वेब स्क्रैपिंग वेबसाइटों से डेटा निष्कर्षण को स्वचालित बनाता है, जिससे बड़ी मात्रा में असंरचित ऑनलाइन डेटा को संरचित और उपयोगी प्रारूपों में बदला जा सकता है।
यह विभिन्न उद्योगों में व्यापक रूप से उपयोग किया जाता है, जैसे मूल्य निगरानी, लीड जनरेशन, SEO ट्रैकिंग, सेंटिमेंट एनालिसिस और डेटा जर्नलिज़्म।
वेब स्क्रैपिंग टूल्स को मुख्य रूप से तीन श्रेणियों में बांटा जा सकता है: नो-कोड सेल्फ-सर्विस टूल्स, कोड-आधारित प्रोग्रामेटिक टूल्स, और पूर्णतः प्रबंधित डेटा निष्कर्षण सेवाएं।
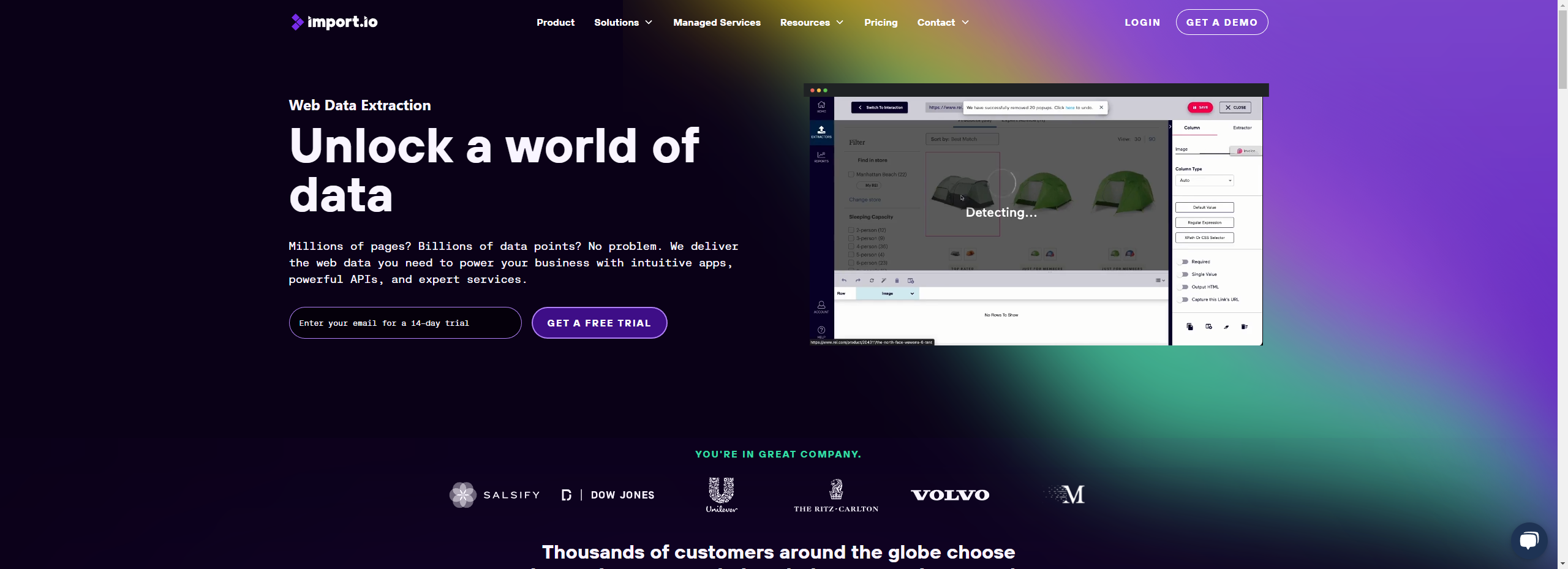
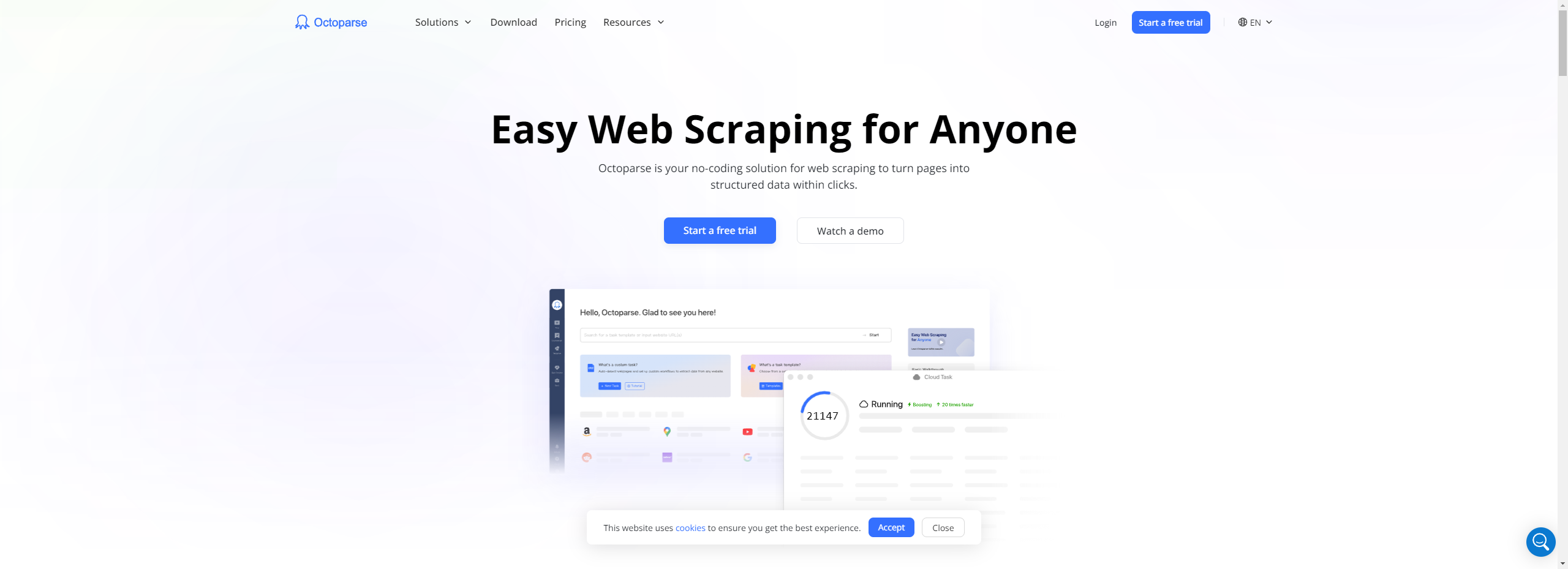
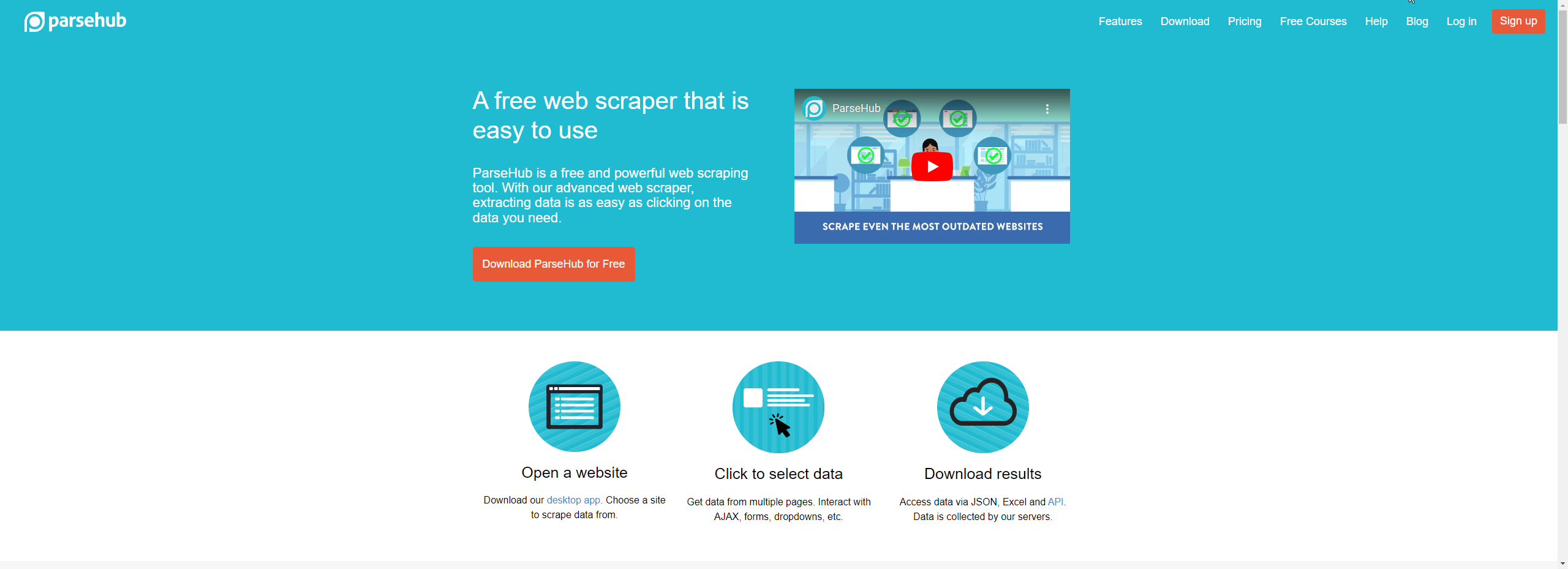
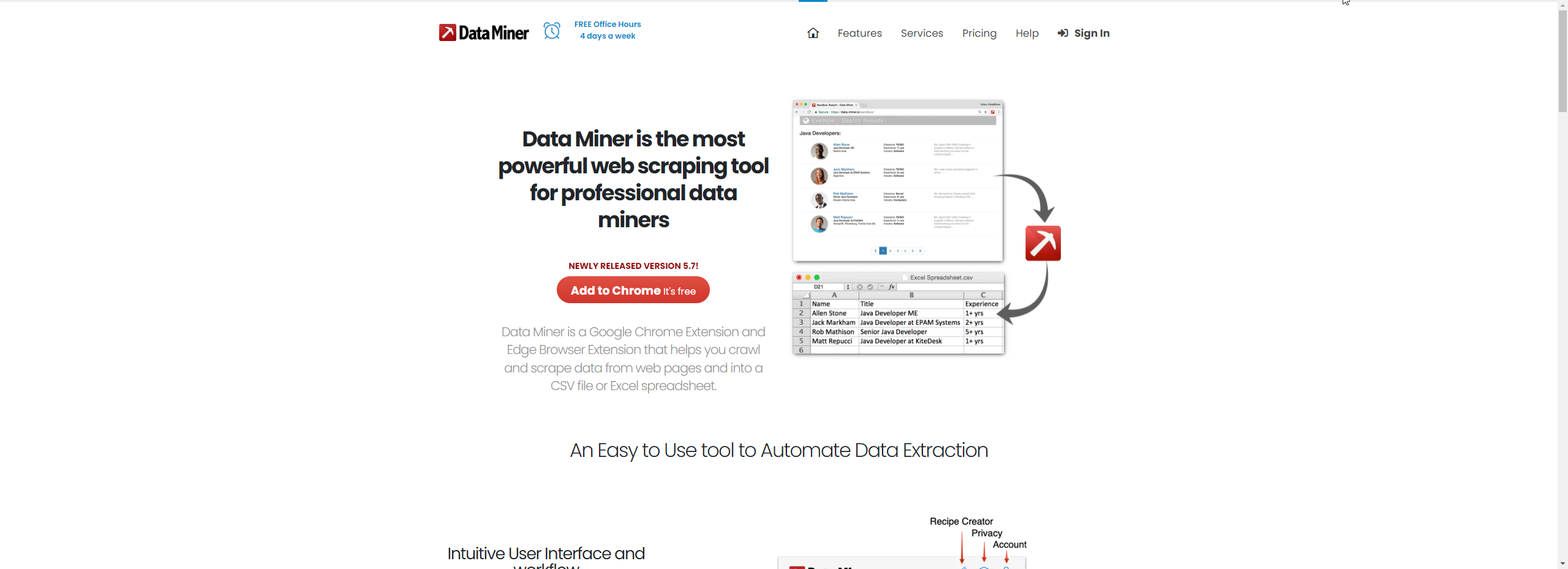
