什么是人工智能中的数据根基?可靠大规模语言模型的实用指南

Ethan Collins
Pattern Recognition Specialist
简要总结
- 数据接地将AI输出与可信、最新和相关的信息源连接起来。
- 数据接地通过在推理时添加上下文来减少未经证实的答案。
- 接地数据可以包括文档、数据库、搜索结果、目录、政策和允许的记录。
- RAG是数据接地的常见技术,但它不是整个学科。
- 强大的数据接地需要质量检查、权限、检索评估、引用和监控。
- 使用自动化的团队应合法收集数据,并且仅在授权的工作流中处理CAPTCHA挑战。
介绍
数据接地是一种使AI答案更准确、最新和可验证的实践。它在模型回答之前提供正确的上下文。本指南适用于在大型语言模型(LLM)基础上构建AI工具的产品团队、SEO团队、开发人员和自动化团队。您将了解AI中的数据接地是什么,它是如何工作的,它与RAG和微调有何不同,以及如何负责任地应用它。其价值是实际的:接地的AI系统可以引用来源,尊重权限,并减少过时的答案。当合法的自动化工作流遇到流量验证或CAPTCHA挑战时,CapSolver可以支持合规的测试流程。
数据接地定义
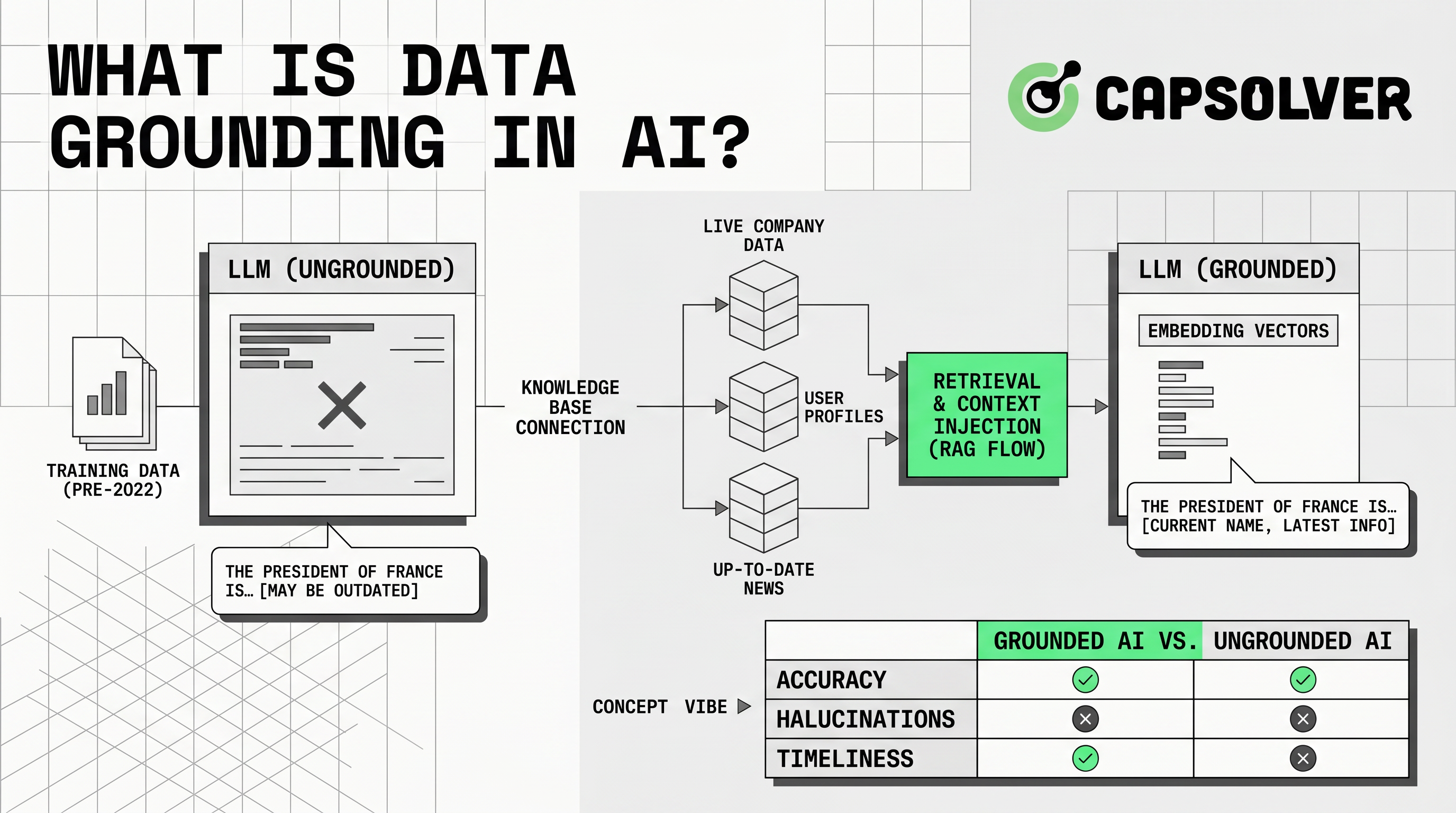
数据接地意味着将AI响应锚定在可信的外部上下文中。当用户提问时,应用程序会提供相关信息给模型。微软将接地数据定义为在推理时提供给语言模型的信息,通过< a href="https://learn.microsoft.com/en-us/azure/well-architected/ai/grounding-data-design" rel="nofollow">微软Azure Well-Architected指南,利用原始训练数据中未包含的上下文来提高准确性和相关性。
数据接地之所以重要,是因为LLM预测语言。它们不会自动知道您最新的价格、政策、文档、客户记录或公开市场数据。没有可信的上下文,答案可能听起来很自信,但可能遗漏事实。通过数据接地,系统可以检索原始材料,将其插入提示中,并让模型从该材料中回答。
AI数据接地不仅仅是一个提示技巧。它是一种数据设计模式。它包括源选择、清理、索引、访问控制、检索、响应生成、引用、评估和监控。
为什么数据接地对AI准确性至关重要
数据接地通过缩小模型的答案空间来提高AI的可靠性。谷歌云将企业接地描述为将模型连接到网络信息、企业数据、数据库、应用程序和可信来源,通过< a href="https://cloud.google.com/blog/products/ai-machine-learning/grounding-gen-ai-in-enterprise-truth" rel="nofollow">谷歌云企业真相提高完整性和准确性。
这对于快速变化的领域很有用。库存、支持政策、文档、定价和活动日程经常变化。几个月前训练的模型无法知道每个更新。数据接地为应用程序提供了获取新鲜信息的路径,而无需每天重新训练模型。
数据接地还帮助团队解释答案。引用、时间戳和来源字段支持质量保证、合规审查和用户信任。
数据接地如何工作
数据接地通过检索和生成流程工作。系统首先确定哪些来源是可信的。然后为这些来源准备搜索。常见的来源包括帮助中心、手册、API、SQL数据库、向量索引、产品feed和批准的公共页面。
