Data Grounding trong AI là gì? Cẩm nang thực hành cho các mô hình ngôn ngữ lớn đáng tin cậy

Anh Tuan
Data Science Expert
TL;DR
- Kết nối dữ liệu giúp đầu ra AI liên kết với các nguồn thông tin đáng tin cậy, cập nhật và liên quan.
- Kết nối dữ liệu giảm các câu trả lời không được hỗ trợ bằng cách thêm bối cảnh tại thời điểm suy diễn.
- Dữ liệu kết nối có thể bao gồm tài liệu, cơ sở dữ liệu, kết quả tìm kiếm, danh mục, chính sách và hồ sơ được phép.
- RAG là kỹ thuật phổ biến để kết nối dữ liệu, nhưng không phải là toàn bộ lĩnh vực.
- Kết nối dữ liệu mạnh cần kiểm tra chất lượng, quyền truy cập, đánh giá truy xuất, trích dẫn và giám sát.
- Các nhóm sử dụng tự động hóa nên thu thập dữ liệu hợp pháp và xử lý các thách thức CAPTCHA chỉ trong các quy trình được ủy quyền.
Giới thiệu
Kết nối dữ liệu là thực hành giúp câu trả lời AI chính xác hơn, cập nhật và có thể kiểm chứng. Nó cung cấp bối cảnh đúng cho mô hình trước khi trả lời. Hướng dẫn này dành cho các nhóm sản phẩm, nhóm SEO, nhà phát triển và nhóm tự động hóa xây dựng công cụ AI dựa trên LLM. Bạn sẽ học được ý nghĩa của kết nối dữ liệu trong AI, cách nó hoạt động, cách nó khác với RAG và tinh chỉnh, cũng như cách áp dụng nó một cách có trách nhiệm. Giá trị thực tế là các hệ thống AI được kết nối có thể trích dẫn nguồn, tuân thủ quyền truy cập và giảm các câu trả lời lỗi thời. Khi quy trình tự động hóa hợp pháp gặp thách thức kiểm tra lưu lượng hoặc CAPTCHA, CapSolver có thể hỗ trợ quy trình kiểm tra tuân thủ.
