CAPTCHA IA impulsada por grandes modelos: ¿Por qué es más adecuada para escenarios empresariales?

Aloísio Vítor
Image Processing Expert

La tecnología CAPTCHA está siendo rediseñada por las capacidades de reconocimiento visual de la IA. Muchos aún ven la CAPTCHA como un "componente" simple, pero en entornos de procesamiento automatizado reales, ha evolucionado hacia un avance continuo entre la tecnología de reconocimiento visual de la IA y los mecanismos de verificación.
I. Evolución de CAPTCHA: De OCR a reconocimiento visual de IA
1. Primera generación: La era del OCR (2000-2010)
Contexto técnico
Los problemas principales enfrentados por Internet temprana eran el spam y el abuso de programas automatizados. reCAPTCHA surgió como un sistema pionero, con una filosofía de diseño simple: aprovechar las ventajas humanas en el reconocimiento visual para crear barreras difíciles de superar para las máquinas.
Implementaciones típicas
- Cadenas de caracteres en inglés distorsionados (4-6 dígitos)
- Líneas de interferencia añadidas, ruido, texturas de fondo
- Interferencia de contraste de color
Evolution of Automated Recognition Technology
| Fase | Método técnico | Eficiencia de reconocimiento |
|---|---|---|
| 2003-2005 | OCR tradicional (Tesseract) + corrección por reglas | 30-50% |
| 2005-2008 | Preprocesamiento de imágenes (denoising, binarización, segmentación) + SVM | 60-80% |
| 2008-2010 | Redes neuronales convolucionales (versión mejorada de LeNet-5) | 90%+ |
Evento histórico
En 2008, una investigación publicada en Science demostró que las tasas de reconocimiento de máquinas para CAPTCHAs basadas en texto estaban mejorando rápidamente. Esto impulsó directamente el nacimiento de la segunda generación de CAPTCHAs.
Insight principal: Conjuntos de caracteres fijos + reglas de distorsión limitadas = conjuntos de datos recopilables = fácilmente reconocidos por sistemas automatizados.
2. Segunda generación: Desafíos de comportamiento + imagen (2010-2020)
Cambio de paradigma
Los diseñadores de CAPTCHA se dieron cuenta de que simplemente aumentar la dificultad de reconocimiento también afectaba negativamente la experiencia del usuario real. Se volvió necesario introducir "capacidades exclusivas de humanos" - comprensión semántica y patrones de comportamiento.
Análisis de tres sistemas comerciales principales
reCAPTCHA (Google)
- v2 (2014): casilla "No soy un robot" + análisis de riesgo invisible
- Tecnología principal: Motor de análisis de riesgo, basado en 100+ señales (Cookies, historial de dispositivos, movimientos sutiles del mouse, tiempo de interacción en la página)
- Desafíos de imagen: Escenas del mundo real extraídas de Google Street View (semáforos, cruces de peatones, autobuses), usando etiquetado por crowdsourcing para entrenar simultáneamente modelos de conducción autónoma
GCaptcha (Intuition Machines)
- Posicionamiento diferenciado: Enfoque en privacidad, afirma que no rastrea datos personales de los usuarios
- Características técnicas: Arquitectura de verificación distribuida, imágenes de desafío de los propios conjuntos de datos del cliente, formando un modelo de negocio "verificación como etiquetado"
- Diseño de verificación: Ajuste dinámico de dificultad, conmutación en tiempo real de tipos de desafío según la presión de procesamiento automatizado
GeeTest
- Innovación principal: Verificación de deslizamiento + restauración de rompecabezas, transformando "reconocimiento" en "operación"
- Recopilación de datos de comportamiento: Secuencias de coordenadas de trayectoria (normalmente 50-200 puntos), curvas de velocidad, cambios de aceleración, eventos táctiles (móvil)
- Dimensiones de control de riesgo: No solo determina pasar/fallar, sino que también genera un "puntaje de confianza humana" para toma de decisiones a nivel empresarial
Desarrollo de la tecnología de procesamiento automatizado
| Tipo de automatización | Método técnico | Respuesta del verificador |
|---|---|---|
| Reconocimiento de imágenes automatizado | Detección de objetos (YOLO/Faster R-CNN) + segmentación semántica | Generación de imágenes dinámicas, muestras adversarias |
| Simulación de trayectoria de deslizamiento | Simulación de motor físico (curvas de Bézier, inyección de ruido) | Análisis de series temporales, reconocimiento biométrico |
| Procesamiento de plataformas de crowdsourcing | Plataformas de crowdsourcing (costo $0.5-2/mil) | Límite de velocidad, análisis de correlación, sistemas de reputación |
| Automatización de navegadores | Selenium, Puppeteer, Playwright | Detección de huella digital del navegador, reconocimiento de características automatizadas |
Desafíos principales
La suposición principal de los sistemas de segunda generación era que los programas automatizados no podían simular el comportamiento humano a gran escala. Sin embargo, con el desarrollo del aprendizaje profundo, esta suposición está siendo desafiada:
- Generación de trayectoria: GANs pueden aprender las características dinámicas de los movimientos del mouse reales
- Comprensión de imágenes: Avances en Transformadores de visión (ViT) en ImageNet han acercado la visión de máquinas al nivel humano.
