Raspado de web en Node.js: Usando Node Unblocker y CapSolver

Aloísio Vítor
Image Processing Expert
TL;Dr
- Web scraping en Node.js enfrenta desafíos crecientes debido a la detección de bots y CAPTCHAS sofisticados.
- Node Unblocker maneja eficazmente medidas básicas de anti-escaneo como el bloqueo de IP y restricciones geográficas actuando como un middleware de proxy.
- CapSolver es esencial para superar desafíos avanzados, específicamente los CAPTCHAS, que Node Unblocker no puede abordar solo.
- Combinar Node Unblocker con CapSolver crea una solución robusta y eficiente para el web scraping en Node.js.
- La integración adecuada de estas herramientas garantiza una extracción de datos confiable de sitios web complejos.
Introducción
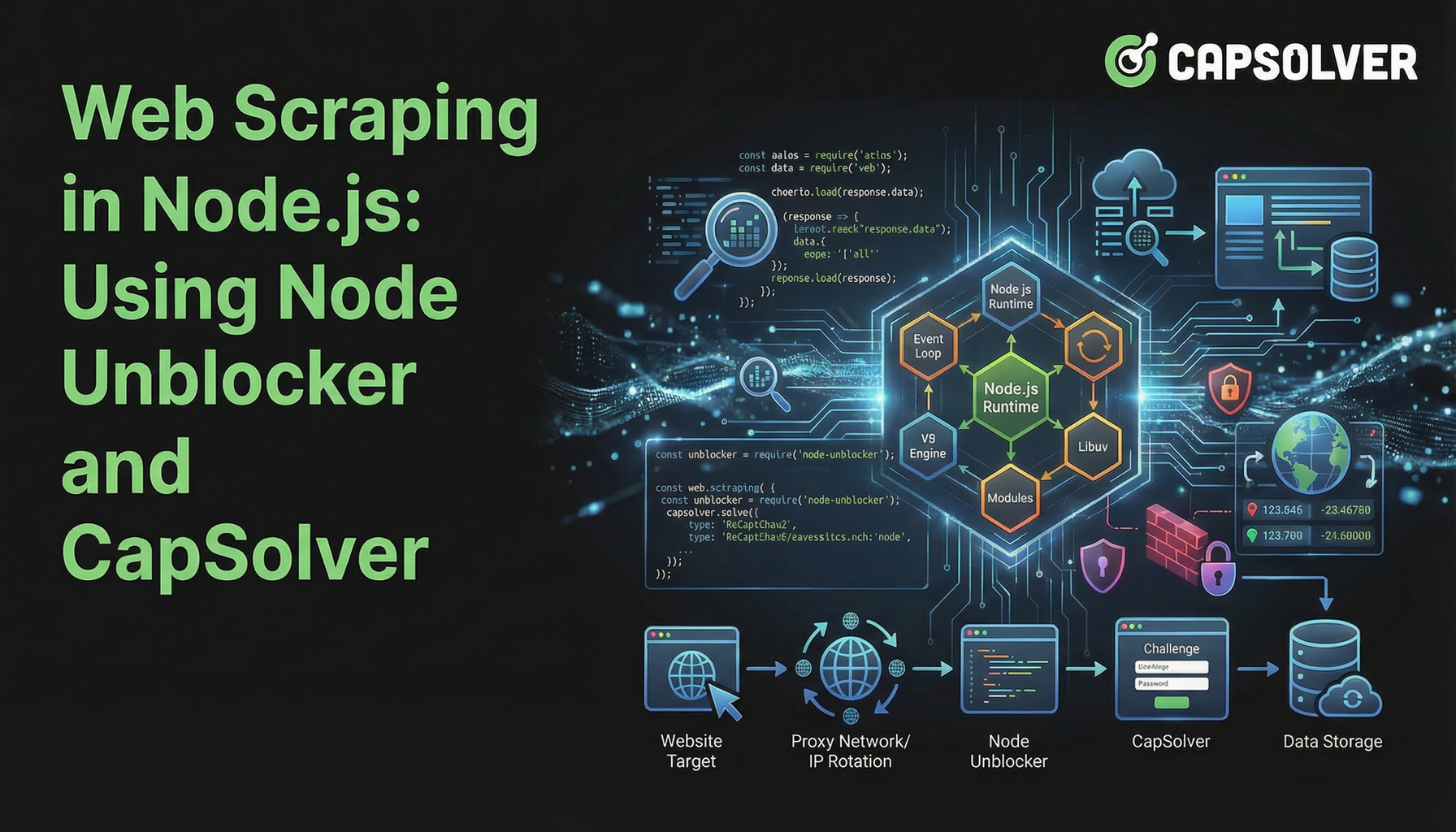
El web scraping en Node.js se ha convertido en una técnica poderosa para la recolección de datos, pero a menudo enfrenta obstáculos significativos. Los sitios web implementan defensas avanzadas para prevenir el acceso automatizado, haciendo que la extracción de datos sea una tarea compleja. Este artículo explora cómo mejorar tus proyectos de web scraping en Node.js combinando Node Unblocker, un middleware de proxy versátil, con CapSolver, un servicio especializado en resolución de CAPTCHAS. Te guiaremos a través de la construcción de una infraestructura de scraping resistente que pueda navegar por restricciones comunes en la web y garantizar un flujo constante de datos. Esta guía está dirigida a desarrolladores que busquen métodos eficientes y confiables para el web scraping en Node.js en el entorno en línea actual.