Định nghĩa Kết nối Dữ liệu
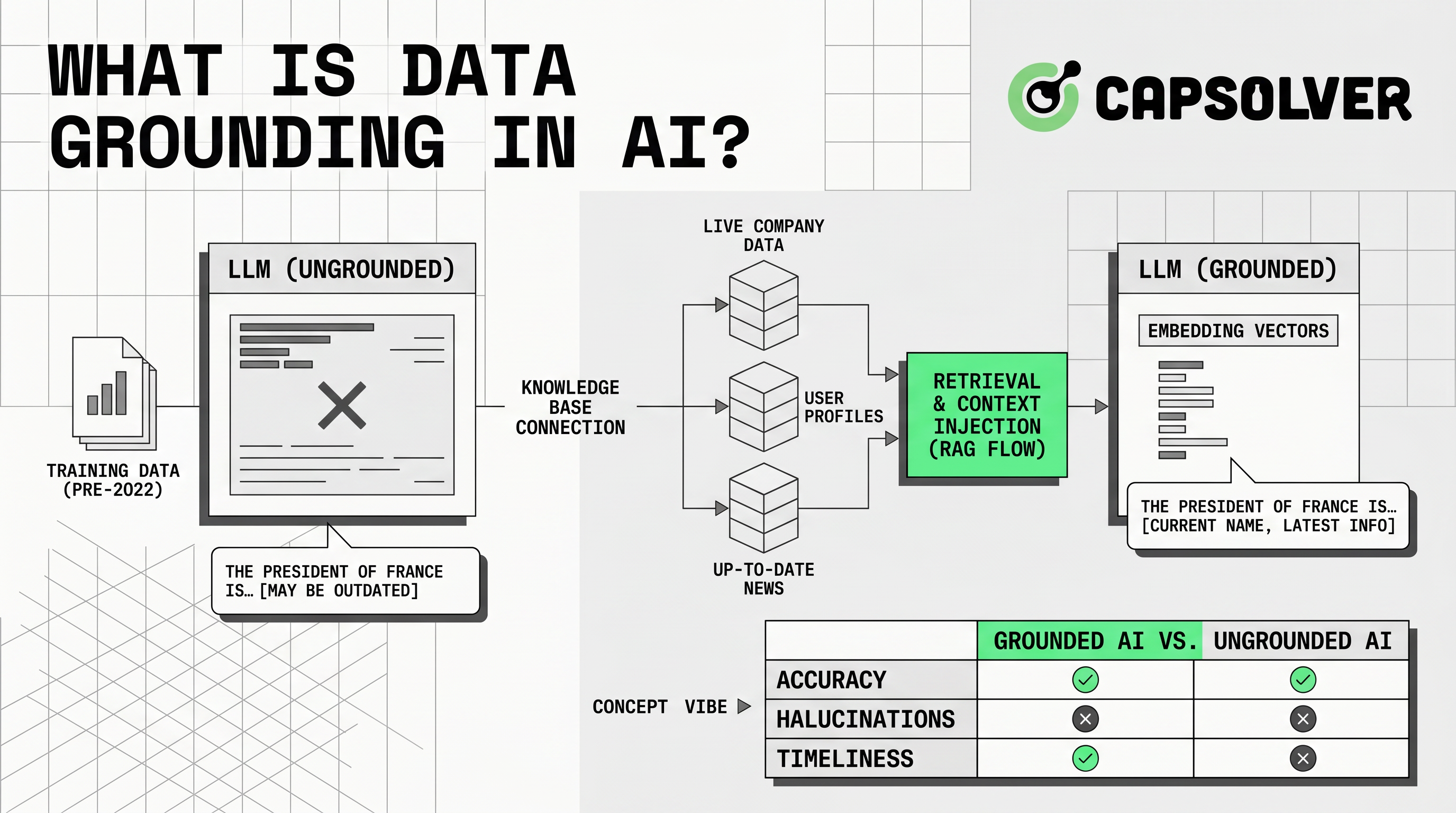
Kết nối dữ liệu có nghĩa là gắn kết câu trả lời AI trong bối cảnh bên ngoài đáng tin cậy. Ứng dụng cung cấp thông tin liên quan cho mô hình khi người dùng đặt câu hỏi. Microsoft định nghĩa dữ liệu kết nối là thông tin được cung cấp cho mô hình ngôn ngữ tại thời điểm suy diễn để cải thiện độ chính xác và tính liên quan thông qua Hướng dẫn Azure Well-Architected.
Kết nối dữ liệu quan trọng vì LLM dự đoán ngôn ngữ. Chúng không tự động biết giá cả, chính sách, tài liệu, hồ sơ khách hàng hoặc dữ liệu thị trường công khai mới nhất của bạn. Không có bối cảnh đáng tin cậy, câu trả lời có thể nghe tự tin nhưng thiếu thông tin. Với kết nối dữ liệu, hệ thống có thể truy xuất tài liệu nguồn, chèn vào prompt và yêu cầu mô hình trả lời từ tài liệu đó.
Kết nối dữ liệu AI không chỉ là một mẹo prompt. Đó là một mẫu thiết kế dữ liệu. Nó bao gồm việc chọn nguồn, làm sạch, lập chỉ mục, kiểm soát truy cập, truy xuất, tạo phản hồi, trích dẫn, đánh giá và giám sát.
Tại sao Kết nối Dữ liệu Quan trọng đối với Độ Chính xác AI
Kết nối dữ liệu cải thiện độ tin cậy của AI bằng cách thu hẹp không gian câu trả lời của mô hình. Google Cloud mô tả kết nối doanh nghiệp là kết nối mô hình với thông tin web, dữ liệu doanh nghiệp, cơ sở dữ liệu, ứng dụng và nguồn đáng tin cậy để cải thiện tính toàn diện và độ chính xác thông qua Giá trị doanh nghiệp của Google Cloud.