- Huella digital del navegador: Las técnicas de randomización de huellas de marcos automatizados están volviéndose cada vez más sofisticadas
Insight principal: Cualquier desafío fijo, sin importar lo ingenioso que esté diseñado, es esencialmente un "examen con respuestas estándar". Mientras haya respuestas estándar, pueden ser recopiladas, aprendidas y procesadas finalmente por programas automatizados.
II. Desarrollo y desafíos de la tecnología de reconocimiento visual de IA
1. Sistema industrializado para reconocimiento automatizado
El reconocimiento automatizado de CAPTCHA moderno ha formado un sistema industrializado completo con pilas tecnológicas altamente especializadas:
Capa de datos
- Sistemas de recolección: Grupos distribuidos de rastreadores, recopilando desafíos de sitios objetivo 24/7
- Fábricas de etiquetado: Equipos de etiquetado de bajo costo, o herramientas de etiquetado semiautomáticas (asistidas por SAM)
- Aumento de datos: Rotación, recorte, transformación de color, ruido adversarial para ampliar la diversidad del conjunto de entrenamiento
Capa de modelo
| Tipo de tarea | Arquitectura de modelo | Referencia de implementación de código abierto |
|---|---|---|
| Reconocimiento de caracteres | CRNN + CTC | PaddleOCR, EasyOCR |
| Detección de objetos | YOLOv8, RT-DETR | Ultralytics |
| Clasificación de imágenes | ViT, ConvNeXt | Hugging Face Transformers |
| Trayectoria de deslizamiento | Seq2Seq, Modelo de difusión | Soluciones de código abierto de la comunidad |
| Comprensión multimodal | CLIP, LLaVA | CLIP de OpenAI, Qwen-VL de Alibaba |
Capa de ingeniería
- Optimización de inferencia: TensorRT, ONNX Runtime, OpenVINO para respuestas en milisegundos
- Arquitectura de servicio: Orquestación de Kubernetes, escalabilidad automática, soportando solicitudes de alta concurrencia
- Bypass automatizado: Aleatorización de huella digital del navegador, grupos de proxies IP, simulación de ritmo de comportamiento
Análisis del fenómeno OpenClaw
El proyecto recientemente popular OpenClaw representa la tendencia de la "democratización de herramientas de reconocimiento visual de IA":
- Bajo umbral: Modelos preentrenados + archivos de configuración pueden apuntar a objetivos específicos
- Modularidad: Desacoplamiento de recolección de datos, entrenamiento de modelos, servicios de inferencia y presentación de resultados
- Impulsado por la comunidad: Compartir muestras de reconocimiento, pesos de modelos y soluciones técnicas iterativas
Impacto en empresas: Lo que antes requería equipos especializados de seguridad para implementar reconocimiento automatizado ahora puede ser adoptado rápidamente por desarrolladores ordinarios. Esto eleva significativamente los requisitos técnicos para los mecanismos de verificación de CAPTCHA.
2. Mecanismos de verificación: De "desafíos estáticos" a "control de riesgo dinámico"
Cambio de paradigma: Aumento del modelado de comportamiento
La transformación principal de los sistemas de CAPTCHA empresariales es de "verificar la corrección de la respuesta" a "evaluar la autenticidad del comportamiento". Esto es análogo a la evolución del control de riesgos financieros de "motores de reglas" a "tarjetas de puntuación de aprendizaje automático".
