Web Scraping com Selenium e Python | Resolvendo Captcha Ao Fazer Web Scraping

Anh Tuan
Data Science Expert
Imagine que você pode obter facilmente todos os dados que precisa da Internet sem ter que navegar manualmente pelo site ou copiar e colar. Essa é a beleza da raspagem de web. Seja você um analista de dados, pesquisador de mercado ou desenvolvedor, a raspagem de web abre um novo mundo de coleta de dados automatizada.
Nessa era orientada por dados, a informação é poder. No entanto, extrair informações manualmente de centenas ou até milhares de páginas da web não é apenas trabalhoso, mas também propenso a erros. Felizmente, a raspagem de web oferece uma solução eficiente e precisa que permite automatizar o processo de extração de dados da Internet, aumentando assim significativamente a eficiência e a qualidade dos dados.
Índice
- O que é raspagem de web?
- Começando com o Selenium
- Como contornar proteções contra raspagem
- Conclusão
O que é raspagem de web?
A raspagem de web é uma técnica para extrair informações de páginas da web automaticamente escrevendo programas. Essa tecnologia tem uma ampla gama de aplicações em vários campos, incluindo análise de dados, pesquisa de mercado, inteligência competitiva, agregação de conteúdo e muito mais. Com a raspagem de web, você pode coletar e consolidar dados de um grande número de páginas da web em um curto período de tempo, em vez de depender de operações manuais.
O processo de raspagem de web geralmente inclui os seguintes passos:
- Enviar requisição HTTP: Enviar programaticamente uma requisição para o site alvo para obter o código HTML da página da web. Ferramentas comuns como a biblioteca requests do Python podem fazer isso facilmente.
- Analisar o conteúdo HTML: Após obter o código HTML da página, ele precisa ser analisado para extrair os dados necessários. Bibliotecas de análise HTML como BeautifulSoup ou lxml podem ser usadas para processar a estrutura HTML.
- Extração de dados: Com base na estrutura HTML analisada, localize e extraia conteúdo específico, como o título do artigo, informações de preço, links de imagens, etc. Métodos comuns incluem o uso de XPath ou seletores CSS.
- Armazenar dados: Salve os dados extraídos em um meio de armazenamento adequado, como um banco de dados, arquivo CSV ou arquivo JSON, para análise e processamento posterior.
E, ao usar ferramentas como o Selenium, é possível simular a operação do navegador do usuário, contornando algumas das mecanismos anti-robô, permitindo assim completar a tarefa de raspagem de web de forma mais eficiente.
Resgatar seu código de bônus do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código de bônus CAPN ao recarregar sua conta do CapSolver para obter um bônus extra de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
.
Começando com o Selenium
Vamos usar o ScrapingClub como exemplo e completar o primeiro exercício com o selenium.