下一步是摄入。团队清理文档,删除重复项,标准化元数据,将内容拆分为块,并存储在搜索索引中。索引可能使用关键词搜索、向量搜索、混合搜索或图搜索。微软建议当外部化接地数据可以提高检索、性能和源系统保护时,通过AI接地数据设计将其外部化。
当用户提问时,系统会检索相关记录。它会根据权限、新鲜度、语言、地区或产品线进行过滤。然后将检索到的上下文添加到模型提示中。模型从该上下文中回答,并可能返回来源引用。
数据接地在检索精确时成功。强大的系统会衡量相关性、忠实度、延迟和源覆盖范围。
对比总结
数据接地与几种AI方法有重叠。下表显示了实际差异。
| 方法 | 主要目的 | 最佳使用场景 | 关键限制 |
|---|---|---|---|
| 数据接地 | 将答案锚定在可信上下文中 | 当前的、有来源支持的答案 | 需要强大的检索和治理 |
| RAG | 在生成前检索文档 | 知识库问答和支持代理 | 可能检索不相关或过时的上下文 |
| 微调 | 通过示例改变模型行为 | 风格、格式或领域行为 | 不适合改变事实 |
| 提示工程 | 通过指令引导行为 | 小任务和响应格式 | 无法单独提供缺失的事实 |
| 守护程序 | 强制执行政策和输出控制 | 安全、格式和合规检查 | 无法替代验证的来源上下文 |
此对比显示了为什么数据接地比RAG更广泛。RAG是一种常见的实现模式。数据接地是将模型输出连接到可靠证据的完整学科。
常见数据接地来源
数据接地从源质量开始。团队应根据权威性、新鲜度、所有权和权限级别对来源进行排名。
内部来源通常提供最大的商业价值。这些包括CRM记录、工单、政策、库存系统、产品规格和知识库。它们需要严格的访问控制。
外部来源增加新鲜度和广度。这些包括官方文档、政府指导、公开数据集、标准机构和可信的市场数据。NIST指出,其AI风险管理体系帮助组织管理对个人、组织和社会的风险通过NIST AI RMF。当编写可信AI系统的政策时,这些来源很有用。
公共网络数据可以支持市场监控、SEO研究和竞争分析。团队应保持合法和合理。他们应尊重网站条款、速率限制、适用的机器人指导和隐私义务。CapSolver的AI和自动化和自动化工作流资源是负责任流程的有用起点。
数据接地的生产工作流
数据接地在明确的操作模型中效果最佳。首先,定义答案边界。决定AI可以回答什么,可以使用哪些来源,以及何时必须拒绝或升级。
其次,准备数据。删除重复项、过时记录、私有字段和嘈杂的模板内容。添加元数据,如所有者、日期、地区、产品、语言和权限级别。这使检索更准确。
第三,设计检索。使用关键词搜索精确术语,使用向量搜索语义相似性,并使用过滤器获取允许的记录。
第四,评估性能。创建真实问题的测试集。评分检索相关性、答案忠实度、引用准确性和平均延迟。与领域专家审查边缘案例。不要仅依赖模型置信度。
第五,监控数据漂移。当文档过时、索引损坏、权限更改或用户意图变化时,数据接地可能会失败。关键系统需要自动新鲜度检查和人工审查路径。
合规性和安全性考虑
数据接地必须尊重法律、隐私和安全边界。技术访问并不意味着权限。接地的AI系统应避免使用私人、受限、敏感或未经授权的数据,除非组织有明确的合法依据和用户许可。
安全风险也很重要。OWASP列出了LLM应用的主要风险,包括提示注入、敏感信息泄露、过度代理和过度依赖,通过OWASP LLM应用Top 10。数据接地可以减少未经证实的声明,但如果检索接受恶意内容或暴露受保护的记录,它可能会引入风险。
