Como lidar com os bloqueios de raspagem da web: métodos práticos que funcionam

Ethan Collins
Pattern Recognition Specialist

TL;Dr:
- Entenda o Mecanismo: Sites usam rastreamento de IP, fingerprinting de navegador e análise de comportamento para identificar e bloquear scripts automatizados.
- Implemente Rotação: Use proxies residenciais em rotação e strings de User-Agent diversas para imitar padrões de tráfego humanos.
- Lide com os Desafios: Integre ferramentas especializadas para resolver CAPTCHAs e gerenciar sistemas complexos de detecção de bots de forma eficiente.
- Mantenha-se Ético: Sempre siga as diretrizes do robots.txt e implemente limitação de requisições para manter um impacto baixo nos servidores alvo.
Introdução
O web scraping tornou-se um componente essencial para a tomada de decisões baseada em dados, mas o cenário de coleta de dados automatizada está cada vez mais desafiador. À medida que os sites implementam medidas de segurança mais sofisticadas, aprender como lidar com os bloqueios de web scraping deixou de ser apenas uma vantagem — é uma necessidade para qualquer projeto bem-sucedido de extração de dados. Este guia fornece uma visão abrangente sobre por que os bloqueios ocorrem, a tecnologia por trás dos mecanismos de detecção e as estratégias mais eficazes e éticas para garantir que seus scrapers permaneçam operacionais. Seja você um desenvolvedor construindo um crawler personalizado ou um analista de dados supervisionando uma operação em larga escala, entender esses métodos práticos o ajudará a manter acesso consistente às informações que você precisa.
Compreendendo a Natureza dos Bloqueios de Web Scraping
Para gerenciar obstáculos de forma eficaz, é necessário primeiro entender o que são e por que existem. Um bloqueio de web scraping é uma medida de defesa implementada por um site para impedir scripts automatizados de acessar seu conteúdo. Essas medidas geralmente fazem parte de uma estratégia de segurança mais ampla, projetada para proteger recursos do servidor, prevenir o roubo de propriedade intelectual ou manter a integridade dos dados dos usuários.
De acordo com dados recentes da indústria, o tráfego automatizado representa uma parte significativa de todas as requisições web, levando muitas plataformas a adotar filtros agressivos. Você pode encontrar mais detalhes sobre tendências globais no relatório Dados de Tráfego de Bot da Statista. Quando um servidor detecta padrões que se desviam do comportamento humano padrão, ele pode responder servindo um CAPTCHA, reduzindo a velocidade da conexão ou emitindo um banimento completo do IP. Aprender como lidar com os bloqueios de web scraping em tais cenários é essencial para a persistência dos dados.
Fundamentos Técnicos: Como os Mecanismos de Detecção Funcionam
Sistemas de segurança modernos não dependem de um único fator para identificar bots. Em vez disso, utilizam uma combinação de técnicas para construir um perfil de risco para cada requisição recebida.
1. Rastreamento Baseado em IP
Esta é a camada mais fundamental de defesa. Servidores monitoram o número de requisições provenientes de um único endereço IP em um período específico. Se a frequência ultrapassar um limite pré-definido, o IP é marcado. É por isso que saber como lidar com os bloqueios de web scraping no nível de rede é tão importante. IPs de data centers são frequentemente bloqueados antecipadamente, pois raramente são usados por visitantes legítimos.
2. Fingerprinting de Navegador
Além do endereço IP, os sites podem coletar uma vasta quantidade de informações do seu ambiente de navegador. Isso inclui resolução da tela, fontes instaladas, fuso horário e especificações de hardware. Se esses detalhes parecerem inconsistentes ou muito "limpos" (típicos de navegadores headless), o sistema identifica a requisição como automatizada.
3. Análise de Comportamento
Plataformas sofisticadas rastreiam como um usuário interage com a página. Humanos movem o mouse em padrões não lineares, levam tempo para ler o conteúdo e clicam em elementos com ritmos variados. Em contraste, um script pode pular diretamente para uma URL e extrair dados em milissegundos. Qualquer desvio do comportamento humano esperado dispara um alerta. Essa detecção baseada no comportamento é um dos desafios mais difíceis ao descobrir como lidar com os bloqueios de web scraping.