Điều này hữu ích cho các lĩnh vực thay đổi nhanh. Kho hàng, chính sách hỗ trợ, tài liệu, giá cả và lịch trình sự kiện thay đổi thường xuyên. Một mô hình được huấn luyện vài tháng trước không thể biết mọi cập nhật. Kết nối dữ liệu cung cấp cho ứng dụng con đường đến thông tin mới mà không cần huấn luyện lại mô hình mỗi ngày.
Kết nối dữ liệu cũng giúp các nhóm giải thích câu trả lời. Các trích dẫn, thời gian đánh dấu và trường nguồn hỗ trợ kiểm tra chất lượng, đánh giá tuân thủ và niềm tin của người dùng.
Cách Kết nối Dữ liệu Hoạt động
Kết nối dữ liệu hoạt động thông qua luồng truy xuất và tạo ra. Hệ thống trước tiên xác định các nguồn đáng tin cậy. Sau đó, chuẩn bị các nguồn đó để tìm kiếm. Các nguồn phổ biến bao gồm trung tâm hỗ trợ, hướng dẫn, API, cơ sở dữ liệu SQL, chỉ mục vector, nguồn sản phẩm và trang công khai được phê duyệt.
Bước tiếp theo là tiếp nhận. Các nhóm làm sạch tài liệu, loại bỏ bản sao, chuẩn hóa thông tin mô tả, chia nội dung thành các đoạn và lưu trữ chúng trong chỉ mục tìm kiếm. Chỉ mục có thể sử dụng tìm kiếm từ khóa, tìm kiếm vector, tìm kiếm kết hợp hoặc tìm kiếm đồ thị. Microsoft khuyến nghị tách biệt dữ liệu kết nối ra khỏi hệ thống nguồn khi cải thiện truy xuất, hiệu suất và bảo vệ hệ thống nguồn thông qua Thiết kế dữ liệu kết nối AI.
Khi người dùng đặt câu hỏi, hệ thống truy xuất các tài liệu liên quan. Nó lọc theo quyền truy cập, độ mới, ngôn ngữ, khu vực hoặc dòng sản phẩm. Sau đó, thêm bối cảnh đã truy xuất vào prompt của mô hình. Mô hình trả lời từ bối cảnh đó và có thể trả lại trích dẫn nguồn.
Kết nối dữ liệu thành công khi truy xuất chính xác. Các hệ thống mạnh đo lường tính liên quan, tính trung thực, độ trễ và phạm vi nguồn.
Tóm tắt So sánh
Kết nối dữ liệu trùng lặp với một số phương pháp AI. Bảng dưới đây cho thấy sự khác biệt thực tế.
| Phương pháp | Mục đích chính | Trường hợp sử dụng tốt nhất | Hạn chế chính |
|---|---|---|---|
| Kết nối dữ liệu | Gắn câu trả lời vào bối cảnh đáng tin cậy | Câu trả lời hiện tại, có nguồn gốc | Yêu cầu truy xuất và quản trị mạnh |
| RAG | Truy xuất tài liệu trước khi tạo | Câu hỏi và trả lời cơ sở kiến thức và đại diện hỗ trợ | Có thể truy xuất bối cảnh không liên quan hoặc lỗi thời |
| Tinh chỉnh | Thay đổi hành vi mô hình thông qua ví dụ | Hành vi phong cách, định dạng hoặc lĩnh vực | Không lý tưởng cho việc thay đổi sự thật |
| Kỹ thuật prompt | Hướng dẫn hành vi với chỉ dẫn | Nhiệm vụ nhỏ và định dạng phản hồi | Không thể cung cấp sự thật thiếu hụt riêng lẻ |
| Rào cản an toàn | Áp dụng chính sách và kiểm soát đầu ra | Kiểm tra an toàn, định dạng và tuân thủ | Không thể thay thế bối cảnh nguồn xác minh |
So sánh này cho thấy tại sao kết nối dữ liệu rộng hơn RAG. RAG là mẫu triển khai phổ biến. Kết nối dữ liệu là toàn bộ lĩnh vực kết nối đầu ra mô hình với bằng chứng đáng tin cậy.
Nguồn Dữ liệu Kết nối Dữ liệu Thường Gặp
Kết nối dữ liệu bắt đầu bằng chất lượng nguồn. Các nhóm nên xếp hạng nguồn theo quyền lực, độ mới, quyền sở hữu và cấp độ quyền truy cập.
