Tự động hóa giải CAPTCHA trong trình duyệt không giao diện: Hướng dẫn toàn diện về quy trình

Emma Foster
Machine Learning Engineer

TL;Dr:
- Mục đích: Tự động hóa việc giải CAPTCHA trong môi trường trình duyệt không giao diện để thực hiện tự động hóa web hiệu quả.
- Các bước chính: Thiết lập môi trường, tích hợp API (CapSolver), tạo nhiệm vụ, lấy kết quả và tích hợp vào các tập lệnh tự động hóa.
- Lợi ích: Giảm can thiệp thủ công, cải thiện độ tin cậy của tự động hóa và mở rộng nỗ lực thu thập dữ liệu.
- CapSolver: Dịch vụ được đề xuất để giải CAPTCHA đáng tin cậy và hiệu quả, cung cấp nhiều loại nhiệm vụ và tùy chọn tích hợp.
- Tối ưu hóa: Triển khai proxy, quản lý tần suất yêu cầu và xử lý lỗi để đảm bảo tự động hóa mạnh mẽ.
Giới thiệu
Tự động hóa web thường gặp phải CAPTCHA, được thiết kế để phân biệt người dùng thực với bot tự động. Khi sử dụng trình duyệt không giao diện cho các nhiệm vụ như quét dữ liệu, giám sát hoặc kiểm thử, những thách thức này có thể làm dừng tiến trình. Hướng dẫn này cung cấp quy trình toàn diện, từng bước để tự động hóa việc giải CAPTCHA trong trình duyệt không giao diện, đảm bảo quy trình tự động hóa của bạn chạy trơn tru và hiệu quả. Chúng tôi sẽ đề cập đến mọi thứ từ thiết lập môi trường đến tích hợp dịch vụ giải CAPTCHA đáng tin cậy như CapSolver, xử lý kết quả và giải quyết các vấn đề phổ biến. Đến cuối hướng dẫn này, bạn sẽ có kiến thức và công cụ để quản lý CAPTCHA trong các dự án trình duyệt không giao diện của mình, nâng cao độ tin cậy và khả năng mở rộng của nỗ lực tự động hóa web của bạn.
Hiểu về trình duyệt không giao diện và CAPTCHA
Trình duyệt không giao diện là các trình duyệt web không có giao diện người dùng, thường được sử dụng cho kiểm thử tự động, quét web và render phía máy chủ. Các ví dụ phổ biến bao gồm Puppeteer cho Chrome và Playwright cho nhiều trình duyệt. Mặc dù mạnh mẽ, bản chất tự động của chúng khiến chúng dễ bị phát hiện bởi các trang web sử dụng CAPTCHA. CAPTCHA đóng vai trò là lớp bảo mật quan trọng, ngăn chặn truy cập tự động và lạm dụng tài nguyên web. Thách thức nằm ở việc tích hợp một giải pháp có thể giải các câu đố này một cách đáng tin cậy mà không làm ảnh hưởng đến hiệu suất của các hoạt động trình duyệt không giao diện của bạn. Đây là lúc tự động hóa giải CAPTCHA trong trình duyệt không giao diện trở nên thiết yếu.
Tại sao CAPTCHA xuất hiện trong trình duyệt không giao diện
Các trang web sử dụng nhiều kỹ thuật để phát hiện hoạt động tự động, chẳng hạn như phân tích dấu vân tay trình duyệt, mô hình hành vi người dùng và địa chỉ IP. Khi các hệ thống này ghi nhận trình duyệt không giao diện là không phải người dùng thật, CAPTCHA thường được hiển thị. Cơ chế này được thiết kế để bảo vệ chống lại spam, tấn công mật khẩu và trích xuất dữ liệu. Đối với tự động hóa web hiệu quả, một chiến lược mạnh mẽ để tự động hóa giải CAPTCHA trong trình duyệt không giao diện là không thể thiếu.
