Integrar Crawlab con CapSolver: Resolución Automatizada de CAPTCHA para el Rastreo Distribuido

Adélia Cruz
Neural Network Developer

Gestionar robots de web crawling a gran escala requiere una infraestructura robusta que pueda manejar los desafíos anti-bot modernos. Crawlab es una plataforma de gestión de crawlers distribuidos potente, y CapSolver es un servicio de resolución de CAPTCHA con inteligencia artificial. Juntos, permiten sistemas de crawling de nivel empresarial que evitan automáticamente los desafíos de CAPTCHA.
Este guía proporciona ejemplos de código completos y listos para usar para integrar CapSolver en sus spideers de Crawlab.
Lo que aprenderás
- Resolver reCAPTCHA v2 con Selenium
- Resolver Cloudflare Turnstile
- Integración de middleware con Scrapy
- Integración con Node.js/Puppeteer
- Mejores prácticas para manejar CAPTCHA a gran escala
¿Qué es Crawlab?
Crawlab es una plataforma de administración de crawlers distribuidos diseñada para gestionar spideers en múltiples lenguajes de programación.
Características clave
- Independiente de lenguaje: Soporta Python, Node.js, Go, Java y PHP
- Marco de trabajo flexible: Funciona con Scrapy, Selenium, Puppeteer, Playwright
- Arquitectura distribuida: Escalabilidad horizontal con nodos maestro/trabajador
- Interfaz de gestión: Interfaz web para gestión y programación de spideers
Instalación
bash
# Usando Docker Compose
git clone https://github.com/crawlab-team/crawlab.git
cd crawlab
docker-compose up -dAcceda a la interfaz de usuario en http://localhost:8080 (por defecto: admin/admin).
¿Qué es CapSolver?
CapSolver es un servicio de resolución de CAPTCHA con inteligencia artificial que proporciona soluciones rápidas y confiables para diversos tipos de CAPTCHA.
Tipos de CAPTCHA soportados
- reCAPTCHA: v2, v3 y Enterprise
- Cloudflare: Turnstile y Challenge
- AWS WAF: Bypass de protección
- Y Más
Flujo de trabajo de la API
- Enviar parámetros de CAPTCHA (tipo, siteKey, URL)
- Recibir ID de tarea
- Consultar solución
- Inyectar token en la página
Requisitos previos
- Python 3.8+ o Node.js 16+
- Clave de API de CapSolver - Regístrese aquí
- Navegador Chrome/Chromium
bash
# Dependencias de Python
pip install selenium requestsResolver reCAPTCHA v2 con Selenium
Script completo de Python para resolver desafíos de reCAPTCHA v2:
python
"""
Crawlab + CapSolver: Solucionador de reCAPTCHA v2
Script completo para resolver desafíos de reCAPTCHA v2 con Selenium
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Configuración
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'SU_CLAVE_DE_API_DE_CAPSOLVER')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverClient:
"""Cliente de la API de CapSolver para reCAPTCHA v2"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def create_task(self, task: dict) -> str:
"""Crear una tarea de resolución de CAPTCHA"""
payload = {
"clientKey": self.api_key,
"task": task
}
response = self.session.post(
f"{CAPSOLVER_API}/createTask",
json=payload
)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Error de CapSolver: {result.get('errorDescription')}")
return result['taskId']
def get_task_result(self, task_id: str, timeout: int = 120) -> dict:
"""Consultar resultado de la tarea"""
for _ in range(timeout):
payload = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(
f"{CAPSOLVER_API}/getTaskResult",
json=payload
)
result = response.json()
if result.get('status') == 'ready':
return result['solution']
if result.get('status') == 'failed':
raise Exception("La resolución de CAPTCHA falló")
time.sleep(1)
raise Exception("Tiempo de espera agotado para la solución")
def solve_recaptcha_v2(self, website_url: str, site_key: str) -> str:
"""Resolver reCAPTCHA v2 y devolver token"""
task = {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
print(f"Creando tarea para {website_url}...")