Entendiendo el paisaje de los desafíos del web scraping
Los sitios web modernos emplean varias técnicas para disuadir los esfuerzos de scraping automatizados. Estas defensas van desde el bloqueo de IP simple hasta desafíos interactivos complejos. Realizar un web scraping en Node.js exitoso requiere comprender y abordar estos obstáculos.
Desafíos comunes incluyen:
- Bloqueo basado en IP: Los sitios web detectan y bloquean las solicitudes que provienen de direcciones IP sospechosas, a menudo asociadas con centros de datos o actividades de scraping conocidas.
- Límites de velocidad: Los servidores restringen el número de solicitudes desde una sola IP en un período determinado, lo que lleva a bloqueos temporales o errores.
- Restricciones geográficas: La disponibilidad de contenido varía según la ubicación geográfica, impidiendo el acceso a ciertos datos desde regiones específicas.
- CAPTCHAS: Estos están diseñados para distinguir usuarios humanos de bots, presentando acertijos visuales o interactivos que son difíciles para los scripts automatizados.
- Contenido dinámico: Los sitios que renderizan contenido con JavaScript requieren que los scrapers ejecuten JavaScript, lo que agrega complejidad.
- Gestión de sesiones: Mantener el estado de la sesión y manejar las cookies correctamente es crucial para navegar por secciones autenticadas de los sitios web.
Estos desafíos destacan la necesidad de herramientas sofisticadas más allá de las bibliotecas básicas de solicitudes HTTP al realizar un web scraping serio en Node.js.
Node Unblocker: La base para un scraping resiliente
Node Unblocker es un middleware de código abierto de Node.js diseñado para facilitar el web scraping en Node.js al sortear restricciones web comunes. Actúa como un proxy, dirigiendo tus solicitudes a través de un servidor intermedio, ocultando así tu dirección IP real y posiblemente evitando bloqueos geográficos. Su principal fortaleza radica en su capacidad para modificar encabezados de solicitud y respuesta, manejar cookies y gestionar sesiones, convirtiéndolo en un activo valioso para capas iniciales de defensa.
Ventajas clave de Node Unblocker:
- Máscara de IP: Enruta el tráfico a través de un proxy, ocultando la IP real de tu scraper. Esto ayuda a evitar bloqueos basados en IP.
- Circunvalación de restricciones geográficas: Al usar proxies ubicados en diferentes regiones, puedes acceder a contenido restringido geográficamente.
- Gestión de encabezados: Permite modificar fácilmente los encabezados HTTP, como User-Agent, Referer y Accept-Language, para imitar solicitudes de navegadores legítimos.
- Manejo de cookies: Gestiona automáticamente las cookies, esencial para mantener el estado de la sesión entre múltiples solicitudes.
- Integración de middleware: Diseñado para integrarse sin problemas con marcos populares de Node.js como Express.js, simplificando la configuración y el uso.
- Flexibilidad de código abierto: Al ser de código abierto, ofrece control total y opciones de personalización para que los desarrolladores lo adapten a necesidades específicas de scraping.
Configuración de Node Unblocker para el web scraping en Node.js
Integrar Node Unblocker en tu proyecto de web scraping en Node.js es sencillo. Primero, asegúrate de tener Node.js y npm instalados. Luego, puedes instalar Node Unblocker y Express.js:
bash
npm init -y
npm install express unblockerA continuación, crea un archivo index.js y configura Node Unblocker como middleware:
javascript
const express = require("express");
const Unblocker = require("unblocker");
const app = express();
const unblocker = new Unblocker({ prefix: "/proxy/" });
app.use(unblocker);
const port = 3000;
app.listen(port).on("upgrade", unblocker.onUpgrade);
console.log(`Proxy en ejecución en http://localhost:${port}/proxy/`);Esta configuración básica crea un servidor proxy local. Luego, puedes enrutar tus solicitudes de scraping a http://localhost:3000/proxy/ seguido de la URL objetivo. Para una configuración más detallada, consulta el repositorio de Node Unblocker en GitHub.
