Elevando la Automatización Empresarial: Infraestructura Potenciada por LLM para un Reconocimiento de CAPTCHA Sin Problemas & Eficiencia Operativa

Adélia Cruz
Neural Network Developer

En el entorno en constante evolución de la transformación digital, los CAPTCHAs han pasado de ser verificaciones de seguridad básicas a filtros de procesos empresariales sofisticados. Aunque esenciales para la seguridad, suelen introducir fricción significativa, creando una "brecha de eficiencia" en los flujos de trabajo automatizados. Globalmente, las empresas dedican colectivamente aproximadamente 500.000 horas diarias a la resolución manual de CAPTCHA, obstaculizando la ejecución fluida de operaciones empresariales críticas.
Esta intervención manual conlleva varios desafíos:
- Altos costos operativos: La dependencia de operadores humanos para la resolución de CAPTCHA escala mal con el aumento del volumen empresarial.
- Interrupciones en el proceso: Los scripts automatizados frecuentemente se detienen al encontrar CAPTCHA, rompiendo la continuidad de los procesos empresariales.
- Presiones de privacidad y técnicas: Los estándares de privacidad en evolución plantean desafíos para los métodos tradicionales de verificación basados en comportamiento, exigiendo soluciones más transparentes y eficientes.
Nuestra visión: Creemos que los CAPTCHA deben potenciar, no impedir, el crecimiento empresarial. Al proporcionar una infraestructura de automatización de IA de vanguardia para la reconocimiento automatizado de CAPTCHA, nos comprometemos a ayudar a las empresas a reducir significativamente la intervención manual, optimizar los costos operativos y elevar la eficiencia del ecosistema de sus procesos empresariales principales.
📈 I. La evolución de la verificación: De reglas estáticas a sinergia inteligente
El camino de la tecnología de verificación en los últimos 25 años refleja una búsqueda constante de equilibrio entre seguridad y experiencia del usuario. La aparición de Modelos de Lenguaje a Gran Escala (LLM) marca un cambio pivotal, abriendo una nueva era de procesamiento inteligente y sinérgico.
| Etapa | Tecnología principal | Lógica de procesamiento | Impacto empresarial |
|---|---|---|---|
| V1 (2000s) | Caracteres distorsionados | Reconocimiento OCR básico | Vulnerable a automatización básica, alta eficiencia inicial |
| V2 (2014s) | Selección de imágenes | Detección y clasificación de objetos | Requiere etiquetado manual extensivo, aumenta costos operativos |
| V3 (2024s) | Análisis de comportamiento | Puntuación de riesgo y fingerprinting | Enfrenta preocupaciones de privacidad, desafiante para automatización eficiente |
| V4 (2026+) | Sinergia LLM | Comprensión semántica y generación | Alta fiabilidad, eficiencia mejorada, automatización completa |
Insight clave: A medida que los CAPTCHA se dirigen hacia direcciones semánticas y multimodales, las soluciones basadas en reglas tradicionales resultan insuficientes. Las empresas requieren una infraestructura inteligente con capacidades avanzadas de comprensión semántica para satisfacer sus necesidades de automatización. Esto es donde LLM para CAPTCHA se vuelve indispensable.
🧠 II. Potenciación de LLM: Capacidad central de la infraestructura de automatización
Integrar modelos grandes en el ecosistema de procesamiento de verificación los convierte en motores inteligentes que impulsan la eficiencia de los procesos empresariales.
En esta tendencia, algunas plataformas de infraestructura de automatización orientadas a empresas han comenzado a integrar capacidades de LLM. Por ejemplo, CapSolver ofrece servicios de procesamiento de automatización de CAPTCHA estables al integrar reconocimiento multimodal con capacidades de inferencia de modelos grandes, permitiendo a las empresas mejorar la continuidad y la eficiencia de ejecución de sus procesos empresariales sin aumentar la intervención manual.
El valor central de estas soluciones radica no en capacidades puntuales, sino en servir como infraestructura subyacente para ayudar a las empresas a mantener capacidades de automatización estables y costos controlables en un entorno de verificación en evolución.