नो-कोड और विज़ुअल टूल्स (जैसे Import.io, Octoparse, ParseHub, WebHarvy) गैर-तकनीकी उपयोगकर्ताओं के लिए उपयुक्त हैं जिन्हें तेज़ परिणाम चाहिए।
डेवलपर्स के लिए टूल्स और लाइब्रेरीज़ (जैसे Scrapy, BeautifulSoup, Selenium, Puppeteer, Cheerio) अधिक लचीलापन और स्केलेबिलिटी प्रदान करते हैं, लेकिन प्रोग्रामिंग कौशल की आवश्यकता होती है।
ब्राउज़र ऑटोमेशन टूल्स जैसे Selenium और Puppeteer जावास्क्रिप्ट-हैवी और अत्यधिक इंटरएक्टिव वेबसाइटों के लिए अनिवार्य हैं।
सही टूल का चयन तकनीकी अनुभव, डेटा की जटिलता, स्केल और बजट पर निर्भर करता है, न कि “वन-साइज़-फिट्स-ऑल” दृष्टिकोण पर।
जिम्मेदार स्क्रैपिंग अत्यंत महत्वपूर्ण है—हमेशा वेबसाइट की सेवा शर्तों और लागू कानूनी एवं नैतिक दिशानिर्देशों का पालन करें।
Web Scraping Tools
