How to Start Web Scraping in R: A Complete Guide for 2026

Lucas Mitchell
Automation Engineer

TL;DR
- Web Scraping with R: R is not only a statistics and visualization language but also a practical tool for collecting and structuring web data.
- Core Tool – rvest: With functions like
read_html(),html_nodes(),html_text(), andhtml_attr(),rvestenables efficient HTML parsing and data extraction. - Environment Setup: R scraping projects can run smoothly in RStudio or PyCharm, fitting well into data science workflows.
- Hands-on Example: Demonstrates how to scrape product images, titles, prices, and descriptions from a real website.
- Common Challenges: Real-world scraping often involves reCAPTCHA, browser fingerprinting, IP risk checks, and complex JavaScript logic.
- CapSolver Solution: CapSolver’s AI-powered Auto Web Unblock technology automates CAPTCHA solving and bypasses common scraping obstacles.
- Best Practices: Respect robots.txt, control request frequency, and ensure ethical and compliant data collection.
Introduction
Are there times when you are curious, like how data scientists collect large amounts of online data for research, marketing and analysis? Web scraping in R is a powerful skill that can transform online content into valuable datasets, enabling data-driven decisions and deeper insights. So, what makes web scraping challenging, and how can R help? In this guide, we’ll walk through setting up your R environment, extracting data from web pages, handling more complex scenarios like dynamic content, and finishing with best practices to stay ethical and compliant.
Why Choose R?
R is a language and environment primarily used for statistical analysis and data visualization. Initially popular among statisticians in academia, R has expanded its user base to researchers in various fields. With the rise of big data, professionals from computing and engineering backgrounds have significantly contributed to enhancing R’s computational engine, performance, and ecosystem, driving its development forward.
As an integrated tool for statistical analysis and graphical display, R is versatile, running seamlessly on UNIX, Windows, and macOS. It features a robust, user-friendly help system and is tailored for data science, offering a rich set of data-focused libraries ideal for tasks like web scraping.
However, regardless of the programming language you use for web scraping, it’s essential to adhere to websites' robots.txt protocol. Found in the root directory of most websites, this file specifies which pages can and cannot be crawled. Following this protocol helps avoid unnecessary disputes with website owners.
