urllib3 与 Requests:应该使用哪个 Python HTTP 库?

Ethan Collins
Pattern Recognition Specialist

TL;DR
- urllib3 与 Requests 的选择主要是低级控制与高级开发舒适度之间的权衡。
- 对于 API 客户端、小型脚本、数据流程和可读性高的应用代码,Requests 通常是更好的默认选择。
- 当你需要显式的连接池、重试行为、TLS 设置和库级别的传输控制时,urllib3 更为合适。
- 两个库都是同步的,因此对于繁重的异步工作负载,可能需要使用 HTTPX、aiohttp 或其他异步客户端。
- 对于遇到验证码挑战的合法自动化任务,CapSolver 可以支持挑战处理部分,而你的 HTTP 库负责处理常规请求。
引言
对于大多数团队而言,Requests 是最佳起点,而当传输控制比代码简洁性更重要时,urllib3 更为合适。本指南旨在帮助 Python 开发者在 API、爬虫、QA 自动化、监控和后端服务中选择 Python HTTP 库。核心价值很简单:当可维护性和开发速度更重要时选择 Requests,当需要直接控制连接池、重试和底层 HTTP 行为时选择 urllib3。如果你的自动化流程也面临流量验证或验证码挑战,CapSolver 可以作为合规挑战处理的解决方案,同时你的代码仍需遵守网站条款和数据访问规则。
简短答案:优先使用 Requests,需要控制时使用 urllib3
在 urllib3 与 Requests 的选择中,有一个实际的默认方案。除非你能清楚解释为何需要直接使用 urllib3,否则应优先使用 Requests。Requests 将 HTTP 表现为普通的 Python 方法。它通过简洁的 API 处理常见的需求,如请求头、参数、Cookie、会话、重定向、JSON 响应、流式下载和代理。官方的 Requests 文档也指出,Keep-Alive 和 HTTP 连接池是自动处理的,因为 Requests 底层使用了 urllib3 Requests 文档。
urllib3 并不是次等工具。它是许多 Python 项目依赖的传输引擎。urllib3 项目描述自己为一个具有线程安全连接池、重试、重定向、SSL/TLS 验证、压缩支持和代理支持的 HTTP 客户端 PyPI 上的 urllib3。这使其成为内部 SDK、基础设施服务和高吞吐量客户端的强选择,其中连接行为必须可见且可配置。
Requests 的优势
Requests 让普通的 HTTP 任务更简单。这是在 urllib3 与 Requests 的选择中它的主要优势。一个典型的 API 调用可以用几行代码完成,响应对象提供了清晰的属性,如状态码、文本、请求头和 JSON 解析。这对于由多个开发者维护的项目尤为重要,而不仅仅是最初编写脚本的人。
Requests 还拥有庞大的生态系统。其 PyPI 页面显示每周约有 3 亿次下载,并在项目描述中列出超过 400 万个依赖仓库 PyPI 上的 Requests。流行度不应单独决定架构,但它提高了故障排查、示例和代码审查的熟悉度。
urllib3 的优势
urllib3 提供了更接近传输层的访问。这就是为什么 urllib3 与 Requests 的选择不是简单的初学者与专家比较。urllib3 将 PoolManager 作为核心概念。其用户指南解释了 PoolManager 处理连接池和线程安全,并且 request() 方法可以使用任何 HTTP 动词发起请求 urllib3 用户指南。
这种显式模型在 HTTP 客户端是更大系统的一部分时非常有用。你可以推理连接池大小、主机特定行为、重试策略、超时、重定向、TLS 详细信息和响应流式处理。当构建可重用的 SDK 或在负载下必须表现可预测的服务时,这种控制非常有用。
对比总结
在比较决策因素时,urllib3 与 Requests 的选择会更清晰。以下表格采用实用评分风格,而非通用功能列表。
| 决策因素 | Requests | urllib3 | 更佳选择 |
|---|---|---|---|
| 初学者可读性 | 非常强,使用简单的方法如 get() 和 post() | 良好,但更需要显式设置 | Requests |
| 连接池 | 通过 Sessions 自动处理,且底层使用 urllib3 | 通过 PoolManager 直接处理 | 平局,urllib3 提供更多控制 |
| 重试配置 | 通过 adapters 使用 urllib3 工具实现 | 原生且显式 | urllib3 |
| JSON 响应处理 | 非常方便 | 现代 urllib3 支持,但更底层的使用更常见 | Requests |
| TLS 和传输调优 | 可行,但更抽象 | 更直接且可见 | urllib3 |
| API 集成 | 易于编写和审查 | 当传输细节重要时表现良好 | Requests |
| 内部 SDK | 适合简单的 SDK | 在传输行为控制方面更强 | urllib3 |
| 异步工作负载 | 默认不适合 | 默认不适合 | 考虑其他替代方案 |
语法与开发体验
Requests 在首次阅读时更清晰。在 urllib3 与 Requests 的示例中,Requests 通常更接近自然的 Python 语法。一个基本调用通常读起来像直接操作,如 requests.get(url)。同样的 urllib3 调用可能需要方法字符串、PoolManager 或直接处理响应字节,具体取决于模式。
urllib3 并不难读。它更显式。这种差异在生产环境中很重要,因为显式的客户端更容易检查隐藏状态。然而,对于编写普通 API 客户端的团队,额外的控制可能带来不必要的代码复杂性。最佳规则是直接的:除非传输层是你的应用设计的一部分,否则使用 Requests 编写应用代码。
性能、连接池与扩展性
性能不能仅凭一个基准测试来判断。在 urllib3 与 Requests 的选择中,两者都可以足够快,因为 Requests 使用 urllib3 作为底层 HTTP 引擎。更重要的是你如何重用连接、设置超时、处理重试和关闭响应。
对于小型脚本,Requests 的开销通常不是主要问题。网络延迟、服务器响应时间、速率限制、DNS、TLS 协商和负载大小通常更重要。对于长时间运行的工作者,urllib3 可能更容易调优,因为 PoolManager 让连接行为更可见。无论使用哪个库,超时和重试规则应明确,尤其是在 POST、PUT 或类似支付的操作中。
网络爬虫、自动化与负责任的使用
在网络爬虫讨论中也会出现 urllib3 与 Requests 的选择。Requests 很常见,因为它保持了请求头、Cookie 和会话的可读性。当连接池和底层传输设置很重要时,urllib3 更有用。对于公共数据监控或 QA 自动化,只要目标允许自动化访问,任一库都可以使用。
合规性不是可选的。技术能力并不意味着有权访问私人、受限、敏感或未经授权的数据。在相关情况下,应审查 robots.txt,阅读服务条款,遵守速率限制,适当标识你的客户端,并在没有合法依据时避免收集个人或机密数据。CapSolver 的 网络爬虫常见问题 和 AI 与自动化常见问题 是设计自动化流程的团队内部的重要参考资料。
当一个被允许的流程遇到验证码挑战时,HTTP 库只是系统的一部分。Requests 或 urllib3 可以发送常规 HTTP 请求,但挑战处理可能需要专用服务。CapSolver 在其官方文档中记录了 API 服务器端点和 createTask 流程 CapSolver API 服务器文档 CapSolver createTask 文档。仅使用官方文档,不要自行发明任务参数或端点。
领取 CapSolver 奖励代码
立即提升你的自动化预算!
