obtener el código fuente HTML de la página web. Herramientas comunes como la biblioteca requests de Python pueden hacer esto fácilmente.
- Parsear el contenido HTML: Después de obtener el código fuente HTML, se necesita parsearlo para extraer los datos requeridos. Se pueden usar bibliotecas de parseo HTML como BeautifulSoup o lxml para procesar la estructura HTML.
- Extracción de datos: Basado en la estructura HTML parseada, localizar y extraer contenido específico, como el título del artículo, información de precios, enlaces de imágenes, etc. Los métodos comunes incluyen el uso de XPath o selectores CSS.
- Almacenar datos: Guardar los datos extraídos en un medio de almacenamiento adecuado, como una base de datos, un archivo CSV o un archivo JSON, para análisis y procesamiento posterior.
Y al usar herramientas como Selenium, se puede simular la operación del navegador del usuario, evitando algunas mecanismos de anti-robot, para completar la tarea de scraping de web de manera más eficiente.
Canjear tu código de bonificación de CapSolver
¡Aumenta tu presupuesto de automatización de inmediato!
Usa el código de bonificación CAPN al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Canjéalo ahora en tu Panel de CapSolver
.
Comenzando con Selenium
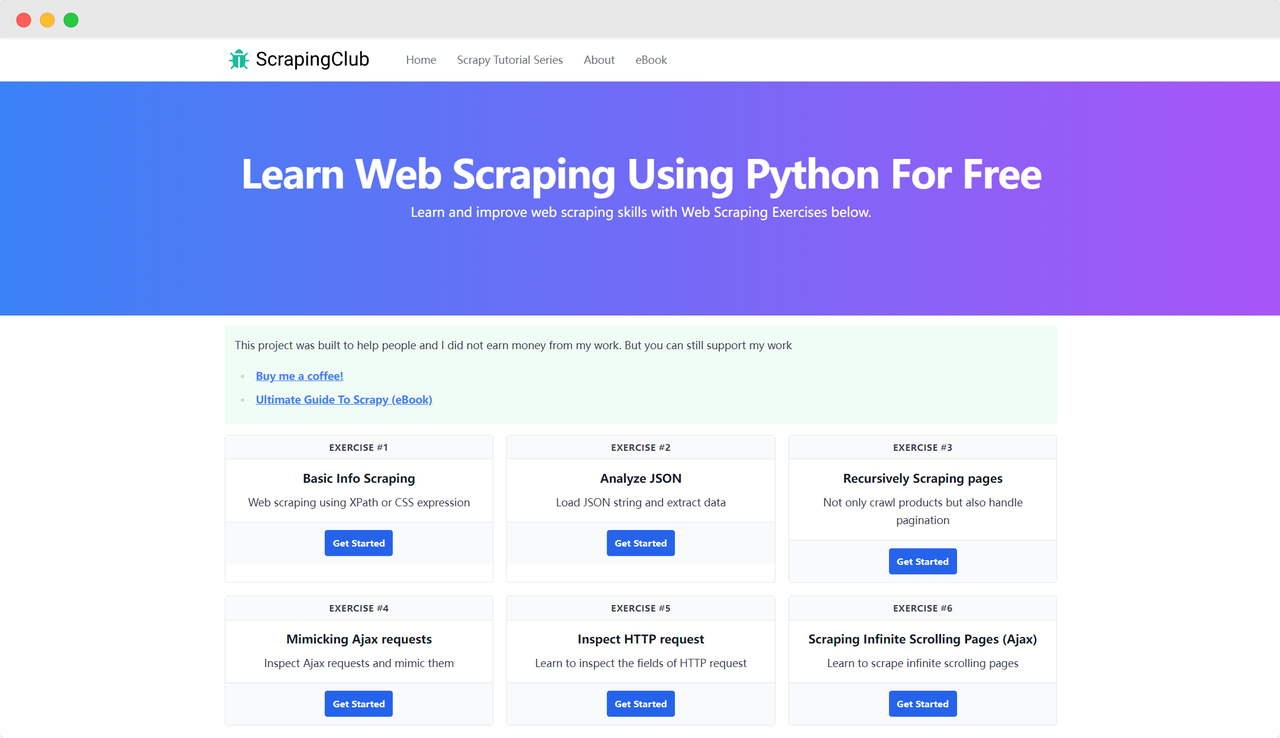
Tomemos ScrapingClub como ejemplo y usemos selenium para completar el primer ejercicio.