Nguồn nội bộ thường cung cấp giá trị kinh doanh cao nhất. Những nguồn này bao gồm hồ sơ CRM, vé, chính sách, hệ thống kho hàng, thông số kỹ thuật sản phẩm và cơ sở kiến thức. Chúng yêu cầu kiểm soát truy cập nghiêm ngặt.
Nguồn bên ngoài thêm độ mới và phạm vi. Những nguồn này bao gồm tài liệu chính thức, hướng dẫn chính phủ, dữ liệu công khai, các cơ quan tiêu chuẩn và dữ liệu thị trường đáng tin cậy. NIST cho biết Khung Quản lý Rủi ro AI của họ giúp các tổ chức quản lý rủi ro đối với cá nhân, tổ chức và xã hội thông qua Khung RMF AI của NIST. Những nguồn này hữu ích khi viết chính sách cho các hệ thống AI đáng tin cậy.
Dữ liệu web công khai có thể hỗ trợ theo dõi thị trường, nghiên cứu SEO và phân tích cạnh tranh. Các nhóm nên giữ điều này hợp pháp và hợp lý. Họ nên tôn trọng các điều khoản trang, giới hạn tốc độ yêu cầu, hướng dẫn robots áp dụng và nghĩa vụ bảo mật. Tài nguyên của CapSolver về AI và tự động hóa và quy trình tự động hóa là điểm bắt đầu hữu ích cho quy trình có trách nhiệm.
Quy trình Sản xuất cho Kết nối Dữ liệu
Kết nối dữ liệu hoạt động tốt nhất với mô hình vận hành rõ ràng. Đầu tiên, xác định ranh giới câu trả lời. Quyết định điều gì AI có thể trả lời, nguồn nào nó có thể sử dụng và khi nào phải từ chối hoặc chuyển tiếp.
Thứ hai, chuẩn bị dữ liệu. Loại bỏ bản sao, hồ sơ lỗi thời, trường riêng tư và nội dung nhiễu. Thêm thông tin mô tả như chủ sở hữu, ngày, khu vực, sản phẩm, ngôn ngữ và cấp độ quyền truy cập. Điều này làm cho truy xuất chính xác hơn.
Thứ ba, thiết kế truy xuất. Sử dụng tìm kiếm từ khóa cho các thuật ngữ chính xác, tìm kiếm vector cho sự tương đồng ngữ nghĩa và bộ lọc cho các hồ sơ được phép.
Thứ tư, đánh giá hiệu suất. Tạo một tập thử nghiệm các câu hỏi thực tế. Điểm truy xuất liên quan, tính trung thực câu trả lời, độ chính xác trích dẫn và độ trễ. Xem xét các trường hợp biên với chuyên gia lĩnh vực. Không nên chỉ dựa vào độ tự tin của mô hình.
Thứ năm, giám sát sự thay đổi. Kết nối dữ liệu có thể thất bại khi tài liệu trở nên lỗi thời, chỉ mục bị hỏng, quyền truy cập thay đổi hoặc ý định người dùng thay đổi. Các hệ thống quan trọng cần kiểm tra độ mới tự động và đường đi xem xét của con người.
Xem xét Tuân thủ và An ninh
Kết nối dữ liệu phải tôn trọng ranh giới pháp lý, quyền riêng tư và an ninh. Truy cập kỹ thuật không có nghĩa là quyền truy cập. Các hệ thống AI được kết nối nên tránh dữ liệu riêng tư, bị hạn chế, nhạy cảm hoặc không được phép trừ khi tổ chức có cơ sở pháp lý rõ ràng và sự cho phép của người dùng.
Rủi ro an ninh cũng quan trọng. OWASP liệt kê các rủi ro chính cho ứng dụng LLM như tấn công prompt, tiết lộ thông tin nhạy cảm, cơ quan quá mức và phụ thuộc quá mức thông qua OWASP Top 10 cho Ứng dụng LLM. Kết nối dữ liệu có thể giảm các tuyên bố không được hỗ trợ, nhưng nó có thể tạo rủi ro nếu truy xuất chấp nhận nội dung độc hại hoặc tiết lộ hồ sơ được bảo vệ.
