Como fazer scraping na web com Puppeteer e NodeJS | Tutorial do Puppeteer

Adélia Cruz
Neural Network Developer

O web scraping é uma técnica poderosa usada para extrair dados de sites. Neste tutorial, exploraremos como realizar web scraping usando Puppeteer e Node.js, duas tecnologias populares no ecossistema de desenvolvimento web. O Puppeteer é uma biblioteca Node.js que fornece uma API de alto nível para controlar navegadores Chrome ou Chromium headless. Ele permite automatizar ações do navegador, navegar por páginas da web e extrair os dados desejados. Ao combinar o Puppeteer com a flexibilidade do Node.js, podemos construir soluções robustas e eficientes para web scraping. Vamos mergulhar nos passos envolvidos na raspagem de sites usando o Puppeteer.
O que é o Puppeteer?
Puppeteer é um framework de ponta que permite aos testadores realizar testes de navegador headless com o Google Chrome. Com testes do Puppeteer, os testadores podem executar comandos JavaScript para interagir com páginas da web, incluindo ações como clicar em links, preencher formulários e enviar botões.
Desenvolvido pelo Google, o Puppeteer é uma biblioteca Node.js que permite o controle sem problemas do Chrome headless por meio do Protocolo DevTools. Ele fornece uma série de APIs de alto nível que facilitam testes automatizados, desenvolvimento de recursos de site, depuração, inspeção de elementos e análise de desempenho.
Com o Puppeteer, você pode usar (navegador headless) Chromium ou Chrome para abrir sites, preencher formulários, clicar em botões, extrair dados e realizar geralmente qualquer ação que uma pessoa poderia fazer ao usar um computador. Isso torna o Puppeteer uma ferramenta realmente poderosa para web scraping, mas também para automatizar fluxos de trabalho complexos na web. Ter um entendimento claro do Puppeteer e suas capacidades é valioso tanto para testadores quanto para desenvolvedores no cenário atual de desenvolvimento web.
Quais são as vantagens de usar o Puppeteer para web scraping?
Axios e Cheerio são ótimas opções para raspagem com JavaScript. No entanto, isso apresenta dois problemas: rastrear conteúdo dinâmico e software anti- raspagem. Como o Puppeteer é um navegador headless, ele não tem problema em raspar conteúdo dinâmico.
Também o Puppeteer oferece uma série de vantagens significativas para web scraping:
-
Automação de Navegador Headless: Com o Puppeteer, você pode controlar um navegador Chrome headless programaticamente, permitindo a automação de ações do navegador como clicar, rolar, preencher formulários e extrair dados sem uma janela de navegador visível.
-
Funcionalidade Completa do Chrome e Manipulação do DOM: O Puppeteer fornece acesso à funcionalidade completa do Chrome, tornando-o adequado para raspagem de sites modernos com conteúdo JavaScript intenso. Você pode interagir facilmente com elementos da página, modificar atributos e realizar ações como clicar em botões ou enviar formulários.
-
Interações Simuladas do Usuário e Captura de Eventos: O Puppeteer permite que você simule interações do usuário e capture requisições e respostas de rede. Isso permite raspagem de páginas que exigem entrada do usuário ou carregam conteúdo dinamicamente por meio de requisições AJAX ou WebSocket.
-
Capacidades de Desempenho e Depuração: O motor Chrome otimizado do Puppeteer garante raspagem eficiente, e sua integração com DevTools oferece capacidades robustas de depuração e testes. Você pode depurar páginas da web, registrar mensagens do console, rastrear atividade de rede e analisar métricas de desempenho.
Nos próximos guias, vou explorar o processo de web scraping usando o Puppeteer e o Node.js, junto com a integração de uma solução inovadora de resolução de CAPTCHA, CapSolver, para superar um dos maiores desafios encontrados durante o web scraping.
Código Bônus
Um código bônus para soluções top de CAPTCHA; CapSolver : WEBS. Após resgatá-lo, você receberá um bônus adicional de 5% após cada recarga, ilimitado.

Como Resolver CAPTCHA no Puppeteer usando o CapSolver durante o Web Scraping
O objetivo será resolver o CAPTCHA localizado em recaptcha-demo.appspot.com usando o CapSolver.
Durante o tutorial, seguiremos os seguintes passos para resolver o CAPTCHA acima:
- Instalar as dependências necessárias.
- Encontrar a chave do site do Formulário de CAPTCHA.
- Configurar o CapSolver.
- Resolver o CAPTCHA.
Instalar Dependências Necessárias
Para começar, precisamos instalar as seguintes dependências para este tutorial:
- capsolver-python: O SDK oficial do Python para integração fácil com a API do CapSolver.
- pyppeteer: pyppeteer é uma versão do Puppeteer para Python.
Instale essas dependências executando o seguinte comando:
python -m pip install pyppeteer capsolver-pythonAgora, crie um arquivo chamado main.py onde escreveremos o código Python para resolver CAPTCHAs.
bash
touch main.pyObter a Chave do Site do Formulário de CAPTCHA
A Chave do Site é um identificador único fornecido pelo Google que identifica unicamente cada CAPTCHA.