task_id = self.create_task(task)
print(f"Tarea creada: {task_id}")
print("Esperando solución...")
solution = self.get_task_result(task_id)
return solution['gRecaptchaResponse']
def get_balance(self) -> float:
"""Obtener saldo de la cuenta"""
response = self.session.post(
f"{CAPSOLVER_API}/getBalance",
json={"clientKey": self.api_key}
)
return response.json().get('balance', 0)
class RecaptchaV2Crawler:
"""Crawler de Selenium con soporte para reCAPTCHA v2"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.capsolver = CapsolverClient(CAPSOLVER_API_KEY)
def start(self):
"""Iniciar navegador"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--window-size=1920,1080")
self.driver = webdriver.Chrome(options=options)
print("Navegador iniciado")
def stop(self):
"""Cerrar navegador"""
if self.driver:
self.driver.quit()
print("Navegador cerrado")
def detect_recaptcha(self) -> str:
"""Detectar reCAPTCHA y devolver clave de sitio"""
try:
element = self.driver.find_element(By.CLASS_NAME, "g-recaptcha")
return element.get_attribute("data-sitekey")
except:
return None
def inject_token(self, token: str):
"""Inyectar token resuelto en la página"""
self.driver.execute_script(f"""
// Establecer el campo de texto g-recaptcha-response
var responseField = document.getElementById('g-recaptcha-response');
if (responseField) {{
responseField.style.display = 'block';
responseField.value = '{token}';
}}
// Establecer todos los campos de respuesta ocultos
var textareas = document.querySelectorAll('textarea[name="g-recaptcha-response"]');
for (var i = 0; i < textareas.length; i++) {{
textareas[i].value = '{token}';
}}
""")
print("Token inyectado")
def submit_form(self):
"""Enviar el formulario"""
try:
submit = self.driver.find_element(
By.CSS_SELECTOR,
'button[type="submit"], input[type="submit"]'
)
submit.click()
print("Formulario enviado")
except Exception as e:
print(f"No se pudo enviar el formulario: {e}")
def crawl(self, url: str) -> dict:
"""Crawlear URL con manejo de reCAPTCHA v2"""
result = {
'url': url,
'success': False,
'captcha_solved': False
}
try:
print(f"Navegando a: {url}")
self.driver.get(url)
time.sleep(2)
# Detectar reCAPTCHA
site_key = self.detect_recaptcha()
if site_key:
print(f"reCAPTCHA v2 detectado! Clave de sitio: {site_key}")
# Resolver CAPTCHA
token = self.capsolver.solve_recaptcha_v2(url, site_key)
print(f"Token recibido: {token[:50]}...")
# Inyectar token
self.inject_token(token)
result['captcha_solved'] = True
# Enviar formulario
self.submit_form()
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
result['error'] = str(e)
print(f"Error: {e}")
return result
def main():
"""Punto de entrada principal"""
# Verificar saldo
client = CapsolverClient(CAPSOLVER_API_KEY)
print(f"Saldo de CapSolver: ${client.get_balance():.2f}")
# Crear crawler
crawler = RecaptchaV2Crawler(headless=True)
try:
crawler.start()
# Crawlear URL objetivo (reemplazar con su URL objetivo)
result = crawler.crawl("https://example.com/pagina-protegida")
print("\n" + "=" * 50)
print("RESULTADO:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Resolver Cloudflare Turnstile
Script completo de Python para resolver Cloudflare Turnstile:
python
"""
Crawlab + CapSolver: Solucionador de Cloudflare Turnstile
Script completo para resolver desafíos de Turnstile
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
# Configuración
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'SU_CLAVE_DE_API_DE_CAPSOLVER')
CAPSOLVER_API = 'https://api.capsolver.com'
class TurnstileSolver:
"""Cliente de CapSolver para Turnstile"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def solve(self, website_url: str, site_key: str) -> str:
"""Resolver CAPTCHA de Turnstile"""
print(f"Resolviendo Turnstile para {website_url}")
print(f"Clave de sitio: {site_key}")
# Crear tarea
task_data = {
"clientKey": self.api_key,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
}
response = self.session.post(f"{CAPSOLVER_API}/createTask", json=task_data)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Error de CapSolver: {result.get('errorDescription')}")
task_id = result['taskId']
print(f"Tarea creada: {task_id}")
# Consultar resultado
for i in range(120):
result_data = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(f"{CAPSOLVER_API}/getTaskResult", json=result_data)
result = response.json()
if result.get('status') == 'ready':
token = result['solution']['token']
print(f"Turnstile resuelto!")
