Scrapy vs. Selenium: Qual é o melhor para o seu projeto de raspagem de web

Anh Tuan
Data Science Expert

TL;DR
Scrapy e Selenium são duas ferramentas populares para raspagem de web, cada uma adequada a diferentes casos de uso. O Scrapy é um framework Python rápido, leve e escalável ideal para raspagem em larga escala de sites estáticos. O Selenium, por outro lado, automatiza navegadores reais e se destaca na raspagem de páginas dinâmicas e com JavaScript pesado que exigem interação do usuário. A escolha certa depende da complexidade do seu projeto, dos requisitos de desempenho e da necessidade de interação, e ambas as ferramentas podem enfrentar desafios de CAPTCHA que podem ser resolvidos com serviços como CapSolver.
Introdução
A raspagem de web é uma técnica essencial para coletar dados da internet, e se tornou cada vez mais popular entre desenvolvedores, pesquisadores e empresas. Duas das ferramentas mais comumente usadas para raspagem de web são Scrapy e Selenium. Cada uma tem suas forças e fraquezas, tornando-as adequadas para diferentes tipos de projetos. Neste artigo, compararemos Scrapy e Selenium para ajudá-lo a determinar qual ferramenta é a melhor para suas necessidades de raspagem de web.
O que é Scrapy
O Scrapy é um framework de raspagem de web poderoso e rápido escrito em Python. Foi projetado para raspar páginas da web e extrair dados estruturados delas. O Scrapy é altamente eficiente, escalável e personalizável, tornando-o uma excelente escolha para projetos de raspagem de web em larga escala.
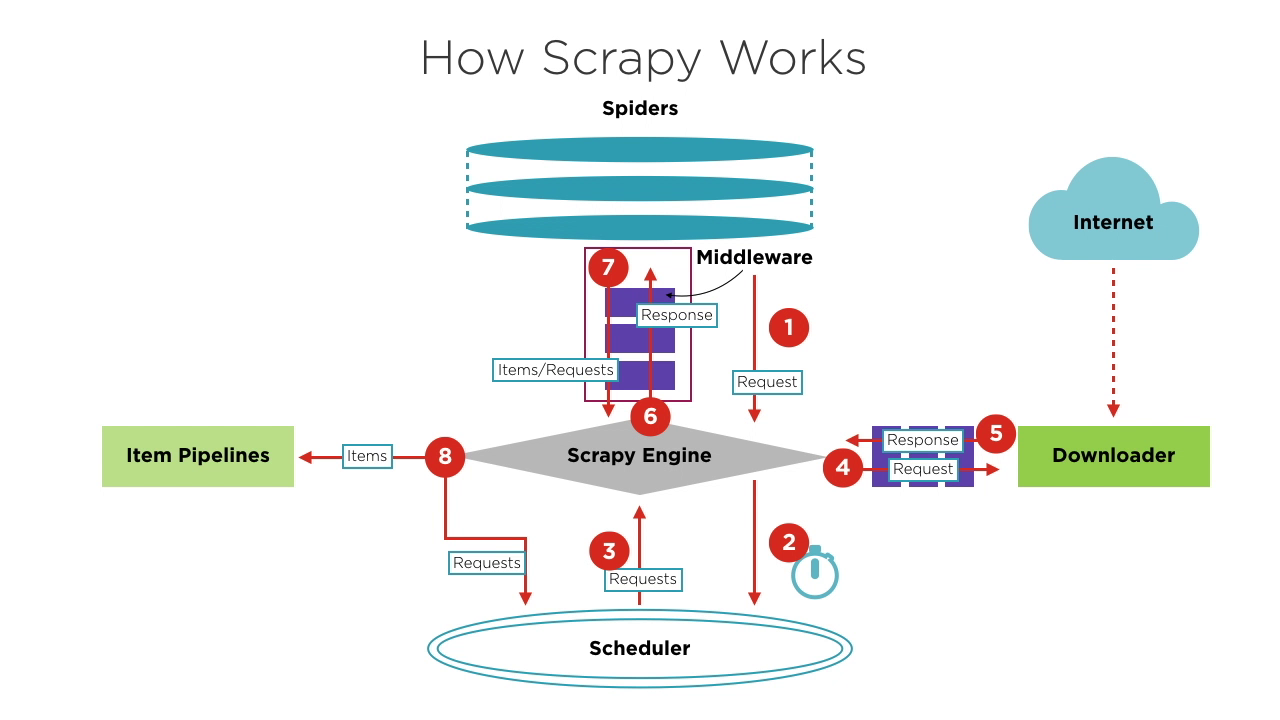
Componentes do Scrapy
- Motor Scrapy: O núcleo do framework, gerenciando o fluxo de dados e eventos no sistema. É como o cérebro, lidando com transferência de dados e processamento de lógica.
