Integração do Crawlab com o CapSolver: Resolução Automatizada de CAPTCHA para Raspagem Distribuída

Adélia Cruz
Neural Network Developer

Gerenciar crawlers web em escala exige infraestrutura robusta que possa lidar com os desafios modernos de anti-bot. Crawlab é uma plataforma poderosa de gerenciamento de crawlers web distribuídos e CapSolver é um serviço de resolução de CAPTCHA baseado em IA. Juntos, eles permitem sistemas de raspagem de dados de nível corporativo que automaticamente contornam os desafios de CAPTCHA.
Este guia fornece exemplos de código completos e prontos para uso para integrar o CapSolver aos seus spiders do Crawlab.
O que você aprenderá
- Resolvendo reCAPTCHA v2 com Selenium
- Resolvendo Cloudflare Turnstile
- Integração com middleware do Scrapy
- Integração com Node.js/Puppeteer
- Melhores práticas para gerenciamento de CAPTCHAs em escala
O que é Crawlab?
Crawlab é uma plataforma de administração de crawlers web distribuídos projetada para gerenciar spiders em múltiplas linguagens de programação.
Principais funcionalidades
- Independente de linguagem: Suporta Python, Node.js, Go, Java e PHP
- Framework flexível: Funciona com Scrapy, Selenium, Puppeteer, Playwright
- Arquitetura distribuída: Escalabilidade horizontal com nós mestre/trabalhador
- Interface de gerenciamento: Interface web para gerenciamento e agendamento de spiders
Instalação
bash
# Usando Docker Compose
git clone https://github.com/crawlab-team/crawlab.git
cd crawlab
docker-compose up -dAcesse a interface em http://localhost:8080 (padrão: admin/admin).
O que é CapSolver?
CapSolver é um serviço de resolução de CAPTCHA baseado em IA que fornece soluções rápidas e confiáveis para vários tipos de CAPTCHA.
Tipos de CAPTCHA suportados
- reCAPTCHA: v2, v3 e Enterprise
- Cloudflare: Turnstile e Challenge
- AWS WAF: Bypass de proteção
- E mais
Fluxo de trabalho da API
- Enviar parâmetros de CAPTCHA (tipo, siteKey, URL)
- Receber ID da tarefa
- Consultar solução
- Injetar token na página
Pré-requisitos
- Python 3.8+ ou Node.js 16+
- Chave de API do CapSolver - Registre-se aqui
- Navegador Chrome/Chromium
bash
# Dependências do Python
pip install selenium requestsResolvendo reCAPTCHA v2 com Selenium
Script Python completo para resolver reCAPTCHA v2:
python
"""
Crawlab + CapSolver: Solucionador de reCAPTCHA v2
Script completo para resolver desafios de reCAPTCHA v2 com Selenium
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Configuração
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'SUA_CHAVE_DE_API_DO_CAPSOLVER')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverClient:
"""Cliente da API do CapSolver para reCAPTCHA v2"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def create_task(self, task: dict) -> str:
"""Criar uma tarefa de resolução de CAPTCHA"""
payload = {
"clientKey": self.api_key,
"task": task
}
response = self.session.post(
f"{CAPSOLVER_API}/createTask",
json=payload
)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Erro do CapSolver: {result.get('errorDescription')}")
return result['taskId']
def get_task_result(self, task_id: str, timeout: int = 120) -> dict:
"""Consultar resultado da tarefa"""
for _ in range(timeout):
payload = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(
f"{CAPSOLVER_API}/getTaskResult",
json=payload
)
result = response.json()
if result.get('status') == 'ready':
return result['solution']
if result.get('status') == 'failed':
raise Exception("Falha na resolução do CAPTCHA")
time.sleep(1)
raise Exception("Tempo esgotado ao esperar pela solução")
def solve_recaptcha_v2(self, website_url: str, site_key: str) -> str:
"""Resolver reCAPTCHA v2 e retornar token"""
task = {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
print(f"Criando tarefa para {website_url}...")