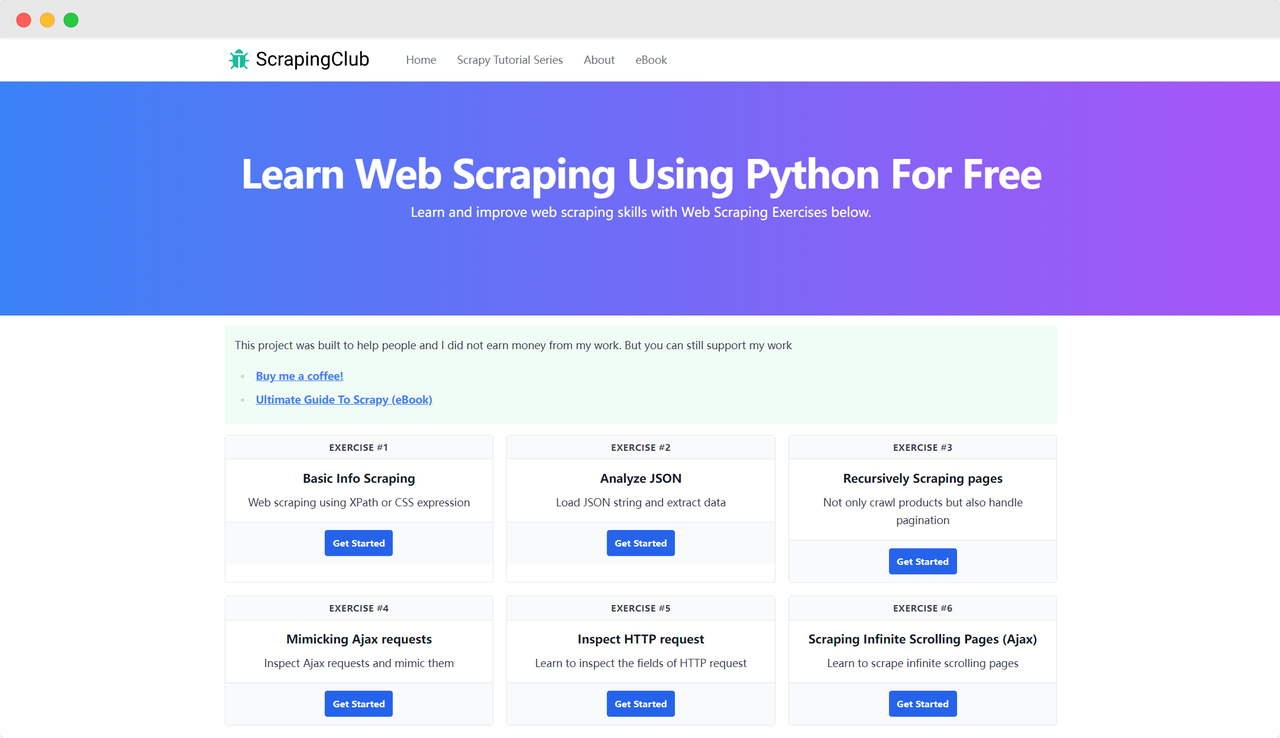
Preparação
Primeiro, você precisa garantir que o Python esteja instalado na sua máquina local. Você pode verificar a versão do Python digitando o seguinte comando no seu terminal:
bash
python --versionCertifique-se de que a versão do Python seja maior que 3. Se não estiver instalado ou a versão for muito baixa, baixe a versão mais recente no site oficial do Python. Em seguida, você precisa instalar a biblioteca selenium usando o seguinte comando:
bash
pip install seleniumImportar bibliotecas
python
from selenium import webdriverAcessando uma página
Usar o Selenium para controlar o Google Chrome para acessar uma página não é complicado. Após inicializar o objeto Chrome Options, você pode usar o método get() para acessar a página alvo:
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()Parâmetros de inicialização
Os parâmetros do Chrome Options podem adicionar muitos parâmetros de inicialização que ajudam a melhorar a eficiência da coleta de dados. Você pode visualizar a lista completa de parâmetros no site oficial: Lista de switches da linha de comando do Chromium. Alguns parâmetros comuns estão listados na tabela abaixo:
| Parâmetro | Propósito |
|---|---|
| --user-agent="" | Definir o User-Agent no cabeçalho da requisição |
| --window-size=xxx,xxx | Definir a resolução do navegador |
| --start-maximized | Executar com resolução maximizada |
| --headless | Executar no modo headless |
| --incognito | Executar no modo anônimo |
| --disable-gpu | Desativar a aceleração de hardware GPU |
Exemplo: Executando no modo headless
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()Localizando elementos da página
Um passo necessário na coleta de dados é encontrar os elementos HTML correspondentes no DOM. O Selenium fornece dois métodos principais para localizar elementos na página:
find_element: Encontra um único elemento que atende aos critérios.find_elements: Encontra todos os elementos que atendem aos critérios.