Tipos Comuns de Desafios de CAPTCHA
Quando um sistema está inseguro, mas suspeita, ele geralmente apresenta um CAPTCHA. Compreender esses tipos é crucial para saber como lidar com os bloqueios de web scraping de forma eficaz.
| Tipo de CAPTCHA | Descrição | Lógica de Detecção Primária |
|---|---|---|
| Reconhecimento de Imagem | Usuários devem selecionar objetos específicos (ex.: semáforos) em uma grade. | Testa a capacidade de processar dados visuais e identifica padrões de clique humanos. |
| CAPTCHA Invisível | Funciona em segundo plano sem interação do usuário. | Analisa o ambiente do navegador e o comportamento histórico para atribuir uma pontuação de risco. |
| Desafios de Texto/Equação | Exige resolver uma equação simples ou digitar texto distorcido. | Baseia-se na dificuldade da OCR (Reconhecimento Óptico de Caracteres) para bots antigos. |
| Quebra-cabeça/Deslizamento | Usuários devem arrastar uma peça para completar uma imagem. | Foca no movimento físico do cursor e no timing da ação. |
Métodos Práticos para Lidar com Bloqueios de Web Scraping
Implementar as estratégias técnicas certas pode reduzir significativamente a probabilidade de ser detectado. Aqui estão os métodos mais eficazes utilizados por profissionais hoje em dia.
Use Proxies Residenciais em Rotação
Como os bloqueios de IP são comuns, usar um conjunto de proxies residenciais é uma das melhores formas de evitar bloqueios de IP e garantir altas taxas de sucesso. Esses proxies são uma base das melhores práticas de web scraping. Ao contrário dos IPs de data center, os IPs residenciais estão associados a conexões reais de internet doméstica, tornando-os muito mais difíceis de distinguir de usuários legítimos. Ao rotacionar esses IPs a cada poucas requisições, você distribui seu tráfego e permanece em segundo plano.
Gerencie Cabeçalhos de Requisição e User-Agents
Toda requisição HTTP inclui cabeçalhos que informam ao servidor sobre o cliente. Um erro comum é usar cabeçalhos de biblioteca padrão como "python-requests/2.25.1". Em vez disso, você deve usar uma variedade de strings de User-Agent reais. Consulte a Documentação de User-Agent da MDN para entender como estruturar esses corretamente. Certifique-se de que seus cabeçalhos incluam campos como "Accept-Language" e "Referer" para imitar uma sessão de navegação real.
Implemente Limitação de Requisições
Velocidade é frequentemente o maior indício de um bot. Ao adicionar atrasos aleatórios entre suas requisições, você pode simular o comportamento de um navegador humano. Essa técnica, conhecida como limitação, evita que você sobrecarregue o servidor alvo e reduz as chances de disparar alarmes de limitação de taxa. Implementar essas melhores práticas de web scraping o ajudará a manter acesso a dados sensíveis, enquanto também evita bloqueios de IP durante operações em larga escala.
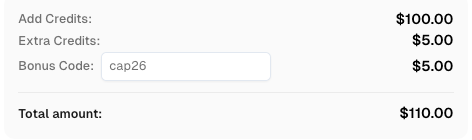
Use o código
CAP26ao se cadastrar no CapSolver para receber créditos extras!
Resolva CAPTCHAs Automaticamente
Mesmo com cabeçalhos e proxies perfeitos, você eventualmente encontrará um desafio. É aí que serviços especializados se tornam valiosos. Por exemplo, o CapSolver oferece uma API robusta para resolver diversos tipos de desafios, como ReCaptcha e FriendlyCaptcha, garantindo que seus fluxos automatizados não sejam interrompidos. Essas ferramentas são essenciais para como lidar com os bloqueios de web scraping em ambientes modernos.
Se você estiver usando ferramentas como cURL ou Python para sua automação, pode integrar uma solução seguindo este fluxo geral:
- Envie a Tarefa: Envie os detalhes do CAPTCHA (chave do site, URL) para o serviço.
- Recupere a Solução: Consulte a API usando o ID da Tarefa até que a solução esteja pronta.
- Envie o Token: Use o token retornado para contornar o desafio no site alvo.