Sistema de huella comportamental multidimensional
| Dimensión de recolección de datos | Indicadores técnicos | Método de análisis de IA |
|---|---|---|
| Dinámica del mouse | Densidad de puntos de trayectoria, curvas de velocidad, distribución de aceleración, cambios de ángulo | Modelado de series temporales LSTM/Transformer, comparación con distribución base de usuarios reales |
| Interacción del teclado | Intervalos de pulsación de teclas (Keydown-Keyup), patrones de combinación de teclas, comportamientos de corrección (frecuencia de retroceso) | Análisis de ritmo, detección de características de intervalo uniforme de herramientas automatizadas |
| Eventos táctiles (móvil) | Valor de presión, área de contacto, inercia de deslizamiento, patrones de multitáctil | Reconocimiento biométrico, distinguir dedos humanos de brazos robóticos/simuladores |
| Atención visual | Seguimiento de ojos (si se permite), patrones de desplazamiento de página, momento de enfoque en elementos | Análisis de mapa de calor de atención, detección de patrones de navegación no humanos |
| Tiempo de reacción cognitivo | Retraso desde la presentación del desafío hasta la primera interacción, distribución del tiempo de decisión | Pruebas estadísticas, las herramientas automatizadas suelen ser demasiado rápidas o lentas |
| Contexto ambiental | Postura del dispositivo (giróscopo), estado de la batería, fluctuaciones de latencia de red | Detección de anomalías, identificación de máquinas virtuales/simuladores/teléfonos en la nube |
Papel clave de modelos grandes
Los motores de reglas tradicionales luchan para manejar secuencias de comportamiento de alta dimensión y no lineales. Los modelos grandes (especialmente arquitectura Transformer) traen avances:
- Aprendizaje de representación: Codificar secuencias de comportamiento crudo en embeddings de baja dimensión para capturar patrones profundos
- Aprendizaje transferido: Preentrenamiento con grandes datos de comportamiento no supervisados, fine-tuning con muestras pequeñas para adaptarse a nuevos escenarios
- Fusión multimodal: Procesamiento unificado de imágenes, características de series temporales y categóricas para optimización de extremo a extremo
III. ¿Por qué el reconocimiento visual de CAPTCHA con modelos grandes es más adecuado para escenarios empresariales?
Volantín de datos: En la era de la dominancia de datos, la ventaja competitiva única de las empresas
Comparación de datos de reconocedor automatizado vs. verificador
| Tipo de datos | Disponible para reconocedor automatizado | Realmente propiedad del verificador empresarial | Valor estratégico |
|---|---|---|---|
| Casos de reconocimiento exitoso | ✅ Muestras limitadas (requiere recolección costosa) | ✅ Casos fallidos masivos (registros de reconocimiento automatizado) | Entrenar modelos de "reconocimiento de patrones automatizados" |
| Comportamiento de usuario real | ❌ Difícil de obtener a gran escala | ✅ Tráfico completo de negocios | Construir "bases de comportamiento humano" |
| Huellas de herramientas automatizadas | ❌ Descubiertas pasivamente | ✅ Detección proactiva + recolección de cebo | Identificar características de marcos automatizados |