Quy trình từng bước để tự động hóa giải CAPTCHA
Phần này nêu rõ quy trình đầy đủ để tích hợp dịch vụ giải CAPTCHA vào tự động hóa trình duyệt không giao diện của bạn. Chúng tôi sẽ sử dụng CapSolver làm ví dụ do API toàn diện và hỗ trợ nhiều loại CAPTCHA.
Bước 1: Chuẩn bị môi trường
Trước khi bắt đầu, hãy đảm bảo môi trường phát triển của bạn được cài đặt các công cụ cần thiết. Điều này bao gồm việc cài đặt thư viện trình duyệt không giao diện và môi trường Python để tương tác với API giải CAPTCHA.
Mục đích: Thiết lập nền tảng chức năng để chạy tập lệnh trình duyệt không giao diện và tương tác với các dịch vụ bên ngoài.
Thao tác:
- Cài đặt Python: Đảm bảo Python 3.x được cài đặt trên hệ thống của bạn.
- Cài đặt thư viện trình duyệt không giao diện: Chọn Puppeteer (cho Node.js) hoặc Playwright (hỗ trợ Python, Node.js, Java, .NET). Đối với hướng dẫn này, chúng tôi giả định môi trường Python với Playwright.
bash
pip install playwright playwright install - Cài đặt thư viện Requests: Điều này sẽ được sử dụng để tương tác với API CapSolver.
bash
pip install requests - Nhận khóa API CapSolver: Đăng ký trên trang web CapSolver và lấy khóa API từ bảng điều khiển. Khóa này rất quan trọng để xác thực các yêu cầu của bạn đến dịch vụ giải CAPTCHA.
Lưu ý: Luôn giữ khóa API an toàn và tránh ghi trực tiếp vào kho lưu trữ công khai. Sử dụng biến môi trường để thực hành bảo mật tốt hơn.
Bước 2: Tích hợp API CapSolver
Với môi trường sẵn sàng, bước tiếp theo là tích hợp API CapSolver vào tập lệnh tự động hóa của bạn. Điều này bao gồm việc gửi chi tiết CAPTCHA đến CapSolver và nhận lại mã giải.
Mục đích: Gửi các thách thức CAPTCHA đến CapSolver một cách lập trình và nhận được các giải pháp của chúng.
Thao tác: Việc tích hợp thường bao gồm hai cuộc gọi API chính: createTask để gửi CAPTCHA và getTaskResult để lấy giải pháp. Dưới đây là ví dụ bằng Python sử dụng thư viện requests.
python
import requests
import time
# TODO: thiết lập cấu hình của bạn
api_key = "KHÓA_API_CAPSOLVER_CỦA_BẠN" # Thay thế bằng khóa API CapSolver của bạn
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # Ví dụ site key cho reCAPTCHA v2 demo
site_url = "https://www.google.com/recaptcha/api2/demo" # Ví dụ trang URL có demo reCAPTCHA v2
def solve_recaptcha_v2_capsolver():
print("Tạo nhiệm vụ CAPTCHA...")
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess', # Sử dụng proxy tích hợp của máy chủ
"websiteKey": site_key,
"websiteURL": site_url
}
}
try:
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print(f"Không thể tạo nhiệm vụ: {res.text}")
return None
print(f"Đã tạo nhiệm vụ với ID: {task_id}. Đang chờ kết quả...")
while True:
time.sleep(3) # Chờ 3 giây trước khi kiểm tra kết quả
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
print("CAPTCHA đã được giải thành công!")
return resp.get("solution", {}).get('gRecaptchaResponse')
elif status == "processing":
print("CAPTCHA vẫn đang được xử lý...")