Setting Up the R Environment
Before using R for web scraping, ensure you have a properly configured R environment:
-
Download and Install R:
Visit the R Project official website and download the appropriate installation package for your operating system. -
Choose an IDE for R:
Select a development environment to run R code:- PyCharm: A popular IDE for Python, PyCharm can also support R through plugins. Visit the JetBrains website to download it.
- RStudio: A dedicated IDE for R that provides a seamless and integrated experience. Visit the Posit website to download RStudio.
-
If Using PyCharm:
You’ll need to install the R Language for IntelliJ plugin to run R code within PyCharm.
For this guide, we'll use PyCharm to create our first R web scraping project. Start by opening PyCharm and creating a new project.

Click "Create," and PyCharm will initialize your R project. It will automatically generate a blank main.R file. On the right and bottom of the interface, you will find the R Tools and R Console tabs, respectively. These tabs allow you to manage R packages and access the R shell, as shown in the image below:
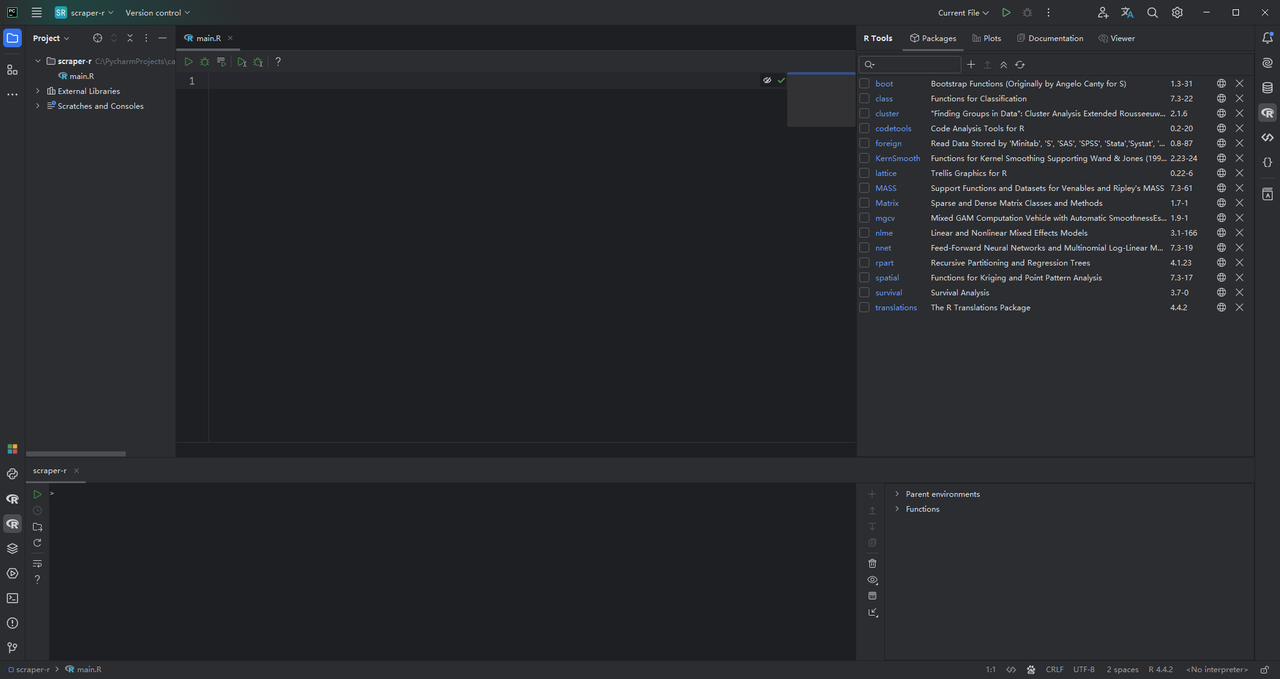
Using R for Data Scraping
Let's take the first exercise from ScrapingClub as an example to demonstrate how to use R to scrape product images, titles, prices, and descriptions:
1. Install rvest
rvest is an R package designed to assist with web scraping. It simplifies common web scraping tasks and works seamlessly with the magrittr package to provide an easy-to-use pipeline for extracting data. The package draws inspiration from libraries like Beautiful Soup and RoboBrowser.
To install rvest in PyCharm, use the R Console located at the bottom of the interface. Enter the following command:
R
install.packages("rvest")Before installation begins, PyCharm will prompt you to select a CRAN mirror (package source). Choose the one closest to your location for faster downloads. Once installed, you're ready to start scraping!
2. Access the HTML Page
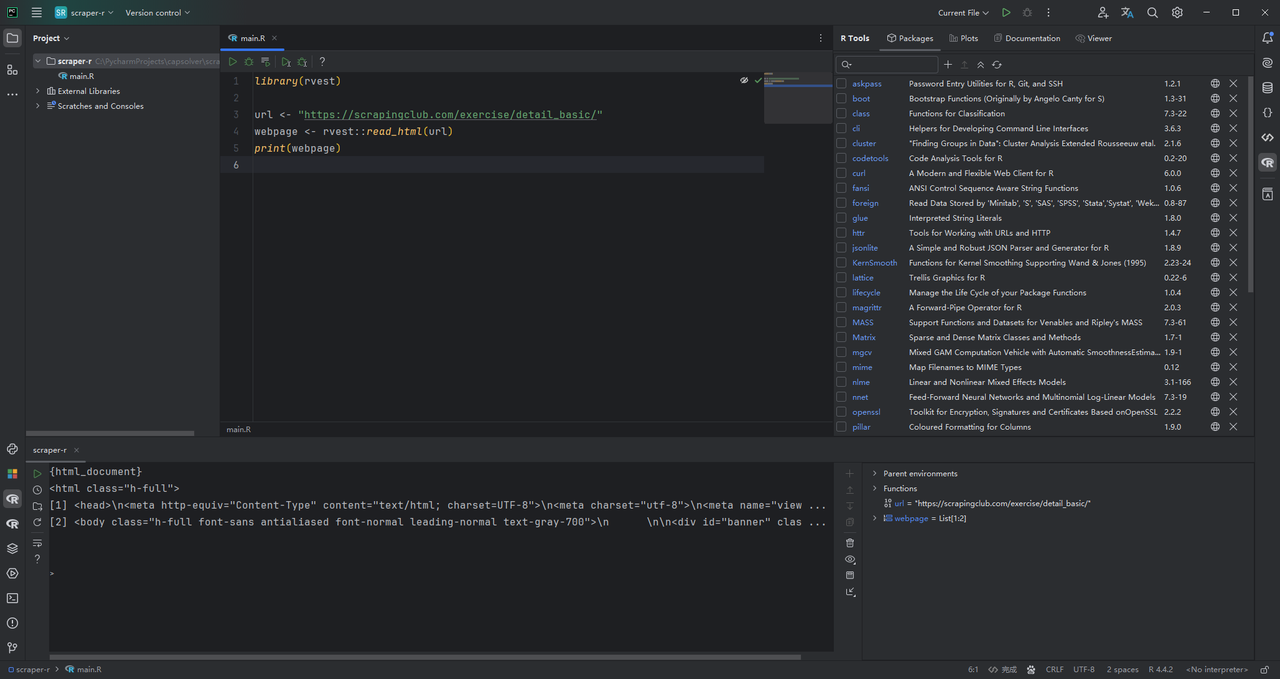
The rvest package provides the read_html() function, which retrieves the HTML content of a webpage when given its URL. Here's how you can use it to fetch the HTML of a target website:
R
library(rvest)
url <- "https://scrapingclub.com/exercise/detail_basic/"
webpage <- rvest::read_html(url)
print(webpage)Running this code will output the HTML source code of the page in the R Console, giving you a clear look at the structure of the webpage. This is the foundation for extracting specific elements like product details.