task_id = self.create_task(task)
print(f"Tarefa criada: {task_id}")
print("Aguardando solução...")
solution = self.get_task_result(task_id)
return solution['gRecaptchaResponse']
def get_balance(self) -> float:
"""Obter saldo da conta"""
response = self.session.post(
f"{CAPSOLVER_API}/getBalance",
json={"clientKey": self.api_key}
)
return response.json().get('balance', 0)
class RecaptchaV2Crawler:
"""Crawler com Selenium e suporte a reCAPTCHA v2"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.capsolver = CapsolverClient(CAPSOLVER_API_KEY)
def start(self):
"""Iniciar navegador"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--window-size=1920,1080")
self.driver = webdriver.Chrome(options=options)
print("Navegador iniciado")
def stop(self):
"""Fechar navegador"""
if self.driver:
self.driver.quit()
print("Navegador fechado")
def detect_recaptcha(self) -> str:
"""Detectar reCAPTCHA e retornar chave do site"""
try:
element = self.driver.find_element(By.CLASS_NAME, "g-recaptcha")
return element.get_attribute("data-sitekey")
except:
return None
def inject_token(self, token: str):
"""Injetar token resolvido na página"""
self.driver.execute_script(f"""
// Definir campo de texto g-recaptcha-response
var responseField = document.getElementById('g-recaptcha-response');
if (responseField) {{
responseField.style.display = 'block';
responseField.value = '{token}';
}}
// Definir todos os campos de resposta ocultos
var textareas = document.querySelectorAll('textarea[name="g-recaptcha-response"]');
for (var i = 0; i < textareas.length; i++) {{
textareas[i].value = '{token}';
}}
""")
print("Token injetado")
def submit_form(self):
"""Enviar formulário"""
try:
submit = self.driver.find_element(
By.CSS_SELECTOR,
'button[type="submit"], input[type="submit"]'
)
submit.click()
print("Formulário enviado")
except Exception as e:
print(f"Não foi possível enviar formulário: {e}")
def crawl(self, url: str) -> dict:
"""Raspar URL com suporte a reCAPTCHA v2"""
result = {
'url': url,
'success': False,
'captcha_solved': False
}
try:
print(f"Navegando para: {url}")
self.driver.get(url)
time.sleep(2)
# Detectar reCAPTCHA
site_key = self.detect_recaptcha()
if site_key:
print(f"reCAPTCHA v2 detectado! Chave do site: {site_key}")
# Resolver CAPTCHA
token = self.capsolver.solve_recaptcha_v2(url, site_key)
print(f"Token recebido: {token[:50]}...")
# Injetar token
self.inject_token(token)
result['captcha_solved'] = True
# Enviar formulário
self.submit_form()
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
result['error'] = str(e)
print(f"Erro: {e}")
return result
def main():
"""Ponto de entrada principal"""
# Verificar saldo
client = CapsolverClient(CAPSOLVER_API_KEY)
print(f"Saldo do CapSolver: ${client.get_balance():.2f}")
# Criar crawler
crawler = RecaptchaV2Crawler(headless=True)
try:
crawler.start()
# Raspar URL alvo (substitua pela sua URL alvo)
result = crawler.crawl("https://exemplo.com/pagina-protegida")
print("\n" + "=" * 50)
print("RESULTADO:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Resolvendo Cloudflare Turnstile
Script Python completo para resolver Cloudflare Turnstile:
python
"""
Crawlab + CapSolver: Solucionador de Cloudflare Turnstile
Script completo para resolver desafios de Turnstile
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
# Configuração
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'SUA_CHAVE_DE_API_DO_CAPSOLVER')
CAPSOLVER_API = 'https://api.capsolver.com'
class TurnstileSolver:
"""Cliente do CapSolver para Turnstile"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def solve(self, website_url: str, site_key: str) -> str:
"""Resolver CAPTCHA de Turnstile"""
print(f"Resolvendo Turnstile para {website_url}")
print(f"Chave do site: {site_key}")
# Criar tarefa
task_data = {
"clientKey": self.api_key,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
}
response = self.session.post(f"{CAPSOLVER_API}/createTask", json=task_data)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Erro do CapSolver: {result.get('errorDescription')}")
task_id = result['taskId']
print(f"Tarefa criada: {task_id}")
# Consultar resultado
for i in range(120):
result_data = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(f"{CAPSOLVER_API}/getTaskResult", json=result_data)
result = response.json()
if result.get('status') == 'ready':
token = result['solution']['token']
print(f"Turnstile resolvido!")
