Cómo hacer scraping web con Puppeteer y NodeJS | Tutorial de Puppeteer

Adélia Cruz
Neural Network Developer

El raspado de web es una técnica poderosa utilizada para extraer datos de sitios web. En este tutorial, exploraremos cómo realizar el raspado de web utilizando Puppeteer y Node.js, dos tecnologías populares en el ecosistema de desarrollo web. Puppeteer es una biblioteca de Node.js que proporciona una API de alto nivel para controlar navegadores Chrome o Chromium en modo headless. Permite automatizar acciones del navegador, navegar por páginas web y extraer los datos deseados. Al combinar Puppeteer con la flexibilidad de Node.js, podemos construir soluciones robustas y eficientes para el raspado de web. Comencemos con los pasos involucrados en el raspado de sitios web utilizando Puppeteer.
¿Qué es Puppeteer?
Puppeteer es un marco de vanguardia que permite a los testers realizar pruebas de navegadores headless con Google Chrome. Con las pruebas de Puppeteer, los testers pueden ejecutar comandos de JavaScript para interactuar con páginas web, incluyendo acciones como hacer clic en enlaces, completar formularios y enviar botones.
Desarrollado por Google, Puppeteer es una biblioteca de Node.js que permite un control fluido de Chrome en modo headless a través del Protocolo DevTools. Proporciona una serie de APIs de alto nivel que facilitan las pruebas automatizadas, el desarrollo de características de sitios web, la depuración, la inspección de elementos y el análisis de rendimiento.
Con Puppeteer, puedes usar (navegador headless) Chromium o Chrome para abrir sitios web, completar formularios, hacer clic en botones, extraer datos y realizar generalmente cualquier acción que un humano podría realizar al usar una computadora. Esto hace que Puppeteer sea una herramienta realmente poderosa para el raspado de web, pero también para automatizar flujos de trabajo complejos en la web. Tener un claro entendimiento de Puppeteer y sus capacidades es invaluable para testers y desarrolladores en el entorno actual de desarrollo web.
¿Cuáles son las ventajas de utilizar Puppeteer para el raspado de web?
Axios y Cheerio son excelentes opciones para el raspado con JavaScript. Sin embargo, esto plantea dos problemas: rastrear contenido dinámico y software anti- raspado. Como Puppeteer es un navegador headless, no tiene problemas para raspado contenido dinámico.
También Puppeteer ofrece una serie de ventajas significativas para el raspado de web:
-
Automatización de navegadores headless: Con Puppeteer, puedes controlar un navegador Chrome en modo headless de forma programática, lo que permite automatizar acciones del navegador como hacer clic, desplazarse, completar formularios y extraer datos sin una ventana de navegador visible.
-
Funcionalidad completa de Chrome y manipulación del DOM: Puppeteer proporciona acceso a la funcionalidad completa de Chrome, lo que lo hace adecuado para raspado de sitios web modernos con contenido basado en JavaScript. Puedes interactuar fácilmente con elementos de la página, modificar atributos y realizar acciones como hacer clic en botones o enviar formularios.
-
Simulación de interacciones de usuarios y captura de eventos: Puppeteer te permite simular interacciones de usuarios y capturar solicitudes y respuestas de red. Esto permite raspado de páginas que requieren entrada de usuario o contenido cargado dinámicamente a través de solicitudes AJAX o WebSocket.
-
Capacidad de rendimiento y depuración: El motor Chrome optimizado de Puppeteer garantiza un raspado eficiente, y su integración con DevTools ofrece capacidades robustas de depuración y pruebas. Puedes depurar páginas web, registrar mensajes de consola, trazar actividad de red y analizar métricas de rendimiento.
En las siguientes guías, exploraré el proceso de raspado de web utilizando Puppeteer y Node.js, junto con la integración de una solución de resolución de CAPTCHA de vanguardia, CapSolver, para superar uno de los principales desafíos encontrados durante el raspado de web.
Código de bonificación
Un código de bonificación para soluciones de CAPTCHA top; CapSolver : WEBS. Después de canjearlo, obtendrás un bono adicional del 5% después de cada recarga, ilimitado

Cómo resolver CAPTCHA en Puppeteer usando CapSolver mientras se raspa web
El objetivo será resolver el CAPTCHA ubicado en recaptcha-demo.appspot.com usando CapSolver.