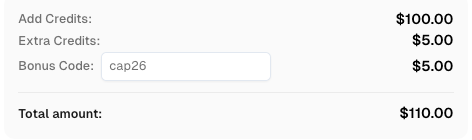
在充值 CapSolver 账户时使用奖励代码 CAP26,每次充值均可获得额外 5% 奖励——无限制。
现在在你的 CapSolver 仪表板 中领取
如需更多背景信息,CapSolver 的 网络爬虫中解决验证码的指南 将这些议题与真实的 Python 流程联系起来。
按项目类型决定的框架
urllib3 与 Requests 的选择应基于项目类型,而非个人偏好。对于一次性脚本,Requests 通常是正确的答案。它降低了代码量并减少了审查摩擦。对于需要自定义重试规则调用多个主机的内部服务,urllib3 可能是更好的基础。
对于要交付给客户的 API 客户端库,需谨慎选择。Requests 为用户提供了熟悉的依赖和清晰的示例。urllib3 为维护者提供了更多控制和更少的传输层抽象。对于爬虫和监控,Requests 通常足以处理允许的页面和简单响应。如果你管理多个主机、长时间运行的工作者和调优的连接池,urllib3 值得认真考虑。
避免的常见错误
第一个错误是将 urllib3 与 Requests 视为纯粹的速度竞赛。大多数真实系统受限于网络条件、服务器行为和工作流设计。在用低级库替换清晰库之前,先进行测量。
第二个错误是忽略超时设置。没有超时的请求可能会挂起工作者并隐藏失败。两个库都支持超时模式,因此在生产代码中应将超时作为标准。
第三个错误是未考虑幂等性就重试不安全操作。失败的响应并不总是意味着服务器未能执行操作。应围绕 HTTP 方法、端点行为和业务影响来构建重试规则。
第四个错误是忽视自动化中的合规性。Python HTTP 库只是一个工具,而非权限。对于验证码相关话题,应将 CapSolver 的 验证码解决常见问题 作为更广泛的法律和运营审查的一部分来使用。
结论 / 行动呼吁
urllib3 与 Requests 有实际答案。对于大多数应用代码,优先使用 Requests,因为它可读性强、流行度高且基于 urllib3。当你需要直接控制连接池、重试、TLS 行为和传输层设计时,才转向 urllib3。不要因为模糊的性能原因更换库;先对实际工作负载进行性能分析。
对于合规的自动化,将常规 HTTP 访问与挑战处理分开。Requests 或 urllib3 可以管理 HTTP 通信,而官方的 CapSolver 文档可以在你的工作流被授权且合理时指导验证码相关任务。如果你的团队需要专门处理自动化中的验证码挑战的服务,考虑 CapSolver 作为负责任的 Python 流程的一部分。
常见问题
Requests 是否只是 urllib3 的封装?
Requests 在连接池和 HTTP 传输方面使用了 urllib3,但它不仅仅是轻量级封装。它增加了更简单的 API、会话、Cookie、认证助手、响应便利性和庞大的用户生态系统。
urllib3 是否比 Requests 更快?
urllib3 可能有更少的封装开销,但实际性能取决于连接复用、超时、负载大小、DNS、TLS 和服务器延迟。在大多数 API 客户端中,Requests 足够快。在切换之前,先测量你自己的工作负载。
网络爬虫应该使用 urllib3 还是 Requests?
对于大多数允许的爬虫任务,使用 Requests,因为它更容易阅读和维护。当你需要更严格的连接池、重试和传输行为控制时,使用 urllib3。始终遵循网站条款、速率限制和数据保护规则。
urllib3 和 Requests 是否支持异步请求?
它们默认是同步库。如果你的项目需要异步并发,应评估 HTTPX、aiohttp 或其他异步 HTTP 客户端,而不是强制让 urllib3 或 Requests 承担此角色。
CapSolver 可以用于 Python HTTP 流程吗?
可以,CapSolver 可以支持授权自动化流程中的验证码挑战处理。将常规 HTTP 逻辑保留在 Requests 或 urllib3 中,并仅根据官方文档和适用规则使用 CapSolver。