return token
if result.get('status') == 'failed':
raise Exception("La resolución de Turnstile falló")
time.sleep(1)
raise Exception("Tiempo de espera agotado para la solución")
class TurnstileCrawler:
"""Crawler de Selenium con soporte para Turnstile"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.solver = TurnstileSolver(CAPSOLVER_API_KEY)
def start(self):
"""Iniciar navegador"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
self.driver = webdriver.Chrome(options=options)
def stop(self):
"""Cerrar navegador"""
if self.driver:
self.driver.quit()
def detect_turnstile(self) -> str:
"""Detectar Turnstile y devolver clave de sitio"""
try:
turnstile = self.driver.find_element(By.CLASS_NAME, "cf-turnstile")
return turnstile.get_attribute("data-sitekey")
except NoSuchElementException:
return None
def inject_token(self, token: str):
"""Inyectar token de Turnstile"""
self.driver.execute_script(f"""
var token = '{token}';
// Encontrar campo cf-turnstile-response
var field = document.querySelector('[name="cf-turnstile-response"]');
if (field) {{
field.value = token;
}}
// Encontrar todos los campos de Turnstile
var inputs = document.querySelectorAll('input[name*="turnstile"]');
for (var i = 0; i < inputs.length; i++) {{
inputs[i].value = token;
}}
""")
print("Token inyectado!")
def crawl(self, url: str) -> dict:
"""Crawlear URL con manejo de Turnstile"""
result = {
'url': url,
'success': False,
'captcha_solved': False,
'captcha_type': None
}
try:
print(f"Navegando a: {url}")
self.driver.get(url)
time.sleep(3)
# Detectar Turnstile
site_key = self.detect_turnstile()
if site_key:
result['captcha_type'] = 'turnstile'
print(f"Turnstile detectado! Clave de sitio: {site_key}")
# Resolver
token = self.solver.solve(url, site_key)
# Inyectar
self.inject_token(token)
result['captcha_solved'] = True
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
print(f"Error: {e}")
result['error'] = str(e)
return result
def main():
"""Punto de entrada principal"""
crawler = TurnstileCrawler(headless=True)
try:
crawler.start()
# Crawlear URL objetivo (reemplazar con su URL objetivo)
result = crawler.crawl("https://example.com/protected-by-turnstile")
print("\n" + "=" * 50)
print("RESULTADO:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Integración con Scrapy
Spider de Scrapy con middleware de CapSolver:
python
"""
Crawlab + CapSolver: Spider de Scrapy
Spider de Scrapy con middleware de resolución de CAPTCHA
"""
import scrapy
import requests
import time
import os
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'SU_CLAVE_DE_API_DE_CAPSOLVER')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverMiddleware:
"""Middleware de Scrapy para resolución de CAPTCHA"""
def __init__(self):
self.api_key = CAPSOLVER_API_KEY
def solve_recaptcha_v2(self, url: str, site_key: str) -> str:
"""Resolver reCAPTCHA v2"""Crear tarea
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": self.api_key,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": url,
"websiteKey": site_key
}
}
)
task_id = response.json()['taskId']
# Esperar resultado
for _ in range(120):
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={"clientKey": self.api_key, "taskId": task_id}
).json()
if result.get('status') == 'ready':
return result['solution']['gRecaptchaResponse']
time.sleep(1)
raise Exception("Tiempo de espera agotado")class CaptchaSpider(scrapy.Spider):
"""Spider con manejo de CAPTCHA"""
name = "captcha_spider"
start_urls = ["https://example.com/protected"]
custom_settings = {