return token
if result.get('status') == 'failed':
raise Exception("Falha na resolução do Turnstile")
time.sleep(1)
raise Exception("Tempo esgotado ao esperar pela solução")
class TurnstileCrawler:
"""Crawler com Selenium e suporte a Turnstile"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.solver = TurnstileSolver(CAPSOLVER_API_KEY)
def start(self):
"""Iniciar navegador"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
self.driver = webdriver.Chrome(options=options)
def stop(self):
"""Fechar navegador"""
if self.driver:
self.driver.quit()
def detect_turnstile(self) -> str:
"""Detectar Turnstile e retornar chave do site"""
try:
turnstile = self.driver.find_element(By.CLASS_NAME, "cf-turnstile")
return turnstile.get_attribute("data-sitekey")
except NoSuchElementException:
return None
def inject_token(self, token: str):
"""Injetar token do Turnstile"""
self.driver.execute_script(f"""
var token = '{token}';
// Encontrar campo cf-turnstile-response
var field = document.querySelector('[name="cf-turnstile-response"]');
if (field) {{
field.value = token;
}}
// Encontrar todos os campos de Turnstile
var inputs = document.querySelectorAll('input[name*="turnstile"]');
for (var i = 0; i < inputs.length; i++) {{
inputs[i].value = token;
}}
""")
print("Token injetado!")
def crawl(self, url: str) -> dict:
"""Raspar URL com suporte a Turnstile"""
result = {
'url': url,
'success': False,
'captcha_solved': False,
'captcha_type': None
}
try:
print(f"Navegando para: {url}")
self.driver.get(url)
time.sleep(3)
# Detectar Turnstile
site_key = self.detect_turnstile()
if site_key:
result['captcha_type'] = 'turnstile'
print(f"Turnstile detectado! Chave do site: {site_key}")
# Resolver
token = self.solver.solve(url, site_key)
# Injetar
self.inject_token(token)
result['captcha_solved'] = True
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
print(f"Erro: {e}")
result['error'] = str(e)
return result
def main():
"""Ponto de entrada principal"""
crawler = TurnstileCrawler(headless=True)
try:
crawler.start()
# Raspar URL alvo (substitua pela sua URL alvo)
result = crawler.crawl("https://exemplo.com/protected-page-com-turnstile")
print("\n" + "=" * 50)
print("RESULTADO:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Integração com Scrapy
Spider do Scrapy com middleware do CapSolver:
python
"""
Crawlab + CapSolver: Spider do Scrapy
Spider do Scrapy com middleware de resolução de CAPTCHA
"""
import scrapy
import requests
import time
import os
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'SUA_CHAVE_DE_API_DO_CAPSOLVER')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverMiddleware:
"""Middleware do Scrapy para resolução de CAPTCHA"""
def __init__(self):
self.api_key = CAPSOLVER_API_KEY
def solve_recaptcha_v2(self, url: str, site_key: str) -> str:
"""Resolver reCAPTCHA v2"""Criar tarefa
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": self.api_key,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": url,
"websiteKey": site_key
}
}
)
task_id = response.json()['taskId']
# Verificar resultado
for _ in range(120):
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={"clientKey": self.api_key, "taskId": task_id}
).json()
if result.get('status') == 'ready':
return result['solution']['gRecaptchaResponse']
time.sleep(1)
raise Exception("Tempo esgotado")class CaptchaSpider(scrapy.Spider):
"""Spider com tratamento de CAPTCHA"""
name = "captcha_spider"
start_urls = ["https://example.com/protected"]