Aqui está um exemplo simplificado com base na documentação do CapSolver para enviar uma tarefa:
json
{
"clientKey": "SUA_CHAVE_DE_API",
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": "https://www.example.com",
"websiteKey": "6LcR_okUAAAAAPYrPe-z_bx1oYxq6zz_S0vO49zV"
}
}Resumo Comparativo: Técnicas de Scraping
Para ajudá-lo a escolher a abordagem certa, aqui está uma comparação das principais métodos.
| Método | Efetividade | Complexidade de Implementação | Custo |
|---|---|---|---|
| Cabeçalhos Básicos | Baixa | Baixa | Grátis |
| Proxies de Data Center | Média | Média | Baixo |
| Proxies Residenciais | Alta | Média | Moderado |
| Navegadores Headless | Alta | Alta | Alto (Recursos) |
| Solvedores de CAPTCHA | Essencial | Baixa | Baixo |
Considerações Éticas e de Conformidade
Ao aprender como lidar com os bloqueios de web scraping, é vital enfatizar práticas éticas. A coleta de dados automatizada deve sempre ser realizada de forma que respeite os termos do site alvo e a saúde do servidor. Sempre verifique o arquivo robots.txt de um domínio para ver quais áreas estão restritas. Seguir essas melhores práticas de web scraping protege você legalmente e garante a longevidade de suas fontes de dados.
Para aqueles que buscam ferramentas mais avançadas, explorar os melhores ferramentas de extração de dados pode oferecer insights adicionais sobre a construção de sistemas resistentes.
Transição Natural para Soluções
À medida que a tecnologia de detecção de bots evolui, a complexidade de manter um scraper aumenta. Muitos desenvolvedores descobrem que por que a automação web continua falhando em CAPTCHA geralmente é devido à falta de uma estratégia dedicada. Utilizar um melhor solvedor de CAPTCHA permite que você se concentre na análise de dados em vez de corrigir constantemente scripts quebrados. Ao integrar esses serviços profissionais em sua pilha, você pode garantir altas taxas de sucesso mesmo em plataformas altamente protegidas.
Conclusão
Dominar como lidar com os bloqueios de web scraping exige uma abordagem de múltiplas camadas que combina precisão técnica com responsabilidade ética. Ao entender a lógica de detecção, implementar um gerenciamento robusto de proxies e utilizar serviços especializados de resolução, você pode construir pipelines de dados confiáveis. Lembre-se de que o objetivo não é apenas contornar uma barreira, mas criar um sistema sustentável que respeite o ecossistema digital enquanto fornece as insights em que seu negócio depende.
Perguntas Frequentes
1. Por que ainda estou sendo bloqueado mesmo com proxies?
Os bloqueios podem ocorrer devido ao fingerprinting de navegador ou cabeçalhos inconsistentes. Certifique-se de que seu User-Agent corresponda à localização percebida pelo proxy e que você não esteja revelando seu IP real através do WebRTC.
2. É legal contornar os bloqueios de web scraping?
A legalidade depende de sua jurisdição e do tipo de dados que você está coletando. Geralmente, o scraping de dados publicamente disponíveis é legal, mas você deve respeitar leis de direitos autorais e proteção de dados pessoais.
3. Quão frequentemente devo rotacionar meu User-Agent?
É melhor usar um novo User-Agent para cada nova sessão ou a cada algumas centenas de requisições, especialmente se você também estiver rotacionando seu IP.
4. Os navegadores headless podem evitar todos os bloqueios?
Embora úteis, navegadores headless como Puppeteer ou Playwright ainda podem ser detectados por propriedades específicas. Você deve usar "plugins de stealth" para mascarar seu caráter automatizado.
5. Qual é a forma mais econômica de lidar com CAPTCHAs?
Usar um serviço de resolução baseado em API, como o CapSolver, é geralmente mais econômico do que construir seus próprios modelos de ML ou usar trabalho manual, pois oferece alta velocidade e precisão a um custo baixo por tarefa.
Ver mais
The Other CAPTCHAMay 15, 2026
API de resolução de CAPTCHA rápida para Fluxos de Trabalho de Automação
API de resolução rápida de CAPTCHA para automação: compare fluxos de trabalho de tokens, desafios suportados, verificações de latência e integração responsável da CapSolver.

The Other CAPTCHAApr 03, 2026
Tempo de Resposta da API de Resolução de CAPTCHA Explicado: Fatores de Velocidade e Desempenho
Entenda o tempo de resposta da API de resolução de CAPTCHA, seu impacto na automação e os principais fatores que afetam a velocidade. Aprenda como otimizar o desempenho e aproveitar soluções eficientes como a CapSolver para resolução rápida de CAPTCHA.