| Datos correlacionados de series temporales | ❌ Perspectiva de punto único | ✅ Vista global a través de líneas de negocio | Análisis de correlación, identificar comportamiento automatizado organizado |
Bucle de aprendizaje continuo
[Tráfico de producción] → [Recolección de datos de comportamiento] → [Ingeniería de características] → [Inferencia del modelo] → [Puntuación de riesgo]
↑ ↓
[Actualización del modelo] ← [Evaluación del rendimiento] ← [Retroalimentación de etiquetado] ← [Decisión empresarial]
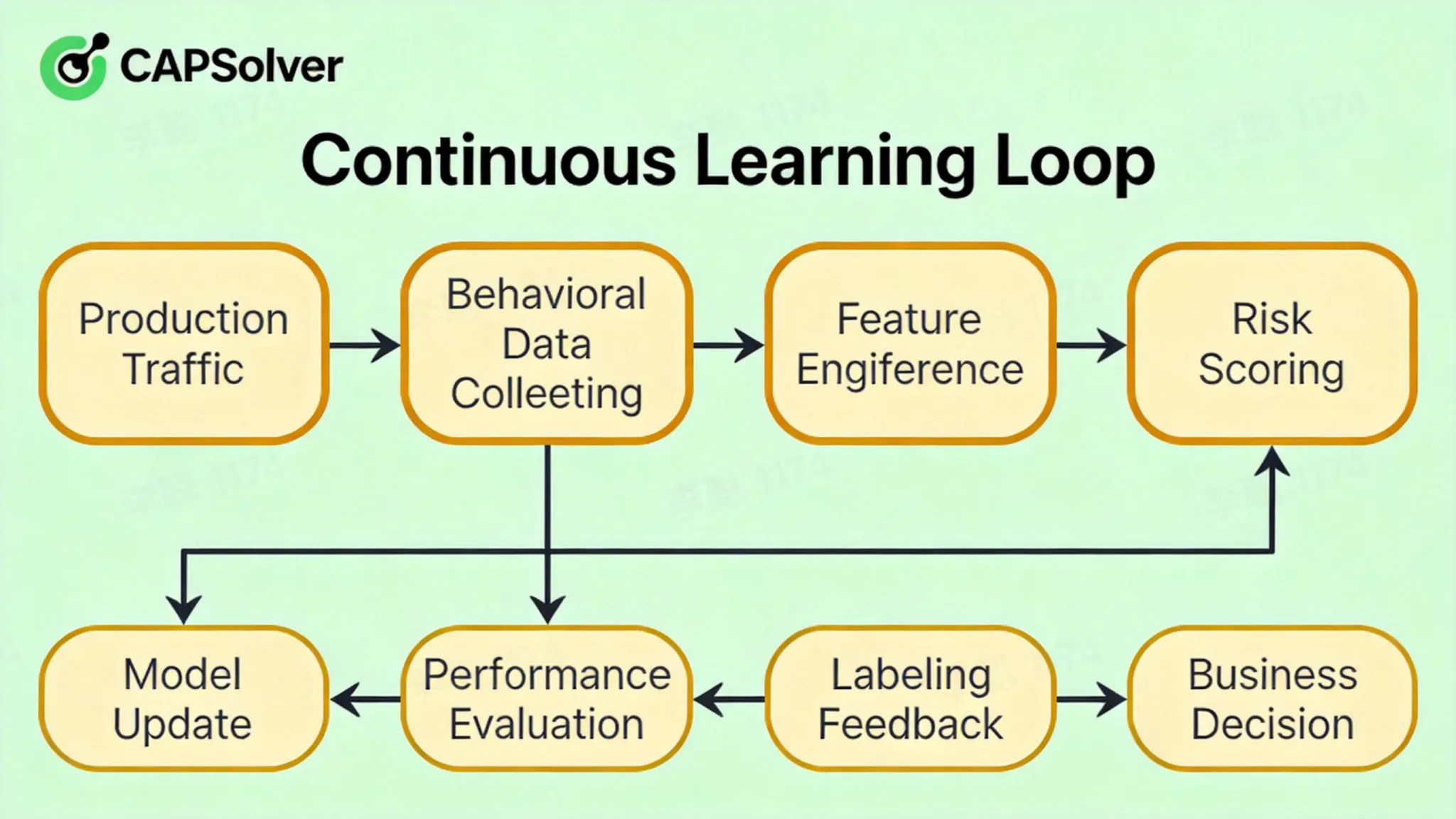
- Aprendizaje en línea: Los parámetros del modelo se ajustan en tiempo real con nuevos datos, sin requerir reentrenamiento completo
- Aprendizaje activo: Seleccionar inteligentemente muestras de alto valor para etiquetado manual, optimizar el ROI de etiquetado
- Entrenamiento adversarial: Mejorar la robustez utilizando muestras de reconocimiento automatizado como ejemplos negativos
Integración profunda con control de riesgos empresarial
| Escenario de integración | Implementación técnica | Valor empresarial |
|---|---|---|
| Protección de inicio de sesión | Puntuación CAPTCHA + huella digital del dispositivo + reputación de IP → puntuación de riesgo unificada | Intercepta eficazmente inicios de sesión automatizados, reduce falsos positivos |
| Antifraude en registro | Comportamiento de verificación anormal → activar verificación secundaria de teléfono/correo electrónico | Identificar registros en masa, proteger la calidad del usuario |
| Actividades de marketing | Escenarios de ventas flash, reconocimiento humano-máquina en tiempo real → límite dinámico | Prevenir captura automatizada, proteger los derechos de usuarios reales |
| Seguridad de pagos | Verificación obligatoria antes de operaciones de alto riesgo + revisión de comportamiento | Bloquear transacciones fraudulentas automatizadas, reducir pérdidas de activos |
Para más insights sobre automatización moderna, consulte nuestra guía sobre por qué la automatización web sigue fallando en CAPTCHA
IV. Ruta de evolución de implementación privada
Viaje típico de experimento a producción
Fase uno: Prueba de concepto (PoC, 1-2 meses)
- Escenario: El equipo de seguridad evalúa las vulnerabilidades de CAPTCHAs existentes, o el negocio se queja de mala experiencia de verificación
- Acción: Simular reconocimiento automatizado usando herramientas como OpenClaw, cuantificar costo y tasa de éxito de reconocimiento
- Salida: Informe de viabilidad de reconocimiento automatizado, estimación preliminar de ROI
Fase dos: Implementación piloto (Pilot, 3-6 meses)
- Pila tecnológica: Modelos de código abierto (YOLO + ResNet) + equipo de etiquetado propio
- Desafíos principales:
- Mala generalización del modelo, falla rápida cuando aparecen nuevos tipos de automatización
- Alta latencia de inferencia, afectando la experiencia del usuario
- Falta de dimensiones de análisis de comportamiento, dependiendo solo del reconocimiento de imágenes
- Decisión clave: Si invertir recursos en construir una plataforma MLOps o comprar una solución comercial
Fase tres: Producción a gran escala (Production, 6-12 meses)
- Mejora de arquitectura:
- Capa de inferencia: Servidor de inferencia Triton + TensorRT, optimización de utilización de GPU
- Capa de datos: Almacenamiento en tiempo real de características (Redis/Flink) + lago de datos offline (Iceberg/Delta Lake)