'DOWNLOAD_DELAY': 2,
'CONCURRENT_REQUESTS': 1,
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.capsolver = CapsolverMiddleware()
def parse(self, response):
# Verificar CAPTCHA
site_key = response.css('.g-recaptcha::attr(data-sitekey)').get()
if site_key:
self.logger.info(f"CAPTCHA detectado: {site_key}")
# Resolver CAPTCHA
token = self.capsolver.solve_recaptcha_v2(response.url, site_key)
# Enviar formulario con token
yield scrapy.FormRequest.from_response(
response,
formdata={'g-recaptcha-response': token},
callback=self.after_captcha
)
else:
yield from self.extract_data(response)
def after_captcha(self, response):
"""Procesar página después del CAPTCHA"""
yield from self.extract_data(response)
def extract_data(self, response):
"""Extraer datos de la página"""
yield {
'title': response.css('title::text').get(),
'url': response.url,
}Configuración de Scrapy (settings.py)
"""
BOT_NAME = 'captcha_crawler'
SPIDER_MODULES = ['spiders']
Capsolver
CAPSOLVER_API_KEY = 'TU_CLAVE_DE_API_DE_CAPSOLVER'
Límites de velocidad
DOWNLOAD_DELAY = 2
CONCURRENT_REQUESTS = 1
ROBOTSTXT_OBEY = True
"""
---
## Integración con Node.js/Puppeteer
Script completo de Node.js con Puppeteer:
```javascript
/**
* Crawlab + Capsolver: Spider con Puppeteer
* Script completo para resolver CAPTCHA
*/
const puppeteer = require('puppeteer');
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY || 'TU_CLAVE_DE_API_DE_CAPSOLVER';
const CAPSOLVER_API = 'https://api.capsolver.com';
/**
* Cliente de Capsolver
*/
class Capsolver {
constructor(apiKey) {
this.apiKey = apiKey;
}
async createTask(task) {
const response = await fetch(`${CAPSOLVER_API}/createTask`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
task: task
})
});
const result = await response.json();
if (result.errorId !== 0) {
throw new Error(result.errorDescription);
}
return result.taskId;
}
async getTaskResult(taskId, timeout = 120) {
for (let i = 0; i < timeout; i++) {
const response = await fetch(`${CAPSOLVER_API}/getTaskResult`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
taskId: taskId
})
});
const result = await response.json();
if (result.status === 'ready') {
return result.solution;
}
if (result.status === 'failed') {
throw new Error('Tarea fallida');
}
await new Promise(r => setTimeout(r, 1000));
}
throw new Error('Tiempo de espera agotado');
}
async solveRecaptchaV2(url, siteKey) {
const taskId = await this.createTask({
type: 'ReCaptchaV2TaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse;
}
async solveTurnstile(url, siteKey) {
const taskId = await this.createTask({
type: 'AntiTurnstileTaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.token;
}
}
/**
* Función principal de raspado
*/
async function crawlWithCaptcha(url) {
const capsolver = new Capsolver(CAPSOLVER_API_KEY);
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
try {
console.log(`Raspar: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
// Detectar tipo de CAPTCHA
const captchaInfo = await page.evaluate(() => {
const recaptcha = document.querySelector('.g-recaptcha');
if (recaptcha) {
return {
type: 'recaptcha',
siteKey: recaptcha.dataset.sitekey
};
}
const turnstile = document.querySelector('.cf-turnstile');
if (turnstile) {
return {
type: 'turnstile',
siteKey: turnstile.dataset.sitekey
};
}
return null;
});
if (captchaInfo) {
console.log(`${captchaInfo.type} detectado!`);
let token;
if (captchaInfo.type === 'recaptcha') {
token = await capsolver.solveRecaptchaV2(url, captchaInfo.siteKey);
// Inyectar token