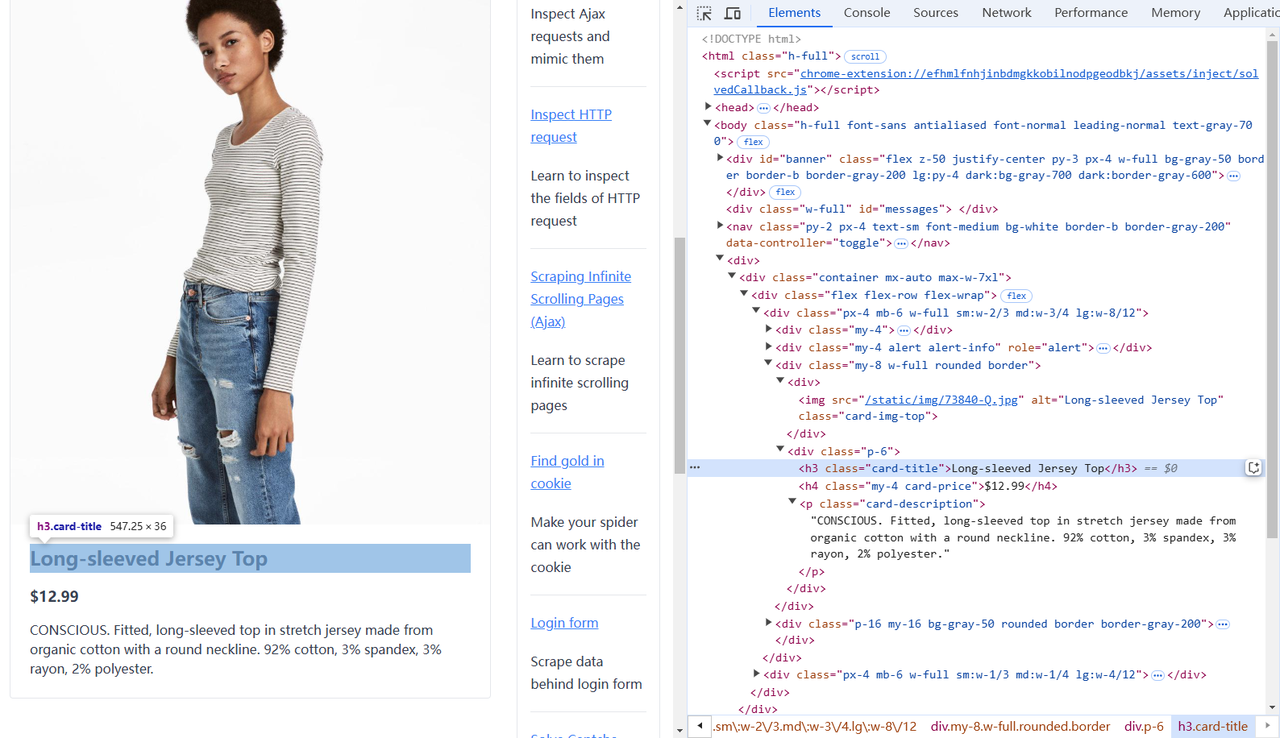
3. Parse the Data
To extract specific data from a webpage, we first need to understand its structure. Using your browser’s developer tools, you can inspect the elements and identify where the desired data is located. Here's a breakdown of the target elements on the example page:
- Product Image: Found in the
imgtag with the classcard-img-top. - Product Title: Located within the
<h3>element. - Product Price: Contained in the
<h4>element. - Product Description: Found in the
<p>tag with the classcard-description.
The rvest package in R provides robust tools to parse and extract content from HTML documents. Here are some key functions used for web scraping:
html_nodes(): Selects all nodes (HTML tags) from the document that match the specified CSS selector. It allows you to filter content effectively using CSS-like syntax.html_attr(): Extracts the value of a specified attribute from the selected HTML nodes. For example, you can retrieve thesrcattribute for images orhreffor links.html_text(): Extracts the plain text content within the selected HTML nodes, ignoring the HTML tags.
