Scrapy vs. Selenium: ¿Cuál es el mejor para tu proyecto de raspado web?

Ethan Collins
Pattern Recognition Specialist

TL;DR
Scrapy y Selenium son dos herramientas populares para el raspado de web, cada una adecuada para casos de uso diferentes. Scrapy es un marco de Python rápido, ligero y escalable ideal para el raspado a gran escala de sitios web estáticos. Selenium, por otro lado, automatiza navegadores reales y destaca en el raspado de páginas dinámicas y con mucha JavaScript que requieren interacción del usuario. La elección correcta depende de la complejidad de su proyecto, los requisitos de rendimiento y las necesidades de interacción, y ambas herramientas pueden enfrentar desafíos de CAPTCHA que se pueden resolver con servicios como CapSolver.
Introducción
El raspado de web es una técnica esencial para recopilar datos de Internet, y ha ganado popularidad entre desarrolladores, investigadores y empresas. Dos de las herramientas más utilizadas para el raspado de web son Scrapy y Selenium. Cada una tiene sus fortalezas y debilidades, lo que las hace adecuadas para diferentes tipos de proyectos. En este artículo, compararemos Scrapy y Selenium para ayudarle a determinar qué herramienta es la mejor para sus necesidades de raspado de web.
¿Qué es Scrapy?
Scrapy es un marco de rastreo web potente y rápido escrito en Python. Está diseñado para raspar páginas web y extraer datos estructurados de ellas. Scrapy es altamente eficiente, escalable y personalizable, lo que lo hace una excelente opción para proyectos de raspado a gran escala.
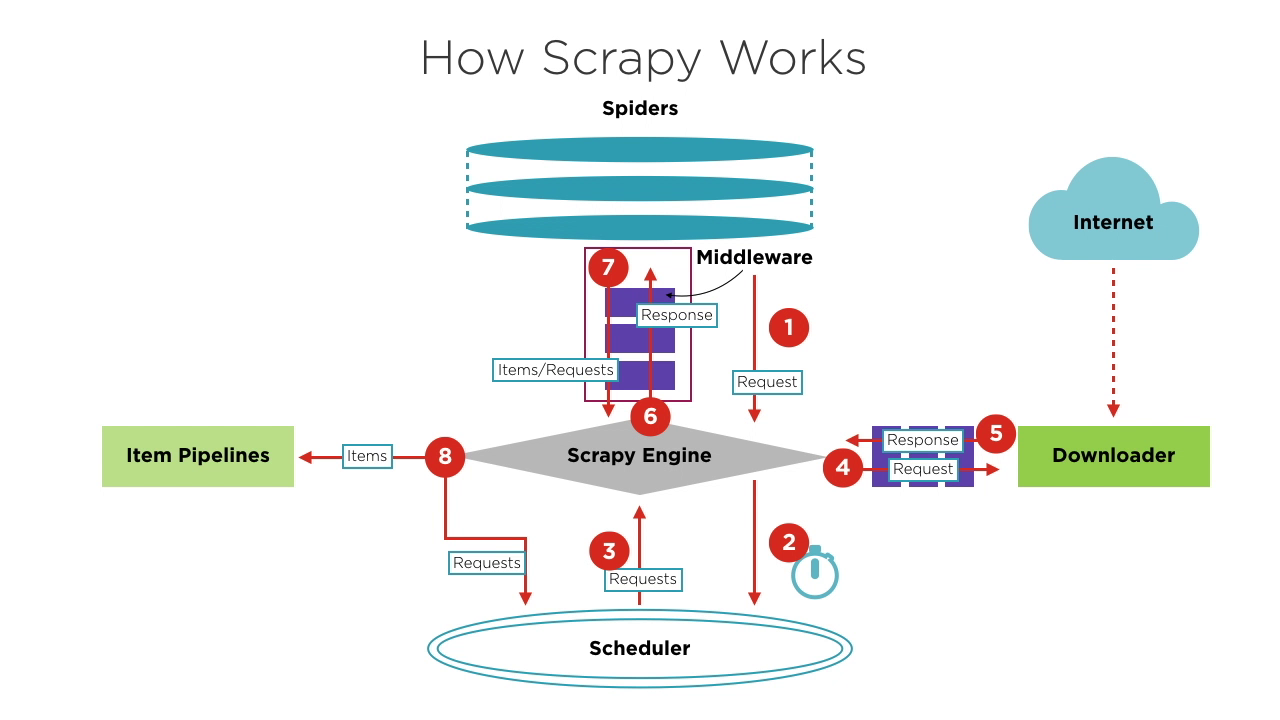
Componentes de Scrapy
- Motor de Scrapy: El núcleo del marco, que gestiona el flujo de datos y eventos dentro del sistema. Es como el cerebro, encargado del intercambio de datos y el procesamiento de lógica.
