Agentes de IA en Raspado de Web & Guía de Inteligencia Competitiva

Aloísio Vítor
Image Processing Expert

TL;DR
- Los agentes de IA son sistemas de software autónomos que planifican, ejecutan y adaptan tareas de recopilación de datos de múltiples pasos sin la necesidad constante de intervención humana.
- En la industria de los agentes de IA, el scraping web y la inteligencia competitiva son entre las áreas de aplicación más rápidamente crecientes.
- Los agentes de IA pueden monitorear precios de competidores, seguir cambios en productos y extraer datos estructurados a una escala que ningún equipo manual puede igualar.
- Los sitios web modernos implementan CAPTCHAs, limitación de tasas y capas de detección de bots que interrumpen los procesos automatizados: servicios de resolución de CAPTCHAs como CapSolver ayudan a los agentes a mantener la continuidad.
- El uso responsable y conforme de los agentes de IA para la recopilación de datos requiere respetar el robots.txt, los términos de servicio y las regulaciones aplicables de datos.
Introducción
Los agentes de IA están transformando la forma en que las empresas recopilan y actúan sobre datos externos. En la industria de los agentes de IA, dos casos de uso han pasado de experimentales a producción más rápido que casi cualquier otro: el scraping web y la inteligencia competitiva. Las empresas ahora implementan agentes que navegan de forma autónoma por la web, extraen información estructurada y la alimentan directamente en motores de precios, dashboards de mercado y informes estratégicos, todo sin que un humano haga clic en un botón. Este artículo explica qué son estos agentes, cómo funcionan, dónde aportan más valor y qué obstáculos técnicos (incluidos los CAPTCHAs) deben planearse al construir pipelines conformes y de producción.
¿Qué son los agentes de IA y por qué importan para la recopilación de datos?
Un agente de IA es un programa de software que percibe su entorno, razona sobre un objetivo y toma una secuencia de acciones para lograrlo, luego se ajusta según lo que observa. A diferencia de un script simple que sigue un camino fijo, un agente puede decidir qué página visitar a continuación, cómo manejar un cambio inesperado en el diseño y cuándo reintentar una solicitud fallida.
IBM define los agentes de IA como sistemas que combinan percepción, razonamiento y acción en un ciclo continuo. Ese ciclo es exactamente lo que los hace poderosos para la recopilación de datos: la web es desordenada, dinámica e inconsistente, y una capa de razonamiento maneja esa variabilidad mucho mejor que un raspador rígido.
La industria de los agentes de IA está creciendo a un ritmo notable. Según MarketsandMarkets, el mercado global de agentes de IA se proyecta que crezca de 7.84 mil millones de dólares en 2025 a 52.62 mil millones para 2030, a una TCEA del 46,3%. La investigación y la recopilación de datos son algunos de los tres principales casos de uso ya en implementación. El Informe del estado de los agentes de IA de LangChain encontró que el 51% de las empresas encuestadas ya tenían agentes en producción a mediados de 2024, con investigación y recolección de datos citados como la aplicación principal — por delante del servicio al cliente y la productividad personal.
Arquitectura principal: cómo operan los agentes de IA en los pipelines de scraping
Entender la arquitectura ayuda a los equipos a construir sistemas más confiables. Un pipeline típico de scraping en la industria de los agentes de IA tiene cuatro capas:
1. Capa de planificación
El agente recibe un objetivo de alto nivel — por ejemplo, "recopilar precios diarios de los 50 principales SKUs en tres sitios de competidores". Lo divide en subtareas: identificar URLs, programar solicitudes, definir esquemas de extracción. En configuraciones más avanzadas, la capa de planificación utiliza un modelo de lenguaje a gran escala (LLM) para generar un plan de ejecución paso a paso que puede revisarse durante la ejecución si cambian las condiciones.
2. Capa de ejecución
El agente envía solicitudes HTTP o controla un navegador headless (Playwright, Puppeteer, Selenium). Analiza HTML, APIs JSON o contenido JavaScript renderizado y lo mapea a un formato estructurado. La capa de ejecución debe manejar paginación, desplazamiento infinito, flujos de inicio de sesión y contenido dinámico renderizado en el lado del cliente — todos escenarios donde un raspador estático fallaría.
3. Capa de observación y adaptación
Después de cada acción, el agente verifica el resultado. ¿Cargó correctamente la página? ¿Estaba presente los datos esperados? ¿Apareció un CAPTCHA? Basándose en la observación, decide el siguiente paso — reintentar, escalar o pasar a la siguiente. Esta es la capa que hace que los agentes sean genuinamente diferentes de los scripts: no solo ejecutan, también evalúan.
