为什么Chrome会阻止网站:安全与自动化访问的权衡解析

Ethan Collins
Pattern Recognition Specialist
TL;Dr:
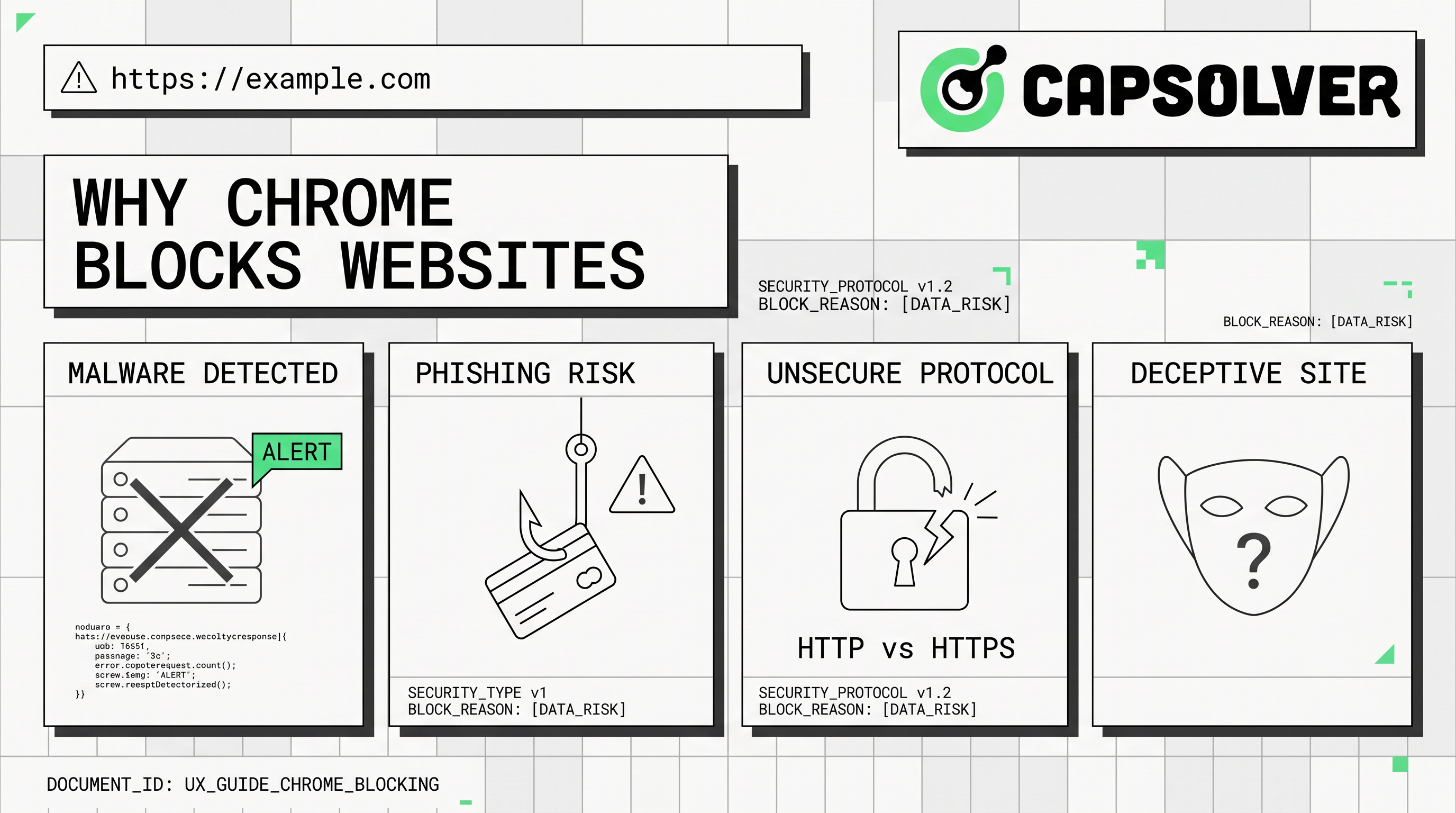
- Chrome主要出于用户安全考虑阻止网站,以对抗恶意软件、网络钓鱼和不安全的连接。
- 自动化工具经常遇到这些阻止,导致错误如
ERR_CONNECTION_REFUSED或验证码挑战。 - 理解Chrome的安全功能对于合法的网页自动化至关重要。
- 代理和VPN可以帮助克服地理限制,但并非所有浏览器级别的安全阻止都能绕过。
- CapSolver 提供了有效的验证码解决方案,确保更顺畅的自动化流程。
引言
Google Chrome 是互联网最受欢迎的入口,每天引导数十亿用户。这种广泛采用意味着 Chrome 承担着重要的用户安全责任。它主动阻止网站以保护用户免受各种在线威胁。然而,这些强大的安全措施经常给合法的网页自动化流程制造障碍。本文探讨了 Chrome 的必要浏览器安全与日益增长的无缝自动化访问需求之间的微妙平衡。我们将深入探讨 Chrome 为何阻止网站以及这些机制如何影响自动化任务,为普通用户和开发人员提供见解。
Chrome 的核心安全机制
Chrome 采用多层安全方法来保护其用户。这些机制不断演变以应对新威胁。了解这些核心功能有助于阐明 Chrome 为何阻止网站。
安全浏览
Chrome 的安全浏览功能是其安全框架的基石。它主动警告用户有关危险网站的信息。这包括已知的恶意软件、网络钓鱼和不需要的软件网站。当你遇到“chrome 阻止网站”的警告时,安全浏览通常在起作用。它维护不安全网站的列表,并实时检查页面是否符合这些列表 Google 安全浏览。这有助于防止意外访问恶意域名。
SSL/TLS 证书
安全套接字层(SSL)和传输层安全(TLS)证书对于加密通信至关重要。Chrome 严格检查这些证书以确保数据完整性和隐私。SSL 证书错误 chrome 表示网站证书存在问题。这可能是由于过期、配置错误或不受信任的颁发机构。Chrome 会显示 NET::ERR_CERT_AUTHORITY_INVALID 警告,阻止访问可能不安全的网站。这可以保护敏感信息免受拦截。
混合内容阻止
现代网站应通过安全的 HTTPS 连接加载所有资源。当安全的 HTTPS 页面尝试加载不安全的 HTTP 资源时,就会发生混合内容。Chrome 会阻止这种混合内容以防止漏洞。不安全的资源可能被利用来破坏整个安全页面。此阻止增强了网络浏览的整体安全态势。
沙盒架构
Chrome 运行在沙盒架构上,隔离不同的浏览器进程。这意味着如果一个标签页或扩展程序被破坏,它不会影响其他标签页或你的操作系统。这种隔离限制了恶意代码的破坏潜力。这是 Chrome 抵抗攻击的基本安全设计选择。
Chrome 阻止网站的常见原因
除了其核心安全功能外,还有一些具体问题可能导致 Chrome 阻止访问。这些问题范围从服务器端问题到用户特定设置。每个原因都对为什么 Chrome 阻止网站有所贡献。
ERR_CONNECTION_REFUSED
ERR_CONNECTION_REFUSED 错误是一个常见的连接失败消息。它意味着你的浏览器尝试连接到网站的服务器,但服务器主动拒绝了连接。这可能发生在服务器离线、过载或配置为阻止你的 IP 地址时。任一端的网络设置或防火墙规则也可能导致此错误 Google Chrome 帮助。对于自动化,这通常表示 IP 被封禁或速率限制。
ERR_NAME_NOT_RESOLVED
当 Chrome 显示 ERR_NAME_NOT_RESOLVED 时,表示 DNS 解析存在问题。浏览器无法将网站的域名转换为 IP 地址。这可能源于错误的 DNS 设置、临时 DNS 服务器故障或 URL 中的拼写错误。这实际上意味着 Chrome 无法在互联网上找到该网站。
地理限制
一些网站根据地理位置限制访问。这被称为地理限制。内容提供商通常由于许可协议或区域分发政策实施这些限制。如果你的 IP 地址显示你位于受限区域,Chrome 将阻止访问。这是在“解决地理限制 chrome”以获取内容时的常见挑战。
