2025年R语言网络爬虫入门完整指南

Ethan Collins
Pattern Recognition Specialist

你是否也好奇数据科学家是如何收集大量的在线数据用于研究、营销和分析?R语言中的网页抓取是一项强大的技能,可以将在线内容转换成有价值的数据集,从而实现数据驱动的决策和更深入的洞察。那么,是什么让网页抓取如此具有挑战性,R语言又如何提供帮助呢?本指南将引导你设置R环境、从网页提取数据、处理动态内容等更复杂的场景,并最终介绍一些最佳实践,以确保你的行为合乎道德和规范。
为什么选择R?
R语言是一种主要用于统计分析和数据可视化的语言和环境。它最初在学术界的统计学家群体中流行,如今其用户群体已扩展到各个领域的科研人员。随着大数据的兴起,来自计算机和工程背景的专业人士也对增强R的计算引擎、性能和生态系统做出了重大贡献,推动了它的发展。
作为一个集统计分析和图形显示于一体的工具,R语言功能多样,可在UNIX、Windows和macOS系统上无缝运行。它拥有强大的、用户友好的帮助系统,专为数据科学而设计,提供了一套丰富的、以数据为中心的库,非常适合网页抓取等任务。
但是,无论你使用哪种编程语言进行网页抓取,都必须遵守网站的robots.txt协议。该文件位于大多数网站的根目录下,指定哪些页面可以抓取,哪些页面不能抓取。遵守此协议有助于避免与网站所有者发生不必要的纠纷。
设置R环境
在使用R进行网页抓取之前,请确保你已正确配置R环境:
-
下载并安装R:
访问R Project官方网站并下载适合你操作系统的安装包。 -
选择R的IDE:
选择一个开发环境来运行R代码:- PyCharm: 一个流行的Python IDE,可以通过插件支持R。访问JetBrains网站下载它。
- RStudio: 一个专为R设计的IDE,提供无缝且集成的体验。访问Posit网站下载RStudio。
-
如果使用PyCharm:
你需要安装R Language for IntelliJ插件才能在PyCharm中运行R代码。
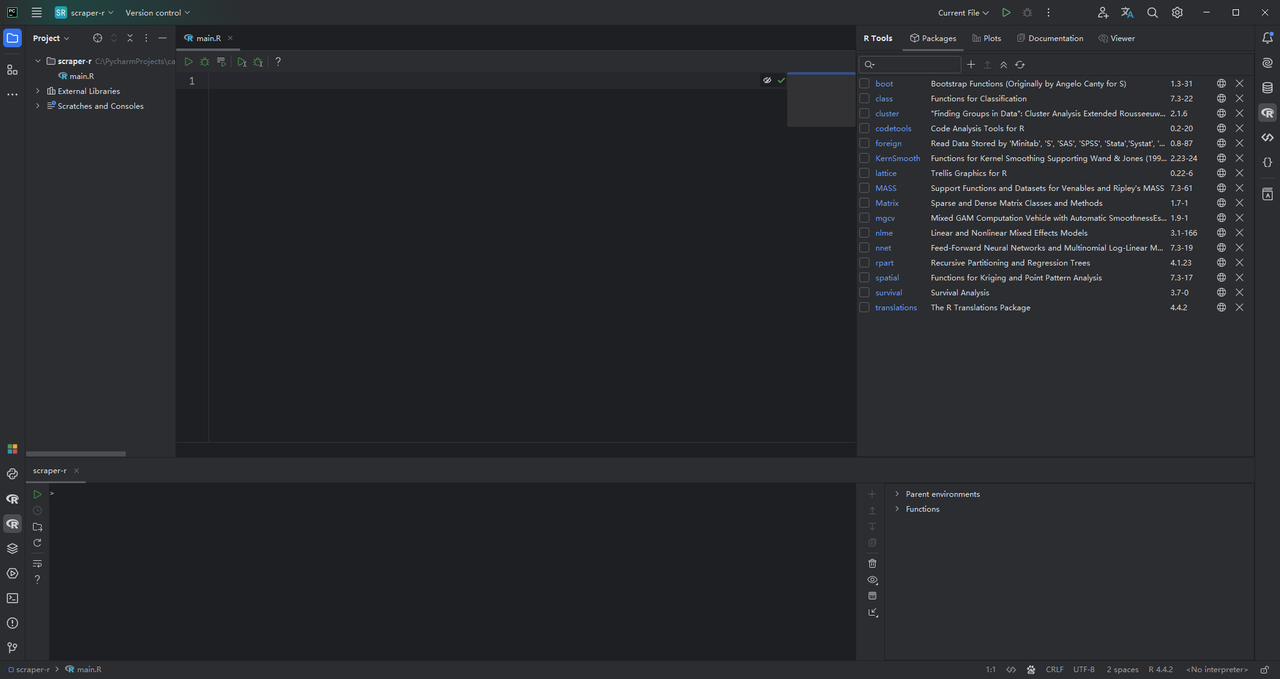
在本指南中,我们将使用PyCharm创建我们的第一个R网页抓取项目。首先打开PyCharm并创建一个新项目。

