Web Scraping com SeleniumBase e Python em 2024

Anh Tuan
Data Science Expert
Introdução ao SeleniumBase
SeleniumBase é uma estrutura Python que simplifica a automação e os testes da web. Ela estende os recursos do Selenium WebDriver com uma API mais amigável, seletores avançados, esperas automáticas e ferramentas de teste adicionais.
Configurando o SeleniumBase
Antes de começarmos, certifique-se de que o Python 3 esteja instalado em seu sistema. Siga estas etapas para configurar o SeleniumBase:
-
Instale o SeleniumBase:
bashpip install seleniumbase -
Verifique a Instalação:
bashsbase --help
Scraper Básico com SeleniumBase
Vamos começar criando um script simples que navega para quotes.toscrape.com e extrai citações e autores.
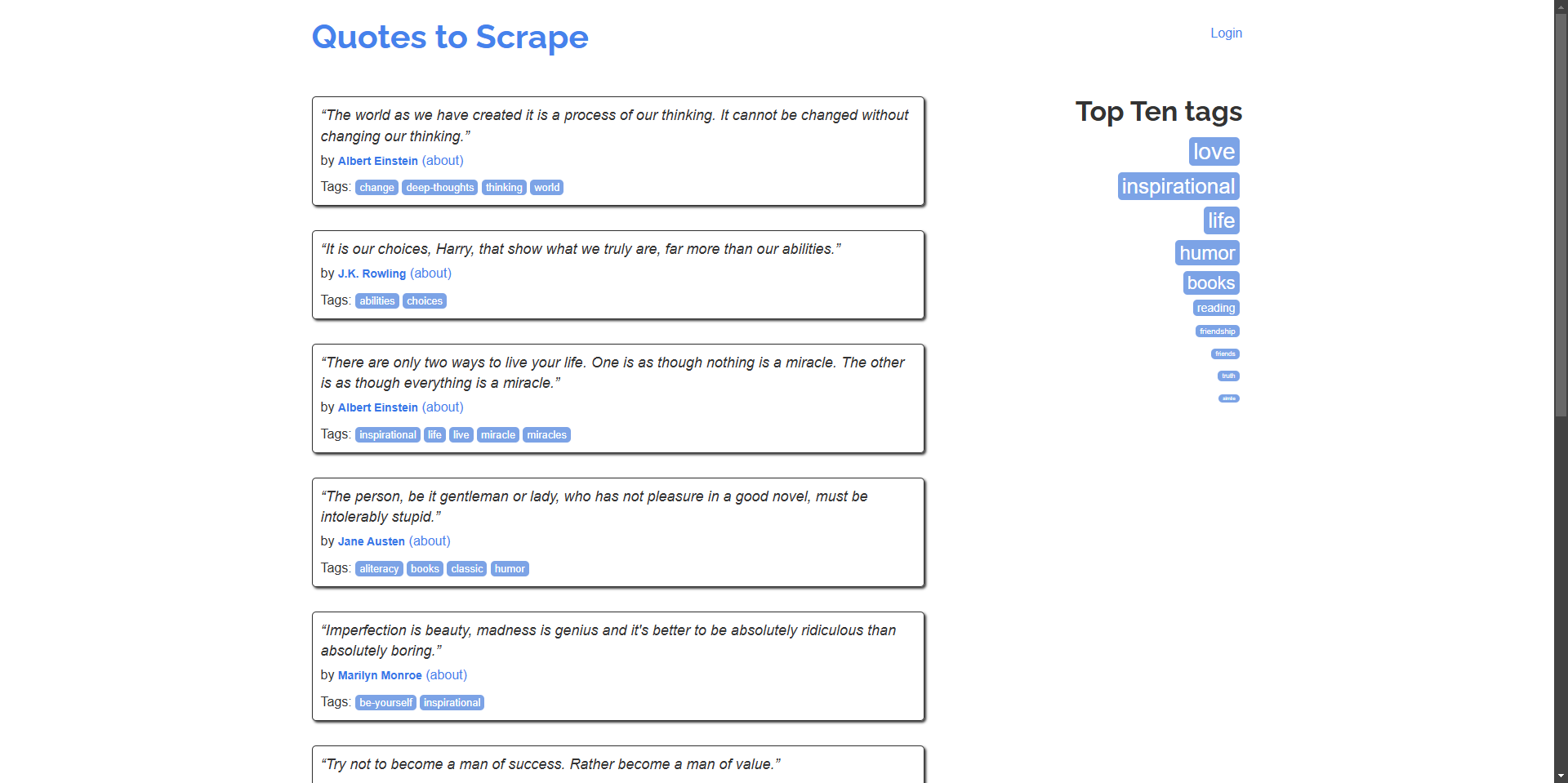
Exemplo: Raspe citações e seus autores da página inicial.
python
# scrape_quotes.py
from seleniumbase import BaseCase
class QuotesScraper(BaseCase):
def test_scrape_quotes(self):
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
if __name__ == "__main__":
QuotesScraper().main()Execute o script:
bash
python scrape_quotes.pySaída:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” - Albert Einstein
...Exemplos Mais Avançados de Web Scraping
Para aprimorar suas habilidades de web scraping, vamos explorar exemplos mais avançados usando SeleniumBase.