- Agendador: Recebe solicitações do motor, as fila e as envia de volta ao motor para que o descarregador as execute. Ele mantém a lógica de agendamento, como FIFO (Primeiro a Chegar, Primeiro a Sair), LIFO (Último a Chegar, Primeiro a Sair) e filas de prioridade.
- Spiders: Define a lógica para raspagem e análise de páginas. Cada spider é responsável por processar respostas, gerar itens e novas solicitações para enviar ao motor.
- Descarregador: Lida com o envio de solicitações aos servidores e recebimento de respostas, que são então enviadas de volta ao motor.
- Pipelines de Itens: Processa os itens extraídos pelos spiders, realizando tarefas como limpeza de dados, validação e armazenamento.
- Middlewares:
- Middlewares de Descarregador: Posicionados entre o motor e o descarregador, lidam com solicitações e respostas.
- Middlewares de Spider: Posicionados entre o motor e os spiders, lidam com itens, solicitações e respostas.
Tendo dificuldade com a falha repetida em resolver o irritante CAPTCHA? Descubra a resolução automática de CAPTCHA com a tecnologia de desbloqueio web baseada em IA do CapSolver!
Aumente imediatamente seu orçamento de automação!
Use o código de bônus CAPN ao recarregar sua conta do CapSolver para obter um bônus extra de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
.
Fluxo Básico de um Projeto Scrapy
-
Ao iniciar um projeto de crawleio, o Motor encontra o Spider que lida com o site alvo com base no site a ser raspado. O Spider gera uma ou mais solicitações iniciais correspondentes às páginas que precisam ser raspadas e as envia ao Motor.
-
O Motor obtém essas solicitações do Spider e as passa ao Agendador para aguardar o agendamento.
-
O Motor pede ao Agendador a próxima solicitação a ser processada. Nesse momento, o Agendador seleciona uma solicitação apropriada com base na sua lógica de agendamento e a envia ao Motor.
-
O Motor encaminha a solicitação do Agendador ao Descarregador para execução da download. O processo de enviar a solicitação ao Descarregador passa por vários Middlewares de Descarregador pré-definidos.
-
O Descarregador envia a solicitação ao servidor alvo, recebe a resposta correspondente e a retorna ao Motor. O processo de retornar a resposta ao Motor também passa por vários Middlewares de Descarregador pré-definidos.
-
A resposta recebida pelo Motor do Descarregador contém o conteúdo do site alvo. O Motor enviará essa resposta ao Spider correspondente para processamento. O processo de enviar a resposta ao Spider passa por Middlewares de Spider pré-definidos.
-
O Spider processa a resposta, analisando seu conteúdo. Nesse momento, o Spider produz um ou mais itens de resultados raspados ou uma ou mais solicitações correspondentes às páginas subsequentes a serem raspadas. Em seguida, ele envia esses itens ou solicitações de volta ao Motor para processamento. O processo de enviar itens ou solicitações ao Motor passa por Middlewares de Spider pré-definidos.