点击“创建”,PyCharm将初始化你的R项目。它将自动生成一个空白的main.R文件。在界面的右侧和底部,你会分别找到R工具和R控制台选项卡。这些选项卡允许你管理R包并访问R shell,如下图所示:
使用R进行数据抓取
让我们以ScrapingClub的第一个练习为例,演示如何使用R抓取产品图片、标题、价格和描述:
1. 安装rvest
rvest是一个旨在辅助网页抓取的R包。它简化了常见的网页抓取任务,并与magrittr包无缝协作,提供了一个易于使用的管道来提取数据。该包的灵感来自Beautiful Soup和RoboBrowser等库。
要在PyCharm中安装rvest,请使用位于界面底部的R控制台。输入以下命令:
R
install.packages("rvest")在安装开始之前,PyCharm将提示你选择一个CRAN镜像(包源)。选择离你最近的一个以加快下载速度。安装完成后,你就可以开始抓取了!
2. 访问HTML页面
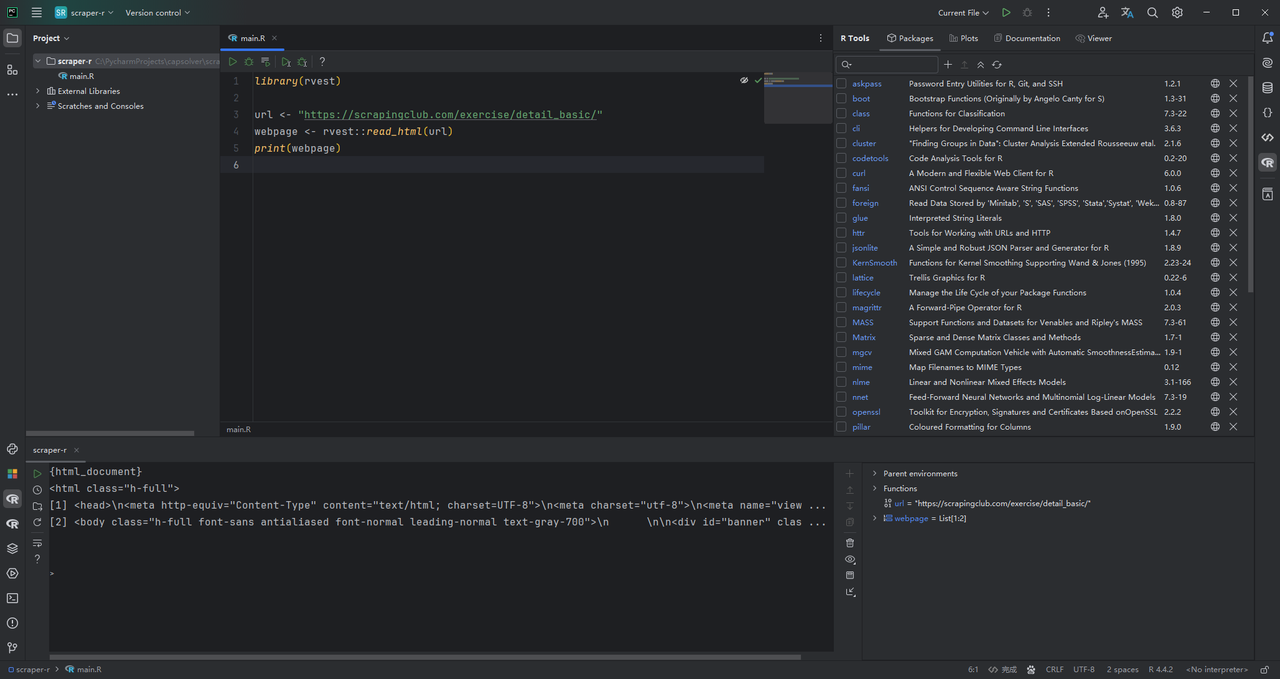
rvest包提供了read_html()函数,该函数在给出网页的URL时会检索网页的HTML内容。以下是如何使用它来获取目标网站的HTML:
R
library(rvest)
url <- "https://scrapingclub.com/exercise/detail_basic/"
webpage <- rvest::read_html(url)
print(webpage)运行此代码将在R控制台中输出页面的HTML源代码,让你清楚地了解网页的结构。这是提取特定元素(如产品详细信息)的基础。
3. 解析数据
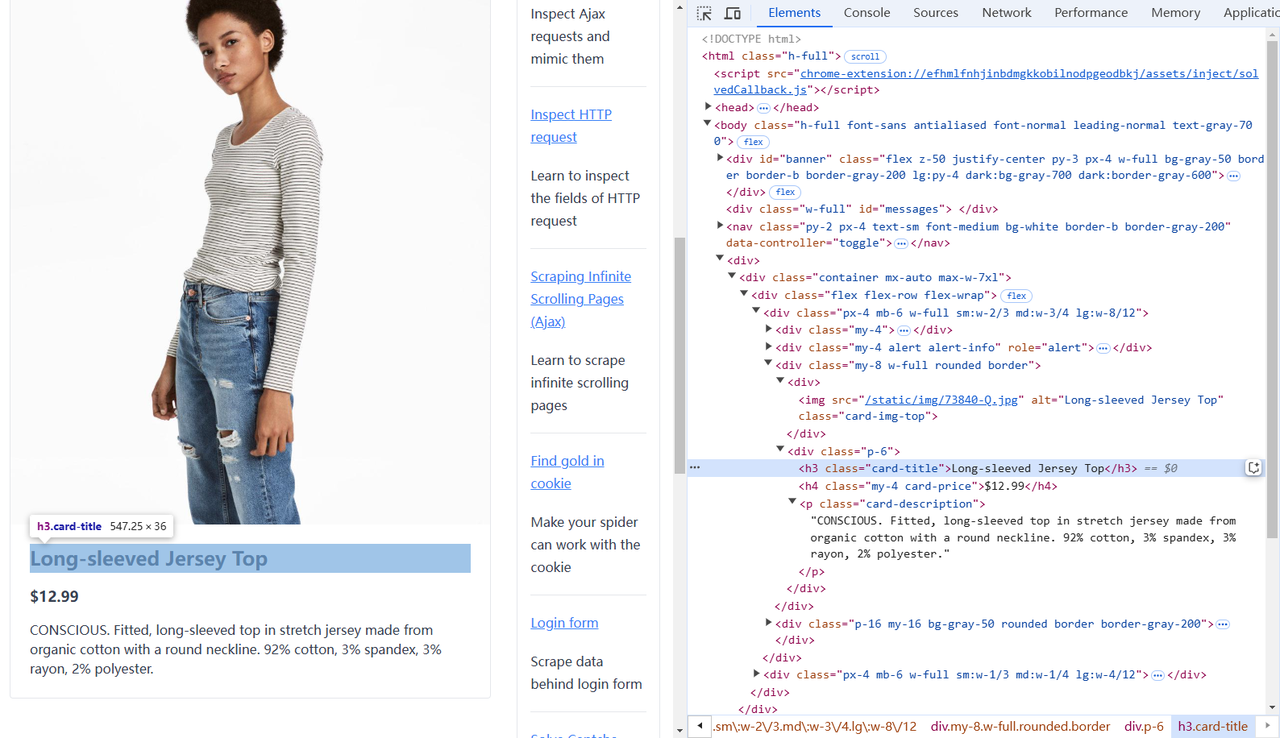
要从网页中提取特定数据,我们首先需要了解其结构。使用浏览器的开发者工具,你可以检查元素并确定所需数据的位置。以下是示例页面上目标元素的细分:
- 产品图片: 位于具有
card-img-top类的img标签中。 - 产品标题: 位于
<h3>元素内。 - 产品价格: 位于
<h4>元素内。 - 产品描述: 位于具有
card-description类的<p>标签中。
R中的rvest包提供了强大的工具来解析和提取HTML文档中的内容。以下是一些用于网页抓取的关键函数:
html_nodes(): 选择与指定的CSS选择器匹配的文档中的所有节点(HTML标签)。它允许你使用类似CSS的语法有效地过滤内容。html_attr(): 从选定的HTML节点中提取指定属性的值。例如,你可以检索图像的src属性或链接的href属性。html_text(): 提取选定HTML节点内的纯文本内容,忽略HTML标签。
以下是如何使用这些函数从示例页面抓取数据:
R
library(rvest)
# 目标网页的URL
url <- "https://scrapingclub.com/exercise/detail_basic/"
webpage <- rvest::read_html(url)
# 提取数据
img_src <- webpage %>% html_nodes("img.card-img-top") %>% html_attr("src") # 图片源
title <- webpage %>% html_nodes("h3") %>% html_text() # 产品标题
price <- webpage %>% html_nodes("h4") %>% html_text() # 产品价格
description <- webpage %>% html_nodes("p.card-description") %>% html_text() # 产品描述
# 显示提取的数据
print(img_src)
print(title)
print(price)
print(description)代码说明
- 读取HTML:
read_html()函数获取目标网页的整个HTML结构。 - 提取数据: 使用
html_nodes()和CSS选择器,你可以定位特定的元素,例如图片、标题和描述。 - 检索属性/文本:
html_attr()函数提取属性值,例如图片的src,而html_text()则检索标签内的文本内容。
输出示例
运行上述代码后,提取的数据将显示在你的R控制台中。例如:
- 图片URL: 产品图片的路径,例如
/images/example.jpg。 - 标题: 产品名称,例如*"示例产品"*。
- 价格: 价格信息,例如*"$20.99"*。
- 描述: 产品描述,例如*"这是一件高质量的商品。"*。
这使你可以有效地从网页收集结构化数据,以便进一步分析或存储。
结果预览