2.1 Capacidad central 1: Motor de decisión de riesgo inteligente
La automatización tradicional suele depender de reglas rígidas if-else para el manejo de CAPTCHA, lo que conduce a sistemas fragmentados, difíciles de mantener y fáciles de evadir. La infraestructura impulsada por LLM actúa como un motor de decisión de riesgo inteligente, integrando señales diversas para un procesamiento unificado, adaptable y explicado.
Enfoque tradicional (basado en reglas):
python
# Forma tradicional
if puntuacion_riesgo_ip > 0.8 y dispositivo_nuevo == True:
tipo_captcha = "difícil"
elif puntuacion_comportamiento < 0.5:
tipo_captcha = "medio"
else:
tipo_captcha = "ninguno"Enfoque impulsado por LLM (tomada de decisiones contextual):
python
# Forma de LLM
contexto = {
"reputacion_ip": "media",
"huella_dispositivo": "dispositivo_nuevo",
"puntuacion_comportamiento": 0.65,
"frecuencia_solicitud": "alta",
"ubicacion_geografica": "anómala",
"patron_historico": "desviacion_detectada"
}
# Salida de LLM: {"nivel_riesgo": "alto", "tipo_captcha": "imagen_semantica",
# "dificultad": 0.8, "razon": "La huella del dispositivo entra en conflicto con la ubicación geográfica de la IP nueva"}Propuesta de valor:
- ✅ Reducción de falsos positivos (20%+): Minimizando interrupciones para usuarios legítimos, mejorando la experiencia del usuario.
- ✅ Decisiones explicables: Proporcionando insights auditables para operaciones de seguridad y optimización continua.
- Adaptabilidad dinámica: Ajustándose automáticamente a los desafíos de verificación en evolución y necesidades empresariales.
2.2 Capacidad central 2: Motor de verificación generativa
Los CAPTCHA tradicionales dependen de bancos de preguntas limitados, lo que los hace vulnerables al entrenamiento offline y al robo por automatización sofisticada. Utilizar inteligencia artificial generativa, incluidos modelos de difusión, crea desafíos de verificación únicos y dinámicos. Cada instancia es una creación nueva, incrementando significativamente el costo y la complejidad para cualquier intento de automatización preentrenada.
mermaid
graph TD
A[CAPTCHA tradicional] --> B{Banco de preguntas limitado}
B --> C[Vulnerable al entrenamiento offline/robo]
D[Motor de verificación generativa] --> E{LLM + Modelos de difusión}
E --> F[Instancias infinitas y únicas de CAPTCHA]
F --> G[Costo prohibitivo para automatización no autorizada]Principio central: Garantizar que el costo de generalización para automatización no autorizada exceda las ganancias potenciales de evadir la verificación.
2.3 Capacidad central 3: Análisis de secuencia de comportamiento profundo
Aunque el análisis de comportamiento tradicional podría marcar patrones simples (por ejemplo, movimientos de ratón rectos como robóticos), los LLM pueden realizar un análisis profundo de secuencias de comportamiento. Al vectorizar secuencias de operaciones del usuario y procesarlas mediante modelos Transformer, el sistema puede distinguir matices sutiles de interacciones humanas de scripts automatizados demasiado perfectos.
Flujo de análisis de secuencia de comportamiento:
mermaid
graph LR
A[Secuencia de acciones del usuario] --> B[Vectorización de características]
B --> C[Codificación Transformer]
C --> D[Puntuación de riesgo]
subgraph Acciones del usuario
E[Movimiento del ratón]
F[Posición del clic]
G[Tiempo de permanencia]
H[Desplazamiento de página]
I[Ritmo del teclado]
end
E --> A
F --> A
G --> A
H --> A
I --> A
D --> J{Juicio de LLM: "Usuario real titubeante" vs. "Script automatizado perfecto"}Esto permite al sistema diferenciar entre un "usuario real titubeante" y un "script automatizado perfecto", basándose en las "imperfecciones humanas" inherentes a las interacciones reales.
🗺️ III. Ventaja estratégica: Optimizando costos de automatización con LLM
La esencia de una automatización efectiva no es la prevención absoluta, sino hacer que el robo no autorizado sea económicamente inviable. Los LLM amplifican esta asimetría de costos, haciendo que la automatización legítima sea más eficiente y la no autorizada prohibitivamente cara.