Preparación
Primero, asegúrate de que Python esté instalado en tu máquina local. Puedes verificar la versión de Python ingresando el siguiente comando en tu terminal:
bash
python --versionAsegúrate de que la versión de Python sea mayor que 3. Si no está instalado o la versión es demasiado baja, descarga la última versión desde el sitio web oficial de Python. A continuación, necesitas instalar la biblioteca selenium utilizando el siguiente comando:
bash
pip install seleniumImportar bibliotecas
python
from selenium import webdriverAcceder a una página
No es complicado usar Selenium para controlar Google Chrome y acceder a una página. Después de inicializar el objeto Chrome Options, puedes usar el método get() para acceder a la página objetivo:
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()Parámetros de inicio
Chrome Options puede agregar muchos parámetros de inicio que ayudan a mejorar la eficiencia de la recuperación de datos. Puedes ver la lista completa de parámetros en el sitio web oficial: Lista de switches de línea de comandos de Chromium. Algunos parámetros comunes se muestran en la tabla siguiente:
| Parámetro | Propósito |
|---|---|
| --user-agent="" | Establecer el User-Agent en el encabezado de la solicitud |
| --window-size=xxx,xxx | Establecer la resolución del navegador |
| --start-maximized | Ejecutar con resolución maximizada |
| --headless | Ejecutar en modo headless |
| --incognito | Ejecutar en modo incógnito |
| --disable-gpu | Desactivar la aceleración por hardware de GPU |
Ejemplo: Ejecutar en modo headless
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()Localizar elementos de la página
Un paso necesario en la recolección de datos es encontrar los elementos HTML correspondientes en el DOM. Selenium proporciona dos métodos principales para localizar elementos en la página:
find_element: Encuentra un solo elemento que cumpla con los criterios.find_elements: Encuentra todos los elementos que cumplan con los criterios.
Ambos métodos admiten ocho formas diferentes de localizar elementos HTML:
| Método | Significado | Ejemplo HTML | Ejemplo de Selenium |
|---|---|---|---|
| By.ID | Localizar por ID de elemento | <form id="loginForm">...</form> |
driver.find_element(By.ID, 'loginForm') |
| By.NAME | Localizar por nombre de elemento | <input name="username" type="text" /> |
driver.find_element(By.NAME, 'username') |
| By.XPATH | Localizar por XPath | <p><code>My code</code></p> |
driver.find_element(By.XPATH, "//p/code") |
| By.LINK_TEXT | Localizar hipervínculo por texto | <a href="continue.html">Continue</a> |
driver.find_element(By.LINK_TEXT, 'Continue') |
| By.PARTIAL_LINK_TEXT | Localizar hipervínculo por texto parcial | <a href="continue.html">Continue</a> |
driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti') |
| By.TAG_NAME | Localizar por nombre de etiqueta | <h1>Welcome</h1> |
driver.find_element(By.TAG_NAME, 'h1') |
| By.CLASS_NAME | Localizar por nombre de clase | <p class="content">Welcome</p> |
driver.find_element(By.CLASS_NAME, 'content') |
| By.CSS_SELECTOR | Localizar por selector CSS | <p class="content">Welcome</p> |