Ambos os métodos suportam oito maneiras diferentes de localizar elementos HTML:
| Método | Significado | Exemplo HTML | Exemplo do Selenium |
|---|---|---|---|
| By.ID | Localizar pelo ID do elemento | <form id="loginForm">...</form> |
driver.find_element(By.ID, 'loginForm') |
| By.NAME | Localizar pelo nome do elemento | <input name="username" type="text" /> |
driver.find_element(By.NAME, 'username') |
| By.XPATH | Localizar pelo XPath | <p><code>Meu código</code></p> |
driver.find_element(By.XPATH, "//p/code") |
| By.LINK_TEXT | Localizar hiperlink pelo texto | <a href="continue.html">Continuar</a> |
driver.find_element(By.LINK_TEXT, 'Continuar') |
| By.PARTIAL_LINK_TEXT | Localizar hiperlink pelo texto parcial | <a href="continue.html">Continuar</a> |
driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti') |
| By.TAG_NAME | Localizar pelo nome da tag | <h1>Bem-vindo</h1> |
driver.find_element(By.TAG_NAME, 'h1') |
| By.CLASS_NAME | Localizar pelo nome da classe | <p class="content">Bem-vindo</p> |
driver.find_element(By.CLASS_NAME, 'content') |
| By.CSS_SELECTOR | Localizar pelo seletor CSS | <p class="content">Bem-vindo</p> |
driver.find_element(By.CSS_SELECTOR, 'p.content') |
Voltemos à página do ScrapingClub e escreva o seguinte código para encontrar o elemento do botão "Get Started" para o primeiro exercício:
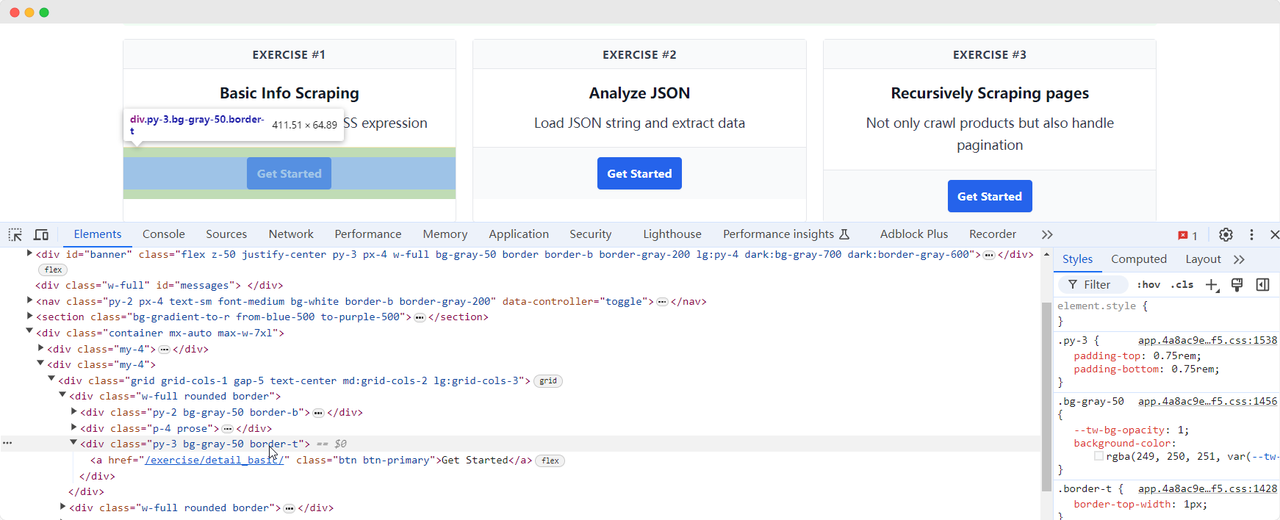
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
time.sleep(5)
driver.quit()Interação com elementos
Uma vez que encontramos o elemento do botão "Get Started", precisamos clicar no botão para entrar na próxima página. Isso envolve interação com elementos. O Selenium fornece vários métodos para simular ações:
click(): Clique no elemento;clear(): Limpe o conteúdo do elemento;send_keys(*value: str): Simule a entrada do teclado;submit(): Submeta um formulário;screenshot(filename): Salve uma captura de tela da página.