- Scheduler: Recibe solicitudes del motor, las coloca en cola y las devuelve al motor para que el descargador las ejecute. Mantiene la lógica de programación, como FIFO (Primero en Entrar, Primero en Salir), LIFO (Último en Entrar, Primero en Salir) y colas de prioridad.
- Spiders: Define la lógica para raspar y analizar páginas. Cada spider es responsable de procesar respuestas, generar elementos y nuevas solicitudes para enviar al motor.
- Downloader: Maneja el envío de solicitudes a servidores y la recepción de respuestas, que luego se envían de vuelta al motor.
- Pipelines de Elementos: Procesa los elementos extraídos por los spidres, realizando tareas como limpieza de datos, validación y almacenamiento.
- Middlewares:
- Middlewares de Descarga: Ubicados entre el motor y el descargador, manejan solicitudes y respuestas.
- Middlewares de Spiders: Ubicados entre el motor y los spidres, manejan elementos, solicitudes y respuestas.
¿Luchando con el fracaso repetido para resolver completamente el molesto CAPTCHA? Descubra la resolución automática de CAPTCHA sin problemas con la tecnología Auto Web Unblock impulsada por IA de CapSolver!
¡Aumente su presupuesto de automatización de inmediato!
Utilice el código de bonificación CAPN al recargar su cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Canjéalo ahora en tu Panel de CapSolver.
.
Flujo básico de un proyecto de Scrapy
-
Al iniciar un proyecto de rastreo, el Motor encuentra el Spider que maneja el sitio objetivo según el sitio a rastrear. El Spider genera una o más solicitudes iniciales correspondientes a las páginas que necesitan ser rastreadas y las envía al Motor.
-
El Motor obtiene estas solicitudes del Spider y luego las pasa al Scheduler para que esperen la programación.
-
El Motor solicita al Scheduler la siguiente solicitud a procesar. En este momento, el Scheduler selecciona una solicitud adecuada según su lógica de programación y la envía al Motor.
-
El Motor envía la solicitud del Scheduler al Downloader para su ejecución. El proceso de enviar la solicitud al Downloader pasa por el procesamiento de muchos Middlewares de Descarga predefinidos.
-
El Downloader envía la solicitud al servidor objetivo, recibe la respuesta correspondiente y luego la devuelve al Motor. El proceso de devolver la respuesta al Motor también pasa por el procesamiento de muchos Middlewares de Descarga predefinidos.
-
La respuesta recibida por el Motor del Downloader contiene el contenido del sitio objetivo. El Motor enviará esta respuesta al Spider correspondiente para su procesamiento. El proceso de enviar la respuesta al Spider pasa por el procesamiento de los Middlewares de Spider predefinidos.
-
El Spider procesa la respuesta, analizando su contenido. En este momento, el Spider producirá uno o más elementos de resultados raspados o una o más solicitudes correspondientes a páginas objetivo posteriores para ser raspadas. Luego enviará estos elementos o solicitudes de vuelta al Motor para su procesamiento. El proceso de enviar elementos o solicitudes al Motor pasa por el procesamiento de los Middlewares de Spider predefinidos.