团队应使用权限感知的检索。他们应清理不可信文本,记录源ID而不是敏感记录,并按分类分离数据。
自动化团队需要额外的注意。网络数据收集应专注于允许的公共数据、合理的请求速率和记录的业务目的。当授权的QA、监控或数据工作流中出现CAPTCHA挑战时,团队应将其视为流量验证的一部分。CapSolver的公共网络数据收集文章和CAPTCHA挑战指南可以帮助团队了解操作背景。
CapSolver在负责任的AI工作流中的位置
当数据接地依赖于合法的自动化工作流时,CapSolver是相关的。一些团队收集公共数据用于价格监控、SEO检查、广告验证、QA测试或研究。这些工作流可能在正常浏览或测试期间遇到CAPTCHA挑战。
CapSolver可以通过专为自动化环境设计的服务帮助团队处理这些挑战。建议是狭窄且以合规性为先。仅在您有授权、尊重适用规则并避免受限或敏感数据时使用。团队可以查看CapSolver产品以了解支持的场景并匹配到批准的工作流。
领取您的CapSolver优惠码
立即提升您的自动化预算!
在充值CapSolver账户时使用优惠码 CAP26,每次充值可获得额外 5% 的奖励——无限制。
立即在您的CapSolver仪表板中领取
数据接地和CAPTCHA处理不应随意混合。接地层决定AI可以使用的证据。自动化层在批准的规则下收集或检查数据。保持这些层的分离使审计更容易并减少运营风险。
接地AI系统的实用指标
数据接地需要可衡量的质量标准。检索相关性询问返回的上下文是否回答了问题。低分意味着模型正在使用弱证据。
答案忠实性询问答案是否在检索到的来源内。这是因为流畅的答案仍可能添加未经证实的细节。
引用准确性检查每个引用的来源是否支持其后的句子。新鲜度跟踪文档年龄、索引更新时间和来源更新频率。拒绝质量检查系统在证据缺失时是否说不。
结论和行动呼吁
数据接地是使AI系统更可靠的一种最实用的方法。它将答案连接到可信上下文,提高新鲜度,支持引用,并帮助团队管理风险。RAG通常是解决方案的一部分,但生产级的数据接地还需要干净的数据、强大的权限、评估、监控和负责任的自动化实践。
如果您的AI工作流依赖于公共数据监控、浏览器自动化、QA测试或研究,请仔细规划数据管道。保持源访问合法。保护敏感数据。在使用前审查输出。对于遇到CAPTCHA挑战的批准工作流,考虑将CapSolver作为合规自动化堆栈的一部分进行评估。
常见问题
什么是AI中的数据接地?
数据接地是将AI答案连接到可信上下文的过程。上下文可能来自文档、数据库、API、搜索索引或批准的公共来源。它帮助模型从证据中回答,而不是仅依赖训练数据。
数据接地和RAG是一样的吗?
不。RAG是实现数据接地的一种常见方式。数据接地更广泛。它包括源治理、索引、权限、检索评估、引用、监控和升级规则。
为什么数据接地减少了未经证实的AI答案?
数据接地通过在推理时为模型提供相关证据来减少未经证实的答案。模型可以基于当前上下文回答,而不是仅依靠统计模式填补空白。
应该使用哪些数据用于LLM的数据接地?
使用准确、允许、当前和相关数据。好的例子包括官方文档、产品记录、支持政策、知识库、公开数据集和批准的企业数据库。在没有适当授权的情况下避免私人或受限数据。
团队应如何负责任地应用数据接地?
团队应定义源规则,实施访问控制,监控检索质量,并审查高影响的输出。自动化团队应合法收集数据,尊重网站规则,并仅在授权的工作流中使用与CAPTCHA相关的服务。