Best Java Web Scraping Libraries for Reliable Data Extraction

Rajinder Singh
Deep Learning Researcher

TL;DR
- Java web scraping libraries should be chosen by page type, not popularity.
- jsoup is best for static HTML parsing and selector-based extraction.
- Selenium Java scraping fits pages that need real browser actions.
- Playwright for Java is strong for modern JavaScript-heavy workflows.
- HtmlUnit works for lighter browser-like tasks without a full browser.
- Apache Nutch is suited to enterprise crawling and indexing.
- A web scraping API is better when CAPTCHA, scale, and operations dominate.
Introduction
The best Java web scraping libraries depend on how the target page delivers data. Static pages need fast parsing. Dynamic pages need browser automation. Large crawl programs need queueing, indexing, and monitoring. CAPTCHA workflows need a documented service, not fragile custom logic. This guide helps developers choose between jsoup, Selenium Java scraping, Playwright for Java, HtmlUnit, Apache Nutch, Java crawler framework options, and a web scraping API. Use the smallest reliable tool, follow site rules, and keep workflows maintainable.
Why Java Is Used for Web Scraping
Java is a strong scraping language when projects must run for months, not minutes. It supports typed code, stable dependency management, mature HTTP clients, and production-friendly observability. Oracle describes Java as a major development platform for reducing development time and running applications across environments through the Java model Oracle Java.
Java web scraping libraries also fit enterprise habits. Teams can add retries, logs, rate limits, tests, and access controls. Java may not be fastest for prototypes. It becomes attractive when reliability and maintenance matter.
The key is matching tools to content. A parser cannot render a React page. A browser may be wasteful for static HTML. A crawler framework may be too heavy for one product page. The best Java web scraping libraries solve a defined problem.
Comparison Summary
| Tool | Best For | JavaScript Handling | Scale Fit | Main Limitation |
|---|---|---|---|---|
| jsoup | Static HTML parsing | No | Medium | Needs other tools for rendering |
| HttpClient + jsoup | Controlled static scraping | No | Medium to High | Requires custom fetching logic |
| Selenium | Browser automation | Strong | Low to Medium | Heavy runtime and fragile selectors |
| Playwright for Java | Modern browser automation | Strong | Medium | Requires browser runtime management |
| HtmlUnit | Lightweight browser-like flows | Partial to Good | Medium | Not a full browser replacement |
| WebMagic or Gecco | Java crawler framework projects | Limited | Medium | Smaller ecosystem |
| Apache Nutch | Enterprise crawling and indexing | Limited | High | Complex setup and operations |
| Web scraping API | Managed scraping operations | Provider handled | High | Less direct control |
Static Web Scraping Libraries in Java
Static scraping should start with parsers. If the first HTML response contains the needed data, browser automation adds cost without improving accuracy. Java web scraping libraries in this category are fast, testable, and easier to operate.
jsoup for HTML Parsing
jsoup is the best first choice for static HTML. Its official site describes it as a Java HTML parser for real-world HTML and XML, with URL fetching, parsing, DOM methods, CSS selectors, and XPath selectors jsoup official documentation.
Use jsoup for article pages, category pages, simple product pages, tables, and HTML fragments. It handles imperfect markup well. That matters because many pages are readable by browsers but not clean enough for strict XML tools.
A reliable jsoup workflow is direct. Request the page with clear headers. Parse the document. Select fields with stable CSS selectors. Validate empty values before storage. This pattern keeps Java web scraping libraries predictable.
jsoup is not a browser. It does not execute JavaScript. If content appears only after scripts run, inspect the network calls first. If allowed endpoints exist, use an HTTP client. If browser behavior is required, use Selenium or Playwright for Java.
HttpClient + jsoup Approach
HttpClient plus jsoup is ideal for controlled static scraping. Java’s HTTP client can manage headers, timeouts, redirects, and response bodies. jsoup then parses the HTML. This separation keeps fetching and parsing clean.
