C# é uma linguagem de programação versátil amplamente utilizada em projetos e aplicações de nível corporativo. Com suas raízes na família C, ela oferece eficiência e poder, tornando-se uma adição valiosa para qualquer kit de ferramentas de desenvolvedor.
Gracias ao seu uso generalizado, o C# oferece uma diversidade de ferramentas que empoderam os desenvolvedores a resolver soluções sofisticadas, e a raspagem de web não é exceção.
Neste tutorial, vamos guiá-lo através da criação de um raspador de web simples usando C# e suas bibliotecas amigáveis ao usuário. Além disso, revelaremos um truque útil para ajudá-lo a evitar ser bloqueado com apenas uma linha de código. Está pronto? Vamos lá!
Índice
Introdução à raspagem de web
Por que escolher C# em vez de C para raspagem de web?
Configurando seu ambiente
Pré-requisitos
Instalando bibliotecas
Criando um projeto de raspagem de web em C# no Visual Studio
Raspagem de web básica com C#
Fazendo solicitações HTTP
Analisando conteúdo HTML
Análise avançada de HTML
Como lidar com os dados raspados
Lidando com CAPTCHAs na raspagem de web
Integrando solucionadores de CAPTCHA
Código de exemplo para CapSolver
Conclusão
1. Introdução à raspagem de web
A raspagem de web é o processo de extrair informações de sites automaticamente. Isso pode ser feito para diversos propósitos, incluindo análise de dados, pesquisa de mercado e inteligência competitiva. No entanto, muitos sites implementam mecanismos para detectar e bloquear tentativas de raspagem automatizadas, tornando essencial usar técnicas sofisticadas para evitar ser bloqueado.
Por que escolher C# em vez de C para raspagem de web?
A raspagem de web frequentemente envolve interagir com elementos da web, gerenciar solicitações HTTP e lidar com extração e análise de dados. Embora o C seja uma linguagem poderosa e eficiente, ele não possui as bibliotecas integradas e os recursos modernos que tornam a raspagem de web mais fácil e eficiente. Aqui estão alguns motivos pelos quais o C# é uma melhor escolha para raspagem de web:
Bibliotecas ricas: O C# possui bibliotecas extensas como HtmlAgilityPack para análise de HTML e Selenium para automação de navegadores, simplificando o processo de raspagem.
Programação assíncrona: As palavras-chave async e await do C# permitem operações assíncronas eficientes, essenciais para lidar com múltiplas solicitações da web simultaneamente.
Facilidade de uso: A sintaxe do C# é mais moderna e amigável ao usuário em comparação com o C, tornando o processo de desenvolvimento mais rápido e menos propenso a erros.
Integração: O C# se integra de forma suave com o framework .NET, fornecendo ferramentas e serviços poderosos para construir aplicações robustas.
Enfrentando falhas repetidas ao resolver o irritante captcha?
Descubra a resolução automática de captcha com a tecnologia de desbloqueio web automatizada da Capsolver!
Reclame seu Código de Bônus para soluções de captcha top;
: WEBS. Após resgatá-lo, você receberá um bônus adicional de 5% após cada recarga, ilimitado
2. Configurando seu ambiente
Antes de começarmos a raspar, precisamos configurar nosso ambiente de desenvolvimento. Aqui está como você pode fazer isso:
Pré-requisitos
Visual Studio: a versão Community gratuita do Visual Studio 2022 será suficiente.
.NET 6+: qualquer versão LTS maior ou igual a 6 funcionará.