Para resolver o CAPTCHA, é necessário enviar a Chave do Site para o CapSolver.
Vamos encontrar a Chave do Site do Formulário de CAPTCHA seguindo os seguintes passos:
- Acesse o Formulário de CAPTCHA.
- Abra as Ferramentas do Chrome Dev Tools pressionando
Ctrl/Cmd+Shift+I. - Vá para a guia
Elementse procure pordata-sitekey. Copie o valor do atributo.
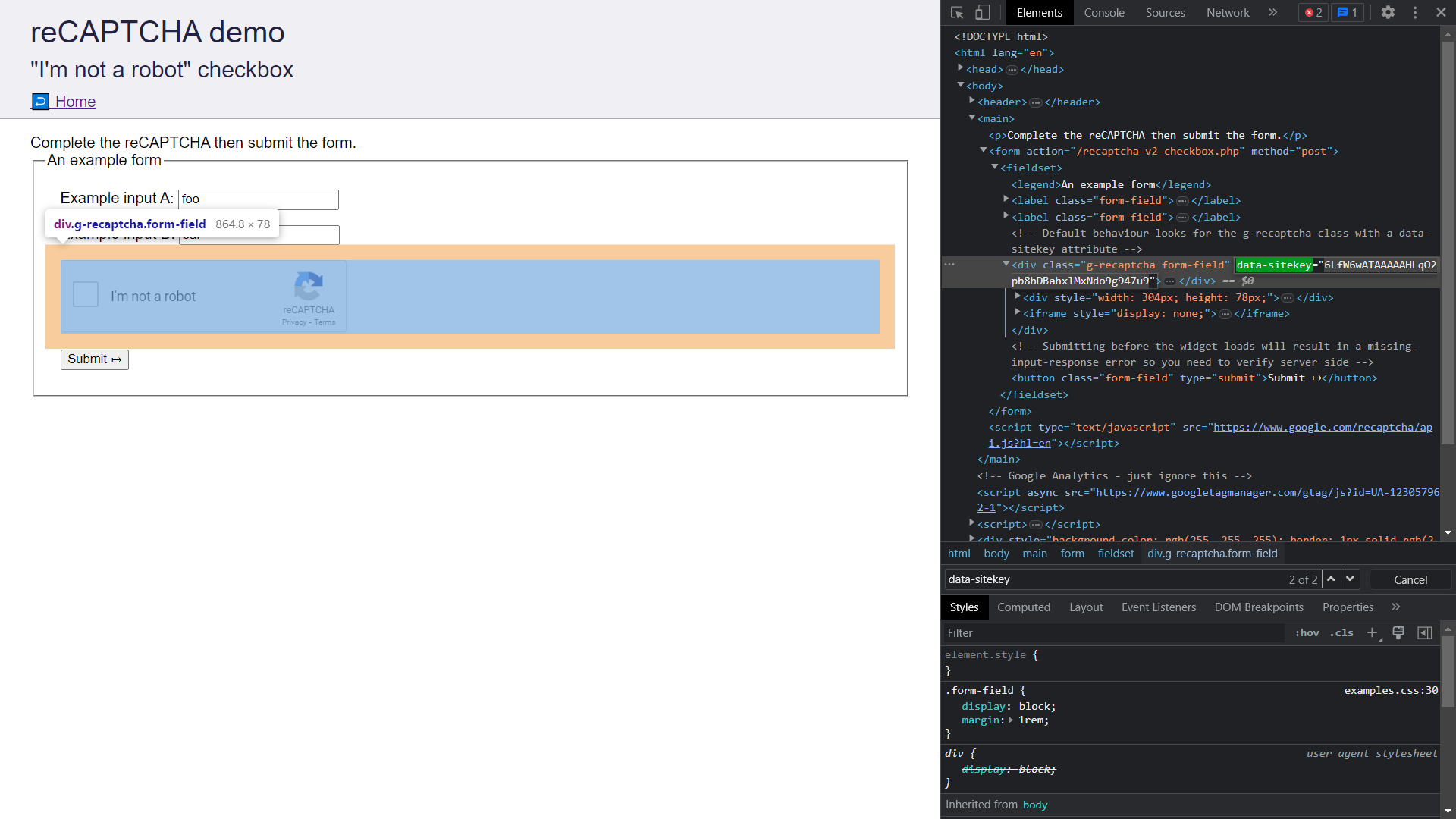
- Armazene a Chave do Site em um local seguro, pois ela será usada na seção posterior quando submetermos o CAPTCHA ao CapSolver.
Configurar o CapSolver
Para resolver CAPTCHAs usando o CapSolver, você precisa criar uma conta no CapSolver, adicionar fundos à sua conta e obter uma chave de API. Siga estes passos para configurar sua conta no CapSolver:
-
Registre-se em uma conta do CapSolver visitando CapSolver
-
Adicione fundos à sua conta do CapSolver usando PayPal, Criptomoedas ou outros métodos de pagamento listados. Observe que o valor mínimo para depósito é de $6 e taxas adicionais se aplicam.