elif status == "failed" or resp.get("errorId"):
print(f"Không thể giải CAPTCHA! Trả lời: {res.text}")
return None
except requests.exceptions.RequestException as e:
print(f"Yêu cầu API thất bại: {e}")
return None
# Ví dụ sử dụng trong tập lệnh trình duyệt không giao diện (khái niệm)
# from playwright.sync_api import sync_playwright
# with sync_playwright() as p:
# browser = p.chromium.launch(headless=True)
# page = browser.new_page()
# page.goto(site_url)
# # Kích hoạt CAPTCHA (ví dụ: bằng cách nhấp vào nút hoặc điều hướng đến trang được bảo vệ)
# # Khi CAPTCHA xuất hiện, gọi trình giải
# captcha_token = solve_recaptcha_v2_capsolver()
# if captcha_token:
# print(f"Nhận được token CAPTCHA: {captcha_token[:30]}...")
# # Chèn token vào trang (ví dụ: qua JavaScript hoặc điền vào trường ẩn)
# # page.evaluate(f"document.getElementById(\'g-recaptcha-response\').value = \'{captcha_token}\';")
# # Gửi biểu mẫu
# else:
# print("Không thể nhận token CAPTCHA.")
# browser.close()Lưu ý: Điều chỉnh thời gian time.sleep() dựa trên thời gian giải CAPTCHA thông thường. Quét quá mức có thể dẫn đến giới hạn tần suất. Luôn xử lý các lỗi API và vấn đề mạng một cách trơn tru.
Bước 3: Xử lý token CAPTCHA đã giải
Khi CapSolver trả về giải pháp, bạn cần chèn token này trở lại phiên trình duyệt không giao diện của bạn để hoàn thành thử thách CAPTCHA.
Mục đích: Gửi giải pháp CAPTCHA đến trang web mục tiêu và tiếp tục tự động hóa.
Thao tác: Phương pháp chèn token phụ thuộc vào loại CAPTCHA và cách trang web kỳ vọng giải pháp. Đối với reCAPTCHA v2, token thường được đặt vào một khung văn bản ẩn với ID g-recaptcha-response.
python
# ... (mã trước đó cho hàm solve_recaptcha_v2_capsolver)
from playwright.sync_api import sync_playwright
# Ví dụ sử dụng
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(site_url)
# Chờ iframe reCAPTCHA tải và hiển thị (điều chỉnh các lựa chọn khi cần)
page.wait_for_selector("iframe[title='reCAPTCHA challenge']", timeout=30000)
captcha_token = solve_recaptcha_v2_capsolver()
if captcha_token:
print(f"Nhận được token CAPTCHA: {captcha_token[:30]}...")
# Chèn token vào trường ẩn
page.evaluate(f"document.getElementById('g-recaptcha-response').value = '{captcha_token}';")
print("Token CAPTCHA đã được chèn. Đang cố gắng gửi biểu mẫu...")
# Giả sử có nút gửi, nhấp vào nó. Điều chỉnh lựa chọn khi cần.
# page.click("button[type='submit']")
# Hoặc, nếu biểu mẫu gửi tự động sau khi chèn token, không cần nhấp.
page.wait_for_timeout(5000) # Cho một chút thời gian để biểu mẫu xử lý
else:
print("Không thể nhận token CAPTCHA. Tự động hóa đã dừng lại.")
browser.close()Lưu ý: Đảm bảo các lựa chọn của bạn cho iframe CAPTCHA và trường ẩn chính xác. Các trang web có thể thay đổi cấu trúc, yêu cầu cập nhật các lựa chọn của bạn. Luôn kiểm tra xem việc gửi biểu mẫu có thành công sau khi chèn token hay không.
Giải quyết các vấn đề phổ biến
Ngay cả với thiết lập mạnh mẽ, bạn có thể gặp phải các vấn đề. Dưới đây là một số vấn đề phổ biến và giải pháp khi tự động hóa giải CAPTCHA trong trình duyệt không giao diện.
Vấn đề: taskId Không Được Trả Về Hoặc Lỗi API
Vấn đề: Cuộc gọi API createTask không trả về taskId, hoặc trả về thông báo lỗi.
