如何在无需浏览器的情况下解决AWS WAF挑战:技术指南

Ethan Collins
Pattern Recognition Specialist
无需浏览器绕过AWS WAF挑战
TL;Dr:
- 无需浏览器解决AWS WAF挑战可以消除对资源密集型无头浏览器(如Puppeteer)的需求。
- 该过程需要从405状态码响应中提取特定的加密参数。
- CapSolver的API处理生成有效aws-waf-token所需的复杂JS执行和解密。
- 集成无浏览器求解器可以将基础设施成本降低多达80%,同时提高自动化速度。
介绍
自动化从受Amazon Web Services保护的网站收集数据时,通常会遇到一个重大的技术障碍:AWS WAF挑战。传统上,开发人员依赖无头浏览器来执行所需的JavaScript并解决这些难题。然而,根据Imperva恶意机器人报告2025,如今机器人流量已占互联网活动的近50%,安全措施变得更加严格。为每次请求运行完整的浏览器实例不仅速度慢,而且在大规模情况下也非常昂贵。本指南专注于更高效的方法:如何在无需浏览器的情况下解决AWS WAF挑战。了解如何在无需浏览器的情况下解决AWS WAF挑战对于现代网络爬虫至关重要。通过使用基于令牌的API策略,您可以以最小的开销和最大的可靠性绕过这些安全层。
AWS WAF挑战的架构
要无需浏览器解决挑战,您首先需要了解请求被拦截时会发生什么。掌握如何在无需浏览器的情况下解决AWS WAF挑战需要深入研究405状态码。AWS WAF通常使用两种主要方法验证流量:无声JavaScript挑战和可见CAPTCHA。当您的爬虫访问受保护的资源时,服务器可能会返回202或405状态码。每种都需要不同的参数集来解决。理解这些响应是构建无浏览器解决方案的第一步。
202状态码与405状态码
服务器返回的状态码决定了您需要解决的挑战的复杂性。202状态码通常表示一个简单的仅JavaScript挑战,而405状态码意味着需要完整的CAPTCHA或更复杂的检查。
| 状态码 | 挑战类型 | 所需参数 |
|---|---|---|
| 202 已接受 | 无声JS挑战 | awsChallengeJS URL |
| 405 方法不允许 | 完整CAPTCHA / 检查 | awsKey, awsIv, awsContext, awsChallengeJS |
对于希望扩展的开发人员来说,程序化识别这些代码至关重要。您可以在我们关于如何处理AWS WAF 405状态码的详细指南中了解更多这些响应的具体信息。
为什么选择无浏览器?
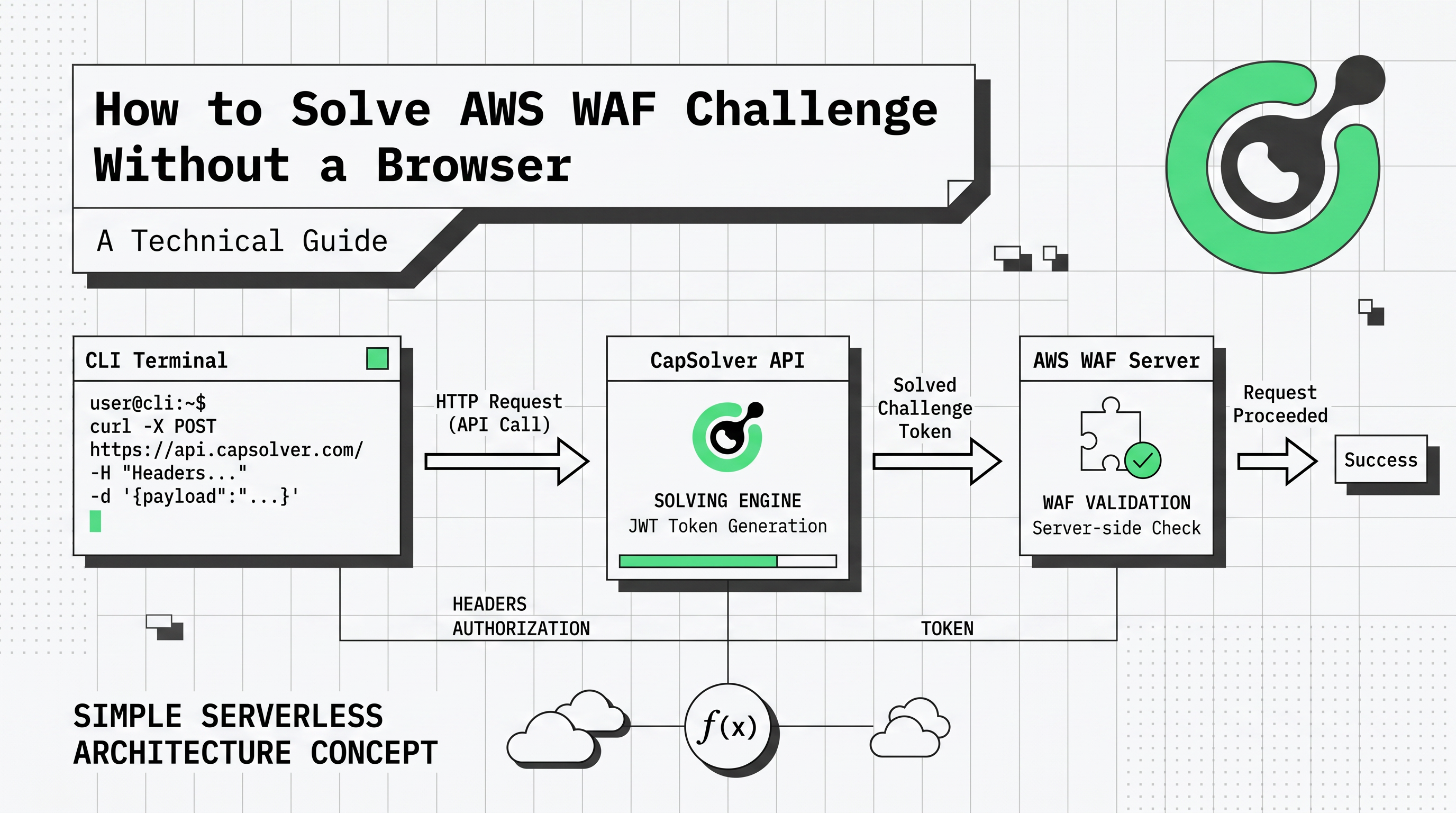
无浏览器求解的转变是由效率需求驱动的。许多开发人员现在询问如何在无需浏览器的情况下解决AWS WAF挑战以节省服务器成本。这就是为什么学习如何在无需浏览器的情况下解决AWS WAF挑战已成为优先事项。无头浏览器消耗大量CPU和内存,通常需要专门的基础设施才能可靠运行。相比之下,无浏览器方法使用标准HTTP客户端(如Python的requests或Node.js的axios)直接与求解API通信。这种方法可以将基础设施成本降低多达80%,同时提高每次请求的效率。
绕过JavaScript执行需求
在无浏览器环境中,主要障碍是执行AWS挑战脚本。该脚本旨在收集浏览器指纹并解决加密难题。通过使用CapSolver等服务,您可以将此执行卸载到专用服务器。API会获取AWS响应的原始参数,并返回最终的aws-waf-token,而无需渲染页面。这是任何现代网络爬虫工具详解指南的核心组成部分。
无浏览器集成的分步方法
实现无浏览器解决方案涉及三个主要阶段:拦截、求解和注入。这是如何在无需浏览器的情况下解决AWS WAF挑战的标准工作流程。通过遵循此方法,您可以有效地学习如何在无需浏览器的情况下解决AWS WAF挑战。此工作流程确保您的自动化脚本即使在面对严格的AWS WAF规则时也能保持有效会话。
第1步:拦截挑战