Comparación de costos: Automatización no autorizada vs. Infraestructura inteligente
| Factor de costo | Automatización no autorizada | Infraestructura inteligente |
|---|---|---|
| Recolección de datos | Alta (para entrenamiento) | Baja (adquisición de datos de comportamiento) |
| Entrenamiento del modelo | Alta (entrenamiento iterativo) | Media (implementación de modelos generativos) |
| Generación de muestras adversarias | Alta | N/A |
| Vida útil de efectividad | Baja (el CAPTCHA se vuelve obsoleto) | Alta (actualizaciones dinámicas de estrategia) |
| Riesgo de detección | Alto | Bajo |
| Manejo de falsos positivos | N/A | Media (procesamiento de apelaciones) |
Conclusión: Los costos operativos para automatización no autorizada son significativamente más altos que los costos sostenibles de mantener infraestructura impulsada por LLM, asegurando automatización a largo plazo y robusta.
Cómo los LLM mejoran la optimización de costos:
- Aumento del costo de generalización: CAPTCHA generativos crean un espacio visual infinito, impidiendo modelos preentrenados.
- Aumento del costo de inferencia: CAPTCHA semánticos requieren razonamiento de múltiples pasos, consumiendo recursos computacionales significativos para intentos no autorizados.
- Reducción del tiempo de vida: Períodos más cortos de validez de CAPTCHA hacen que las soluciones robotizadas se vuelvan obsoletas antes de su implementación generalizada.
- Contaminación de datos: Obfuscación dinámica del tráfico real con datos de honeypot contaminan los conjuntos de datos de entrenamiento para automatización no autorizada.
🚀 IV. Perspectiva del futuro: Construyendo un ecosistema de automatización sin barreras y basado en la confianza
Imaginamos un futuro donde la verificación sea un proceso invisible y continuo, integrado sin esfuerzo en la experiencia del usuario.
4.1 Fase 1: LLM como "copiloto de eficiencia" (Actual - Futuro cercano)
En esta fase inicial, los LLM actúan como asistente inteligente, mejorando la eficiencia de las operaciones de seguridad en lugar de tomar decisiones críticas directamente. Procesan lógica de verificación compleja, reduciendo significativamente la frecuencia de intervención manual y proporcionando insights accionables a expertos humanos.
mermaid
graph TD
A[Solicitud del usuario] --> B{Sistema de verificación tradicional}
B --> C{CAPTCHA encontrado}
C --> D[LLM copiloto: Analizar CAPTCHA y contexto]
D --> E{Experto en seguridad humano: Revisión y decisión}
E --> F[Resultado de verificación]
D -- "Sugiere soluciones" --> E
E -- "Proporciona retroalimentación" --> DPrincipio clave: Los LLM actúan como copilotos, potenciando la experiencia humana para mejorar la eficiencia operativa.
4.2 Fase 2: Verificación generativa dinámica (Futuro cercano - Medio plazo)
Esta fase combina LLM con modelos generativos (como modelos de difusión) para crear CAPTCHA imposibles de preentrenar. Cada instancia de verificación es única, asegurando que cualquier éxito en el robo de una instancia no brinde ventaja para intentos posteriores. La verificación pasa de un modelo de "extracción de banco de preguntas" a "creación en tiempo real".
mermaid
graph TD
A[Acceso del usuario] --> B[LLM: Comprender el contexto de la página]
B --> C["IA generativa (difusión): Crear CAPTCHA semántico"]
C --> D[Usuario: Resolver CAPTCHA único]
D --> E[Éxito/Fracaso de verificación]
subgraph Ejemplo de CAPTCHA
F["Este artículo menciona 3 ciudades, por favor marque sus ubicaciones en el mapa."]
end
C --> FEjemplo de un CAPTCHA del futuro:
El usuario accede a una página → LLM comprende el contenido de la página → Genera una pregunta de verificación semánticamente relevante.
- "Este artículo menciona 3 ciudades; por favor, marque sus ubicaciones en el mapa."
Esto requiere comprender el contenido del artículo, conocimiento geográfico y interacción con imágenes, haciendo que el robo automatizado sea extremadamente costoso, mientras que sigue siendo manejable para usuarios humanos.
