O que é o Puppeteer e como usá-lo em web scraping | Guia Completo 2026

Nikolai Smirnov
Software Development Lead

A raspagem de dados da web tornou-se uma habilidade essencial para qualquer pessoa envolvida na extração de dados da web. Seja você um desenvolvedor, cientista de dados ou entusiasta que busca coletar informações de sites, o Puppeteer é uma das ferramentas mais poderosas disponíveis. Este guia completo irá explorar o que é o Puppeteer e como usá-lo de forma eficaz na raspagem de dados da web.
Introdução ao Puppeteer
O Puppeteer é uma biblioteca Node que fornece uma API de alto nível para controlar o Chrome ou Chromium por meio do Protocolo DevTools. Ele é mantido pela equipe do Google Chrome e oferece aos desenvolvedores a capacidade de realizar uma variedade de tarefas de navegador, como gerar capturas de tela, raspagem de sites e, principalmente, raspagem de dados da web. O Puppeteer é muito popular por sua capacidade de navegação sem interface gráfica, o que significa que pode ser executado sem uma interface gráfica, sendo ideal para tarefas automatizadas.
Resgate seu código promocional do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código promocional CAPN ao recarregar sua conta do CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
.
Por que usar o Puppeteer para raspagem de dados da web?
Axios e Cheerio são boas opções para raspagem de dados da web em JavaScript, mas têm limitações: lidar com conteúdo dinâmico e contornar mecanismos de anti-raspagem.
Como um navegador sem interface gráfica, o Puppeteer se destaca na raspagem de conteúdo dinâmico. Ele carrega totalmente a página de destino, executa JavaScript e pode até disparar solicitações XHR para recuperar dados adicionais. Isso é algo que raspadores estáticos não conseguem, especialmente com aplicações de página única (SPAs), onde o HTML inicial carece de dados significativos.
O que mais o Puppeteer pode fazer? Ele pode renderizar imagens, capturar capturas de tela e tem extensão para resolver diversos tipos de captcha, como reCAPTCHA, captcha, captcha. Por exemplo, você pode programar seu script para navegar por uma página, capturar capturas de tela em intervalos específicos e analisar essas imagens para obter insights competitivos. As possibilidades são virtualmente ilimitadas!
Uso simples do Puppeteer
Nós completamos a primeira parte do ScrapingClub usando Selenium e Python. Agora, vamos usar o Puppeteer para completar a segunda parte
Antes de começar, certifique-se de que o Puppeteer está instalado em sua máquina local. Caso contrário, você pode instalá-lo usando os seguintes comandos:
bash
npm i puppeteer # Baixa o Chrome compatível durante a instalação.
npm i puppeteer-core # Alternativamente, instale como uma biblioteca, sem baixar o Chrome.Acessando uma página da web
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// Pausa por 5 segundos
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();O método puppeteer.launch é usado para iniciar uma nova instância do Puppeteer e pode aceitar um objeto de configuração com várias opções. A mais comum é headless, que especifica se o navegador deve ser executado em modo sem interface gráfica. Se você não especificar esse parâmetro, ele será definido como true. Outras opções comuns de configuração são as seguintes:
| Parâmetro | Tipo | Valor Padrão | Descrição | Exemplo |
|---|---|---|---|---|
args |
string[] |
Array de argumentos da linha de comando a serem passados ao iniciar o navegador | args: ['--no-sandbox', '--disable-setuid-sandbox'] |
|
debuggingPort |
number |
Especifica o número da porta de depuração a ser usada | debuggingPort: 8888 |
|
defaultViewport |
dict |
{width: 800, height: 600} |
Define o tamanho padrão da viewport | defaultViewport: {width: 1920, height: 1080} |
devtools |
boolean |
false |
Se deve abrir automaticamente o DevTools | devtools: true |
executablePath |
string |
Especifica o caminho para o executável do navegador | executablePath: '/caminho/para/o/chrome' |
|
headless |
boolean ou 'shell' |
true |
Se o navegador deve ser executado em modo sem interface gráfica | headless: false |
userDataDir |
string |
Especifica o caminho para o diretório de dados do usuário | userDataDir: '/caminho/para/dados/do/usuario' |
|
timeout |
number |
30000 |
Tempo limite em milissegundos para esperar o navegador iniciar | timeout: 60000 |
ignoreHTTPSErrors |
boolean |
false |
Se deve ignorar erros HTTPS | ignoreHTTPSErrors: true |
Definindo o tamanho da janela
Para obter a melhor experiência de navegação, precisamos ajustar dois parâmetros: o tamanho da viewport e o tamanho da janela do navegador. O código é o seguinte:
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({
headless: false,
args: ['--window-size=1920,1080']
});
const page = await browser.newPage();
await page.setViewport({width: 1920, height: 1080});
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// Pausa por 5 segundos
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();Extração de dados
No Puppeteer, existem vários métodos para extrair dados.