-
O Motor encaminha um ou mais itens enviados de volta pelo Spider para as pipelines de itens pré-definidas para uma série de operações de processamento ou armazenamento de dados. Ele encaminha um ou mais solicitações enviadas de volta pelo Spider ao Agendador para aguardar o próximo agendamento.
Os passos 2 a 8 são repetidos até que não haja mais solicitações no Agendador. Nesse momento, o Motor fechará o Spider e o processo de crawleio será encerrado.
Do ponto de vista geral, cada componente se concentra apenas em uma função, a acoplamento entre os componentes é muito baixo e é muito fácil de estender. O Motor então combina os vários componentes, permitindo que cada componente cumpra sua função, coopere com outros e completem conjuntamente o trabalho de crawleio. Além disso, com o suporte do Scrapy para processamento assíncrono, ele pode maximizar o uso da largura de banda da rede e melhorar a eficiência da raspagem e processamento de dados.
O que é Selenium?
Selenium é uma ferramenta de automação web de código aberto que permite controlar navegadores web de forma programática. Embora seja principalmente usada para testar aplicações web, o Selenium também é popular para raspagem de web porque pode interagir com sites com JavaScript pesado que são difíceis de raspagem com métodos tradicionais. É importante notar que o Selenium só pode testar aplicações web. Não podemos usar o Selenium para testar qualquer aplicação de desktop (software) ou aplicação móvel.
O núcleo do Selenium é o Selenium WebDriver, que fornece uma interface de programação que permite aos desenvolvedores escrever código para controlar o comportamento e interações do navegador. Esta ferramenta é muito popular no desenvolvimento e testes web porque suporta vários navegadores e pode funcionar em diferentes sistemas operacionais. O Selenium WebDriver permite aos desenvolvedores simular ações do usuário no navegador, como clicar em botões, preencher formulários e navegar por páginas.
O Selenium WebDriver oferece funcionalidades ricas, tornando-o uma escolha ideal para testes de automação web.
Principais Funcionalidades do Selenium WebDriver
-
Controle de Navegadores: O Selenium WebDriver suporta vários navegadores principais, incluindo Chrome, Firefox, Safari, Edge e Internet Explorer. Ele pode iniciar e controlar esses navegadores, realizando operações como abrir páginas web, clicar em elementos, inserir texto e capturar screenshots.
-
Compatibilidade Multiplataforma: O Selenium WebDriver pode funcionar em diferentes sistemas operacionais, incluindo Windows, macOS e Linux. Isso o torna muito útil em testes multiplataforma, permitindo que os desenvolvedores garantam que suas aplicações funcionem consistentemente em vários ambientes.
-
Suporte a Linguagens de Programação: O Selenium WebDriver suporta várias linguagens de programação, incluindo Java, Python, C#, Ruby e JavaScript. Os desenvolvedores podem escolher a linguagem com que estão mais familiarizados para escrever scripts de teste automatizados, aumentando assim a eficiência no desenvolvimento e testes.
-
Interação com Elementos Web: O Selenium WebDriver fornece uma API rica para localizar e manipular elementos de páginas web. Ele suporta localização de elementos por diversos métodos, como ID, nome da classe, nome da tag, seletor CSS, XPath, etc. Os desenvolvedores podem usar estas APIs para implementar operações como clicar, inserir, selecionar e arrastar e soltar.
Comparação entre Scrapy e Selenium
| Funcionalidade | Scrapy | Selenium |
|---|---|---|
| Propósito | Apenas raspagem de web | Raspagem de web e teste de aplicações web |
| Suporte a Linguagens | Apenas Python | Java, Python, C#, Ruby, JavaScript, etc. |
| Velocidade de Execução | Rápido | Mais lento |
| Extensibilidade | Alta | Limitada |
| Suporte Assíncrono | Sim | Não |
| Renderização Dinâmica | Não | Sim |
| Interação com Navegador | Não | Sim |
| Consumo de Recursos de Memória | Baixo | Alto |
Escolhendo entre Scrapy e Selenium
-
Escolha o Scrapy se:
- Seu alvo são páginas da web estáticas sem renderização dinâmica.