La pieza faltante: Resolver CAPTCHAS con CapSolver
Aunque Node Unblocker excela en manejar restricciones a nivel de red, no aborda desafíos como los CAPTCHAS. Estos acertijos visuales o interactivos están específicamente diseñados para diferenciar usuarios humanos de scripts automatizados. Cuando tu web scraping en Node.js encuentra un CAPTCHA, el proceso de scraping se detiene.
Es aquí donde CapSolver se convierte en una herramienta indispensable. CapSolver es un servicio especializado en resolución de CAPTCHAS que proporciona una API para resolver programáticamente diversos tipos de CAPTCHAS, incluyendo reCAPTCHA v2, reCAPTCHA v3 y Cloudflare Turnstile. Integrar CapSolver en tu flujo de trabajo de web scraping en Node.js permite que tu scraper supere automáticamente estos pasos de verificación humana, asegurando una recolección ininterrumpida de datos.
Usa el código
CAP26al registrarte en CapSolver para recibir créditos adicionales!
Cómo CapSolver mejora el web scraping en Node.js:
- Resolución automática de CAPTCHAS: Resuelve CAPTCHAS complejos sin intervención manual.
- Amplio soporte de CAPTCHAS: Maneja diversos tipos de CAPTCHAS, ofreciendo una solución integral.
- Integración de API: Proporciona una API sencilla para integrarla en proyectos existentes de Node.js.
- Confiabilidad: Ofrece altas tasas de éxito en la resolución de CAPTCHAS, minimizando interrupciones.
- Velocidad: Entrega soluciones rápidas para CAPTCHAS, manteniendo la eficiencia de tus operaciones de scraping.
Integración de CapSolver en tu scraper de Node.js
Para integrar CapSolver, generalmente realizarás una llamada a la API de CapSolver cada vez que se detecte un CAPTCHA. El proceso implica enviar los detalles del CAPTCHA a CapSolver, recibir la solución y luego enviar esa solución de vuelta al sitio objetivo. Esto se puede hacer utilizando un cliente HTTP como Axios en tu aplicación de Node.js.
Por ejemplo, después de configurar tu proxy de Node Unblocker, tu lógica de scraping incluiría una verificación de CAPTCHAS. Si se encuentra uno, iniciarías una llamada a CapSolver. Puedes encontrar ejemplos detallados y documentación sobre cómo integrar CapSolver para diversos tipos de CAPTCHAS en nuestros artículos, como Cómo resolver reCAPTCHA con Node.js y Cómo resolver el CAPTCHA de Cloudflare Turnstile con NodeJS.
Comparación: Node Unblocker solo vs. Node Unblocker + CapSolver
Comprender los roles distintos de Node Unblocker y CapSolver es crucial para un web scraping efectivo en Node.js. Aunque Node Unblocker proporciona capacidades básicas de proxy, CapSolver aborda un desafío específico y avanzado.
| Característica/Herramienta | Node Unblocker solo | Node Unblocker + CapSolver |
|---|---|---|
| Máscara de IP | Sí | Sí |
| Circunvalación de restricciones geográficas | Sí | Sí |
| Gestión de encabezados/cookies | Sí | Sí |
| Resolución de CAPTCHAS | No | Sí |
| Detección de bots (básica) | Parcial (a través de cambios en IP/encabezados) | Mejorada (resuelve CAPTCHAS, reduciendo puntajes de bots) |
| Complejidad de configuración | Moderada | Moderada a Alta (requiere integración de API de CapSolver) |
| Costo | Gratis (de código abierto) | Gratis (de código abierto) + tarifas del servicio CapSolver |
| Confiabilidad para sitios complejos | Limitada | Alta |
| Caso de uso ideal | Sitios simples, recolección básica de datos, pruebas iniciales | Sitios complejos con CAPTCHAS, extracción a gran escala, entornos de producción |
Esta comparación muestra claramente que para un web scraping robusto en Node.js contra defensas web modernas, un enfoque combinado es superior. Node Unblocker maneja el enrutamiento y la evasión básica, mientras que CapSolver proporciona la inteligencia para superar CAPTCHAS.
Estrategias avanzadas para el web scraping en Node.js
Más allá de simplemente usar Node Unblocker y CapSolver, varias estrategias avanzadas pueden mejorar aún más tus proyectos de web scraping en Node.js. Estas técnicas se centran en imitar el comportamiento humano y gestionar los recursos de manera eficiente.