-
Usando o método
evaluateO método
evaluateexecuta código JavaScript no contexto do navegador para extrair os dados necessários.javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.evaluate(() => { const image = document.querySelector('.card-img-top').src; const title = document.querySelector('.card-title').innerText; const price = document.querySelector('.card-price').innerText; const description = document.querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('Nome do produto:', data.title); console.log('Preço do produto:', data.price); console.log('Imagem do produto:', data.image); console.log('Descrição do produto:', data.description); // Pausa por 5 segundos await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
Usando o método
$evalO método
$evalseleciona um único elemento e extrai seu conteúdo.javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const title = await page.$eval('.card-title', el => el.innerText); const price = await page.$eval('.card-price', el => el.innerText); const image = await page.$eval('.card-img-top', el => el.src); const description = await page.$eval('.card-description', el => el.innerText); console.log('Nome do produto:', title); console.log('Preço do produto:', price); console.log('Imagem do produto:', image); console.log('Descrição do produto:', description); // Pausa por 5 segundos await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
Usando o método
$$evalO método
$$evalseleciona vários elementos de uma vez e extrai seus conteúdos.javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.$$eval('.my-8.w-full.rounded.border > *', elements => { const image = elements[0].querySelector('img').src; const title = elements[1].querySelector('.card-title').innerText; const price = elements[1].querySelector('.card-price').innerText; const description = elements[1].querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('Nome do produto:', data.title); console.log('Preço do produto:', data.price); console.log('Imagem do produto:', data.image); console.log('Descrição do produto:', data.description); // Pausa por 5 segundos await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
Usando os métodos
page.$eevaluateO método
page.$seleciona elementos, e o métodoevaluateexecuta código JavaScript no contexto do navegador para extrair dados.javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const imageElement = await page.$('.card-img-top'); const titleElement = await page.$('.card-title'); const priceElement = await page.$('.card-price'); const descriptionElement = await page.$('.card-description'); const image = await page.evaluate(el => el.src, imageElement); const title = await page.evaluate(el => el.innerText, titleElement); const price = await page.evaluate(el => el.innerText, priceElement); const description = await page.evaluate(el => el.innerText, descriptionElement); console.log('Nome do produto:', title); console.log('Preço do produto:', price); console.log('Imagem do produto:', image); console.log('Descrição do produto:', description); // Pausa por 5 segundos await new Promise(r => setTimeout(r, 5000)); await browser.close(); })();
Bypassando proteções contra raspagem
Completar os exercícios do ScrapingClub é relativamente simples. No entanto, em cenários reais de raspagem de dados, obter dados nem sempre é tão fácil. Alguns sites utilizam tecnologias de anti-raspagem que podem detectar seu script como um robô e bloqueá-lo. A situação mais comum envolve desafios de CAPTCHA, como captcha, captcha, recaptcha, captcha e captcha.