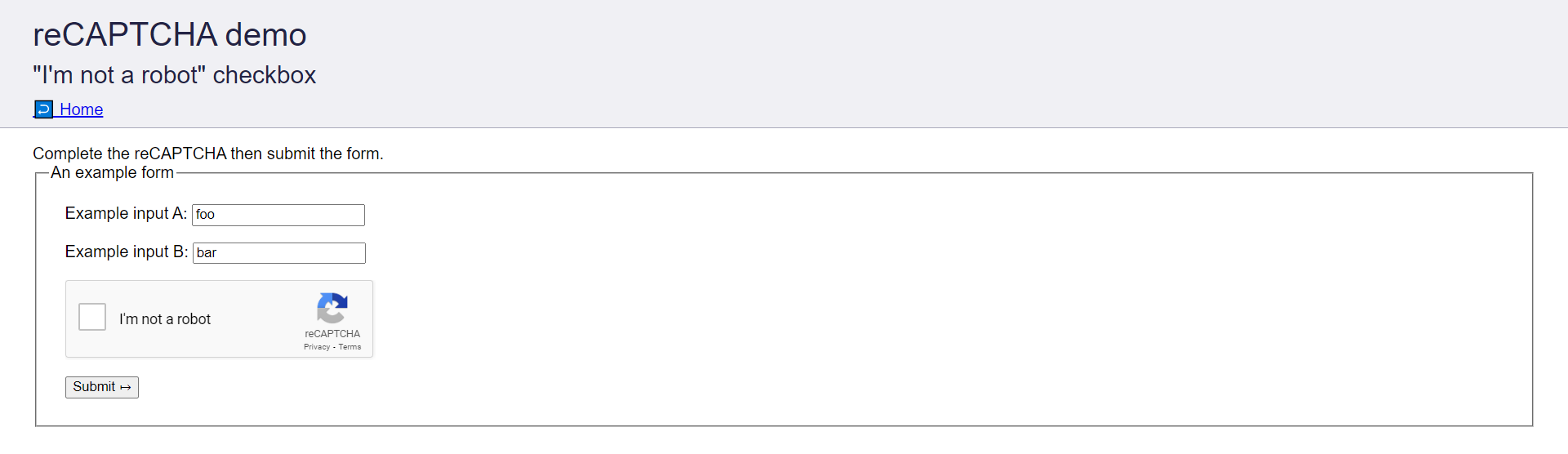
Durante el tutorial, tomaremos los siguientes pasos para resolver el CAPTCHA anterior:
- Instalar las dependencias requeridas.
- Encontrar la clave del sitio del Formulario CAPTCHA.
- Configurar CapSolver.
- Resolver el CAPTCHA.
Instalar dependencias requeridas
Para comenzar, necesitamos instalar las siguientes dependencias para este tutorial:
- capsolver-python: El SDK oficial de Python para una integración sencilla con la API de CapSolver.
- pyppeteer: pyppeteer es una versión de Python de Puppeteer.
Instale estas dependencias ejecutando el siguiente comando:
python -m pip install pyppeteer capsolver-pythonAhora, cree un archivo llamado main.py donde escribiremos el código de Python para resolver CAPTCHAS.
bash
touch main.pyObtener la clave del sitio del formulario CAPTCHA
La clave del sitio es un identificador único proporcionado por Google que identifica únicamente cada CAPTCHA.
Para resolver el CAPTCHA, es necesario enviar la clave del sitio a CapSolver.
Busquemos la clave del sitio del Formulario CAPTCHA siguiendo estos pasos:
- Visite el Formulario CAPTCHA.
- Abra las herramientas de desarrollo de Chrome presionando
Ctrl/Cmd+Shift+I. - Vaya a la pestaña "Elementos" y busque
data-sitekey. Copie el valor del atributo.