driver.find_element(By.CSS_SELECTOR, 'p.content') |
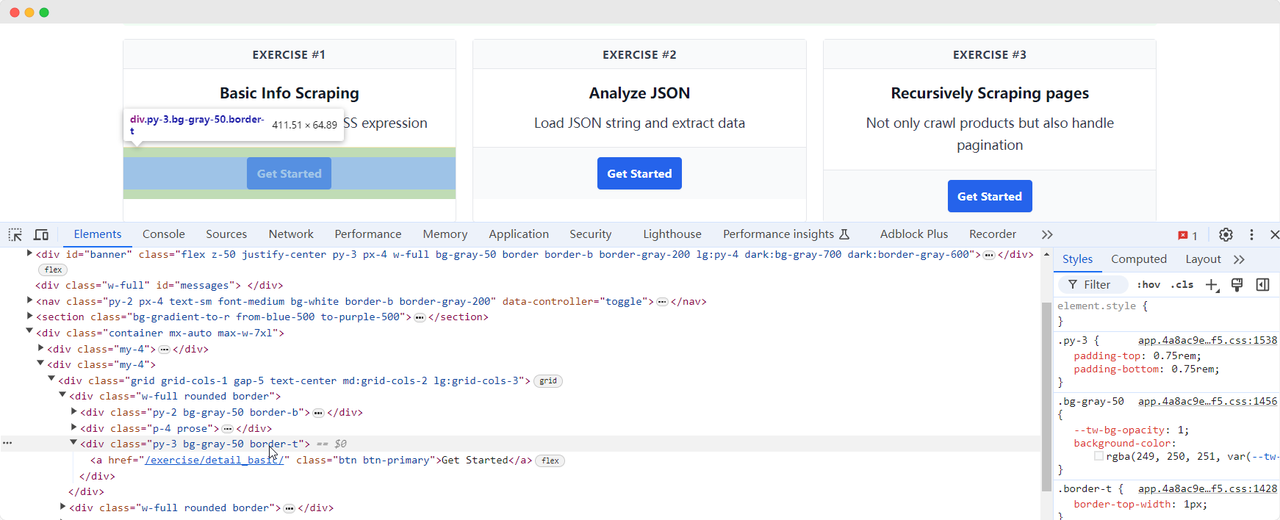
Volvamos a la página de ScrapingClub y escribamos el siguiente código para encontrar el elemento del botón "Get Started" para el primer ejercicio:
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
time.sleep(5)
driver.quit()Interacción con elementos
Una vez que hemos encontrado el elemento del botón "Get Started", necesitamos hacer clic en el botón para acceder a la siguiente página. Esto implica la interacción con elementos. Selenium proporciona varios métodos para simular acciones:
click(): Hacer clic en el elemento;clear(): Limpiar el contenido del elemento;send_keys(*value: str): Simular entrada de teclado;submit(): Enviar un formulario;screenshot(filename): Guardar una captura de pantalla de la página.
Para más interacciones, consulta la documentación oficial: WebDriver API. Continuemos mejorando el código del ejercicio de ScrapingClub agregando la interacción de clic:
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
time.sleep(5)
driver.quit()Extracción de datos
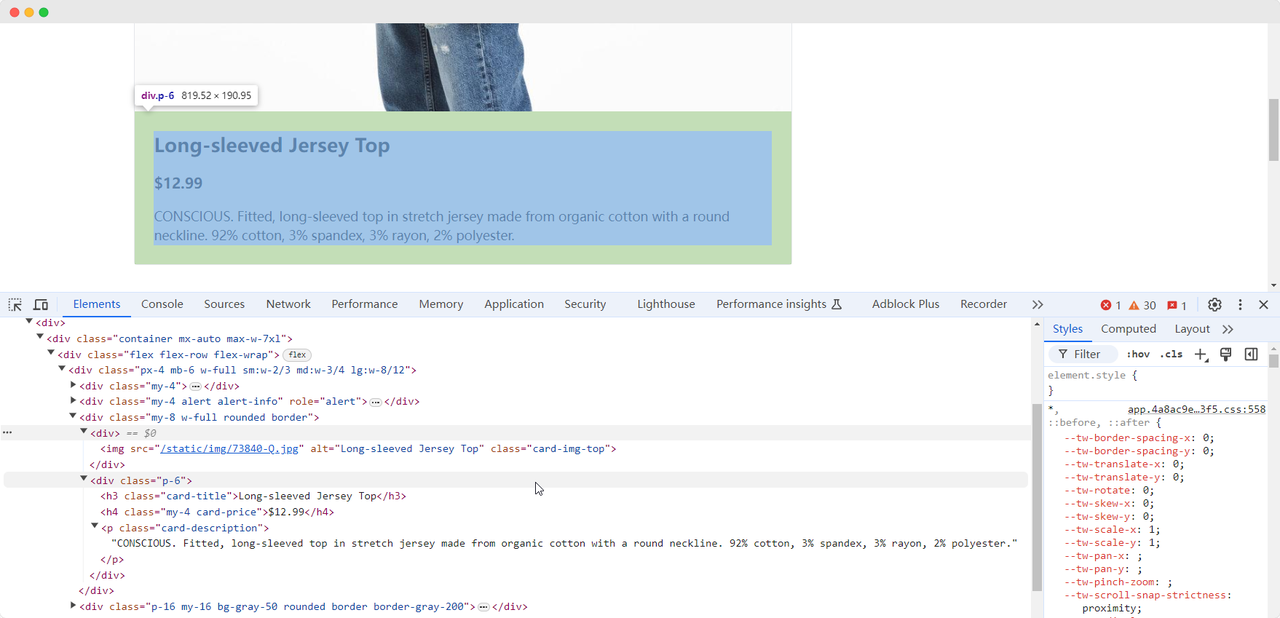
Cuando llegamos a la primera página de ejercicio, necesitamos recopilar información sobre la imagen del producto, el nombre, el precio y la descripción. Podemos usar diferentes métodos para encontrar estos elementos y extraerlos:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Nombre del producto: {product_name}')
print(f'Imagen del producto: {product_image}')
print(f'Precio del producto: {product_price}')
print(f'Descripción del producto: {product_description}')
driver.quit()El código mostrará el siguiente contenido:
Nombre del producto: Camiseta de manga larga
Imagen del producto: https://scrapingclub.com/static/img/73840-Q.jpg
Precio del producto: $12.99
Descripción del producto: CONSCIOUS. Camiseta ajustada de jersey de manga larga hecha de algodón orgánico con cuello redondo. 92% algodón, 3% elastano, 3% rayón, 2% poliéster.Esperar a que los elementos se carguen
A veces, debido a problemas de red u otros motivos, los elementos pueden no haberse cargado aún cuando Selenium termine de ejecutarse, lo que puede causar que algunas recolecciones de datos fallen. Para resolver este problema, podemos configurar que espere hasta que un elemento determinado se cargue completamente antes de continuar con la extracción de datos. Aquí hay un ejemplo de código:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
# esperar a que los elementos de imagen del producto se carguen completamente
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.card-img-top')))
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Nombre del producto: {product_name}')
print(f'Imagen del producto: {product_image}')
print(f'Precio del producto: {product_price}')
print(f'Descripción del producto: {product_description}')
driver.quit()Evitar las protecciones contra scraping
El ejercicio de ScrapingClub es fácil de completar. Sin embargo, en escenarios reales de recolección de datos, obtener datos no es tan fácil porque algunos sitios web utilizan técnicas de anti-scraping que pueden detectar tu script como un robot y bloquear la recolección. La situación más común es el desafío de captcha
