How to Integrate reCAPTCHA v2 Solutions in Python for Data Extraction

Lucas Mitchell
Automation Engineer
``
Introduction
As the internet grows, web scraping and data extraction are widely used to gather information from websites for various purposes, including business intelligence, content aggregation, and market analysis. However, as bots became more sophisticated, websites implemented tools to differentiate between human users and automated programs. One such tool is reCAPTCHA. In this blog, we will explore what reCAPTCHA is, the different versions available, and how to solve reCAPTCHA v2 challenges using Capsolver in Python. Finally, we'll walk through a simple example code to integrate reCAPTCHA v2 into your data extraction project.
What is reCAPTCHA?

reCAPTCHA is a free service developed by Google that helps protect websites from spam and abuse by ensuring that a real person (rather than an automated bot) is interacting with the site. When users visit a website that implements reCAPTCHA, they may be required to complete a challenge to verify that they are human.
Different Versions of reCAPTCHA
There are several versions of reCAPTCHA, each with its own strengths and use cases:
-
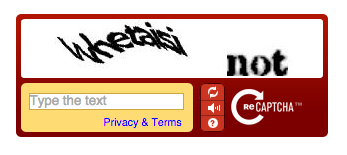
reCAPTCHA v1: The earliest version, now deprecated. It required users to transcribe distorted text from images.
-
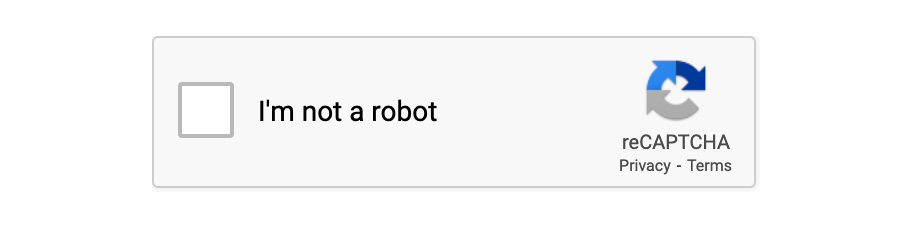
reCAPTCHA v2: A more advanced version that presents users with a checkbox ("I'm not a robot"). If necessary, it also challenges them to select certain images (like traffic lights or crosswalks). This version is the most commonly used today.
-
reCAPTCHA v3: This version analyzes user behavior and interaction with the website to assign a score from 0 to 1, where 0 indicates a bot and 1 indicates a human. It is more seamless for users as it does not require interactive challenges.

-
Invisible reCAPTCHA: This version operates behind the scenes and only presents challenges when suspicious activity is detected. It is designed to be invisible to legitimate users.
What is Data Extraction?