- Capa de entrenamiento: Kubeflow/MLflow para gestionar experimentos y versiones de modelos
- Desarrollo organizacional: Establecer un equipo dedicado de seguridad de IA (ingenieros de algoritmos + ingenieros de backend + analistas de seguridad)
Fase cuatro: Operación de plataforma (Platform, 1-2 años)
- Capacidad de salida: Servicio CAPTCHA como middleware de seguridad interno, apoyando múltiples líneas de negocio
- Integración ecosistémica: Vinculación con inteligencia de amenazas, SOC (Centro de Operaciones de Seguridad), sistemas SIEM
- Verificación continua: Establecer mecanismos de verificación de equipo rojo/equipo azul, simular regularmente ejercicios de reconocimiento automatizado de nivel APT
V. Empresarial vs. No empresarial: Comparación integral
| Dimensión de comparación | Soluciones no empresariales (OpenClaw / OCR tradicional) | CAPTCHA de IA visual empresarial |
|---|---|---|
| Complejidad de implementación | ✅ Simple, inicio con Docker | ❌ Complejo, requiere soporte de plataforma MLOps |
| Costo inicial | ✅ Bajo, GPU única suficiente | ❌ Alto, requiere clúster + equipo de etiquetado |
| Actualizaciones de modelo | ❌ Pesos fijos, fácilmente objetivo de reconocimiento automatizado | ✅ Aprendizaje en línea, evolución continua |
| Análisis de comportamiento | ❌ Reconocimiento de imagen puro, sin dimensión de comportamiento | ✅ Fusión multimodal, diferenciación precisa entre humano y máquina |
| Enlace de control de riesgo | ❌ Sistema aislado, sin conciencia contextual | ✅ Integración profunda con WAF, huellas digitales de dispositivos |
| Alta disponibilidad | ❌ Punto único de despliegue, sin garantía de SLA | ✅ Arquitectura multiactiva, escalabilidad elástica |
| Cumplimiento | ❌ Registros de auditoría débiles, cumplimiento de privacidad | ✅ Adaptación GDPR/CCPA, auditoría completa |
| Escenarios aplicables | Pequeñas y medianas empresas, pruebas internas, proyectos de corto plazo | Producción a gran escala, finanzas, comercio electrónico, asuntos gubernamentales |
VI. Forma futura: Infraestructura de control de riesgos de IA
Tendencias de la evolución tecnológica
| Dirección de evolución | Estado actual | Próximos 3-5 años |
|---|---|---|
| Método de verificación | Desafíos pasivos (el usuario debe realizar acciones) | CAPTCHA invisible, análisis de comportamiento en segundo plano |
| Arquitectura de modelo | Modelos pequeños especializados (CNN/LSTM) | Modelos grandes multimodales (arquitectura GPT-4V como ajuste fino) |
| Generación de desafíos | Banco de preguntas fijo + variaciones limitadas | Síntesis generativa en tiempo real (una pregunta por persona, cada pregunta diferente) |
| Lógica de decisión | Clasificación binaria (humano/máquina) | Puntuación de riesgo continua + orquestación dinámica de estrategias |
| Modo de verificación | Verificación de un solo punto | Aprendizaje federado colaborativo, inteligencia de reconocimiento automatizado a nivel de industria |
Espacio de imaginación para CAPTCHA generativo
Usar modelos de difusión o GANs para generar contenido de verificación en tiempo real:
- Ventajas: No hay una base de preguntas prealmacenada, los reconocedores automatizados no pueden recopilar datos de entrenamiento con anticipación