Resolver estos desafíos de captcha requiere experiencia extensa en aprendizaje automático, ingeniería inversa y medidas de contramedida de huella de navegador, lo cual puede tomar mucho tiempo. Afortunadamente, ahora no tienes que hacer todo este trabajo tú mismo. CapSolver proporciona una solución completa para ayudarte a evitar fácilmente todos los desafíos. CapSolver ofrece extensiones de navegador que pueden resolver automáticamente los desafíos de captcha mientras usas Selenium para recolectar datos. Además, ofrecen métodos de API para resolver captchas y obtener tokens, todo en unos pocos segundos. Consulta la documentación de CapSolver para más información.
Conclusión
Desde extraer detalles de productos hasta navegar a través de medidas anti-scraping complejas, el scraping de web con Selenium abre puertas a un vasto reino de recolección de datos automatizada. Mientras navegamos por un paisaje web en constante evolución, herramientas como CapSolver facilitan el camino para una recolección de datos más fluida, convirtiendo desafíos antes imposibles en cosas del pasado. Por lo tanto, ya sea que seas un entusiasta de los datos o un desarrollador experimentado, aprovechar estas tecnologías no solo mejora la eficiencia, sino que también abre un mundo donde las perspectivas basadas en datos están a solo un raspado de distancia.
Preguntas frecuentes
1. ¿Para qué se utiliza el scraping de web?
El scraping web se utiliza para extraer información de forma automática de páginas web. Permite a desarrolladores, analistas y empresas recopilar datos de productos, precios, artículos, imágenes, reseñas y otros datos en línea en grandes cantidades sin copia manual, mejorando enormemente la eficiencia y la precisión de los datos.
2. ¿Por qué usar Selenium para el scraping web en lugar de requests o BeautifulSoup?
requests y BeautifulSoup funcionan bien para páginas web estáticas, pero muchos sitios modernos utilizan JavaScript para cargar contenido. Selenium simula un navegador real, permitiéndote extraer páginas dinámicas, hacer clic en botones, desplazarse, interactuar con elementos y eludir medidas simples de anti-scraping, lo que lo hace ideal para escenarios complejos.
3. ¿Puede Selenium extraer datos de sitios web que requieren iniciar sesión o acciones del usuario?
Sí. Selenium puede realizar interacciones como hacer clic en botones, escribir texto, navegar por páginas y gestionar cookies o sesiones, lo que lo hace adecuado para extraer datos de páginas detrás de formularios de inicio de sesión o flujos de trabajo del usuario.
4. ¿Cómo manejo los CAPTCHAs al extraer datos?
Los CAPTCHAs son un mecanismo común de antibot que puede detener los scripts de Selenium. En lugar de resolverlos manualmente, puedes integrar soluciones como CapSolver, que proporciona resolución automática de CAPTCHAs a través de una API o extensión de navegador para mantener el proceso de scraping sin interrupciones.
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.

Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.