4. Capa de memoria y almacenamiento
Los datos extraídos se escriben en una base de datos, un data warehouse o un pipeline posterior. Algunos agentes mantienen memoria a corto plazo (contexto de sesión) y memoria a largo plazo (tendencias históricas de precios, patrones conocidos de URL). La memoria a largo plazo permite al agente detectar anomalías — por ejemplo, un precio que cae un 80% de la noche a la mañana es probablemente un error de datos, no un descuento real.
Este modelo de cuatro capas es lo que separa un pipeline de recopilación de datos moderno de un raspador tradicional. El agente no solo recupera páginas — razona sobre la tarea, y esa distinción importa a escala de producción.
Casos de uso clave en inteligencia competitiva
La inteligencia competitiva es una de las aplicaciones de mayor valor del uso de herramientas de la industria de agentes de IA. Estos son los escenarios más comunes donde los equipos implementan agentes hoy en día:
Monitoreo de precios
Los equipos de comercio electrónico usan agentes para seguir precios de competidores en miles de SKUs en tiempo casi real. El agente visita páginas de productos, extrae datos de precios y disponibilidad, y los escribe en un motor de precios que puede desencadenar ajustes automáticos. El monitoreo manual a esta escala no es factible — un solo analista podría seguir 50 productos por día; un agente puede seguir 50.000.
La capa de observación del agente es crítica aquí. Si una página de producto devuelve un estado 429 (Demasiadas solicitudes), el agente se detiene y reintentará con un retraso exponencial. Si el diseño de la página cambia — un fenómeno común durante redes de sitios — el agente puede usar un LLM para reidentificar el elemento de precio en lugar de fallar silenciosamente.
Seguimiento de productos y características
Las empresas de SaaS implementan agentes para monitorear páginas de changelog, notas de lanzamiento y blogs de anuncios de características. Cuando un competidor lanza una nueva integración o cambia un nivel de precios, el agente lo marca en horas en lugar de días. Los gerentes de producto reciben resúmenes estructurados en lugar de volúmenes de HTML crudo, ya que la capa de extracción del agente mapea el contenido a un esquema predefinido: nombre de la característica, fecha de lanzamiento, nivel afectado y resumen.
Este tipo de monitoreo continuo solía requerir a un analista dedicado. Hoy en la industria de agentes de IA, funciona como un proceso programado en segundo plano.
Agregación de reseñas y sentimiento
Los agentes recopilan reseñas de clientes en plataformas como G2, Trustpilot y tiendas de aplicaciones. Las capas de procesamiento de lenguaje natural luego clasifican el sentimiento, extraen temas recurrentes y destacan brechas de productos — dando a los equipos de producto una señal continua del mercado. Un equipo puede identificar que los usuarios de un competidor se quejan consistentemente sobre un proceso de incorporación lento, y luego usar esa información para afinar su propia posición.
Monitoreo de SERP y contenido
Los equipos de SEO y contenido usan agentes para seguir rankings de palabras clave, monitorear perfiles de enlaces de retroalimentación y identificar contenido nuevo publicado por competidores. Esto alimenta directamente calendarios editoriales y estrategias de construcción de enlaces. Los agentes también pueden detectar cuando un competidor publica contenido que apunta a una palabra clave en la que actualmente se encuentra en el primer lugar, activando una alerta antes de que los rankings cambien.
Inteligencia de publicaciones de empleo
Seguir publicaciones de empleo de competidores revela intención estratégica. Un aumento repentino en contrataciones de ingeniería de datos señala una reconstrucción de plataforma. Un grupo de roles de ventas empresarial sugiere una expansión de mercado. Los agentes pueden monitorear páginas de carrera diariamente y aglutinar esta señal automáticamente, dando a los equipos de estrategia un indicador anticipado que a menudo es más confiable que los comunicados de prensa.
Para una visión más amplia sobre cómo las herramientas de scraping están evolucionando para apoyar estos flujos de trabajo, consulte Herramientas de scraping web más importantes en 2026 y Mejores herramientas de extracción de datos.
Comparación: Raspadores tradicionales vs. agentes de IA
| Dimensión | Raspador tradicional | Agente de IA |
|---|---|---|
| Definición de tareas | Selectores fijos, caminos rígidos | Basado en objetivos, adaptable |
| Manejo de cambios en el diseño | Se rompe, requiere corrección manual | Detecta y se adapta |
| Navegación de múltiples pasos | Limitado | Capacidad nativa |
| Recuperación de errores | Intervención manual | Lógica de reintentos autónoma |
| Manejo de CAPTCHAs | Bloquea el pipeline | Puede integrar servicios de resolución |
| Escalabilidad | Lineal con el esfuerzo de ingeniería | Escalable con cálculo |
| Conciencia de cumplimiento | Ninguna incorporada | Puede instruirse para respetar reglas |
El problema de CAPTCHA: Dónde los agentes de IA chocan con un muro
Incluso el pipeline más sofisticado de la industria de agentes de IA eventualmente encontrará un CAPTCHA. Los sitios web los usan como defensa principal contra el acceso automatizado. Los tipos más comunes incluyen:
- reCAPTCHA v2 — desafíos de selección de imágenes ("seleccione todos los semáforos")
- reCAPTCHA v3 — evaluación de riesgo basada en puntuación, invisible
- Cloudflare Turnstile — un desafío más reciente, enfocado en privacidad, que reemplaza a los CAPTCHAs tradicionales
- GeeTest — desafíos de deslizador y comportamiento comunes en plataformas asiáticas
Cuando un agente encuentra un CAPTCHA, el pipeline se detiene. El agente no puede continuar sin un token válido o un desafío completado. Este es un problema estructural, no un caso excepcional — los datos de valor alto casi siempre están protegidos.