Para mais interações, consulte a documentação oficial: API do WebDriver. Vamos continuar a melhorar o código do exercício ScrapingClub adicionando a interação de clique:
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
time.sleep(5)
driver.quit()Extração de dados
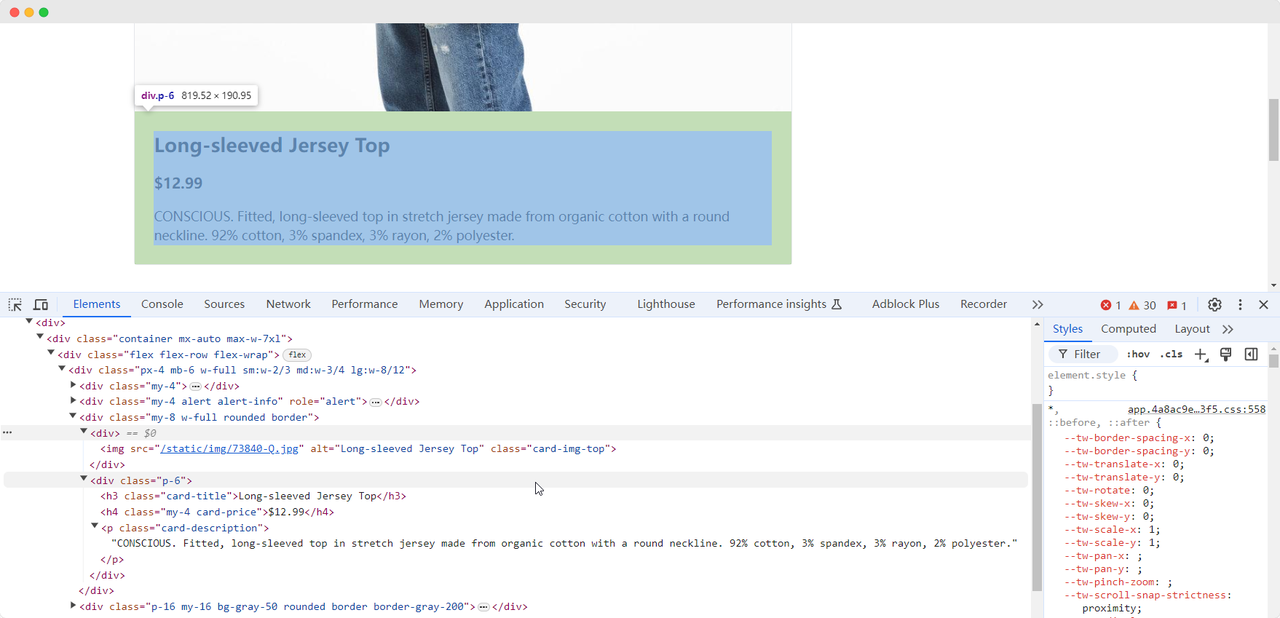
Quando chegamos à primeira página do exercício, precisamos coletar informações sobre a imagem do produto, nome, preço e descrição. Podemos usar diferentes métodos para encontrar esses elementos e extraí-los:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Nome do produto: {product_name}')
print(f'Imagem do produto: {product_image}')
print(f'Preço do produto: {product_price}')
print(f'Descrição do produto: {product_description}')
driver.quit()O código imprimirá o seguinte conteúdo:
Nome do produto: Long-sleeved Jersey Top
Imagem do produto: https://scrapingclub.com/static/img/73840-Q.jpg
Preço do produto: $12.99
Descrição do produto: CONSCIOUS. Camiseta justa com mangas longas feita de jersey orgânico com gola redonda. 92% algodão, 3% elastano, 3% rayon, 2% poliéster.Aguardando o carregamento dos elementos
Às vezes, devido a problemas de rede ou outros motivos, os elementos podem não estar carregados quando o Selenium termina de executar, o que pode causar falhas na coleta de dados. Para resolver esse problema, podemos configurar para esperar até que um determinado elemento esteja totalmente carregado antes de prosseguir com a extração de dados. Aqui está um exemplo de código:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