运行脚本后,你应该在R控制台中看到提取的内容,如下所示:

使用rvest,你可以自动化各种结构化数据需求的网页抓取过程,确保输出干净且可操作。
数据抓取中的挑战
在现实世界的数据抓取场景中,这个过程很少像本文演示的那样简单。你经常会遇到各种机器人挑战,例如广泛使用的reCAPTCHA和类似的系统。
这些系统旨在通过实施以下措施来验证请求是否合法:
- 请求头验证: 检查你的HTTP头是否遵循标准模式。
- 浏览器指纹检查: 确保你的浏览器或抓取工具模拟真实用户的行为。
- IP地址风险评估: 确定你的IP地址是否因可疑活动而被标记。
- 复杂的JavaScript加密: 需要进行高级计算或混淆参数才能继续。
- 具有挑战性的图片或文本识别: 强制求解器从CAPTCHA图片中正确识别元素。
所有这些措施都可能严重阻碍你的抓取工作。但是,不用担心。CapSolver可以有效地解决每一个机器人挑战。
为什么选择CapSolver?
CapSolver采用AI驱动的自动网页解锁技术,能够在几秒钟内解决即使是最复杂的CAPTCHA挑战。它可以自动化诸如解码加密的JavaScript、生成有效的浏览器指纹以及解决高级CAPTCHA难题等任务,确保不间断的数据收集。
索取顶级验证码解决方案的奖励代码;CapSolver:WEBS。兑换后,每次充值后将获得额外5%的奖励,无限量

易于集成
CapSolver提供多种编程语言的SDK,使你可以将它的功能无缝集成到你的项目中。无论你使用Python、R、Node.js还是其他工具,CapSolver都能简化实施过程。
文档和支持
官方的CapSolver文档提供了详细的指南和示例,以帮助你入门。你可以在那里探索其他功能和配置选项,确保流畅高效的抓取体验。
总结
使用R进行网页抓取为数据收集和分析开辟了无限可能,将非结构化的在线内容转化为可操作的见解。借助rvest等高效的数据提取工具和CapSolver等服务来克服抓取挑战,你可以简化甚至是最复杂抓取项目。
但是,始终要记住道德抓取实践的重要性。遵守网站指南、尊重robots.txt文件并确保符合法律标准对于维护负责任和专业的的数据收集方法至关重要。
掌握了本指南中分享的知识和工具,你就可以开始你的R语言网页抓取之旅了。随着你经验的积累,你将发现处理各种场景的方法,扩展你的抓取工具包,并释放数据驱动决策的全部潜力。