वेब स्क्रैपिंग, जिसे वेब डेटा एक्सट्रैक्शन भी कहा जाता है, वेबसाइट से डेटा प्राप्त करने या “स्क्रैप” करने की प्रक्रिया है। मैन्युअल रूप से डेटा निकालने की उबाऊ और समय लेने वाली प्रक्रिया के विपरीत, वेब स्क्रैपिंग बुद्धिमान ऑटोमेशन का उपयोग करके इंटरनेट से सैकड़ों, लाखों,甚至 अरबों डेटा पॉइंट्स एकत्र कर सकती है।
इंटरनेट पर डेटा की मात्रा तेजी से बढ़ रही है। वर्तमान में 1.7 अरब से अधिक वेबसाइटें ऑनलाइन हैं, और हर दिन नई वेबसाइटें बनाई जा रही हैं। इतने विशाल डेटा महासागर में व्यवसाय, शोधकर्ता और व्यक्तिगत उपयोगकर्ता आवश्यक जानकारी कैसे खोजें? इसका उत्तर है—वेब स्क्रैपिंग।
इस गाइड का उद्देश्य आज उपलब्ध सबसे शक्तिशाली वेब स्क्रैपिंग टूल्स का विस्तृत अवलोकन प्रदान करना है। कुछ टूल्स के लिए तकनीकी ज्ञान आवश्यक है, जबकि अन्य गैर-प्रोग्रामर्स के लिए भी उपयुक्त हैं। चाहे आप डेटा साइंटिस्ट हों, सॉफ्टवेयर डेवलपर हों या डिजिटल मार्केटिंग विशेषज्ञ—यहाँ आपको अपनी आवश्यकताओं के अनुरूप टूल मिलेगा।
अपना CapSolver बोनस कोड रिडीम करें
अपने ऑटोमेशन बजट को तुरंत बढ़ाएँ!
CapSolver अकाउंट में टॉप-अप करते समय बोनस कोड CAPN का उपयोग करें और हर रिचार्ज पर अतिरिक्त 5% बोनस प्राप्त करें — बिना किसी सीमा के।
अभी अपने CapSolver Dashboard में इसे रिडीम करें।
1. Introduction to Web Scraping
वेब स्क्रैपिंग एक स्वचालित विधि है जिसका उपयोग वेबसाइटों से बड़ी मात्रा में डेटा तेज़ी से निकालने के लिए किया जाता है। वेबसाइटों पर मौजूद डेटा आमतौर पर असंरचित (unstructured) होता है। वेब स्क्रैपिंग इस डेटा को संरचित रूप में परिवर्तित करने में सक्षम बनाता है।