This approach works for price monitoring, public directories, content audits, and research datasets. It is better than direct jsoup fetching when you need tracing, retry rules, crawl delays, or proxy configuration.
Dynamic Web Scraping Libraries in Java
Dynamic pages need browser behavior. They may load content after scrolling, clicking, authentication, or background requests. Selenium Java scraping, Playwright for Java, and HtmlUnit solve this differently.
Selenium for Browser Automation
Selenium is mature and widely documented. The official project describes Selenium as tools and libraries that enable browser automation, with WebDriver as the core interface for running instructions across major browsers Selenium documentation.
Selenium Java scraping works when sites require real browser actions. It can click buttons, wait for elements, submit forms, and read the rendered DOM. It also fits teams already using Selenium for QA testing.
The tradeoff is cost. Browser sessions consume CPU and memory. Selectors can break when the interface changes. Use Selenium Java scraping when browser fidelity matters more than speed.
If CAPTCHA appears in authorized testing or permitted automation, do not hide it inside brittle scripts. Review the target rules first. Then use a documented workflow such as CapSolver’s Selenium CAPTCHA integration.
Playwright for Java
Playwright for Java is strong for modern automation. Its official Java site says Playwright can drive Chromium, Firefox, and WebKit through one API, with Java support available Playwright for Java documentation.
Playwright for Java often reduces flaky automation. Auto-waiting, browser contexts, tracing, and resilient locators help keep workflows stable. It fits Java web scraping libraries projects that need screenshots, downloads, multi-page navigation, or reliable waits.
Choose Playwright for Java when pages are JavaScript-heavy and repeatable browser contexts matter. Avoid it when a simple HTTP request returns the same data. A browser should be the last necessary layer, not the first habit.
For CAPTCHA in approved automation, connect the workflow to official guidance. CapSolver publishes a Playwright CAPTCHA integration that is safer than copying random snippets.
HtmlUnit for Lightweight JS Handling
HtmlUnit sits between parsing and full browser automation. Its official site calls it a “GUI-Less browser for Java programs.” It can invoke pages, fill forms, click links, manage cookies, and provide JavaScript support for many AJAX workflows HtmlUnit documentation.
Use HtmlUnit for older sites, simple form flows, internal tools, and test systems. It is lighter than full browser automation. That can reduce infrastructure cost for moderate workloads.
HtmlUnit is not a full replacement for Chrome, Firefox, or WebKit. Modern front-end frameworks may expose gaps. If visual rendering or complex events matter, Selenium or Playwright for Java is safer.
Java Web Scraping Frameworks for Large Scale Crawling
Large crawling is different from page extraction. It needs frontier management, deduplication, retry rules, politeness controls, parsing, indexing, and monitoring. A Java crawler framework helps when a scraper becomes a system.
WebMagic and Gecco
WebMagic and Gecco are practical Java crawler framework options for medium projects. They structure downloader logic, page processors, pipelines, and data models. That makes code easier to divide across teams.
Use them for public catalogs, documentation mirrors, recurring content discovery, and similar pages. They are less suitable for highly dynamic pages unless paired with a rendering layer. Their main strength is maintainability. Their main weakness is a smaller ecosystem than jsoup, Selenium, or Playwright.
Apache Nutch for Enterprise Crawling
Apache Nutch is built for large crawl programs. Its homepage describes it as a highly extensible, highly scalable, mature, production-ready web crawler Apache Nutch project. It supports pluggable parsing, indexing, scoring, and integrations with search systems.
Use Apache Nutch when crawling is a platform requirement. It fits search indexing, enterprise discovery, and recurring large-scale data acquisition. It is not ideal for a small one-off scraper. Setup and operations require real engineering time.
Before scaling any Java crawler framework, define allowed domains, refresh frequency, storage rules, and request limits. CapSolver’s guide on web scraping legality and key rules is useful for planning.
