使用Python Requests解决CAPTCHA挑战

Rajinder Singh
Deep Learning Researcher

令人沮丧的验证码……
1. 为什么解决验证码很重要

永恒的斗争——验证码试图区分人类和机器人
虽然验证码保护网站免受垃圾邮件的侵害,但它们可能会阻止合法的自动化操作,例如:
- 研究项目: 学术和市场研究通常需要从网站大规模收集数据。
- 辅助工具: 为残疾用户设计的工具可能需要浏览验证码才能提供内容。
- 数据迁移脚本: 在系统之间传输数据时,自动化脚本可能会遇到验证码。
- 学术研究: 收集数据以研究互联网趋势、用户行为或技术采用的学者。
- 价格比较和市场分析: 抓取电子商务网站上的产品价格以分析市场趋势。
- 电子商务产品抓取: 监控竞争对手的网站以跟踪产品的可用性和价格。
- 广告验证: 确保在线广告正确显示,并且不会被机器人操纵。
- SEO 和网站监控: 自动化检查网站性能、正常运行时间和内容更改。
- 社交媒体数据收集: 从社交平台聚合公共帖子或趋势以进行情绪分析。
- 网络安全研究: 分析潜在漏洞或测试安全措施的稳健性。
- 内容聚合: 自动收集文章或博客文章以用于新闻聚合服务。
2. 设置工具包
您的 Capsolver 仪表板 - API 密钥所在位置
安装需求:
bash
pip install requests获取您的 API 密钥:
- 在 capsolver.com 创建帐户
- 导航到 API 概述
- 复制您的
clientKey
3. 分步实施
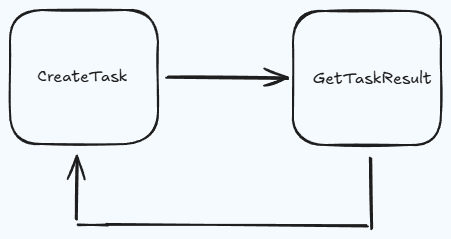
验证码解决过程的工作原理
完整的代码演练:
python
# pip install requests
import requests
import time
# TODO: 设置您的配置
api_key = "YOUR_API_KEY" # 您的 capsolver api 密钥
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_kl-" # 您目标网站的站点密钥
site_url = "" # 您目标网站的页面 URL
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV3TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url,
"pageAction": "login",
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("创建任务失败:", res.text)
return
print(f"获取 taskId:{task_id} / 获取结果...")
while True:
time.sleep(1) # 延迟
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("解决失败!响应:", res.text)
return
token = capsolver()
print(token)4. 了解任务类型
您将遇到的常见验证码类型
| 任务类型 |
|---|
| ReCaptchaV2Task / ReCaptchaV2TaskProxyless |
| ReCaptchaV3Task / ReCaptchaV3TaskProxyless |
| GeeTestTask / GeeTestTaskProxyless |
| AntiTurnstileTaskProxyless |
| ImageToTextTask |
5. 故障排除常见问题

当您的验证码解决方案失败时……
常见修复:
- 双重检查 API 密钥权限
- 验证网站 URL、websiteKey、pageAction 或其他必需/可选参数是否完全匹配
- 使用不同的验证码类型进行测试
- 联系 capsolver 支持