-
Agora, copie a chave de API fornecida pelo CapSolver e armazene-a de forma segura para uso posterior.
Resolvendo o CAPTCHA
Agora, prosseguiremos para resolver o CAPTCHA usando o CapSolver. O processo geral envolve três etapas:
- Iniciar o navegador e visitar a página de CAPTCHA usando o pyppeteer.
- Resolver o CAPTCHA usando o CapSolver.
- Submeter a resposta do CAPTCHA.
Leia os seguintes trechos de código para entender essas etapas.
Iniciar o navegador e visitar a página de CAPTCHA:
python
# Inicia o navegador.
browser = await launch({'headless': False})
# Carrega a página de destino.
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)Resolver o CAPTCHA usando o CapSolver:
python
# Resolve o reCAPTCHA usando o CapSolver.
capsolver = RecaptchaV2Task("SUA_CHAVE_DE_API")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
# Obtenha o código do reCAPTCHA resolvido.
code = result.get("gRecaptchaResponse")Definir o CAPTCHA resolvido no formulário e submetê-lo:
python
# Defina o código do reCAPTCHA resolvido no formulário.
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
# Submeta o formulário.
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()Juntando Tudo
Abaixo está o código completo para o tutorial, que resolverá o CAPTCHA usando o CapSolver.
python
import asyncio
from pyppeteer import launch
from capsolver_python import RecaptchaV2Task
# O seguinte código resolve um desafio reCAPTCHA v2 usando o CapSolver.
async def main():
# Inicia o navegador.
browser = await launch({'headless': False})
# Carrega a página de destino.
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)
# Resolve o reCAPTCHA usando o CapSolver.
print("Resolvendo CAPTCHA")
capsolver = RecaptchaV2Task("SUA_CHAVE_DE_API")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
# Obtenha o código do reCAPTCHA resolvido.
code = result.get("gRecaptchaResponse")
print(f"CAPTCHA resolvido com sucesso. O código de resolução é {code}")
# Defina o código do reCAPTCHA resolvido no formulário.
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
# Submeta o formulário.
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()
# Pausa a execução para que você possa ver a tela após a submissão antes de fechar o navegador
input("Submissão do CAPTCHA bem-sucedida. Pressione enter para continuar")
# Fecha o navegador.
await browser.close()
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())Cole o código acima no seu arquivo main.py. Substitua SUA_CHAVE_DE_API pela sua chave de API e execute o código.
Você observará que o CAPTCHA será resolvido e você será recebido com uma página de sucesso.
Como Resolver CAPTCHA no NodeJS usando o CapSolver durante o Web Scraping
Pré-requisitos
- Proxy (Opcional)
- Node.JS instalado
- Chave de API do Capsolver
Passo 1: Instalar Pacotes Necessários
Execute os seguintes comandos para instalar os pacotes necessários:
python
npm install axiosCódigo Node.JS para resolver reCaptcha v2 sem proxy
Aqui está um script de exemplo em Node.JS para realizar a tarefa:
js
const axios = require('axios');
const PAGE_URL = ""; // Substitua pelo seu site
const SITE_KEY = ""; // Substitua pela sua chave do site
const CLIENT_KEY = ""; // Substitua pela sua chave de API do CAPSOLVER
async function createTask(payload) {
try {
const res = await axios.post('https://api.capsolver.com/createTask', {
clientKey: CLIENT_KEY,
task: payload
});
return res.data;
} catch (error) {
console.error(error);
}
}
async function getTaskResult(taskId) {
try {
success = false;
while(success == false){
await sleep(1000);
console.log("Obtendo resultado da tarefa para o ID da tarefa: " + taskId);
const res = await axios.post('https://api.capsolver.com/getTaskResult', {
clientKey: CLIENT_KEY,
taskId: taskId
});
if( res.data.status == "ready") {
success = true;
console.log(res.data)
return res.data;
}
}
} catch (error) {
console.error(error);
return null;
}
}
async function solveReCaptcha(pageURL, sitekey) {
const taskPayload = {
type: "ReCaptchaV2TaskProxyless",
websiteURL: pageURL,
websiteKey: sitekey,
};
const taskData = await createTask(taskPayload);
return await getTaskResult(taskData.taskId);
}
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function main() {
try {
const response = await solveReCaptcha(PAGE_URL, SITE_KEY );
console.log(`Token recebido: ${response.solution.gReCaptcharesponse}`);
}
catch (error) {
console.error(`Erro: ${error}`);
}
}
main();👀 Mais informações
Conclusão:
Neste tutorial, aprendemos como resolver CAPTCHAs usando CapSolver ao realizar web scraping com Puppeteer e Node.js. Ao utilizar a API do CapSolver, podemos automatizar o processo de resolução de CAPTCHA e tornar as tarefas de web scraping mais eficientes e confiáveis. Lembre-se de seguir os termos e condições dos sites que você raspagem e use o web scraping de forma responsável.
Ver mais
Web ScrapingApr 22, 2026
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.
Web ScrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