Giải pháp:
- Kiểm tra khóa API: Xác minh rằng
api_keycủa bạn chính xác và có đủ số dư. - Xem lại dữ liệu yêu cầu: Đảm bảo
websiteURL,websiteKeyvàtypeđược chỉ định chính xác theo tài liệu API CapSolver cho loại CAPTCHA cụ thể. - Vấn đề mạng: Kiểm tra kết nối internet và đảm bảo điểm cuối API CapSolver có thể truy cập.
Vấn đề: Token CAPTCHA Không Hợp lệ Hoặc Bị Từ Chối
Vấn đề: CapSolver trả về token, nhưng trang web mục tiêu từ chối nó.
Giải pháp:
websiteKeyvàwebsiteURLchính xác: Các tham số này phải khớp chính xác với trang web mục tiêu. Ngay cả sự sai lệch nhỏ cũng có thể gây từ chối.- Sử dụng proxy: Nếu trang web bị giới hạn địa lý hoặc có kiểm tra IP nghiêm ngặt, sử dụng proxy với
ReCaptchaV2Task(ví dụ:ReCaptchaV2Taskvới tham sốproxy) phù hợp với địa chỉ IP của trình duyệt không giao diện. CapSolver cung cấp các tùy chọn proxy. - Tính nhất quán của User-Agent: Đảm bảo chuỗi User-Agent được sử dụng bởi trình duyệt không giao diện của bạn khớp với chuỗi mà CapSolver có thể sử dụng bên trong hoặc được trang web kỳ vọng. Một số CAPTCHA tiên tiến kiểm tra tính nhất quán.
- Thay đổi trang web: Các trang web thường cập nhật triển khai CAPTCHA của họ.
websiteKeyhoặc các tham số khác có thể đã thay đổi. Sử dụng phần mở rộng CapSolver để tự động lấy các tham số cần thiết nếu bạn không chắc.
Vấn đề: Phát hiện trình duyệt không giao diện
Vấn đề: Dù đã giải CAPTCHA, trang web vẫn phát hiện trình duyệt không giao diện và chặn truy cập.
Giải pháp:
- Kỹ thuật ẩn danh: Triển khai plugin hoặc cấu hình cho trình duyệt không giao diện (ví dụ:
puppeteer-extra-plugin-stealthcho Puppeteer, hoặc cấu hình Playwright tương tự) để mô phỏng hành vi trình duyệt người dùng. Điều này bao gồm thay đổi User-Agent, vô hiệu hóa cờ tự động hóa và xử lý các thuộc tính trình duyệt phổ biến mà tiết lộ tự động hóa (tham khảo Tài liệu Web MDN về trình duyệt không giao diện). - Khoảng thời gian thực tế: Thêm khoảng thời gian giống người dùng giữa các hành động. Các hành động nhanh và nhất quán là chỉ báo mạnh mẽ của tự động hóa.
- Quản lý cookie và bộ nhớ cục bộ: Duy trì và tái sử dụng cookie và bộ nhớ cục bộ giữa các phiên để duy trì hồ sơ duyệt web nhất quán.
- Tiêu đề Referer: Đảm bảo các tiêu đề Referer phù hợp được gửi cùng với các yêu cầu.
Gợi ý Tối ưu Hiệu suất
Tối ưu quy trình giải CAPTCHA là điều cần thiết để tự động hóa web hiệu quả và mở rộng quy mô. Xem xét các gợi ý sau để tự động hóa giải CAPTCHA trong trình duyệt không giao diện.
1. Quản lý Proxy
Sử dụng proxy chất lượng cao là rất quan trọng. Proxy nhà ở hoặc di động thường hiệu quả hơn proxy trung tâm dữ liệu, vì chúng dường như là lưu lượng người dùng hợp lệ. Xoay vòng proxy của bạn để tránh bị cấm IP và phân phối các yêu cầu của bạn trên nhiều địa chỉ IP. CapSolver hỗ trợ tích hợp proxy trực tiếp trong API tạo nhiệm vụ của nó.