La solución conforme es integrar una API de resolución de CAPTCHA en la capa de observación del agente. Cuando el agente detecta un desafío, pasa los parámetros relevantes al servicio de resolución, recibe un token y lo inyecta en la solicitud para continuar. El agente nunca necesita detenerse.
CapSolver es un servicio de resolución de CAPTCHA impulsado por IA construido específicamente para este patrón de integración. Soporta reCAPTCHA v2/v3/Enterprise, Cloudflare Turnstile, GeeTest y CAPTCHA de AWS WAF. Las soluciones se devuelven en 1–5 segundos mediante una API REST, sin intervención humana — todo el proceso permanece automatizado.
Para equipos que construyen pipelines de la industria de agentes de IA en Python, la integración sigue el patrón documentado en la documentación oficial de la API de CapSolver. El agente envía una tarea, consulta el resultado y utiliza el token devuelto para completar la solicitud protegida. Esto mantiene el pipeline en funcionamiento sin intervención manual.
También puede explorar cómo resolver CAPTCHAs mientras se hace scraping para un recorrido práctico de patrones de integración comunes.
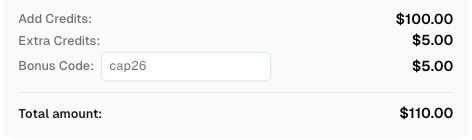
Redime tu código de bono de CapSolver
Aumenta tu presupuesto de automatización de inmediato!
Usa el código de bono CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Redímelo ahora en tu Panel de CapSolver
Marcos de agentes de IA utilizados en flujos de trabajo de scraping
Varios marcos de código abierto y comerciales han surgido específicamente para apoyar casos de uso de la industria de agentes de IA en la recopilación de datos:
- LangChain / LangGraph — popular para construir agentes de razonamiento de múltiples pasos con uso de herramientas
- AutoGen (Microsoft) — soporta colaboración entre agentes, útil para tareas de scraping paralelas
- CrewAI — orquestación de agentes basada en roles, adecuada para flujos de trabajo de inteligencia competitiva
- Crawl4AI — construido específicamente para el rastreo web amigable para IA con salida estructurada
- ScrapeGraph AI — combina modelos de lenguaje a gran escala con scraping para extraer datos usando instrucciones en lenguaje natural
Para un análisis detallado de las opciones principales, consulte Los 9 principales marcos de agentes de IA en 2026.
Cada marco maneja las capas de planificación y ejecución de manera diferente, pero todos enfrentan los mismos desafíos de infraestructura: limitación de tasas, bloqueo de IP y CAPTCHAs. La elección del marco afecta la arquitectura; la capa de resolución de CAPTCHA es un componente separable y componible.
Cumplimiento y uso responsable
La industria de los agentes de IA opera en un paisaje legal y ético que los equipos deben tomar en serio. La recopilación automatizada de datos no es inherentemente ilegal, pero debe realizarse de manera responsable.
Principios clave:
- Respetar robots.txt — este archivo indica qué rutas permite un sitio a la accesibilidad automatizada. Los agentes deben analizarlo y respetarlo.
- Revisar términos de servicio — muchos sitios prohíben explícitamente el scraping automatizado. Es apropiado un análisis legal para casos de uso de alto volumen o de datos sensibles comercialmente.
- Limitación de tasas — los agentes deben implementar retrasos y respetar los encabezados Retry-After para evitar sobrecargar los servidores objetivo.
- Datos personales — recopilar información de identificación personal activa regulaciones como el RGPD, CCPA y otras. Los agentes deben estar limitados a recopilar solo lo necesario.
- Freshness y precisión de datos — la inteligencia competitiva solo tiene valor si los datos son confiables. Los agentes deben incluir pasos de validación para señalar anomalías.
La investigación de Deloitte sobre IA de agentes destaca que la gobernanza y supervisión son las principales preocupaciones para los equipos empresariales que implementan agentes en producción. Incluir el cumplimiento en el conjunto de instrucciones del agente desde el principio es mucho más fácil que adaptarlo más tarde.