Các nhóm nên sử dụng truy xuất có quyền truy cập. Họ nên làm sạch văn bản không đáng tin cậy, ghi lại ID nguồn thay vì hồ sơ nhạy cảm và phân tách dữ liệu theo phân loại.
Các nhóm tự động hóa cần cẩn trọng hơn. Thu thập dữ liệu web nên tập trung vào dữ liệu công khai được phép, tốc độ yêu cầu hợp lý và mục đích kinh doanh được tài liệu hóa. Khi các thách thức CAPTCHA xuất hiện trong QA, giám sát hoặc quy trình dữ liệu được ủy quyền, các nhóm nên coi chúng là một phần của kiểm tra lưu lượng. Bài viết của CapSolver về thu thập dữ liệu web công khai và hướng dẫn của nó về thách thức CAPTCHA có thể giúp các nhóm hiểu bối cảnh vận hành.
CapSolver Nằm Ở Đâu Trong Quy Trình AI Có Trách Nhiệm
CapSolver liên quan khi kết nối dữ liệu phụ thuộc vào quy trình tự động hóa hợp pháp. Một số nhóm thu thập dữ liệu công khai để theo dõi giá cả, kiểm tra SEO, xác minh quảng cáo, kiểm tra chất lượng hoặc nghiên cứu. Các quy trình này có thể gặp thách thức CAPTCHA trong quá trình lướt web hoặc kiểm tra bình thường.
CapSolver có thể giúp các nhóm xử lý những thách thức đó thông qua dịch vụ được thiết kế cho môi trường tự động hóa. Đề xuất này hẹp và tuân thủ trước tiên. Sử dụng nó chỉ khi bạn có sự cho phép, tôn trọng các quy tắc áp dụng và tránh dữ liệu bị hạn chế hoặc nhạy cảm. Các nhóm có thể xem sản phẩm CapSolver để hiểu các tình huống được hỗ trợ và khớp chúng với các quy trình được phê duyệt.
Nhận Mã Ưu đãi CapSolver của Bạn
Tăng ngân sách tự động hóa của bạn ngay lập tức!
Sử dụng mã ưu đãi CAP26 khi nạp tiền vào tài khoản CapSolver để nhận thêm 5% ưu đãi cho mỗi lần nạp tiền — không giới hạn.
Nhận mã ngay bây giờ trong Bảng điều khiển CapSolver
Kết nối dữ liệu và xử lý CAPTCHA không nên kết hợp một cách tùy tiện. Lớp kết nối quyết định tài liệu nào AI có thể sử dụng. Lớp tự động hóa thu thập hoặc kiểm tra dữ liệu dưới các quy tắc được phê duyệt. Giữ các lớp này tách biệt giúp kiểm toán dễ dàng hơn và giảm rủi ro vận hành.
Chỉ số Thực tế cho Hệ thống AI được Kết nối
Kết nối dữ liệu cần tiêu chuẩn chất lượng đo lường được. Tính liên quan truy xuất hỏi liệu bối cảnh đã truy xuất có trả lời câu hỏi hay không. Điểm số thấp có nghĩa là mô hình đang làm việc với bằng chứng yếu.
Tính trung thực câu trả lời hỏi liệu câu trả lời có ở trong các nguồn truy xuất hay không. Điều này quan trọng vì câu trả lời trơn tru vẫn có thể thêm chi tiết không được hỗ trợ.
Độ chính xác trích dẫn kiểm tra xem mỗi nguồn trích dẫn có hỗ trợ câu mà nó theo sau hay không. Độ mới theo dõi tuổi của tài liệu, thời gian cập nhật chỉ mục và tần suất cập nhật nguồn. Chất lượng từ chối kiểm tra xem hệ thống có nói khi bằng chứng thiếu hụt hay không.