- Rotación de User-Agent: Cambiar regularmente el encabezado User-Agent ayuda a evitar la detección. Un conjunto diverso de User-Agents hace que tus solicitudes parezcan provenir de navegadores y dispositivos diferentes. Aprende más sobre la gestión de agentes de usuario en nuestro artículo sobre Mejor User-Agent.
- Retraso y aleatorización de solicitudes: Introducir retrasos aleatorios entre solicitudes evita que tu scraper alcance límites de velocidad. Los patrones de navegación humana rara vez son perfectamente consistentes.
- Navegadores headless: Para sitios web que dependen fuertemente de JavaScript, usar navegadores headless como Puppeteer o Playwright es esencial. Estas herramientas pueden ejecutar JavaScript y renderizar páginas como un navegador real. Puedes integrar CapSolver con estas herramientas; consulta nuestras guías sobre Cómo integrar Puppeteer y Cómo integrar Playwright.
- Rotación de proxies: Aunque Node Unblocker proporciona una capa de proxy, rotar entre un grupo de proxies diferentes (residenciales, móviles) puede reducir significativamente las probabilidades de bloqueo de IP. Esto es especialmente importante para operaciones de web scraping a gran escala en Node.js.
- Manejo de errores y reintentos: Implementar un manejo robusto de errores con mecanismos de reintentos para solicitudes fallidas. Esto hace que tu scraper sea más resiliente ante problemas de red temporales o bloqueos suaves.
Al combinar estas estrategias con Node Unblocker y CapSolver, construyes una solución de web scraping en Node.js altamente sofisticada y efectiva. Para más consejos generales sobre evitar la detección, consulta nuestro artículo sobre Evitar bloqueos de IP.
Conclusión
El web scraping efectivo en Node.js en 2026 exige un enfoque multifacético para superar defensas web cada vez más complejas. Node Unblocker proporciona una base sólida de código abierto para gestionar conexiones de proxy, enmascarar IPs y manejar intricaciones básicas de HTTP. Sin embargo, para los obstáculos más desafiantes, especialmente los CAPTCHAS, un servicio especializado como CapSolver es indispensable. La sinergia entre Node Unblocker y CapSolver crea una infraestructura de scraping poderosa y confiable, permitiendo a los desarrolladores extraer datos de manera constante y eficiente.
Al integrar estas herramientas y adoptar estrategias avanzadas de scraping, puedes construir aplicaciones de web scraping en Node.js resistentes que se enfrenten a los mecanismos modernos de detección de bots. Equipa tus proyectos con la combinación adecuada de herramientas para asegurar que tus esfuerzos de recolección de datos sean exitosos y sostenibles.
Preguntas frecuentes (FAQ)
P: ¿Para qué se utiliza Node Unblocker en el web scraping?
R: Node Unblocker se utiliza principalmente como middleware de proxy en el web scraping en Node.js para enmascarar la dirección IP del scraper, evitar restricciones geográficas y gestionar encabezados HTTP y cookies. Ayuda a sortear medidas básicas de anti-scraping y hacer que las solicitudes parezcan más legítimas.
P: ¿Puede Node Unblocker resolver CAPTCHAS?
R: No, Node Unblocker en sí mismo no puede resolver CAPTCHAS. Su funcionalidad se centra en el enrutamiento a nivel de red y la modificación de solicitudes. Para resolver CAPTCHAS encontrados durante el web scraping en Node.js, necesitas integrar un servicio especializado en resolución de CAPTCHAS como CapSolver.
P: ¿Por qué debería usar CapSolver con Node Unblocker?
R: Deberías usar CapSolver con Node Unblocker para crear una solución completa para el web scraping en Node.js. Node Unblocker maneja la enmascara de IP y la evasión básica, mientras que CapSolver proporciona la capacidad crucial de resolver automáticamente CAPTCHAS, que son un obstáculo común para los scrapers automatizados en sitios protegidos.
P: ¿Hay alternativas a Node Unblocker para la gestión de proxies?
R: Sí, hay varias alternativas para la gestión de proxies en el web scraping en Node.js, incluyendo scripts personalizados de rotación de proxies, servicios comerciales de proxies o otras bibliotecas de código abierto. Sin embargo, Node Unblocker ofrece un enfoque conveniente para aplicaciones basadas en Express.js.
P: ¿Cuáles son las consideraciones legales para el web scraping?
R: Las consideraciones legales para el web scraping en Node.js incluyen respetar los archivos robots.txt, cumplir con los términos de servicio de los sitios web y cumplir con regulaciones de protección de datos como el RGPD o CCPA. Siempre asegúrate de que tus actividades de scraping sean éticas y legales.
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.
Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.