管理员或家长控制
在学校的网络环境中,网络管理员通常会实施内容过滤。家长控制软件也可以阻止特定网站。这些限制是在系统或网络级别执行的,而不是直接由 Chrome 的安全功能执行。然而,Chrome 仍将显示被阻止的页面消息。这是为了政策执行而有意的限制。
Chrome 扩展干扰
某些浏览器扩展可能会无意中导致网站被阻止。广告拦截器、隐私工具或安全扩展可能错误地将合法内容视为恶意。它们可能阻止页面正确加载或阻止特定元素。如果你遇到意外的阻止,逐个禁用扩展可以帮助确定罪魁祸首。
防火墙阻止
你的计算机的防火墙或杀毒软件也可能阻止 Chrome 访问网站。过于严格的防火墙规则可能会阻止合法的出站连接。这可能导致 ERR_CONNECTION_REFUSED 或其他连接错误。确保 Chrome 在你的安全软件中被白名单是不间断浏览的关键。
自动化面临的挑战
Chrome 的强大安全功能虽然对人类用户有益,但对网页自动化提出了独特的挑战。自动化脚本通常模仿人类行为,但可能被标记为可疑。这会导致自动化工具被“chrome 阻止网站”。
网络爬虫、自动化测试和数据收集是常见的自动化任务。这些活动需要对网络资源的持续访问。然而,网站部署了复杂的机器人检测机制。这些系统旨在区分人类用户和自动化脚本。当检测到自动化时,网站可以通过阻止访问、提供验证码或限制请求速率来做出反应。这在自动化开发人员和网站安全之间形成了持续的猫鼠游戏。
例如,自动化脚本如果在短时间内发起太多请求,可能会触发 ERR_CONNECTION_REFUSED。这是服务器端对潜在拒绝服务攻击的防御。同样,如果脚本未正确配置以处理证书验证,SSL 证书错误 chrome 可能会中止自动化。合法自动化的目的是以隐蔽和尊重的方式运行,避免触发这些安全措施。
合法自动化访问的策略
克服 Chrome 的阻止机制以实现合法自动化需要战略方法。这些方法旨在模仿人类浏览模式并解决常见的检测技术。有效的“解除 chrome 阻止网站”策略对成功自动化至关重要。
使用代理和 VPN
代理和 VPN 是管理网络级限制的关键工具。VPN 加密你的互联网流量并将其路由到不同位置的服务器。这有助于“解决 chrome 的地理限制”通过使浏览看起来像来自另一个国家。代理作为中介,隐藏你的原始 IP 地址。在“proxy vs vpn chrome”之间选择取决于具体的自动化需求。代理通常因灵活性和轮换 IP 地址的能力而被优先用于网络爬虫。然而,它们不像 VPN 那样加密流量 Cloudflare 学习。
处理 SSL 错误
对于自动化,SSL 证书错误 chrome 可能很麻烦。脚本需要配置为正确验证 SSL 证书,或在受控环境中解决验证问题。在生产环境中忽略 SSL 错误是不推荐的,因为存在安全风险。确保你的自动化环境拥有最新的根证书可以防止许多 NET::ERR_CERT_AUTHORITY_INVALID 问题。
管理浏览器指纹
网站使用浏览器指纹来识别和跟踪用户,包括自动化机器人。这涉及收集关于你的浏览器、操作系统和设备的数据。自动化工具必须实施技术来管理其浏览器指纹。这包括轮换用户代理、管理 cookies 以及模拟现实的鼠标移动和键盘输入。如果没有适当的指纹管理,自动化脚本很容易被检测和阻止。
CapSolver 解决验证码挑战
网页自动化中最常见的障碍之一是验证码挑战。这些测试旨在区分人类和机器人。当 Chrome 阻止网站,或者当网站的机器人检测触发时,验证码通常会出现。这就是 CapSolver 成为不可或缺的原因。CapSolver 提供自动验证码解决,允许你的自动化脚本无缝继续。它支持各种验证码类型,包括 reCAPTCHA v2、reCAPTCHA v3、Cloudflare Turnstile 等。这确保你的自动化可以高效地通过这些安全检查点。有关自动化为何在验证码上失败的更多信息,请参阅 为什么网页自动化不断在验证码上失败。
以下是使用 aiohttp 和 CapSolver 解决 reCAPTCHA v2 的 Python 示例:
python
import aiohttp
import json
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