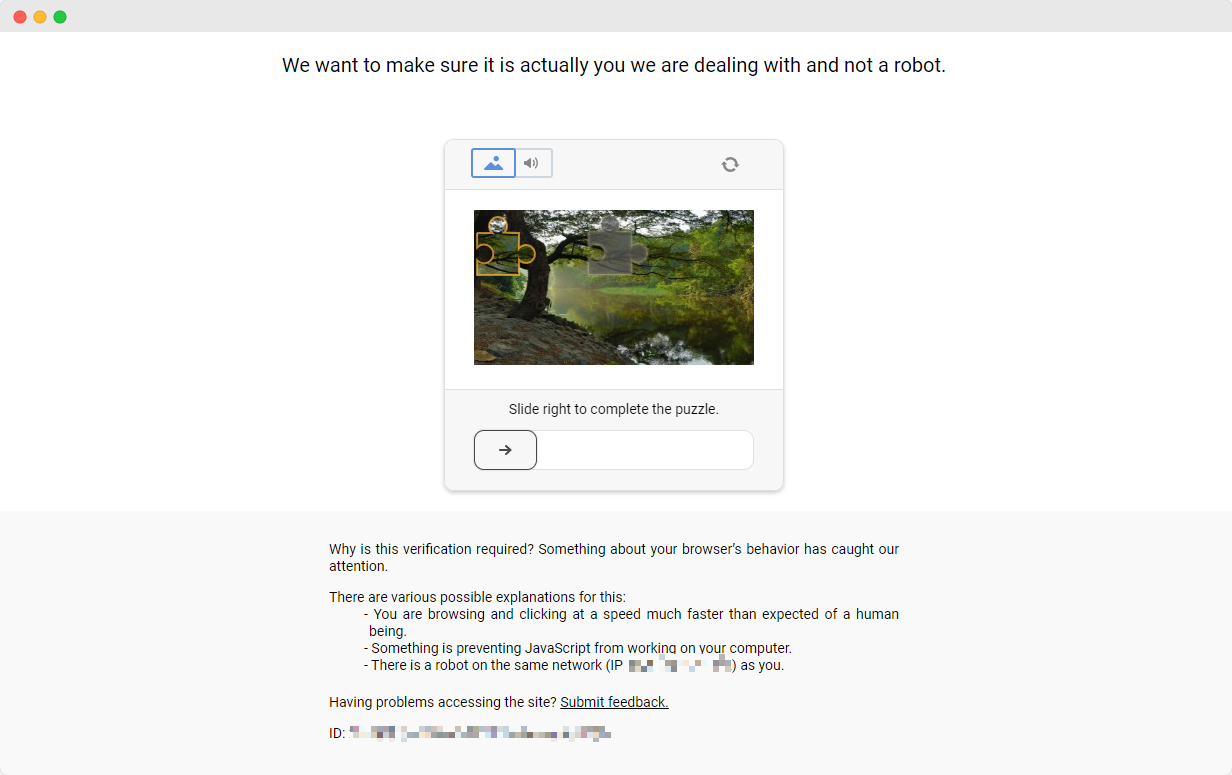
Para resolver esses desafios de CAPTCHA, é necessário ter experiência extensa em machine learning, engenharia reversa e medidas de contramedida de fingerprinting de navegador, o que pode exigir muito tempo.
Felizmente, você não precisa mais lidar com todo esse trabalho sozinho. CapSolver oferece uma solução abrangente que ajuda você a resolver todos os desafios facilmente. O CapSolver oferece uma extensão de navegador que permite resolver automaticamente desafios de CAPTCHA enquanto realiza raspagem de dados com o Puppeteer. Além disso, fornece um método de API para resolver CAPTCHAS e obter tokens. Tudo isso pode ser feito em poucos segundos. Confira este documento para descobrir como resolver os diversos correspondentes de CAPTCHA que você encontrou!
Conclusão
A raspagem de dados da web é uma habilidade valiosa para qualquer pessoa envolvida na extração de dados da web, e o Puppeteer, como uma ferramenta com uma API avançada e recursos poderosos, é uma das melhores escolhas para alcançar esse objetivo. Sua capacidade de lidar com conteúdo dinâmico e resolver mecanismos de anti-raspagem o destaca entre as ferramentas de raspagem.
Neste guia, exploramos o que é o Puppeteer, suas vantagens na raspagem de dados da web e como configurá-lo e usá-lo de forma eficaz. Mostramos com exemplos como acessar páginas da web, definir tamanhos de viewport e extrair dados usando vários métodos. Além disso, discutimos os desafios impostos pelas tecnologias de anti-raspagem e como o CapSolver fornece uma solução poderosa para o desafio de CAPTCHA.
Perguntas Frequentes
1. Para o que o Puppeteer é principalmente usado na raspagem de dados da web?
O Puppeteer é usado para controlar um navegador Chrome/Chromium real, permitindo que ele carregue JavaScript dinâmico, renderize páginas de aplicações de página única (SPAs), interaja com elementos e extraia dados que raspadores baseados em HTTP normais não conseguem acessar.
2. O Puppeteer pode lidar com desafios de CAPTCHA em sites?
O Puppeteer sozinho não pode contornar CAPTCHAS, mas quando combinado com a extensão de navegador do CapSolver ou com sua API, ele pode resolver automaticamente reCAPTCHA, hCaptcha, FunCAPTCHA e outros desafios de verificação durante tarefas de raspagem.
3. O Puppeteer precisa ser executado com uma janela de navegador visível?
Não. O Puppeteer suporta o modo sem interface gráfica, onde o Chrome é executado sem GUI. Este modo é mais rápido e ideal para automação. Você também pode executar no modo não sem interface gráfica para depuração ou monitoramento visual.
Ver mais
The Other CAPTCHAApr 03, 2026
Como lidar com os bloqueios de raspagem da web: métodos práticos que funcionam
Aprenda como lidar efetivamente com os bloqueios de scraping na web. Descubra métodos práticos, insights técnicos sobre detecção de bots e soluções confiáveis para extração de dados.

The Other CAPTCHAApr 03, 2026
Tempo de Resposta da API de Resolução de CAPTCHA Explicado: Fatores de Velocidade e Desempenho
Entenda o tempo de resposta da API de resolução de CAPTCHA, seu impacto na automação e os principais fatores que afetam a velocidade. Aprenda como otimizar o desempenho e aproveitar soluções eficientes como a CapSolver para resolução rápida de CAPTCHA.