-
El Motor envía uno o más elementos enviados por el Spider a las pipelines de elementos predefinidas para una serie de operaciones de procesamiento o almacenamiento de datos. Envía uno o más solicitudes enviadas por el Spider al Scheduler para esperar la próxima programación.
Los pasos 2 a 8 se repiten hasta que no haya más solicitudes en el Scheduler. En este punto, el Motor cerrará el Spider, y el proceso de rastreo finalizará.
Desde una perspectiva general, cada componente se enfoca solo en una función, la acoplación entre componentes es muy baja y es muy fácil de extender. El Motor luego combina los diversos componentes, permitiendo que cada componente realice su labor, coopere entre sí y completen conjuntamente el trabajo de rastreo. Además, con el soporte de Scrapy para el procesamiento asíncrono, puede maximizar el uso de ancho de banda de red y mejorar la eficiencia del raspado y procesamiento de datos.
¿Qué es Selenium?
Selenium es una herramienta de automatización web de código abierto que permite controlar navegadores web de forma programática. Aunque se utiliza principalmente para probar aplicaciones web, Selenium también es popular para el raspado de web porque puede interactuar con sitios web con mucha JavaScript que son difíciles de raspar con métodos tradicionales. Es importante destacar que Selenium solo puede probar aplicaciones web. No podemos usar Selenium para probar aplicaciones de escritorio (software) o aplicaciones móviles.
El núcleo de Selenium es Selenium WebDriver, que proporciona una interfaz de programación que permite a los desarrolladores escribir código para controlar el comportamiento y las interacciones del navegador. Esta herramienta es muy popular en el desarrollo y pruebas de aplicaciones web porque admite múltiples navegadores y puede ejecutarse en diferentes sistemas operativos. Selenium WebDriver permite a los desarrolladores simular acciones del usuario en el navegador, como hacer clic en botones, completar formularios y navegar por páginas.
Selenium WebDriver ofrece funcionalidades ricas, lo que lo hace una elección ideal para la automatización de pruebas web.
Características clave de Selenium WebDriver
-
Control de navegadores: Selenium WebDriver admite múltiples navegadores principales, incluyendo Chrome, Firefox, Safari, Edge e Internet Explorer. Puede iniciar y controlar estos navegadores, realizando operaciones como abrir páginas web, hacer clic en elementos, ingresar texto y tomar capturas de pantalla.
-
Compatibilidad multiplataforma: Selenium WebDriver puede ejecutarse en diferentes sistemas operativos, incluyendo Windows, macOS y Linux. Esto lo hace muy útil en pruebas multiplataforma, permitiendo a los desarrolladores asegurar que sus aplicaciones funcionen de manera consistente en diversos entornos.
-
Soporte de lenguajes de programación: Selenium WebDriver admite múltiples lenguajes de programación, incluyendo Java, Python, C#, Ruby y JavaScript. Los desarrolladores pueden elegir el lenguaje con el que están familiarizados para escribir scripts de prueba automatizados, mejorando así la eficiencia del desarrollo y las pruebas.
-
Interacción con elementos web: Selenium WebDriver proporciona una API rica para localizar y manipular elementos de páginas web. Admite localizar elementos a través de diversos métodos como ID, nombre de clase, nombre de etiqueta, selector CSS, XPath, etc. Los desarrolladores pueden usar estas APIs para implementar operaciones como hacer clic, ingresar texto, seleccionar y arrastrar y soltar.
Comparación entre Scrapy y Selenium
| Característica | Scrapy | Selenium |
|---|---|---|
| Propósito | Solo raspado de web | Raspado de web y pruebas web |
| Soporte de lenguajes | Solo Python | Java, Python, C#, Ruby, JavaScript, etc. |
| Velocidad de ejecución | Rápido | Más lento |
| Extensibilidad | Alta | Limitada |
| Soporte asíncrono | Sí | No |
| Renderizado dinámico | No | Sí |
| Interacción con navegadores | No | Sí |
| Consumo de recursos de memoria | Bajo | Alto |
Elección entre Scrapy y Selenium
-
Elija Scrapy si:
- Su objetivo es páginas web estáticas sin renderizado dinámico.