biblioteca HtmlAgilityPack para análise de HTML
biblioteca RestSharp para fazer solicitações HTTP
Criando um projeto de raspagem de web em C# no Visual Studio
Configurando um projeto no Visual Studio
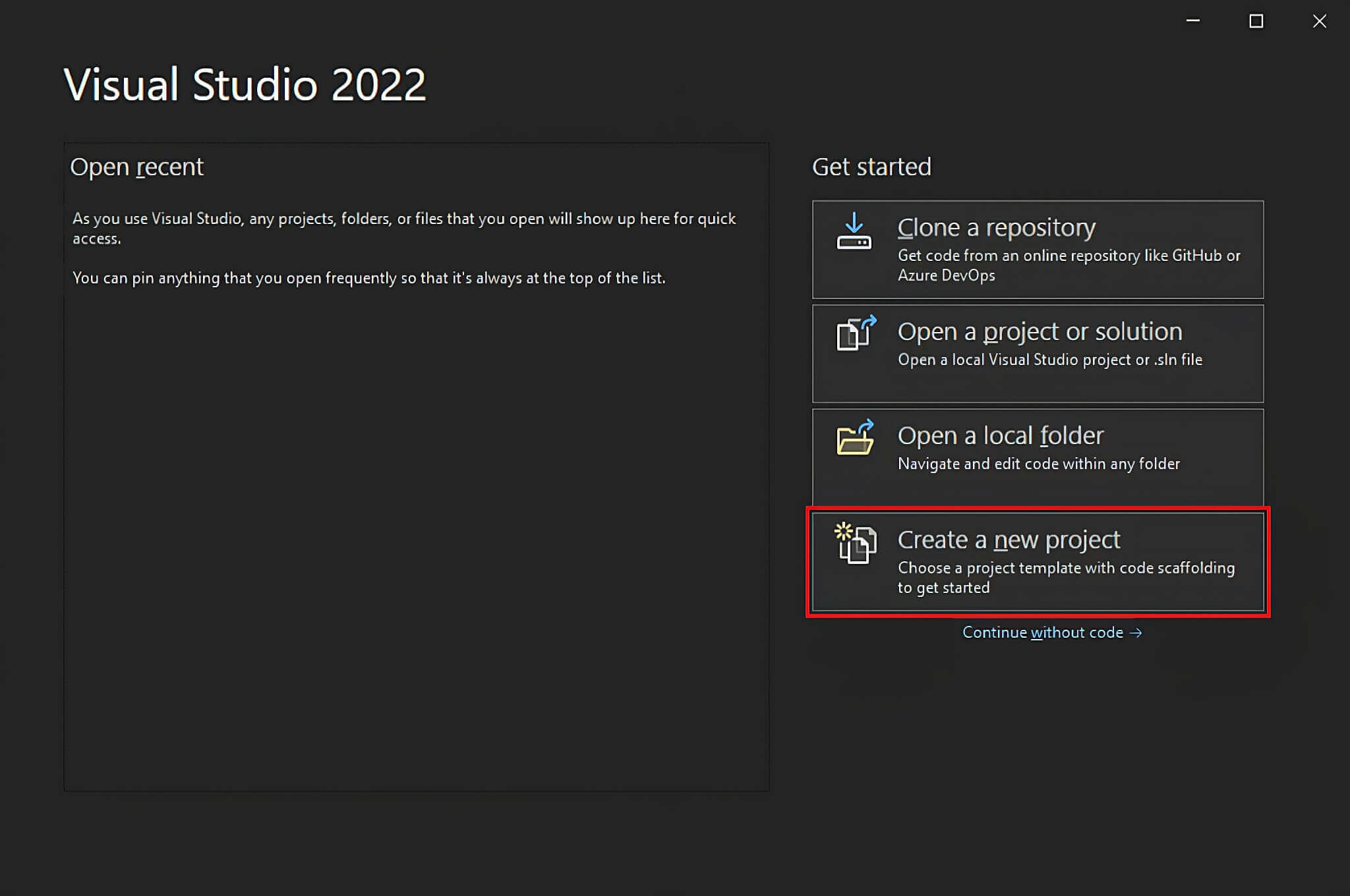
Abra o Visual Studio e clique na opção "Criar um novo projeto".
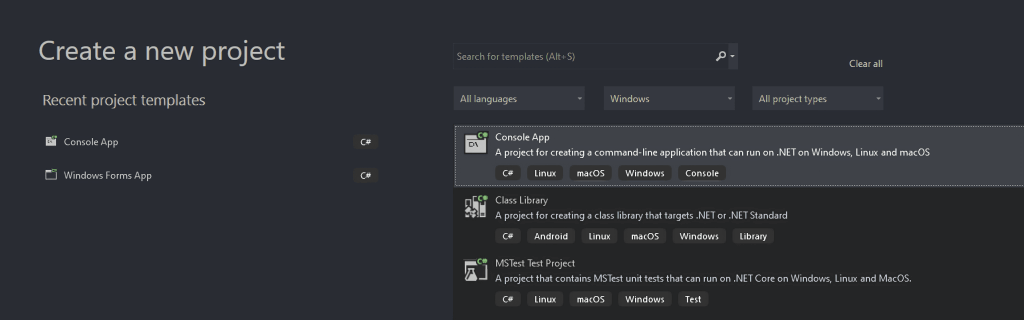
Na janela "Criar um novo projeto", selecione a opção "C#" na lista suspensa. Após especificar a linguagem de programação, selecione o modelo "Aplicativo de Console" e clique em "Próximo".