CAPTCHA Challenges in Java Scraping
CAPTCHA is a workflow signal, not just a technical issue. It may indicate rate pressure, login risk, access rules, or missing permission. Treat it carefully. Confirm that your use case is allowed, minimize request volume, and collect only required data.
Java web scraping libraries do not solve CAPTCHA by themselves. jsoup cannot interact with a challenge. Selenium and Playwright can display one, but they still need a valid handling process. HtmlUnit is rarely the right layer for this task.
CapSolver is relevant when a legitimate automation process needs CAPTCHA handling. Examples include QA testing, account-owned workflows, and permitted scraping. The official CapSolver API documentation lists createTask and getTaskResult as core endpoints for task creation and result retrieval CapSolver API documentation. Use the official docs directly for implementation details.
A safe process is simple. Document the target, confirm permission, limit request rates, and store only needed fields. CapSolver’s FAQ on web scraping and CAPTCHA-solving APIs is a useful planning resource.
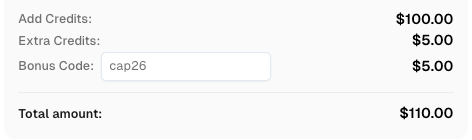
Redeem Your CapSolver Bonus Code
Boost your automation budget instantly!
Use bonus code CAP26 when topping up your CapSolver account to get an extra 5% bonus on every recharge — with no limits.
Redeem it now in your CapSolver Dashboard
When to Use a Web Scraping API Instead of Libraries
Use a web scraping API when operations matter more than code control. Java web scraping libraries are flexible, but teams must manage browser runtimes, retries, monitoring, parser drift, and CAPTCHA workflows.
A web scraping API makes sense for high-volume collection, unstable front ends, JavaScript-heavy pages, and teams without scraping infrastructure. It may also reduce the need for browser farms. The tradeoff is vendor dependency, so review data quality, pricing, logs, and compliance terms.
A hybrid model is often best. Use jsoup for stable static pages. Use Selenium Java scraping or Playwright for Java for a small set of dynamic flows. Use Apache Nutch when crawling becomes a search platform. Use a web scraping API when infrastructure becomes the main workload. CapSolver’s guide to common web scraping challenges can help teams prepare.
Conclusion and CTA
The best Java web scraping libraries are ranked by fit, not hype. jsoup is best for static HTML. HttpClient plus jsoup adds control. Selenium Java scraping and Playwright for Java handle dynamic pages. HtmlUnit covers lighter browser-like flows. WebMagic, Gecco, and Apache Nutch support crawler architecture. A web scraping API helps when infrastructure cost grows.
Start small and stay compliant. Read site rules, respect rate limits, minimize collection, and keep logs. If CAPTCHA appears in an approved workflow, use official documentation and a dedicated provider such as CapSolver.
FAQ
What is the best Java web scraping library?
jsoup is the best first choice for static HTML. Playwright for Java or Selenium is better for JavaScript-heavy pages. Apache Nutch is better for enterprise crawling.
Is Selenium Java scraping better than Playwright for Java?
Selenium has broader history and ecosystem support. Playwright for Java often offers stronger modern automation features, including auto-waiting and browser contexts.
Can jsoup scrape dynamic websites?
jsoup can parse returned HTML, but it does not execute JavaScript. Use browser automation when content appears only after scripts run.
Is Apache Nutch suitable for small scraping projects?
Usually no. Apache Nutch is powerful, but it is better for large crawl systems, search indexing, and enterprise data acquisition.
When should I use CapSolver with Java scraping?
Use CapSolver only for legitimate, documented automation where CAPTCHA handling is allowed. Follow CapSolver’s official API docs and the target site’s rules.
More
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
Learn scalable Rust web scraping architecture with reqwest, scraper, async scraping, headless browser scraping, proxy rotation, and compliant CAPTCHA handling.

Web ScrapingApr 17, 2026
How to Scrape Job Listings Without Getting Blocked
Learn the best techniques to scrape job listings without getting blocked. Master Indeed scraping, Google Jobs API, and web scraping API with CapSolver.