Conclusión
Los agentes de IA han pasado de un concepto de investigación a una herramienta de producción en la industria de agentes de IA, y el scraping web con inteligencia competitiva es uno de los ejemplos más claros de su valor. Manejan páginas dinámicas, se adaptan a cambios en el diseño, ejecutan navegación de múltiples pasos y escalan a volúmenes que ningún proceso manual puede igualar.
Los desafíos técnicos son reales — los CAPTCHAs, limitaciones de tasas y sistemas de detección de bots están diseñados para interrumpir exactamente este tipo de automatización. Integrar un servicio de resolución de CAPTCHA confiable como CapSolver en el pipeline del agente elimina uno de los puntos de falla más comunes, manteniendo la recopilación de datos continua y conforme.
Si está construyendo o evaluando una pipeline de la industria de agentes de IA para inteligencia competitiva, comience con un objetivo claro de datos, elija un framework que se adapte a sus necesidades de orquestación y planifique la capa de infraestructura, incluido el manejo de CAPTCHA, antes de llegar a producción.
PREGUNTAS FRECUENTES
P1: ¿Cuál es la diferencia entre un scraper web y un agente de IA para la recolección de datos?
Un scraper tradicional sigue un conjunto fijo de instrucciones: selectores específicos, URLs predeterminados y una ruta de ejecución rígida. Un agente de IA agrega una capa de razonamiento: puede interpretar un objetivo, planificar los pasos necesarios para lograrlo, adaptarse cuando una página cambia y recuperarse de errores de forma autónoma. Para la inteligencia competitiva a gran escala, la capacidad de adaptación es la diferencia clave.
P2: ¿Son legales los agentes de IA para el scraping web?
La recopilación automatizada de datos es legal en muchas jurisdicciones cuando se enfoca en información accesible públicamente y cumple con los términos de servicio del sitio y las leyes aplicables de protección de datos. El marco legal varía según el país y el caso de uso. Los equipos deben revisar robots.txt, los términos de servicio y las regulaciones pertinentes (GDPR, CCPA) antes de implementar agentes a gran escala.
P3: ¿Cómo manejan los agentes de IA los CAPTCHA durante el scraping?
Cuando un agente se encuentra con un CAPTCHA, puede integrarse con una API de resolución de CAPTCHA. El agente pasa los parámetros del desafío a la API, recibe un token válido y lo inyecta en la solicitud para continuar. Servicios como CapSolver admiten este patrón para reCAPTCHA, hCaptcha, Cloudflare Turnstile y otros tipos comunes de desafío, devolviendo soluciones en segundos mediante una API REST.
P4: ¿Cuál es el mejor framework de agente de IA para pipelines de inteligencia competitiva?
La elección adecuada depende de su stack y la complejidad de su flujo de trabajo. LangChain y LangGraph son ampliamente adoptados y cuentan con un fuerte apoyo de la comunidad. CrewAI es adecuado para flujos de trabajo multiagente basados en roles. Crawl4AI y ScrapeGraph AI están especializados en la extracción de datos web. La mayoría de los equipos comienzan con un framework y agregan componentes de infraestructura componibles: proxies, resolutores de CAPTCHA, almacenamiento, a medida que madura la pipeline.
P5: ¿Con qué frecuencia deben ejecutarse los agentes de inteligencia competitiva?
La frecuencia depende de la volatilidad de los datos. Los datos de precios para comercio electrónico pueden necesitar actualizaciones cada hora. El seguimiento de características y la inteligencia de publicaciones de empleo pueden ejecutarse diariamente o semanalmente. El monitoreo de resultados de búsqueda (SERP) generalmente se ejecuta diariamente. Los agentes deben programarse según qué tan rápido cambia los datos subyacente, equilibrando la carga impuesta en los servidores objetivo y el costo de cómputo.
Ver más
AIMar 27, 2026
Elevando la Automatización Empresarial: Infraestructura Potenciada por LLM para un Reconocimiento de CAPTCHA Sin Problemas & Eficiencia Operativa
Descubre cómo la infraestructura de automatización de IA impulsada por LLM revoluciona el reconocimiento de CAPTCHA, mejorando la eficiencia de los procesos de negocio y reduciendo la intervención manual. Optimiza tus operaciones automatizadas con soluciones avanzadas de verificación.

AIMar 27, 2026
Recopilación de Datos a Gran Escala para el Entrenamiento de GML: Resolver CAPTCHAs a Gran Escala
Aprende a escalar la recopilación de datos para el entrenamiento de modelos de lenguaje grandes resolviendo CAPTCHAs a gran escala. Descubre estrategias automatizadas para construir conjuntos de datos de alta calidad para modelos de IA.