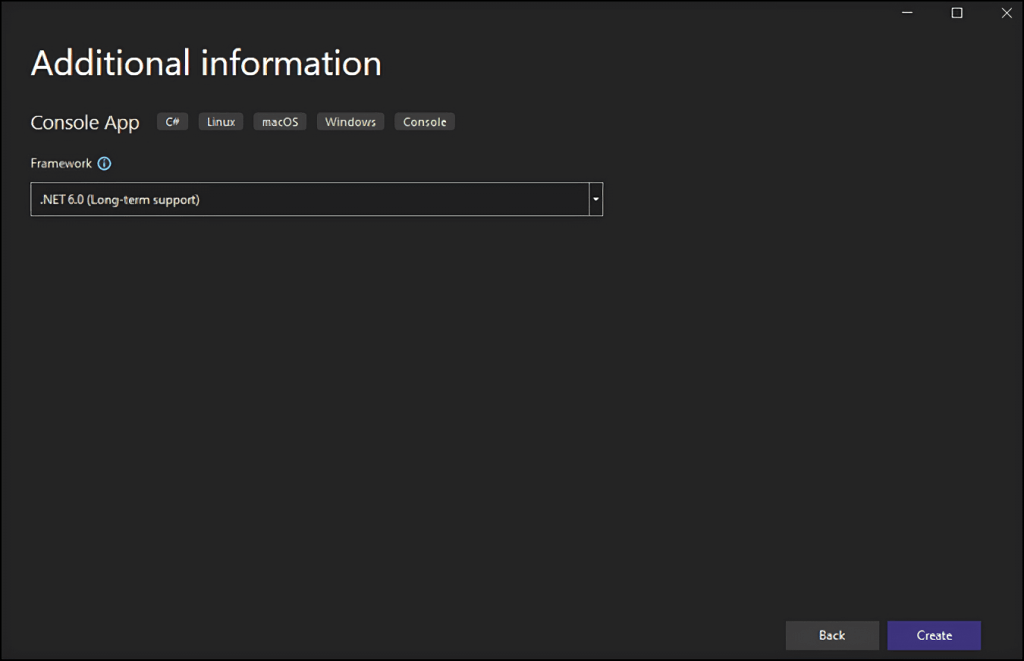
Dê um nome ao seu projeto StaticWebScraping, clique em "Selecionar" e escolha a versão do .NET. Se você instalou o .NET 6.0, o Visual Studio já o selecionará para você.
Clique no botão "Criar" para inicializar seu projeto de raspagem de web em C#. O Visual Studio inicializará uma pasta StaticWebScraping contendo um arquivo App.cs. Este arquivo armazenará a lógica de raspagem de web em C#:
csharpCopy
namespace WebScraping {
public class Program {
public static void Main() {
// lógica de raspagem...
}
}
}
Agora é hora de entender como criar um raspador de web em C#!
3. Raspagem de web básica com C#
Nesta seção, criaremos um aplicativo C# que faz solicitações HTTP a um site, recupera o conteúdo HTML e o analisa para extrair informações.
Fazendo solicitações HTTP
Primeiro, vamos criar um aplicativo C# básico que faz solicitações HTTP a um site e recupera o conteúdo HTML.
csharpCopy
using System;
using RestSharp;
class Program
{
static void Main()
{
// Crie uma nova instância do RestClient com a URL de destino
var client = new RestClient("https://www.example.com");
// Crie uma nova instância do RestRequest com o método GET
var request = new RestRequest(Method.GET);
// Execute a solicitação e obtenha a resposta
IRestResponse response = client.Execute(request);
// Verifique se a solicitação foi bem-sucedida
if (response.IsSuccessful)
{
// Imprima o conteúdo HTML da resposta
Console.WriteLine(response.Content);
}
else
{
Console.WriteLine("Falha ao recuperar conteúdo");
}
}
}
Analisando conteúdo HTML
Em seguida, usaremos o HtmlAgilityPack para analisar o conteúdo HTML e extrair as informações que precisamos.