2. Đồng thời và Tần suất Yêu cầu
Cân bằng giữa đồng thời và tần suất yêu cầu. Dù chạy nhiều trình duyệt không giao diện đồng thời có thể tăng tốc nhiệm vụ, gửi quá nhiều yêu cầu giải CAPTCHA quá nhanh có thể dẫn đến giới hạn tần suất từ dịch vụ CAPTCHA hoặc phát hiện bởi trang web mục tiêu. Triển khai backoff theo cấp số nhân cho các lần thử lại và độ trễ động dựa trên hành vi quan sát của trang web.
3. Bộ nhớ đệm và Tái sử dụng
Đối với một số loại CAPTCHA hoặc phiên trang web, các giải pháp có thể được tái sử dụng trong một khoảng thời gian ngắn. Nếu có thể, bộ nhớ đệm các token CAPTCHA hợp lệ và tái sử dụng chúng trong khoảng thời gian hợp lệ để giảm các yêu cầu giải CAPTCHA dư thừa và chi phí.
Tóm tắt So sánh: Các Phương pháp Giải CAPTCHA
Việc chọn phương pháp giải CAPTCHA phù hợp phụ thuộc vào nhiều yếu tố, bao gồm chi phí, độ tin cậy và độ phức tạp. Dưới đây là so sánh các phương pháp phổ biến:
| Tính năng | Giải CAPTCHA thủ công | Giải CAPTCHA dựa trên OCR | Giải CAPTCHA dựa trên API (ví dụ: CapSolver) | Giải CAPTCHA bằng Machine Learning (tự host) |
|---|---|---|---|---|
| Độ tin cậy | Cao (người dùng) | Thấp đến Trung bình | Cao | Trung bình đến Cao |
| Tốc độ | Biến đổi | Nhanh | Nhanh | Nhanh |
| Chi phí | Nhân công | Thấp (cài đặt) | Phí giải quyết mỗi lần | Cao (cài đặt, bảo trì) |
| Phức tạp | Không | Cao (phát triển) | Thấp (tích hợp API) | Rất cao (chuyên môn ML) |
| Bảo trì | Không | Cao | Thấp | Rất cao |
| Loại CAPTCHA | Tất cả | Hình ảnh đơn giản | Tất cả các loại chính | Các loại cụ thể (được huấn luyện) |
| Khả năng mở rộng | Thấp | Trung bình | Cao | Trung bình |
Các giải pháp dựa trên API như CapSolver cung cấp sự cân bằng giữa độ tin cậy cao, tốc độ và dễ dàng tích hợp, khiến chúng trở thành lựa chọn lý tưởng để tự động hóa việc giải CAPTCHA trong trình duyệt không giao diện mà không cần chi phí phát triển đáng kể.
Sử dụng mã
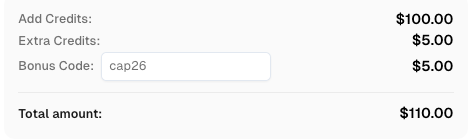
CAP26khi đăng ký tại CapSolver để nhận thêm tín dụng!
Kết luận
Việc tự động hóa giải CAPTCHA trong trình duyệt không giao diện là kỹ năng quan trọng đối với bất kỳ ai tham gia vào tự động hóa web. Bằng cách tuân theo quy trình được trình bày trong hướng dẫn này - từ cài đặt môi trường, tích hợp API đến xử lý kết quả và gỡ lỗi - bạn có thể cải thiện đáng kể hiệu quả và độ bền của các nhiệm vụ tự động của mình. Các dịch vụ như CapSolver cung cấp cách tiếp cận mạnh mẽ và đáng tin cậy để vượt qua các thách thức CAPTCHA, cho phép trình duyệt không giao diện của bạn hoạt động trơn tru. Luôn ưu tiên các yếu tố đạo đức và tuân thủ các điều khoản dịch vụ của trang web khi triển khai các giải pháp tự động hóa. Để tìm hiểu thêm về các thách thức trong tự động hóa web, khám phá các bài viết như Tại sao tự động hóa web thường thất bại với CAPTCHA và Làm thế nào để quét các trang web được bảo vệ bằng CAPTCHA.