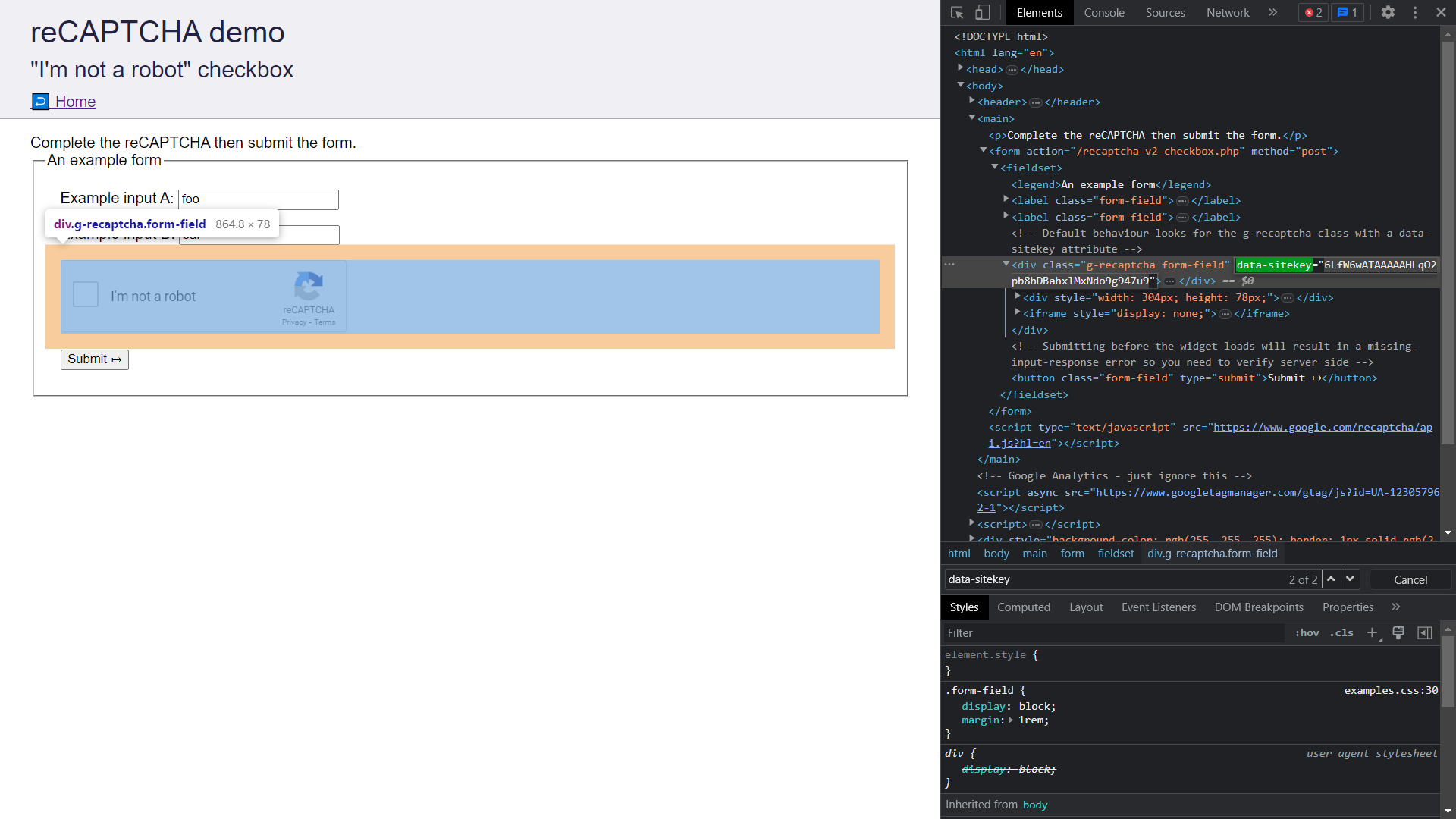
- Almacene la clave del sitio en un lugar seguro, ya que se usará en una sección posterior cuando envíe el CAPTCHA a CapSolver.
Configurar CapSolver
Para resolver CAPTCHAS usando CapSolver, necesitas crear una cuenta en CapSolver, agregar fondos a tu cuenta y obtener una clave de API. Siga estos pasos para configurar su cuenta de CapSolver:
-
Regístrese para una cuenta en CapSolver visitando CapSolver
-
Agregue fondos a su cuenta de CapSolver utilizando PayPal, Criptomonedas u otros métodos de pago listados. Tenga en cuenta que el monto mínimo de depósito es de $6 y se aplican impuestos adicionales.
-
Ahora, copie la clave de API proporcionada por CapSolver y guárdela de forma segura para su uso posterior.
Resolver el CAPTCHA
Ahora, procederemos a resolver el CAPTCHA usando CapSolver. El proceso general implica tres pasos:
- Iniciar el navegador y visitar la página del CAPTCHA usando pyppeteer.
- Resolver el CAPTCHA usando CapSolver.
- Enviar la respuesta del CAPTCHA.
Lea los siguientes fragmentos de código para entender estos pasos.