4.3 Fase 3: Motor de confianza continuo (Medio plazo - Futuro lejano)
El objetivo final es la "desaparición" de CAPTCHA explícitos, reemplazados por una evaluación continua y de fondo de confianza. Los usuarios ya no perciben un paso de verificación, ya que el sistema evalúa constantemente la confianza basándose en señales de comportamiento en tiempo real.
mermaid
graph TD
A[Usuario abre la aplicación] --> B[Segundo plano: Recopilar señales de comportamiento]
B --> C[LLM: Cálculo de puntuación de confianza en tiempo real]
C --> D{Puntuación de confianza > umbral?}
D -- Sí --> E[Operaciones sin interrupciones]
D -- No (degradación silenciosa) --> F[Funcionalidades limitadas]
D -- No (verificación explícita) --> G[Activar CAPTCHA/intervención]Experiencia hipotética de verificación en 2030:
El usuario abre la aplicación → El fondo recopila continuamente señales de comportamiento → LLM calcula la puntuación de confianza en tiempo real.
- Puntuación de confianza > umbral: Todas las operaciones se realizan sin interrupciones.
- Puntuación de confianza < umbral: Algunas funcionalidades se degradan silenciosamente.
- Puntuación de confianza << umbral: Dispara verificación explícita o intervención.
Los usuarios nunca necesitarán hacer clic en "No soy un robot", logrando una experiencia verdaderamente fluida y eficiente.
4.4 Más allá: Pioneros en el futuro de la verificación nativa de IA
También estamos explorando conceptos avanzados, como "CAPTCHA específicos de IA" – diseñados para diferenciar entre IA asistida por humanos (por ejemplo, usuarios que utilizan asistentes de IA) y scripts automatizados puros. A medida que los asistentes de IA se vuelvan comunes, esta distinción será crucial para mantener interacciones digitales justas y seguras.
⚠️ V. Ética e implementación responsable de IA
Aunque los LLM ofrecen oportunidades sin precedentes para la eficiencia, enfatizamos un enfoque responsable en la implementación de IA, priorizando la transparencia y consideraciones éticas:
mermaid
graph TD
A[Automatización impulsada por LLM] --> B{Transparencia primero}
A --> C{Control de costos}
A --> D["Red de seguridad: Intervención humana"]
B --> B1["Protección de la privacidad de los datos"]
B --> B2["Mitigación de sesgos"]
B --> B3["Análisis de explicabilidad"]
C --> C1["Inferencia de modelo optimizada"]
C --> C2["Alto ROI vs. procesamiento manual"]
D --> D1["Supervisión humana"]
D --> D2["Revisión manual para escenarios complejos"]Consideraciones clave:
- Privacidad de los datos: Garantizar que toda la recolección y procesamiento de datos cumpla con estándares globales de protección de privacidad.
- Mitigación de sesgos: Monitorear continuamente y mitigar sesgos potenciales en la toma de decisiones impulsada por LLM para asegurar equidad.
- Transparencia y explicabilidad: Proporcionar insights claros sobre cómo los LLM toman decisiones de verificación, especialmente en casos de fricción con usuarios.
- Intervención humana: Mantener mecanismos de supervisión y intervención humana en escenarios complejos o ambiguos.
Principio central: Las decisiones impulsadas por IA son primarias, con retrocesos basados en reglas y colaboración humano-IA asegurando operaciones robustas y éticas.
💡 VI. Estrategias accionables para empresas: Adoptar la automatización inteligente
Para aprovechar el poder de la automatización impulsada por LLM, las empresas pueden adoptar las siguientes estrategias:
- 📊 Evaluar el estado actual: Evaluar los sistemas de verificación existentes ante la vulnerabilidad a modelos de OCR/detección de código abierto y analizar métricas clave como tasas de falsos positivos, tasas de quejas de usuarios y tasas de éxito de automatización.
- 🧪 Piloto e iterar: Comenzar con líneas de negocio de bajo riesgo para probar soluciones de "verificación sin interrupciones" o "dificultad dinámica". Establecer marcos de pruebas A/B para cuantificar el impacto de nuevas estrategias.