csharpCopy
using HtmlAgilityPack;
using System;
using RestSharp;
class Program
{
static void Main()
{
// Crie uma nova instância do RestClient com a URL de destino
var client = new RestClient("https://www.example.com");
// Crie uma nova instância do RestRequest com o método GET
var request = new RestRequest(Method.GET);
// Execute a solicitação e obtenha a resposta
IRestResponse response = client.Execute(request);
// Verifique se a solicitação foi bem-sucedida
if (response.IsSuccessful)
{
// Carregue o conteúdo HTML no HtmlDocument
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(response.Content);
// Selecione os nós que correspondem à consulta XPath especificada
var nodes = htmlDoc.DocumentNode.SelectNodes("//h1");
// Percorra os nós selecionados e imprima seu texto interno
foreach (var node in nodes)
{
Console.WriteLine(node.InnerText);
}
}
else
{
Console.WriteLine("Falha ao recuperar conteúdo");
}
}
}
Análise avançada de HTML
Vamos levar isso um passo adiante, raspando dados mais complexos de uma página de exemplo. Suponha que queremos raspar uma lista de artigos com títulos e links de uma página de blog.
csharpCopy
using HtmlAgilityPack;
using System;
using RestSharp;
class Program
{
static void Main()
{
// Crie uma nova instância do RestClient com a URL de destino
var client = new RestClient("https://www.example.com/blog");
// Crie uma nova instância do RestRequest com o método GET
var request = new RestRequest(Method.GET);
// Execute a solicitação e obtenha a resposta
IRestResponse response = client.Execute(request);
// Verifique se a solicitação foi bem-sucedida
if (response.IsSuccessful)
{
// Carregue o conteúdo HTML no HtmlDocument
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(response.Content);
// Selecione os nós que correspondem à consulta XPath especificada
var nodes = htmlDoc.DocumentNode.SelectNodes("//div[@class='post']");
// Percorra os nós selecionados e extraia títulos e links
foreach (var node in nodes)
{
var titleNode = node.SelectSingleNode(".//h2/a");
var title = titleNode.InnerText;
var link = titleNode.Attributes["href"].Value;
Console.WriteLine("Título: " + title);
Console.WriteLine("Link: " + link);
Console.WriteLine();
}
}
else
{
Console.WriteLine("Falha ao recuperar conteúdo");
}
}
}
Neste exemplo, raspamos uma página de blog, selecionando o título e o link de cada artigo. A consulta XPath //div[@class='post'] é usada para localizar os artigos individuais.
4. Como lidar com os dados raspados
Armazene-os em um banco de dados para consulta fácil sempre que necessário.
Converta-os para formato JSON e use-os para chamar várias APIs.
Transforme-os em formatos legíveis por humanos como CSV, que podem ser abertos com o Excel.
Esses são apenas alguns exemplos. O ponto principal é que, uma vez que você tenha os dados raspados no seu código, pode utilizá-los da forma que achar conveniente. Normalmente, os dados raspados são convertidos para um formato mais útil para as equipes de marketing, análise de dados ou vendas.
No entanto, tenha em mente que a raspagem de web tem seus próprios desafios.
5. Lidando com CAPTCHAs na raspagem de web
Um dos maiores desafios na raspagem de web é lidar com CAPTCHAs, que são projetados para diferenciar usuários humanos de robôs. Se você encontrar um CAPTCHA, seu script de raspagem precisará resolvê-lo para continuar. Especialmente se quiser escalar sua raspagem de web, CapSolver existe para ajudá-lo com sua alta precisão e resolução rápida de qualquer CAPTCHA que possa encontrar.
Integrar solucionadores de CAPTCHA
Existem vários serviços de resolução de CAPTCHA disponíveis que podem ser integrados ao seu script de raspagem. Aqui, usaremos o serviço CapSolver. Primeiro, você precisa se cadastrar no CapSolver e obter sua chave de API.
Passo 1: Registre-se no CapSolver
Antes de estar pronto para usar os serviços do CapSolver, você precisa ir ao painel do usuário e registrar sua conta.