- Necesita optimizar el consumo de recursos y la velocidad de ejecución.
- Requiere procesamiento de datos extensivo y middlewares personalizados.
-
Elija Selenium si:
- Su sitio web objetivo implica contenido dinámico y requiere interacción.
- La eficiencia de ejecución y el consumo de recursos no son una preocupación.
Ya sea usar Scrapy o Selenium depende de la escena de aplicación específica, comparar las ventajas y desventajas de diversas opciones y elegir la más adecuada para usted, por supuesto, si sus habilidades de programación son suficientemente buenas, incluso puede combinar Scrapy y Selenium al mismo tiempo.
Desafíos con Scrapy y Selenium
Ya sea que utilice Scrapy o Selenium, puede enfrentar el mismo problema: desafíos de bots. Los desafíos de bots se utilizan ampliamente para distinguir entre computadoras y humanos, prevenir el acceso malicioso de bots a sitios web y proteger los datos de ser raspados. Los desafíos comunes de bots incluyen CAPTCHA, reCaptcha, CAPTCHA, CAPTCHA, Cloudflare Turnstile, CAPTCHA, CAPTCHA WAF y otros. Utilizan imágenes complejas y desafíos de JavaScript difíciles de leer para determinar si es un bot. Algunos desafíos incluso son difíciles de superar para los humanos.
Como dice el dicho, "A cada uno le corresponde su especialidad". La aparición de CapSolver ha hecho que este problema sea más sencillo. CapSolver utiliza tecnología de desbloqueo web automático basada en IA que puede ayudarle a resolver diversos desafíos de bots en segundos. No importa qué tipo de desafío de imagen o pregunta encuentre, puede confiar en CapSolver. Si no tiene éxito, no será facturado.
CapSolver proporciona una extensión para el navegador que puede resolver automáticamente los desafíos de CAPTCHA durante su proceso de raspado de datos basado en Selenium. También ofrece un método de API para resolver CAPTCHAS y obtener tokens, permitiéndole manejar fácilmente diversos desafíos en Scrapy. Todo este trabajo se puede completar en unos pocos segundos. Consulte la documentación de CapSolver para más información.
Conclusión
Elegir entre Scrapy y Selenium depende de las necesidades de su proyecto. Scrapy es ideal para raspar sitios web estáticos de manera eficiente, mientras que Selenium destaca en páginas dinámicas y con mucha JavaScript. Considere los requisitos específicos, como velocidad, uso de recursos y nivel de interacción. Para superar desafíos como los CAPTCHA, herramientas como CapSolver ofrecen soluciones eficientes, haciendo que el proceso de raspado sea más suave. En última instancia, la elección correcta garantiza un proyecto de raspado exitoso y eficiente.
Preguntas frecuentes
1. ¿Pueden usarse Scrapy y Selenium juntos en un proyecto?
Sí. Un enfoque común es usar Selenium para manejar el renderizado de JavaScript o interacciones complejas (como flujos de inicio de sesión), luego pasar el HTML renderizado o las URLs extraídas a Scrapy para un rastreo rápido y a gran escala y extracción de datos. Este modelo híbrido combina la flexibilidad de Selenium con el rendimiento de Scrapy.
2. ¿Es adecuado Scrapy para sitios web modernos con mucha JavaScript?
Por defecto, Scrapy no ejecuta JavaScript, lo que lo hace inadecuado para sitios que dependen principalmente del renderizado del lado del cliente. Sin embargo, puede extenderse usando herramientas como Playwright, Splash o Selenium para manejar contenido de JavaScript cuando sea necesario.
3. ¿Qué herramienta es más eficiente en términos de recursos para el raspado a gran escala?
Scrapy es significativamente más eficiente en términos de recursos que Selenium. Utiliza redes asíncronas y no requiere lanzar un navegador, lo que lo hace más adecuado para tareas de raspado a gran escala y volumen alto. Selenium consume más CPU y memoria porque controla un navegador real, lo que limita la escalabilidad.
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.

Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.