Iniciar el navegador y visitar la página del CAPTCHA:
python
# Iniciar el navegador.
browser = await launch({'headless': False})
# Cargar la página objetivo.
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)Resolver el CAPTCHA usando CapSolver:
python
# Resolver el reCAPTCHA usando CapSolver.
capsolver = RecaptchaV2Task("YOUR_API_KEY")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
# Obtener el código de reCAPTCHA resuelto.
code = result.get("gRecaptchaResponse")Establecer el CAPTCHA resuelto en el formulario y enviarlo:
python
# Establecer el código de reCAPTCHA resuelto en el formulario.
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
# Enviar el formulario.
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()Unir todo
A continuación, se muestra el código completo para el tutorial, que resolverá el CAPTCHA usando CapSolver.
python
import asyncio
from pyppeteer import launch
from capsolver_python import RecaptchaV2Task
# El siguiente código resuelve un desafío reCAPTCHA v2 usando CapSolver.
async def main():
# Iniciar Navegador.
browser = await launch({'headless': False})
# Cargar la página objetivo.
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)
# Resolver el reCAPTCHA usando CapSolver.
print("Resolviendo captcha")
capsolver = RecaptchaV2Task("YOUR_API_KEY")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
# Obtener el código de reCAPTCHA resuelto.
code = result.get("gRecaptchaResponse")
print(f"ReCAPTCHA resuelto con éxito. El código de resolución es {code}")
# Establecer el código de reCAPTCHA resuelto en el formulario.
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
# Enviar el formulario.
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()
# Pausar la ejecución para que pueda ver la pantalla después de la presentación antes de cerrar el controlador
input("Envío de CAPTCHA Exitoso. Presione enter para continuar")
# Cerrar Navegador.
await browser.close()
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())Pegue el código anterior en su archivo main.py. Reemplace YOUR_API_KEY con su clave de API y ejecute el código.
Observará que el CAPTCHA se resolverá y será recibido con una página de éxito.
Cómo resolver CAPTCHA en NodeJS usando CapSolver mientras se raspa web
Requisitos previos
- Proxy (Opcional)
- Node.JS instalado
- Clave de API de Capsolver
Paso 1: Instalar los paquetes necesarios
Ejecute los siguientes comandos para instalar los paquetes requeridos:
python
npm install axiosCódigo de Node.JS para resolver reCaptcha v2 sin proxy
Aquí hay un script de muestra en Node.JS para realizar la tarea:
js
const axios = require('axios');
const PAGE_URL = ""; // Reemplazar con su Sitio Web
const SITE_KEY = ""; // Reemplazar con su Sitio Web
const CLIENT_KEY = ""; // Reemplazar con su Clave de API de CAPSOLVER
async function createTask(payload) {
try {
const res = await axios.post('https://api.capsolver.com/createTask', {
clientKey: CLIENT_KEY,
task: payload
});
return res.data;
} catch (error) {
console.error(error);
}
}
async function getTaskResult(taskId) {
try {
success = false;
while(success == false){
await sleep(1000);
console.log("Obteniendo resultado de tarea para ID de tarea: " + taskId);
const res = await axios.post('https://api.capsolver.com/getTaskResult', {
clientKey: CLIENT_KEY,
taskId: taskId
});
if( res.data.status == "ready") {
success = true;
console.log(res.data)
return res.data;
}
}
} catch (error) {
console.error(error);
return null;
}
}
async function solveReCaptcha(pageURL, sitekey) {
const taskPayload = {
type: "ReCaptchaV2TaskProxyless",
websiteURL: pageURL,
websiteKey: sitekey,
};
const taskData = await createTask(taskPayload);
return await getTaskResult(taskData.taskId);
}
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function main() {
try {
const response = await solveReCaptcha(PAGE_URL, SITE_KEY );
console.log(`Token recibido: ${response.solution.gReCaptcharesponse}`);
}
catch (error) {
console.error(`Error: ${error}`);
}
}
main();👀 Más información
Conclusión:
En este tutorial, hemos aprendido cómo resolver CAPTCHAS usando CapSolver mientras realizamos raspado de web con Puppeteer y Node.js. Al aprovechar la API de CapSolver, podemos automatizar el proceso de resolución de CAPTCHAS y hacer que las tareas de raspado de web sean más eficientes y confiables. Recuerde cumplir con los términos y condiciones de los sitios web que raspe y use el raspado de web de manera responsable.
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.

Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.