Câu hỏi thường gặp (FAQ)
Câu hỏi 1: Việc tự động hóa giải CAPTCHA có hợp pháp không?
Trả lời 1: Tính hợp pháp của việc tự động hóa giải CAPTCHA trong trình duyệt không giao diện phụ thuộc rất nhiều vào điều khoản dịch vụ của trang web và các quy định địa phương. Mặc dù việc giải CAPTCHA bản thân không bất hợp pháp, việc sử dụng tự động để truy cập nội dung hoặc thực hiện hành động vi phạm chính sách của trang web có thể là bất hợp pháp. Luôn kiểm tra điều khoản dịch vụ của các trang web bạn tương tác.
Câu hỏi 2: CapSolver có thể xử lý những loại CAPTCHA nào?
Trả lời 2: CapSolver hỗ trợ nhiều loại CAPTCHA, bao gồm reCAPTCHA v2, reCAPTCHA v3, ImageToText và nhiều loại CAPTCHA doanh nghiệp khác. Sự hỗ trợ rộng rãi này khiến nó trở thành công cụ linh hoạt để tự động hóa giải CAPTCHA trong trình duyệt không giao diện trên các nền tảng khác nhau.
Câu hỏi 3: Làm thế nào để giảm chi phí giải CAPTCHA?
Trả lời 3: Để giảm chi phí, tối ưu hóa kịch bản tự động hóa của bạn để chỉ yêu cầu giải CAPTCHA khi thực sự cần thiết. Sử dụng bộ nhớ đệm cho các token có thể tái sử dụng, sử dụng khoảng thời gian kiểm tra hiệu quả cho kết quả, và đảm bảo kỹ thuật lẩn tránh trình duyệt không giao diện của bạn mạnh mẽ để giảm thiểu việc kích hoạt CAPTCHA từ đầu. Thường xuyên theo dõi việc sử dụng CapSolver của bạn và khám phá các gói giá cả của họ.
Câu hỏi 4: Tôi có thể sử dụng CapSolver với các ngôn ngữ lập trình khác không?
Trả lời 4: Có, CapSolver cung cấp API RESTful, điều đó có nghĩa là nó có thể tích hợp với bất kỳ ngôn ngữ lập trình nào có thể thực hiện yêu cầu HTTP. Mặc dù hướng dẫn này sử dụng Python, bạn có thể dễ dàng thích ứng các khái niệm này với Node.js, Java, C#, Go hoặc các ngôn ngữ khác. Tham khảo Tài liệu API CapSolver để xem các ví dụ cụ thể cho từng ngôn ngữ hoặc thông tin tổng quan về API.
Câu hỏi 5: Những nguyên tắc tốt nhất để duy trì tự động hóa web có đạo đức là gì?
Trả lời 5: Tự động hóa web có đạo đức bao gồm việc tôn trọng điều khoản dịch vụ của trang web, tránh tần suất yêu cầu quá cao có thể làm quá tải máy chủ và không tham gia vào các hoạt động có thể bị coi là độc hại hoặc gây hại. Luôn cố gắng minh bạch khi cần thiết và xem xét tác động của tự động hóa của bạn đến tài nguyên và trải nghiệm người dùng của trang web. Tập trung vào các trường hợp sử dụng hợp pháp như thu thập dữ liệu cho nghiên cứu hoặc sử dụng cá nhân, thay vì các hoạt động gây gián đoạn.