# aguardando o carregamento completo dos elementos de imagem do produto
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.card-img-top')))
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Nome do produto: {product_name}')
print(f'Imagem do produto: {product_image}')
print(f'Preço do produto: {product_price}')
print(f'Descrição do produto: {product_description}')
driver.quit()Como contornar proteções contra raspagem
O exercício do ScrapingClub é fácil de ser concluído. No entanto, em cenários reais de coleta de dados, obter dados não é tão fácil, pois alguns sites utilizam técnicas de proteção contra raspagem que podem detectar seu script como um robô e bloquear a coleta. A situação mais comum é o desafio de captcha
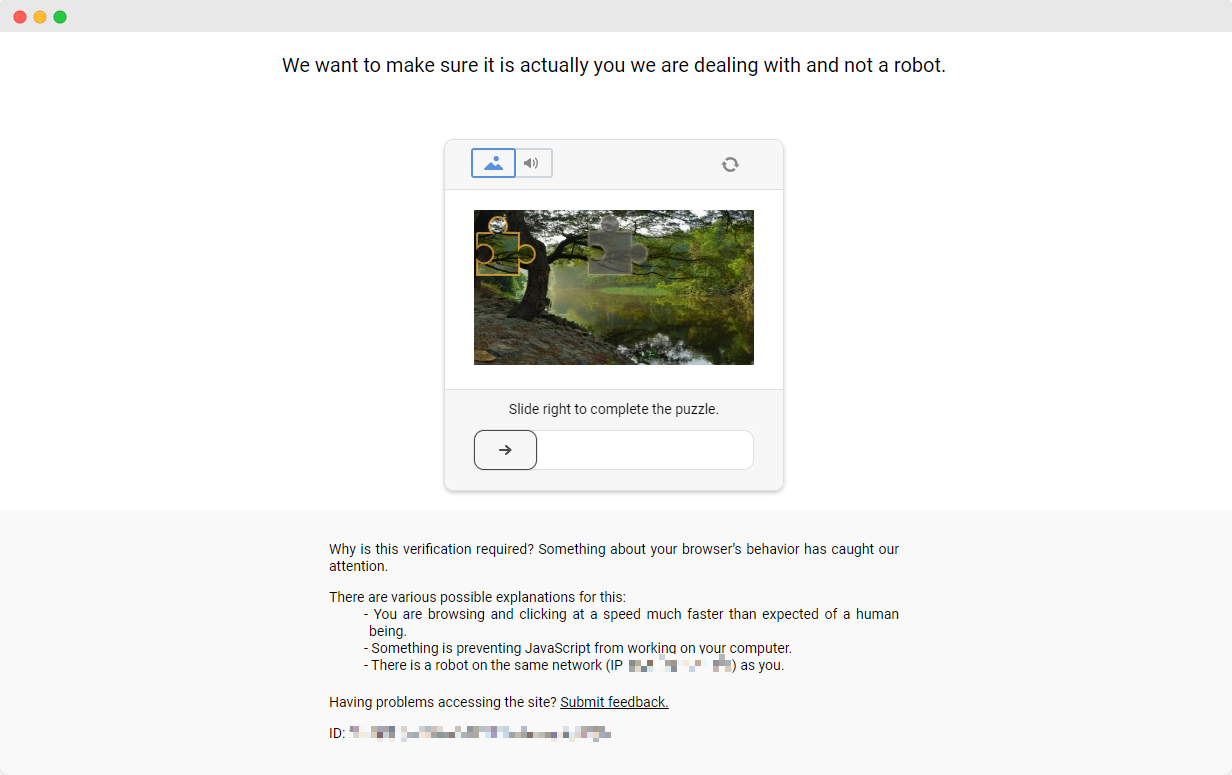
Resolver esses desafios de captcha requer experiência extensa em aprendizado de máquina, engenharia reversa e medidas de contramedida contra impressão digital do navegador, o que pode levar muito tempo. Felizmente, agora você não precisa fazer todo esse trabalho sozinho. CapSolver fornece uma solução completa para ajudá-lo a contornar facilmente todos os desafios. CapSolver oferece extensões do navegador que podem resolver automaticamente os desafios de captcha enquanto usa o Selenium para coletar dados. Além disso, eles fornecem métodos de API para resolver captchas e obter tokens, tudo isso pode ser feito em alguns segundos. Consulte a Documentação do CapSolver para mais informações.