Data extraction refers to the process of retrieving structured data from unstructured sources such as web pages, databases, or other digital formats. It is commonly used in web scraping, where automated programs collect large amounts of information from websites for analysis or aggregation.
Common Use Cases for Data Extraction
-
Market Research: Companies extract competitor pricing data and customer reviews to adjust their marketing and sales strategies.
-
Business Intelligence: Organizations scrape financial reports, news, and other resources to make informed business decisions.
-
Content Aggregation: Websites that curate and display information from multiple sources often extract data from other web pages.
-
SEO Analysis: Extracting content, keywords, and meta tags from competitor websites helps in optimizing SEO strategies.
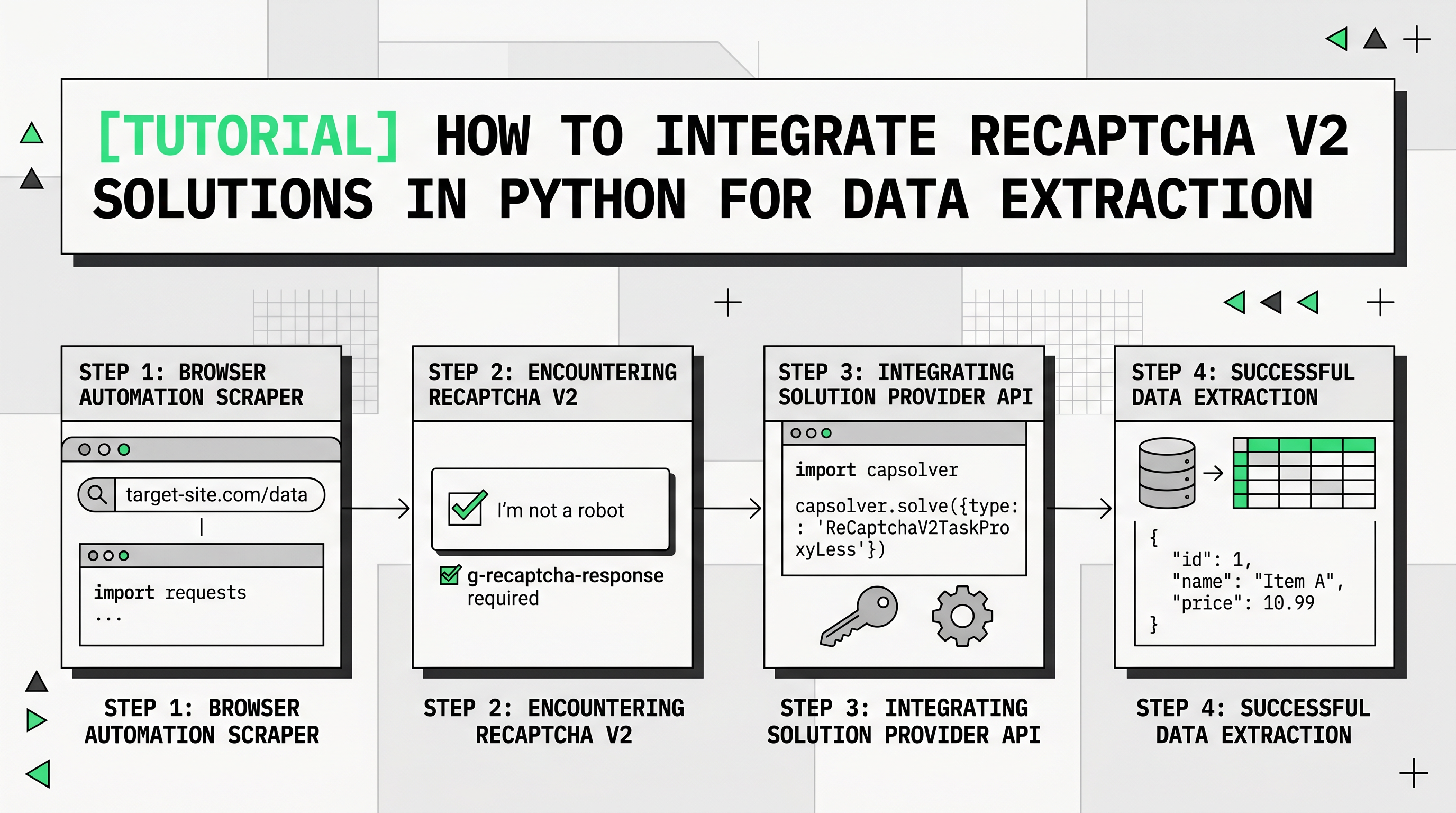
Integrating reCAPTCHA v2 Solution in Python
When extracting data from websites, you may encounter reCAPTCHA challenges. This poses a hurdle for automated scraping. Fortunately, tools like Capsolver can solve reCAPTCHA v2 challenges programmatically, allowing you to continue with your data extraction tasks.
Here is a Python implementation to solve reCAPTCHA v2 using the Capsolver package.
Steps:
-
Install the
capsolverlibrary by running:bashpip install capsolver -
Use the following Python code to solve the reCAPTCHA v2 challenge:
python
import capsolver
# Consider using environment variables for sensitive information
capsolver.api_key = "Your Capsolver API Key"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": url,
"websiteKey":key,
})
return solution
def main():
print("Solving reCaptcha v2")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("Solution: ", solution)
if __name__ == "__main__":
main()Explanation of the Code
-
Capsolver API Setup: In the code, we define the
capsolver.api_keywhich should contain your Capsolver API key. This key will authenticate your requests to the Capsolver service. -
Solve Function: The function
solve_recaptcha_v2accepts theurlof the page and thesite_key(which is the reCAPTCHA key present on the website). It sends a request to Capsolver to solve the reCAPTCHA challenge. -
Main Function: The main function runs the solver and prints the solution.
-
Environment Variables: It is recommended to use environment variables to store sensitive information like API keys for better security. In the example above, you should replace
Your Capsolver API Key,PAGE_URL, andPAGE_SITE_KEYwith your actual values.
Bonus Code
Claim Your Bonus Code for top captcha solutions; CapSolver: scrape. After redeeming it, you will get an extra 5% bonus after each recharge, Unlimited

For more information, read this blog
Conclusion
reCAPTCHA is an essential tool for protecting websites from bots, but it can create challenges for legitimate automation purposes such as data extraction. Using tools like Capsolver allows developers to programmatically solve reCAPTCHA v2 challenges, enabling uninterrupted data extraction. Always ensure that your data extraction activities comply with the website’s terms of service and legal guidelines to avoid any issues.
By integrating the solution provided above into your Python projects, you can continue to gather valuable data from websites while overcoming reCAPTCHA obstacles.
More
reCAPTCHAApr 16, 2026
reCAPTCHA Score Explained: Range, Meaning, and How to Improve It
Understand reCAPTCHA v3 score range (0.0 to 1.0), its meaning, and how to improve your score. Learn how to handle low scores and optimize user experience.

reCAPTCHAApr 16, 2026
reCAPTCHA Invalid Site Key or Token? Causes & Fix Guide
Facing "reCAPTCHA Invalid Site Key" or "invalid reCAPTCHA token" errors? Discover common causes, step-by-step fixes, and troubleshooting tips to resolve reCAPTCHA verification failed issues. Learn how to fix reCAPTCHA verification failed please try again.