custom_settings = {
'DOWNLOAD_DELAY': 2,
'CONCURRENT_REQUESTS': 1,
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.capsolver = CapsolverMiddleware()
def parse(self, response):
# Verificar reCAPTCHA
site_key = response.css('.g-recaptcha::attr(data-sitekey)').get()
if site_key:
self.logger.info(f"reCAPTCHA detectado: {site_key}")
# Resolver CAPTCHA
token = self.capsolver.solve_recaptcha_v2(response.url, site_key)
# Enviar formulário com token
yield scrapy.FormRequest.from_response(
response,
formdata={'g-recaptcha-response': token},
callback=self.after_captcha
)
else:
yield from self.extract_data(response)
def after_captcha(self, response):
"""Processar página após CAPTCHA"""
yield from self.extract_data(response)
def extract_data(self, response):
"""Extrair dados da página"""
yield {
'title': response.css('title::text').get(),
'url': response.url,
}Configurações do Scrapy (settings.py)
"""
BOT_NAME = 'captcha_crawler'
SPIDER_MODULES = ['spiders']
Capsolver
CAPSOLVER_API_KEY = 'SUA_CHAVE_API_CAPSOLVER'
Limitação de taxa
DOWNLOAD_DELAY = 2
CONCURRENT_REQUESTS = 1
ROBOTSTXT_OBEY = True
"""
---
## Integração Node.js/Puppeteer
Script completo em Node.js com Puppeteer:
```javascript
/**
* Crawlab + Capsolver: Spider Puppeteer
* Script completo em Node.js para resolução de CAPTCHA
*/
const puppeteer = require('puppeteer');
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY || 'SUA_CHAVE_API_CAPSOLVER';
const CAPSOLVER_API = 'https://api.capsolver.com';
/**
* Cliente Capsolver
*/
class Capsolver {
constructor(apiKey) {
this.apiKey = apiKey;
}
async createTask(task) {
const response = await fetch(`${CAPSOLVER_API}/createTask`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
task: task
})
});
const result = await response.json();
if (result.errorId !== 0) {
throw new Error(result.errorDescription);
}
return result.taskId;
}
async getTaskResult(taskId, timeout = 120) {
for (let i = 0; i < timeout; i++) {
const response = await fetch(`${CAPSOLVER_API}/getTaskResult`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
taskId: taskId
})
});
const result = await response.json();
if (result.status === 'ready') {
return result.solution;
}
if (result.status === 'failed') {
throw new Error('Tarefa falhou');
}
await new Promise(r => setTimeout(r, 1000));
}
throw new Error('Tempo esgotado');
}
async solveRecaptchaV2(url, siteKey) {
const taskId = await this.createTask({
type: 'ReCaptchaV2TaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse;
}
async solveTurnstile(url, siteKey) {
const taskId = await this.createTask({
type: 'AntiTurnstileTaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.token;
}
}
/**
* Função principal de navegação
*/
async function crawlWithCaptcha(url) {
const capsolver = new Capsolver(CAPSOLVER_API_KEY);
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
try {
console.log(`Navegando: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
// Detectar tipo de CAPTCHA
const captchaInfo = await page.evaluate(() => {
const recaptcha = document.querySelector('.g-recaptcha');
if (recaptcha) {
return {
type: 'recaptcha',
siteKey: recaptcha.dataset.sitekey
};
}
const turnstile = document.querySelector('.cf-turnstile');
if (turnstile) {
return {
type: 'turnstile',
siteKey: turnstile.dataset.sitekey
};
}
return null;
});
if (captchaInfo) {
console.log(`${captchaInfo.type} detectado!`);
let token;
if (captchaInfo.type === 'recaptcha') {
token = await capsolver.solveRecaptchaV2(url, captchaInfo.siteKey);