当您的脚本收到405响应时,您必须解析HTML以查找加密的挑战参数。这些参数通常出现在脚本标签中或作为页面的元数据。您需要提取awsKey、awsIv和awsContext,以及awsChallengeJS文件的URL。
python
import requests
from bs4 import BeautifulSoup
def extract_aws_parameters(url):
response = requests.get(url)
if response.status_code == 405:
soup = BeautifulSoup(response.text, 'html.parser')
# 示例提取逻辑(实际实现取决于页面结构)
aws_key = soup.find('input', {'id': 'aws-waf-key'})['value']
aws_iv = soup.find('input', {'id': 'aws-waf-iv'})['value']
aws_context = soup.find('input', {'id': 'aws-waf-context'})['value']
js_url = soup.find('script', {'src': True})['src']
return aws_key, aws_iv, aws_context, js_url
return None第2步:创建求解任务
一旦您获得参数,就可以将它们提交到CapSolver API。对于无浏览器设置,AntiAwsWafTaskProxyless通常是最佳选择,因为它使用专为AWS优化的内部代理池。
python
def create_capsolver_task(api_key, website_url, aws_key, aws_iv, aws_context, js_url):
payload = {
"clientKey": api_key,
"task": {
"type": "AntiAwsWafTaskProxyless",
"websiteURL": website_url,
"awsKey": aws_key,
"awsIv": aws_iv,
"awsContext": aws_context,
"awsChallengeJS": js_url
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
return response.json().get("taskId")此请求返回一个taskId。然后,您需要轮询getTaskResult端点,直到状态变为ready。有关此过程的更多技术细节,请参考AWS WAF令牌求解指南。
第3步:获取结果
轮询结果是无浏览器工作流程中的关键部分。您应实现一个带有短延迟的循环来检查任务状态。
python
import time
def get_task_result(api_key, task_id):
payload = {
"clientKey": api_key,
"taskId": task_id
}
while True:
response = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
result = response.json()
if result.get("status") == "ready":
return result.get("solution").get("cookie")
time.sleep(3)第4步:注入令牌
最后一步是获取API返回的令牌,并将其添加到HTTP客户端的cookie池中。该cookie必须命名为aws-waf-token。一旦此cookie存在,对受保护网站的后续请求将被视为合法流量。
python
def make_protected_request(url, token):
cookies = {'aws-waf-token': token}