PAGE_URL = "https://example.com/recaptcha_page"
SITE_KEY = "YOUR_RECAPTCHA_SITE_KEY"
async def create_capsolver_task(api_key, website_url, website_key):
url = "https://api.capsolver.com/createTask"
headers = {"Content-Type": "application/json"}
payload = {
"clientKey": api_key,
"task": {
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": website_url,
"websiteKey": website_key
}
}
async with aiohttp.ClientSession() as session:
async with session.post(url, headers=headers, data=json.dumps(payload)) as response:
return await response.json()
async def get_capsolver_result(api_key, task_id):
url = "https://api.capsolver.com/getTaskResult"
headers = {"Content-Type": "application/json"}
payload = {
"clientKey": api_key,
"taskId": task_id
}
async with aiohttp.ClientSession() as session:
async with session.post(url, headers=headers, data=json.dumps(payload)) as response:
return await response.json()
async def solve_recaptcha_v2():
# Create task
create_task_response = await create_capsolver_task(CAPSOLVER_API_KEY, PAGE_URL, SITE_KEY)
if create_task_response.get("errorId") != 0:
print(f"Error creating task: {create_task_response.get('errorDescription')}")
return None
task_id = create_task_response.get("taskId")
print(f"Task created with ID: {task_id}")
# Poll for result
while True:
get_result_response = await get_capsolver_result(CAPSOLVER_API_KEY, task_id)
if get_result_response.get("errorId") != 0:
print(f"Error getting result: {get_result_response.get('errorDescription')}")
return None
status = get_result_response.get("status")
if status == "ready":
g_recaptcha_response = get_result_response["solution"]["gRecaptchaResponse"]
print("reCAPTCHA solved successfully!")
return g_recaptcha_response
elif status == "processing":
print("Solving reCAPTCHA... waiting...")