2. Why Use Web Scraping Tools?
व्यवसायों, शिक्षाविदों और व्यक्तिगत उपयोगकर्ताओं के लिए वेबसाइट स्क्रैप करने के कई कारण हो सकते हैं। कुछ सामान्य उपयोग इस प्रकार हैं:
डेटा जर्नलिज़्म: पत्रकार और शोधकर्ता सार्वजनिक रिकॉर्ड्स में बदलावों को ट्रैक करने या खोजी रिपोर्ट के लिए विभिन्न स्रोतों से जानकारी एकत्र करने हेतु स्क्रैपिंग टूल्स का उपयोग करते हैं।
मूल्य तुलना: ई-कॉमर्स कंपनियाँ अपने प्रतिस्पर्धियों की मूल्य रणनीतियों की निगरानी के लिए वेब स्क्रैपिंग का उपयोग करती हैं।
लीड जनरेशन: कई व्यवसाय डायरेक्टरी या सोशल मीडिया साइट्स से संपर्क जानकारी एकत्र करने के लिए वेब स्क्रैपिंग का उपयोग करते हैं।
सेंटिमेंट एनालिसिस: ग्राहक समीक्षाओं और सोशल मीडिया चर्चाओं को स्क्रैप करके व्यवसाय अपने उत्पादों के प्रति बाज़ार की धारणा को समझ सकते हैं।
SEO मॉनिटरिंग: SEO कंपनियाँ वेबसाइट प्रदर्शन, रैंकिंग बदलाव और अन्य प्रासंगिक डेटा को ट्रैक करने के लिए वेब स्क्रैपर्स का उपयोग करती हैं।
3. Types of Web Scraping Tools
मुख्य रूप से वेब स्क्रैपिंग टूल्स तीन प्रकार के होते हैं:
Self-service Tools: पॉइंट-एंड-क्लिक टूल्स जो बिना कोडिंग के डेटा स्क्रैप करने की सुविधा देते हैं।
Programmatic Tools: लाइब्रेरी या फ्रेमवर्क जिन्हें कोड में इंटीग्रेट किया जाता है; ये अधिक लचीलापन प्रदान करते हैं लेकिन प्रोग्रामिंग ज्ञान आवश्यक होता है।
Managed Services: एंड-टू-एंड प्लेटफॉर्म जहाँ आप आवश्यकताएँ बताते हैं और वे आपको डेटा प्रदान करते हैं—सबसे सुविधाजनक लेकिन कम लचीले और अक्सर महंगे।
4. Detailed Review of Web Scraping Tools
नीचे कुछ लोकप्रिय वेब स्क्रैपिंग टूल्स की विस्तृत समीक्षा दी गई है।
Mozenda एक एंटरप्राइज़-ग्रेड वेब स्क्रैपिंग सॉफ्टवेयर है।
5. Conclusion
आज की डेटा-ड्रिवन दुनिया में वेब स्क्रैपिंग टूल्स अनिवार्य हो गए हैं। ग्राहक भावना समझने से लेकर प्रतिस्पर्धी निगरानी तक—वेब स्क्रैपिंग के उपयोग असीमित हैं। सही टूल का चयन आपकी तकनीकी क्षमता, कार्य की जटिलता और डेटा आवश्यकताओं पर निर्भर करता है।
FAQs
1. शुरुआती लोगों के लिए सबसे अच्छा वेब स्क्रैपिंग टूल कौन सा है?
Import.io, Octoparse, ParseHub, WebHarvy और OutWit Hub जैसे नो-कोड टूल्स शुरुआती और गैर-तकनीकी उपयोगकर्ताओं के लिए सबसे उपयुक्त हैं।
2. Selenium या Puppeteer का उपयोग कब करना चाहिए?
जब वेबसाइट JavaScript पर आधारित हो, डायनामिक कंटेंट लोड करती हो या यूज़र इंटरैक्शन की आवश्यकता हो।
3. क्या वेब स्क्रैपिंग कानूनी है?
वेब स्क्रैपिंग अपने आप में अवैध नहीं है, लेकिन इसकी वैधता वेबसाइट की शर्तों, डेटा के प्रकार और स्थानीय कानूनों पर निर्भर करती है। हमेशा जिम्मेदारी से और नियमों का पालन करते हुए स्क्रैप करें।