- 📚 Mantenerse a la vanguardia: Monitorear avances en IA generativa (por ejemplo, modelos de difusión) y LLM multimodales para sus aplicaciones en verificación y automatización. Participar en conferencias de seguridad de la industria (por ejemplo, BlackHat, DEF CON, RSA) para mantenerse informado.
- 🗄️ Enfoque centrado en los datos: Comience a construir conjuntos de datos de alta calidad que capturen las "diferencias en el comportamiento entre humanos y máquinas". Explore el aprendizaje federado para inteligencia de datos colaborativa manteniendo la privacidad.
- 👥 Colaboración multidisciplinaria: Fomentar equipos compuestos por ingenieros de IA, investigadores de seguridad, gerentes de productos y expertos. Realizar ejercicios periódicos de red teaming internos y establecer mecanismos de compartición de conocimientos.
🎯 Conclusión: El futuro de la verificación es la eficiencia sin costuras
La historia de 25 años de CAPTCHAs revela un ciclo: creación de IA → CAPTCHA para defensa de IA → IA evita CAPTCHA → CAPTCHA se actualiza, frustrando a los humanos → Humanos entrenan IA gratis → IA se vuelve más poderosa... El auge de los modelos de lenguaje de gran tamaño (LLMs) ofrece sin embargo un cambio de paradigma.
Con una Infraestructura de Automatización de IA inteligente, la verificación trasciende ser un obstáculo. Se transforma en un "Membrana de Confianza" que envuelve de forma ininterrumpida las operaciones empresariales, detectando riesgos en silencio, ajustando dinámicamente la intensidad y logrando un equilibrio óptimo entre seguridad y experiencia del usuario.
La forma final de verificación es la "Eficiencia sin costuras". No se trata de la desaparición de la necesidad de seguridad, sino de la integración invisible de la verificación. Nuestro objetivo es garantizar que el 90% de los usuarios legítimos nunca perciban un paso de verificación, mientras que el 100% de la automatización no autorizada enfrenta costos económicamente insostenibles.
Como proveedor líder global de soluciones de Reconocimiento Automático de CAPTCHA, nos comprometemos a innovar eliminando la fricción en los procesos empresariales. Queremos construir un ecosistema más inteligente y eficiente de automatización, permitiendo a las empresas enfocarse en su crecimiento principal, libres de los desafíos de verificación.
Comience a construir un sistema de automatización más eficiente
Si está explorando cómo lograr procesos de automatización más estables y eficientes en entornos de verificación complejos, una infraestructura de automatización de IA confiable será clave.
👉 A través de CapSolver, puede:
- Lograr el reconocimiento y procesamiento automatizado de los tipos principales de CAPTCHA
- Reducir los costos de intervención manual y mejorar la continuidad del proceso
- Mantener tasas de éxito estables en entornos de verificación dinámicos
- Integrarse rápidamente con sistemas empresariales existentes
Ya sea recolección de datos, automatización del crecimiento o optimización de procesos empresariales complejos, CapSolver puede servir como capacidad subyacente para ayudarle a construir un sistema de automatización más eficiente.
🎁 Beneficios exclusivos
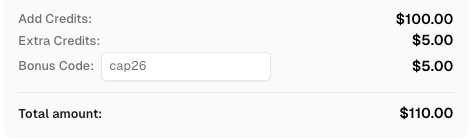
Use el código
CAP26al registrarse en CapSolver para recibir créditos adicionales!
Ver más
AIMar 27, 2026
Recopilación de Datos a Gran Escala para el Entrenamiento de GML: Resolver CAPTCHAs a Gran Escala
Aprende a escalar la recopilación de datos para el entrenamiento de modelos de lenguaje grandes resolviendo CAPTCHAs a gran escala. Descubre estrategias automatizadas para construir conjuntos de datos de alta calidad para modelos de IA.

AIMar 24, 2026
Cómo resolver CAPTCHA en OpenBrowser usando CapSolver (Guía de automatización de Agente de IA)
Resolver CAPTCHA en OpenBrowser usando CapSolver. Automatizar reCAPTCHA, Turnstile y más para agentes de IA fácilmente.