- Desafíos: Control de la calidad de la generación (evitar muestras difíciles para que los humanos las reconozcan), optimización de los costos de inferencia
- Investigación de vanguardia: Rumores de la industria sugieren que sistemas como reCAPTCHA v4 podrían incorporar tecnología generativa.
VII. Recomendaciones para tomadores de decisiones técnicas
| Dimensión de tiempo | Item de acción | Hitos clave | Objetivo |
|---|---|---|---|
| Corto plazo (1-3 meses) | Evaluación de la superficie de reconocimiento automatizado | Completar el reconocimiento automatizado simulado de OpenClaw, cuantificar la MTBF actual de CAPTCHA | Establecer conciencia del riesgo, garantizar la inversión de recursos |
| Construcción del sistema de monitoreo | Implementar reglas de detección de reconocimiento automatizado, identificar características de tráfico automatizado | De "respuesta pasiva" a "reconocimiento visible" | |
| Medio plazo (3-12 meses) | Infraestructura de datos | Construir tuberías de recolección de datos de comportamiento, acumular 10 millones de muestras etiquetadas | Tener la base de datos para entrenar modelos de producción |
| Iteración y lanzamiento del modelo | Pruebas A/B del primer modelo de aprendizaje profundo, verificar la efectividad de la defensa de reconocimiento | Demostrar la viabilidad técnica, construir confianza en el equipo | |
| Largo plazo (1-2 años) | Plataforma | El SLA del servicio CAPTCHA alcanza el 99,99%, soporta 100.000 QPS | Convertirse en una infraestructura de seguridad clave para la empresa |
| Estrategia de seguridad de IA | Integrarse en una plataforma de control de riesgos unificada, vincularse con anti-fraude | Formar un sistema de verificación de IA multidimensional |
VIII. Capabilidades de reconocimiento visual de IA de CapSolver
Como proveedor de tecnología enfocado en ofrecer servicios de reconocimiento visual de IA eficientes y estables, CapSolver posee ventajas significativas en el reconocimiento de CAPTCHA de imagen y capacitación de solucionadores personalizados:
- Soporta diversos CAPTCHAs basados en imágenes: CapSolver ha optimizado profundamente sus algoritmos de reconocimiento para CAPTCHAs de imagen principales y complejos, soportando tipos incluyendo pero no limitados a clasificación de imágenes y detección de objetos.
- Adaptación rápida a nuevos CAPTCHAs: Basado en tecnología avanzada de modelos visuales grandes, CapSolver puede lograr aprendizaje por pocos ejemplos y ajuste rápido, ayudando a las empresas a adaptarse rápidamente a nuevos desafíos de CAPTCHA que aparecen en el mercado.
- API de grado empresarial y capacidad de procesamiento de alta concurrencia: CapSolver proporciona interfaces de API de grado empresarial estables y altamente disponibles que soportan solicitudes de alta concurrencia, asegurando respuestas en milisegundos para satisfacer las necesidades de recolección de datos a gran escala de las empresas.
- Capacitación de solucionadores personalizados: Para necesidades específicas de reconocimiento visual de las empresas, CapSolver ofrece servicios de capacitación de modelos personalizados, ayudando a las empresas a construir soluciones de reconocimiento de CAPTCHA exclusivas y de alta precisión.