Kết luận và CTA
Kết nối dữ liệu là một trong những cách thực tế nhất để làm cho hệ thống AI đáng tin cậy hơn. Nó kết nối câu trả lời với bối cảnh đáng tin cậy, cải thiện độ mới, hỗ trợ trích dẫn và giúp các nhóm quản lý rủi ro. RAG thường là một phần của giải pháp, nhưng kết nối dữ liệu cấp độ sản xuất cũng cần dữ liệu sạch, quyền truy cập mạnh, đánh giá, giám sát và thực hành tự động hóa có trách nhiệm.
Nếu quy trình AI của bạn phụ thuộc vào theo dõi dữ liệu công khai, tự động hóa trình duyệt, kiểm tra chất lượng hoặc nghiên cứu, hãy lập kế hoạch đường dẫn dữ liệu cẩn thận. Giữ quyền truy cập nguồn hợp pháp. Giữ dữ liệu nhạy cảm được bảo vệ. Xem xét đầu ra trước khi sử dụng chúng cho các quyết định quan trọng. Đối với các quy trình được phê duyệt gặp thách thức CAPTCHA, hãy xem xét đánh giá CapSolver như một phần của bộ công cụ tự động hóa tuân thủ.
FAQ
Dữ liệu kết nối trong AI là gì?
Dữ liệu kết nối là quá trình kết nối câu trả lời AI với bối cảnh đáng tin cậy. Bối cảnh có thể đến từ tài liệu, cơ sở dữ liệu, API, chỉ mục tìm kiếm hoặc nguồn công khai được phê duyệt. Nó giúp mô hình trả lời từ bằng chứng thay vì chỉ dựa vào dữ liệu huấn luyện.
Dữ liệu kết nối có giống với RAG không?
Không. RAG là một cách phổ biến để triển khai dữ liệu kết nối. Dữ liệu kết nối rộng hơn. Nó bao gồm quản trị nguồn, lập chỉ mục, quyền truy cập, đánh giá truy xuất, trích dẫn, giám sát và quy tắc chuyển tiếp.
Tại sao dữ liệu kết nối giảm các câu trả lời AI không được hỗ trợ?
Dữ liệu kết nối giảm các câu trả lời không được hỗ trợ vì nó cung cấp bằng chứng liên quan cho mô hình tại thời điểm suy diễn. Mô hình có thể trả lời từ bối cảnh hiện tại thay vì lấp đầy khoảng trống từ các mô hình thống kê riêng lẻ.
Dữ liệu nào nên được sử dụng cho dữ liệu kết nối cho LLM?
Sử dụng dữ liệu chính xác, được phép, cập nhật và liên quan. Các ví dụ tốt bao gồm tài liệu chính thức, hồ sơ sản phẩm, chính sách hỗ trợ, cơ sở kiến thức, dữ liệu công khai và cơ sở dữ liệu doanh nghiệp được phê duyệt. Tránh dữ liệu riêng tư hoặc bị hạn chế mà không có sự cho phép thích hợp.
Các nhóm nên áp dụng dữ liệu kết nối một cách có trách nhiệm như thế nào?
Các nhóm nên xác định quy tắc nguồn, thực thi kiểm soát truy cập, giám sát chất lượng truy xuất và xem xét các đầu ra có tác động lớn. Các nhóm tự động hóa nên thu thập dữ liệu hợp pháp, tôn trọng các quy tắc trang web và chỉ sử dụng các dịch vụ liên quan đến CAPTCHA trong các quy trình được ủy quyền.
Xem thêm
Web ScrapingJul 22, 2026
Theo dõi Suy Giảm SEO Kỹ Thuật: Dòng Tự Động Hóa
Xây dựng giám sát sự suy giảm SEO kỹ thuật với các cơ sở ban đầu được phiên bản hóa, sự khác biệt ngữ nghĩa, cảnh báo được xác minh, và một bước khôi phục CAPTCHA được ủy quyền tùy chọn.
CloudflareJul 22, 2026
Giải CAPTCHA MCP: Hướng dẫn tích hợp Turnstile của Cloudflare
Xây dựng một quy trình có kiểm soát theo chính sách MCP Cloudflare Turnstile với CapSolver, lặp lại có giới hạn, nhật ký đã được làm mờ, kiểm tra phiên làm việc và xác minh kết quả.