Here's how you can use these functions to scrape data from a sample page:
R
library(rvest)
# URL of the target webpage
url <- "https://scrapingclub.com/exercise/detail_basic/"
webpage <- rvest::read_html(url)
# Extracting data
img_src <- webpage %>% html_nodes("img.card-img-top") %>% html_attr("src") # Image source
title <- webpage %>% html_nodes("h3") %>% html_text() # Product title
price <- webpage %>% html_nodes("h4") %>% html_text() # Product price
description <- webpage %>% html_nodes("p.card-description") %>% html_text() # Product description
# Displaying the extracted data
print(img_src)
print(title)
print(price)
print(description)Explanation of the Code
- Read HTML: The
read_html()function fetches the entire HTML structure of the target webpage. - Extract Data: Using CSS selectors with
html_nodes(), you can target specific elements such as images, titles, and descriptions. - Retrieve Attributes/Text: The
html_attr()function extracts attribute values like thesrcfor images, whilehtml_text()retrieves text content within the tags.
Output Example
When you run the above code, the extracted data will be displayed in your R console. For example:
- Image URL: The path to the product image, such as
/images/example.jpg. - Title: The name of the product, such as "Sample Product".
- Price: The price information, like "$20.99".
- Description: The product description, e.g., "This is a high-quality item.".
This allows you to efficiently gather structured data from the webpage, ready for further analysis or storage.
Result Preview
After running the script, you should see the extracted content in your R console, as illustrated below:

Using rvest, you can automate the process of web scraping for various structured data needs, ensuring clean and actionable outputs.
Challenges in Data Scraping
In real-world data scraping scenarios, the process is rarely as straightforward as the demonstration in this article. You will often encounter various bot challenges, such as the widely-used reCAPTCHA and similar systems.
These systems are designed to validate whether requests are legitimate by implementing measures such as:
- Request Header Validation: Checking if your HTTP headers follow standard patterns.
- Browser Fingerprint Checks: Ensuring that your browser or scraping tool mimics real user behavior.
- IP Address Risk Assessment: Determining if your IP address is flagged for suspicious activity.
- Complex JavaScript Encryption: Requiring advanced calculations or obfuscated parameters to proceed.
- Challenging Image or Text Recognition: Forcing solvers to correctly identify elements from CAPTCHA images.
All these measures can significantly hinder your scraping efforts. However, there’s no need to worry. Every one of these bot challenges can be efficiently resolved with CapSolver.
Why CapSolver?
CapSolver employs AI-powered Auto Web Unblock technology, capable of Solving even the most complex CAPTCHA challenges in just seconds. It automates tasks such as decoding encrypted JavaScript, generating valid browser fingerprints, and solving advanced CAPTCHA puzzles—ensuring uninterrupted data collection.
Use code
CAP26when signing up at CapSolver to receive bonus credits!
Easy Integration
CapSolver provides SDKs in multiple programming languages, allowing you to seamlessly integrate its features into your project. Whether you're using Python, R, Node.js, or other tools, CapSolver simplifies the implementation process.
Documentation and Support
The official CapSolver documentation offers detailed guides and examples to help you get started. You can explore additional capabilities and configuration options there, ensuring a smooth and efficient scraping experience.
Wrapping Up
Web scraping with R opens up a world of possibilities for data collection and analysis, turning unstructured online content into actionable insights. With tools like rvest for efficient data extraction and services like CapSolver to overcome scraping challenges, you can streamline even the most complex scraping projects.
However, always remember the importance of ethical scraping practices. Adhering to website guidelines, respecting the robots.txt file, and ensuring compliance with legal standards are essential to maintaining a responsible and professional approach to data collection.
Equipped with the knowledge and tools shared in this guide, you're ready to embark on your web scraping journey with R. As you gain more experience, you’ll discover ways to handle diverse scenarios, expand your scraping toolkit, and unlock the full potential of data-driven decision-making.
FAQs
1. Is R suitable for large-scale web scraping?
R is well-suited for small to medium-scale scraping, especially when data collection is closely tied to analysis and visualization. For very large-scale crawling, R is often combined with proxies, concurrency control, or other languages.
2. Can rvest scrape JavaScript-rendered content?
rvest primarily works with static HTML. Pages that rely heavily on JavaScript rendering usually require browser automation or external services to retrieve fully rendered content.
3. How can I handle CAPTCHA and anti-bot protections when scraping with R?
You can integrate CapSolver, which uses AI-driven automation to solve reCAPTCHA and other bot challenges, ensuring a stable and uninterrupted scraping workflow.
More
CloudflareJun 12, 2026
Playwright Blocked by Cloudflare Turnstile: Causes & Fix
A Playwright-specific Turnstile guide covering traces, locator timing, actionability, network events, parameters, and server-side validation.

AIJun 11, 2026
Solving CAPTCHA Blocking Issues in Cursor Agents
A field guide for Cursor agent CAPTCHA blocks, including loop control, browser state, MCP boundaries, proxy hygiene, and measured remediation.