IX. Lectura adicional y referencias de la industria
| Tipo de recurso | Contenido recomendado | Valor |
|---|---|---|
| Proyectos de código abierto | OpenClaw & CapSolver | Entender las pilas de tecnología de reconocimiento automatizado |
| Informes de la industria | Gartner Market Guide for Fraud Detection | Referencia para la selección de soluciones comerciales |
X. Conclusión
Con el rápido avance de la tecnología de IA, el reconocimiento de CAPTCHA ya no es un desafío técnico simple, sino una capacidad crítica para que las empresas adquieran datos públicos y garanticen la continuidad de los negocios en la era digital. Los modelos grandes visuales de IA, con su excelente comprensión de escenas complejas, poderosas capacidades de generalización y escalabilidad eficiente de modelos, proporcionan soluciones sin precedentes para el reconocimiento automatizado a nivel empresarial. CapSolver, con su profunda acumulación en el reconocimiento visual de IA y capacidades de servicios de grado empresarial, se compromete a ser su socio confiable, ayudando a las empresas a abordar eficientemente y de manera cumplidora diversos desafíos de CAPTCHA y enfocarse en crear valor de negocio principal.
XI. Preguntas frecuentes (FAQ)
P1: ¿Cómo difieren los modelos visuales grandes (LVMs) de los CNN tradicionales en el reconocimiento de CAPTCHA?
A1: A diferencia de los CNN tradicionales que dependen de la extracción de características locales, los LVMs utilizan arquitecturas como Vision Transformers (ViT) para capturar contexto global y significado semántico. Esto les permite comprender escenas complejas y generalizar a nuevos estilos de CAPTCHA no vistos con mucha mayor precisión y con muy poca formación adicional.
P2: ¿Qué es el "aprendizaje por pocos ejemplos" en el contexto de solucionadores de CAPTCHA basados en IA?
A2: El aprendizaje por pocos ejemplos se refiere a la capacidad de un modelo de IA preentrenado para adaptarse a una nueva tarea (como un nuevo tipo de CAPTCHA) utilizando solo un muy pequeño número de ejemplos etiquetados. Esta es una ventaja clave de los grandes modelos, permitiendo una implementación rápida contra mecanismos de verificación en evolución.
P3: ¿Qué tipos de CAPTCHAs de imagen soporta CapSolver?
A3: CapSolver ha optimizado profundamente sus algoritmos de reconocimiento para CAPTCHAs de imagen principales y complejos, soportando tipos incluyendo pero no limitados a clasificación de imágenes y detección de objetos.
Consulte la solución de imagen: Imagetotext & VisionEngine
P4: ¿Cómo garantiza CapSolver la precisión y estabilidad del reconocimiento?
A4: CapSolver se basa en tecnología avanzada de modelos visuales grandes, optimizando continuamente el rendimiento del modelo a través de bucles de aprendizaje continuo y mecanismos de aprendizaje en línea. Además, proporcionamos APIs de grado empresarial y una arquitectura de alta concurrencia, asegurando respuestas en milisegundos y una disponibilidad del 99,9%.
P5: ¿Soporta CapSolver el despliegue privado?
A5: CapSolver ofrece opciones de despliegue flexibles, incluyendo servicios en la nube y despliegue privado, para satisfacer las necesidades de seguridad y cumplimiento de diferentes empresas. Las soluciones de despliegue privado pueden personalizarse según la arquitectura y recursos específicos de la empresa.
Ver más
AIMar 27, 2026
Elevando la Automatización Empresarial: Infraestructura Potenciada por LLM para un Reconocimiento de CAPTCHA Sin Problemas & Eficiencia Operativa
Descubre cómo la infraestructura de automatización de IA impulsada por LLM revoluciona el reconocimiento de CAPTCHA, mejorando la eficiencia de los procesos de negocio y reduciendo la intervención manual. Optimiza tus operaciones automatizadas con soluciones avanzadas de verificación.

AIMar 27, 2026
Recopilación de Datos a Gran Escala para el Entrenamiento de GML: Resolver CAPTCHAs a Gran Escala
Aprende a escalar la recopilación de datos para el entrenamiento de modelos de lenguaje grandes resolviendo CAPTCHAs a gran escala. Descubre estrategias automatizadas para construir conjuntos de datos de alta calidad para modelos de IA.