// Injetar token
await page.evaluate((t) => {
const field = document.getElementById('g-recaptcha-response');
if (field) field.value = t;
document.querySelectorAll('textarea[name="g-recaptcha-response"]')
.forEach(el => el.value = t);
}, token);
} else if (captchaInfo.type === 'turnstile') {
token = await capsolver.solveTurnstile(url, captchaInfo.siteKey);
// Injetar token
await page.evaluate((t) => {
const field = document.querySelector('[name="cf-turnstile-response"]');
if (field) field.value = t;
}, token);
}
console.log('CAPTCHA resolvido e injetado!');
}
// Extrair dados
const data = await page.evaluate(() => ({
title: document.title,
url: window.location.href
}));
return data;
} finally {
await browser.close();
}
}
// Execução principal
const targetUrl = process.argv[2] || 'https://example.com';
crawlWithCaptcha(targetUrl)
.then(result => {
console.log('\nResultado:');
console.log(JSON.stringify(result, null, 2));
})
.catch(console.error);Boas Práticas
1. Tratamento de Erros com Reinícios
python
def solve_with_retry(solver, url, site_key, max_retries=3):
"""Resolver CAPTCHA com lógica de reinício"""
for attempt in range(max_retries):
try:
return solver.solve(url, site_key)
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"Tentativa {attempt + 1} falhou: {e}")
time.sleep(2 ** attempt) # Backoff exponencial2. Gestão de Custos
- Detectar antes de resolver: Chamar Capsolver apenas quando CAPTCHA estiver presente
- Armazenar em cache tokens: Tokens de reCAPTCHA válidos por ~2 minutos
- Monitorar saldo: Verificar saldo antes de trabalhos em lote
3. Limitação de Taxa
python
# Configurações do Scrapy
DOWNLOAD_DELAY = 3
CONCURRENT_REQUESTS_PER_DOMAIN = 14. Variáveis de Ambiente
bash
export CAPSOLVER_API_KEY="sua-chave-aqui"Solução de Problemas
| Erro | Causa | Solução |
|---|---|---|
ERROR_ZERO_BALANCE |
Sem créditos | Recarregar conta do CapSolver |
ERROR_CAPTCHA_UNSOLVABLE |
Parâmetros inválidos | Verificar extração da chave do site |
TimeoutError |
Problemas de rede | Aumentar tempo limite, adicionar reinícios |
WebDriverException |
Falha no navegador | Adicionar o sinalizador --no-sandbox |
Perguntas Frequentes
Q: Por quanto tempo os tokens CAPTCHA são válidos?
A: Tokens de reCAPTCHA: ~2 minutos. Turnstile: varia conforme o site.
Q: Qual é o tempo médio de resolução?
A: reCAPTCHA v2: 5-15s, Turnstile: 1-10s.
Q: Posso usar meu próprio proxy?
A: Sim, use os tipos de tarefa sem o sufixo "ProxyLess" e forneça a configuração do proxy.
Conclusão
Integrar o CapSolver com o Crawlab permite um tratamento robusto de CAPTCHA em sua infraestrutura de raspagem distribuída. Os scripts completos acima podem ser copiados diretamente para seus spiders do Crawlab.
Pronto para começar? Registre-se no CapSolver e eleve seus raspadores ao próximo nível!
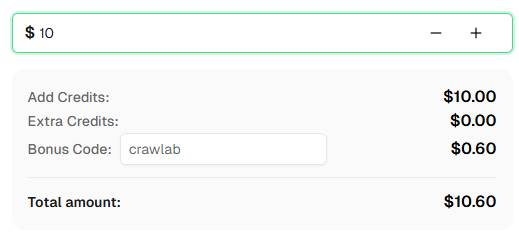
💡 Bônus Exclusivo para Usuários de Integração Crawlab:
Para comemorar esta integração, oferecemos um código de bônus exclusivo de 6% — Crawlab para todos os usuários do CapSolver que se registrarem por meio deste tutorial.
Basta inserir o código durante o recarregamento no Dashboard para receber créditos extras de 6% instantaneamente.
13. Documentações
- 13.1. Documentação Crawlab
- 13.2. GitHub Crawlab
- 13.3. Documentação Capsolver
- 13.4. Referência da API Capsolver
Ver mais
Web ScrapingApr 22, 2026
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.
Web ScrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