- Você precisa otimizar o consumo de recursos e a velocidade de execução.
- Você precisa de processamento extensivo de dados e middlewares personalizados.
-
Escolha o Selenium se:
- Seu site alvo envolve conteúdo dinâmico e exige interação.
- A eficiência de execução e o consumo de recursos são menos importantes.
A escolha entre Scrapy e Selenium depende do cenário de aplicação específico, compare as vantagens e desvantagens de cada um e escolha o mais adequado para você. Claro, se suas habilidades de programação forem suficientemente boas, você pode até mesmo usar Scrapy e Selenium simultaneamente.
Desafios com Scrapy e Selenium
Seja usando Scrapy ou Selenium, você pode enfrentar o mesmo problema: desafios de bot. Desafios de bot são amplamente usados para distinguir entre computadores e humanos, impedir o acesso de bots maliciosos a sites e proteger dados de serem raspados. Desafios comuns incluem CAPTCHA, reCAPTCHA, CAPTCHA, CAPTCHA, Cloudflare Turnstile, CAPTCHA, CAPTCHA WAF e outros. Eles usam imagens complexas e desafios de JavaScript difíceis de ler para determinar se você é um bot. Alguns desafios são até difíceis para humanos passarem.
Como diz o ditado, "Cada um tem sua especialidade." A criação do CapSolver tornou este problema mais simples. CapSolver usa tecnologia de desbloqueio web baseada em IA que pode ajudá-lo a resolver diversos desafios de bot em segundos. Não importa que tipo de desafio de imagem ou pergunta você encontre, você pode confiantemente deixá-lo para o CapSolver. Se não for bem-sucedido, você não será cobrado.
O CapSolver fornece uma extensão de navegador que pode resolver automaticamente desafios de CAPTCHA durante seu processo de raspagem de dados com Selenium. Ele também oferece um método de API para resolver CAPTCHAs e obter tokens, permitindo que você lide facilmente com diversos desafios no Scrapy. Todo esse trabalho pode ser concluído em apenas alguns segundos. Consulte a documentação do CapSolver para mais informações.
Conclusão
Escolher entre Scrapy e Selenium depende das necessidades do seu projeto. O Scrapy é ideal para raspagem eficiente de sites estáticos, enquanto o Selenium se destaca com páginas dinâmicas e com JavaScript pesado. Considere os requisitos específicos, como velocidade, uso de recursos e nível de interação. Para superar desafios como CAPTCHAs, ferramentas como CapSolver oferecem soluções eficientes, tornando o processo de raspagem mais suave. Em última análise, a escolha certa garante um projeto de raspagem bem-sucedido e eficiente.
Perguntas Frequentes
1. É possível usar o Scrapy e o Selenium em um único projeto?
Sim. Uma abordagem comum é usar o Selenium para lidar com renderização de JavaScript ou interações complexas (como fluxos de login), depois passar o HTML renderizado ou URLs extraídas para o Scrapy para crawleio de alta velocidade e em larga escala e extração de dados. Este modelo híbrido combina a flexibilidade do Selenium com o desempenho do Scrapy.
2. O Scrapy é adequado para sites modernos com muita JavaScript?
Por padrão, o Scrapy não executa JavaScript, o que o torna inadequado para sites que dependem fortemente de renderização do lado do cliente. No entanto, ele pode ser estendido usando ferramentas como Playwright, Splash ou Selenium para lidar com conteúdo JavaScript quando necessário.
3. Qual ferramenta é mais eficiente em recursos para raspagem em larga escala?
O Scrapy é significativamente mais eficiente em recursos do que o Selenium. Ele usa rede assíncrona e não requer iniciar um navegador, tornando-o mais adequado para tarefas de raspagem em volume alto e em larga escala. O Selenium consome mais CPU e memória, pois controla um navegador real, limitando sua escalabilidade.
Ver mais
Web ScrapingApr 22, 2026
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.

Web ScrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