await page.evaluate((t) => {
const field = document.getElementById('g-recaptcha-response');
if (field) field.value = t;
document.querySelectorAll('textarea[name="g-recaptcha-response"]')
.forEach(el => el.value = t);
}, token);
} else if (captchaInfo.type === 'turnstile') {
token = await capsolver.solveTurnstile(url, captchaInfo.siteKey);
// Inyectar token
await page.evaluate((t) => {
const field = document.querySelector('[name="cf-turnstile-response"]');
if (field) field.value = t;
}, token);
}
console.log('CAPTCHA resuelto e inyectado!');
}
// Extraer datos
const data = await page.evaluate(() => ({
title: document.title,
url: window.location.href
}));
return data;
} finally {
await browser.close();
}
}
// Ejecución principal
const targetUrl = process.argv[2] || 'https://example.com';
crawlWithCaptcha(targetUrl)
.then(result => {
console.log('\nResultado:');
console.log(JSON.stringify(result, null, 2));
})
.catch(console.error);Buenas prácticas
1. Manejo de errores con reintentos
python
def solve_with_retry(solver, url, site_key, max_retries=3):
"""Resolver CAPTCHA con lógica de reintentos"""
for attempt in range(max_retries):
try:
return solver.solve(url, site_key)
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"Intento {attempt + 1} fallido: {e}")
time.sleep(2 ** attempt) # Retroalimentación exponencial2. Gestión de costos
- Detectar antes de resolver: Llamar a Capsolver solo cuando esté presente el CAPTCHA
- Cachear tokens: Los tokens de reCAPTCHA son válidos por ~2 minutos
- Monitorear saldo: Verificar el saldo antes de trabajos por lotes
3. Límites de velocidad
python
# Configuración de Scrapy
DOWNLOAD_DELAY = 3
CONCURRENT_REQUESTS_PER_DOMAIN = 14. Variables de entorno
bash
export CAPSOLVER_API_KEY="tu-clave-de-api-aquí"Solución de problemas
| Error | Causa | Solución |
|---|---|---|
ERROR_ZERO_BALANCE |
Sin créditos | Recargar la cuenta de CapSolver |
ERROR_CAPTCHA_UNSOLVABLE |
Parámetros inválidos | Verificar la extracción de la clave del sitio |
TimeoutError |
Problemas de red | Aumentar el tiempo de espera, agregar reintentos |
WebDriverException |
Error del navegador | Agregar la bandera --no-sandbox |
Preguntas frecuentes
P: ¿Cuánto tiempo son válidos los tokens de CAPTCHA?
R: Tokens de reCAPTCHA: ~2 minutos. Turnstile: varía según el sitio.
P: ¿Cuál es el tiempo promedio de resolución?
R: reCAPTCHA v2: 5-15s, Turnstile: 1-10s.
P: ¿Puedo usar mi propio proxy?
R: Sí, usar tipos de tarea sin el sufijo "ProxyLess" y proporcionar la configuración del proxy.
Conclusión
La integración de CapSolver con Crawlab permite un manejo robusto de CAPTCHA en toda la infraestructura de raspado distribuido. Los scripts completos anteriores se pueden copiar directamente en sus spide de Crawlab.
¿Listo para comenzar? Regístrese en CapSolver y potencie sus raspadores!
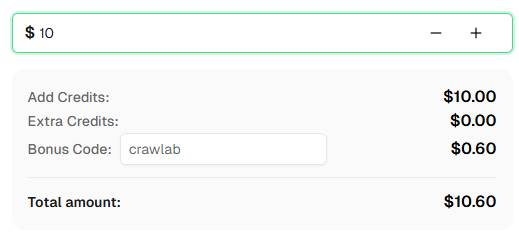
💡 Bonificación exclusiva para usuarios de integración con Crawlab:
Para celebrar esta integración, ofrecemos un código de bonificación exclusivo del 6% — Crawlab para todos los usuarios de CapSolver que se registren a través de este tutorial.
Simplemente ingrese el código durante el recarga en el Dashboard para recibir inmediatamente un 6% adicional de crédito.
13. Documentación
- 13.1. Documentación de Crawlab
- 13.2. GitHub de Crawlab
- 13.3. Documentación de Capsolver
- 13.4. Referencia de la API de Capsolver
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.

Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.