response = requests.get(url, cookies=cookies)
return response.text高流量自动化高级策略
对于企业级爬虫,仅仅解决挑战是不够的。您还必须管理您的指纹和代理以避免被AWS的行为分析标记。
代理管理与指纹识别
即使没有浏览器,AWS WAF也可以分析您的请求的头部和TLS指纹。建议使用高质量的住宅代理并频繁更换用户代理字符串。如果您还处理其他安全层,可能会发现我们的指南最佳代理服务对保持全面的自动化策略有所帮助。
监控与反馈
实施反馈循环对长期成功至关重要。通过使用feedbackTask端点,您可以告知求解服务令牌是否成功。这些数据有助于改进求解算法,并确保针对您特定目标网站的更高成功率。这种级别的集成是专业AWS求解器的标志。
结论
学习如何在无需浏览器的情况下解决AWS WAF挑战对需要扩展自动化的开发人员来说是一个变革性突破。一旦您掌握如何在无需浏览器的情况下解决AWS WAF挑战,您就可以运行数千个并发任务。通过远离资源密集型无头浏览器并采用基于令牌的API方法,您可以实现更快、更经济的结果。CapSolver提供了处理AWS所需的复杂解密和JS执行的必要工具,使您能够专注于核心数据收集任务。
常见问题
-
仅使用Python requests能否解决AWS WAF挑战?
是的,通过使用CapSolver等求解API,您可以提取挑战参数并获取可与Pythonrequests库一起使用的有效令牌。这完全消除了对浏览器的需求。 -
AntiAwsWafTask和AntiAwsWafTaskProxyless之间有什么区别?
AntiAwsWafTask要求您提供自己的代理,求解器将使用这些代理与AWS交互。AntiAwsWafTaskProxyless使用CapSolver的内部代理池,这通常更适合无浏览器设置。 -
获取aws-waf-token需要多长时间?
平均而言,求解过程需要5到15秒,具体取决于挑战的复杂性和当前网络延迟。 -
能否将此方法用于其他AWS服务?
此方法专门针对受AWS WAF保护的网站。如果目标网站使用其他AWS安全功能,参数和任务类型可能会有所不同。 -
哪里可以找到完整的API文档?
所有任务类型和端点的完整技术参考可在CapSolver API文档中找到。
深入解析:令牌生成机制
要真正掌握如何在无需浏览器的情况下解决AWS WAF挑战,必须深入了解挑战阶段发生的加密交换。这是如何在无需浏览器的情况下解决AWS WAF挑战中最技术性的部分。AWS WAF不仅检查有效cookie,还会验证令牌的整个生命周期。这包括检查生成令牌的IP地址、请求的具体上下文以及时间戳。当您使用无浏览器求解器时,API必须模拟整个环境以生成AWS服务器接受的合法令牌。
无浏览器环境中的指纹识别作用
即使在无浏览器设置中,指纹识别仍然是一个关键因素。AWS WAF使用高级启发式方法检测HTTP堆栈中的异常。这包括分析头部的顺序、使用的特定TLS版本和密码套件,甚至TCP/IP窗口大小。专业求解服务通过确保令牌生成过程尽可能接近真实浏览器的指纹来处理这些细节。这就是为什么使用专业AWS求解服务比从头开始编写自定义脚本更有效的原因。
扩展您的无浏览器解决方案
随着自动化需求的增长,您可能会遇到速率限制和更严格的基于IP的阻止。为缓解这些问题,将无浏览器求解器与强大的代理管理系统集成至关重要。轮换代理并确保它们与目标网站的受众地理位置一致可以显著提高成功率。有关优化设置的更多技巧,请查看我们针对网络爬虫推荐的最佳代理服务。
为自动化未来做好准备
网络安全部分的环境不断变化。AWS经常更新其WAF规则和挑战逻辑以保持对自动化工具的领先。了解这些变化是确保爬虫继续运行的唯一方法。通过依赖一个持续维护其求解引擎的服务,您可以为这些更新未来化您的基础设施。无论是新的JS挑战版本还是更复杂的AWS检查,专用API提供商都会处理技术上的繁重任务,让您专注于从收集的数据中提取价值。