await asyncio.sleep(5) # Wait for 5 seconds before polling again
else:
print(f"Unknown status: {status}")
return None
async def main():
# Example usage: solve reCAPTCHA and then submit to a page
recaptcha_token = await solve_recaptcha_v2()
if recaptcha_token:
print(f"Received reCAPTCHA token: {recaptcha_token}")
# Now you can use this token to submit a form or access the protected page
# For example:
# async with aiohttp.ClientSession() as session:
# data = {'g-recaptcha-response': recaptcha_token, 'other_form_field': 'value'}
# async with session.post(PAGE_URL, data=data) as response:
# print(await response.text())
if __name__ == "__main__":
import asyncio
asyncio.run(main())此代码片段展示了如何将 CapSolver 集成到你的 Python 自动化工作流中以处理 reCAPTCHA v2 挑战。有关更高级的爬虫技术,包括处理验证码,可以探索资源如 如何使用 n8n、CapSolver 和 OpenClaw 爬取验证码保护的网站。
领取 CapSolver 奖励代码
立即提升你的自动化预算!
在充值 CapSolver 账户时使用奖励代码 CAP26,每次充值可获得额外 5% 奖励——无限制。
现在在你的 CapSolver 仪表板 中领取
浏览器安全与自动化访问比较总结
| 功能/方面 | 浏览器安全视角 | 自动化访问视角 |
|---|---|---|
| 主要目标 | 保护用户免受威胁(恶意软件、网络钓鱼、数据泄露)。 | 高效且可靠地访问网页数据/功能。 |
| 阻止机制 | 安全浏览、SSL验证、混合内容、沙箱。 | IP封禁、速率限制、验证码、浏览器指纹检测。 |
| 常见错误 | SSL证书错误chrome、ERR_CONNECTION_REFUSED、NET::ERR_CERT_AUTHORITY_INVALID。 | ERR_CONNECTION_REFUSED、验证码提示、HTTP 403 禁止。 |
| 地理限制 | 为许可/区域政策强制执行。 | 通过代理/VPN克服(解决地理限制chrome)。 |
| 自动化影响 | 合法的自动化可能被误认为恶意活动。 | 需要复杂的技巧来模仿人类行为。 |
| 自动化解决方案 | 不直接适用;安全是针对人类交互的。 | 代理、VPN、用户代理轮换、验证码解决服务(例如,CapSolver)。 |
结论
Chrome对用户安全的承诺在其强大的阻止机制中显而易见。例如安全浏览和严格的SSL验证等功能对于安全的在线体验至关重要。然而,这些保护措施对网页自动化构成了重大挑战。从事自动化的开发人员和企业必须了解Chrome为何会阻止网站,以有效应对这些障碍。使用代理、管理浏览器指纹以及集成验证码解决服务(如CapSolver)等策略对于保持无缝的自动化访问至关重要。通过尊重网站政策并采用道德的自动化实践,可以平衡浏览器安全与自动化网络任务的需求。今天就探索CapSolver,以高效地增强您的自动化工作流程并克服验证码挑战。
常见问题
什么是ERR_CONNECTION_REFUSED?
ERR_CONNECTION_REFUSED意味着您的浏览器无法与网站的服务器建立连接。这通常表明服务器已关闭、正在阻止您的请求,或者您的网络存在问题。当chrome阻止网站时,这通常是服务器端问题。
Chrome安全浏览如何工作?
Chrome安全浏览通过维护已知恶意网站(恶意软件、网络钓鱼)的列表来保护您。当您尝试访问一个网站时,Chrome会将其与这些列表进行检查。如果发现匹配,会显示警告,防止您访问可能有害的页面。这是chrome安全浏览的关键功能。
VPN可以解除所有网站的封锁吗?
VPN可以帮助解除chrome网站封锁,这些网站受地理限制或本地网络过滤器的限制。然而,它无法解决所有类型的封锁。例如,如果一个网站有强大的机器人检测,或者Chrome因严重恶意软件而封锁了该网站,仅靠VPN可能不够。它对于解决chrome的地理限制很有效,但并非适用于所有安全封锁。
为什么我会遇到SSL证书错误chrome?
当网站的安全证书出现问题时,就会出现SSL证书错误chrome。这可能意味着证书已过期、未由受信任的机构颁发或配置错误。Chrome会阻止访问以保护您的数据免受不安全连接的威胁。确保您的系统日期和时间正确,这有时会导致此类错误。
自动化工具如何处理Chrome的封锁?
自动化工具可以通过使用代理或VPN进行IP轮换和地理解封来应对Chrome的封锁。它们还应管理浏览器指纹,使其看起来更像人类。对于验证码挑战,集成专门的解决服务(如CapSolver)非常有效。这些策略有助于解除chrome网站封锁,以进行合法的自动化任务。