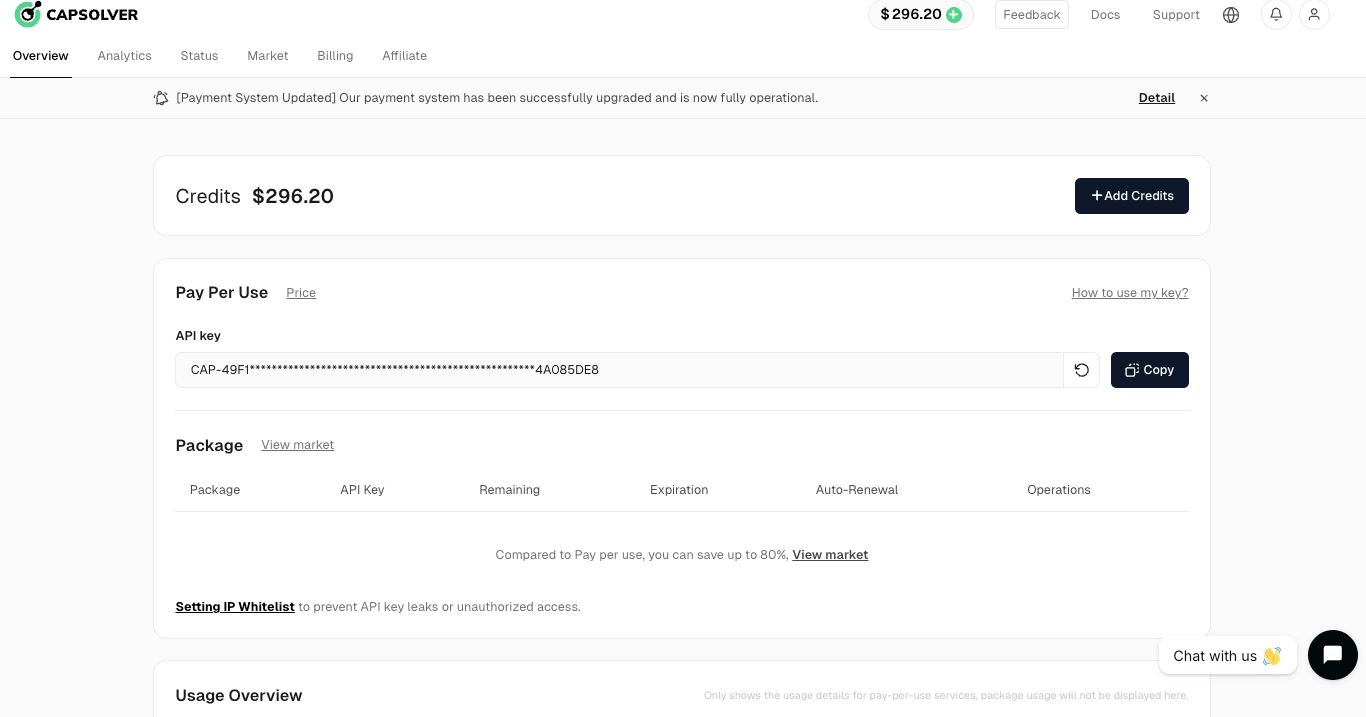
Passo 2: Obtenha sua chave de API
Após se registrar, você pode obter sua chave de API no painel da página inicial
Código de exemplo para CapSolver
Usar o CapSolver em seu projeto de raspagem de web ou automação é simples. Aqui está um exemplo rápido em Python para demonstrar como você pode integrar o CapSolver ao seu fluxo de trabalho:
pythonCopy
# pip install requests
import requests
import time
# TODO: defina sua configuração
api_key = "SUA_CHAVE_DE_API" # sua chave de API do capsolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # chave do site do seu site alvo
site_url = "" # URL da página do seu site alvo
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("Falha ao criar tarefa:", res.text)
return
print(f"Obtivemos taskId: {task_id} / Obtendo resultado...")
while True:
time.sleep(3) # atraso
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("Falha ao resolver! resposta:", res.text)
return
token = capsolver()
print(token)
Neste exemplo, a função capsolver envia uma solicitação à API do CapSolver com os parâmetros necessários e retorna a solução do CAPTCHA. Esta integração simples pode economizar incontáveis horas e esforço na resolução manual de CAPTCHAs durante tarefas de raspagem de web e automação.
6. Conclusão
A raspagem de web em C# empodera os desenvolvedores com um framework robusto para extrair dados de sites de forma eficiente. Ao utilizar bibliotecas como HtmlAgilityPack e RestSharp, juntamente com serviços de resolução de CAPTCHA como CapSolver, os desenvolvedores podem navegar por páginas da web, analisar conteúdo HTML e lidar com desafios de forma suave. Essa capacidade não apenas simplifica os processos de coleta de dados, mas também garante conformidade com práticas éticas de raspagem, aumentando a confiabilidade e a escalabilidade dos projetos de raspagem de web em aplicações diversas.