Conclusão
Da extração de detalhes de produtos à navegação por medidas complexas de proteção contra raspagem, a raspagem de web com o Selenium abre portas para um vasto reino de coleta de dados automatizada. À medida que navegamos pelo constante cenário em evolução da web, ferramentas como CapSolver pavimentam o caminho para uma extração de dados mais suave, tornando desafios antes formidáveis coisa do passado. Então, seja você um entusiasta de dados ou um desenvolvedor experiente, utilizar essas tecnologias não apenas aumenta a eficiência, mas também abre um mundo onde insights baseados em dados estão a apenas um escaneio de distância.
Perguntas Frequentes
1. Para que serve a raspagem de web?
O web scraping é usado para extrair informações automaticamente de páginas da web. Ele permite que desenvolvedores, analistas e empresas coletem dados de produtos, preços, artigos, imagens, avaliações e outras informações online em massa sem cópia manual, aumentando significativamente a eficiência e a precisão dos dados.
2. Por que usar o Selenium para web scraping em vez do requests ou do BeautifulSoup?
O requests e o BeautifulSoup funcionam bem para páginas web estáticas, mas muitos sites modernos usam JavaScript para carregar conteúdo. O Selenium simula um navegador real, permitindo que você raspe páginas dinâmicas, clique em botões, role, interaja com elementos e burlar medidas simples de anti-raspagem, tornando-o ideal para cenários complexos.
3. O Selenium pode raspar sites que exigem login ou ações do usuário?
Sim. O Selenium pode realizar interações como clicar em botões, digitar texto, navegar por páginas e gerenciar cookies ou sessões, tornando-o adequado para raspar páginas protegidas por formulários de login ou fluxos de trabalho do usuário.
4. Como lidar com CAPTCHAs ao raspar dados?
CAPTCHAs são um mecanismo comum contra bots que podem interromper os scripts do Selenium. Em vez de resolvê-los manualmente, você pode integrar soluções como CapSolver, que oferece resolução automática de CAPTCHA via API ou extensão de navegador para manter o processo de raspagem sem interrupções.
Ver mais
The Other CAPTCHAApr 03, 2026
Como lidar com os bloqueios de raspagem da web: métodos práticos que funcionam
Aprenda como lidar efetivamente com os bloqueios de scraping na web. Descubra métodos práticos, insights técnicos sobre detecção de bots e soluções confiáveis para extração de dados.

The Other CAPTCHAApr 03, 2026
Tempo de Resposta da API de Resolução de CAPTCHA Explicado: Fatores de Velocidade e Desempenho
Entenda o tempo de resposta da API de resolução de CAPTCHA, seu impacto na automação e os principais fatores que afetam a velocidade. Aprenda como otimizar o desempenho e aproveitar soluções eficientes como a CapSolver para resolução rápida de CAPTCHA.