Raspagem de Múltiplas Páginas (Paginação)
Muitos sites exibem conteúdo em várias páginas. Vamos modificar nosso script para navegar por todas as páginas e raspar citações.
python
# scrape_quotes_pagination.py
from seleniumbase import BaseCase
class QuotesPaginationScraper(BaseCase):
def test_scrape_all_quotes(self):
self.open("https://quotes.toscrape.com/")
while True:
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
# Verifique se existe uma próxima página
if self.is_element_visible('li.next > a'):
self.click('li.next > a')
else:
break
if __name__ == "__main__":
QuotesPaginationScraper().main()Explicação:
- Fazemos loop pelas páginas verificando se o botão "Próximo" está disponível.
- Usamos
is_element_visiblepara verificar se o botão "Próximo" está disponível. - Clicamos no botão "Próximo" para navegar para a próxima página.
Lidando com Conteúdo Dinâmico com AJAX
Alguns sites carregam conteúdo dinamicamente usando AJAX. SeleniumBase pode lidar com esses cenários esperando que os elementos carreguem.
Exemplo: Raspe tags do site, que carregam dinamicamente.
python
# scrape_dynamic_content.py
from seleniumbase import BaseCase
class TagsScraper(BaseCase):
def test_scrape_tags(self):
self.open("https://quotes.toscrape.com/")
# Clique no link 'Top Ten tags' para carregar tags dinamicamente
self.click('a[href="/tag/"]')
self.wait_for_element("div.tags-box")
tags = self.find_elements("span.tag-item > a")
for tag in tags:
tag_name = tag.text
print(f"Tag: {tag_name}")
if __name__ == "__main__":
TagsScraper().main()Explicação:
- Esperamos que o elemento
div.tags-boxcarregue para garantir que o conteúdo dinâmico seja carregado. wait_for_elementgarante que o script não prossiga até que o elemento esteja disponível.
Enviando Formulários e Fazendo Login
Às vezes, você precisa fazer login em um site antes de raspar o conteúdo. Aqui está como você pode lidar com o envio de formulários.
Exemplo: Faça login no site e raspe as citações da página do usuário autenticado.
python
# scrape_with_login.py
from seleniumbase import BaseCase
class LoginScraper(BaseCase):
def test_login_and_scrape(self):
self.open("https://quotes.toscrape.com/login")
# Preencha o formulário de login
self.type("input#username", "testuser")
self.type("input#password", "testpass")
self.click("input[type='submit']")
# Verifique o login procurando um link de logout
if self.is_element_visible('a[href="/logout"]'):
print("Logado com sucesso!")
# Agora raspe as citações
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
else:
print("Falha ao logar.")
if __name__ == "__main__":
LoginScraper().main()Explicação:
- Navegamos para a página de login e preenchemos as credenciais.
- Após enviar o formulário, verificamos o login procurando a presença de um link de logout.
- Então, prosseguimos para raspar o conteúdo disponível para usuários logados.
Observação: Como quotes.toscrape.com permite qualquer nome de usuário e senha para demonstração, podemos usar credenciais fictícias.
Extraindo Dados de Tabelas
Os sites costumam apresentar dados em tabelas. Aqui está como extrair dados de tabela.
Exemplo: Raspe dados de uma tabela (exemplo hipotético, pois o site não possui tabelas).
python
# scrape_table.py
from seleniumbase import BaseCase
class TableScraper(BaseCase):
def test_scrape_table(self):
self.open("https://www.example.com/table-page")
# Espere a tabela carregar
self.wait_for_element("table#data-table")
rows = self.find_elements("table#data-table > tbody > tr")
for row in rows:
cells = row.find_elements("td")
row_data = [cell.text for cell in cells]
print(row_data)
if __name__ == "__main__":
TableScraper().main()Explicação:
- Localizamos a tabela por seu ID ou classe.
- Iteramos sobre cada linha e, em seguida, sobre cada célula para extrair dados.
- Como
quotes.toscrape.comnão possui tabelas, substitua a URL por um site real que contenha uma tabela.
Integrando o CapSolver no SeleniumBase
Embora quotes.toscrape.com não tenha CAPTCHAs, muitos sites do mundo real têm. Para nos prepararmos para tais casos, demonstraremos como integrar o CapSolver em nosso script SeleniumBase usando a extensão do navegador CapSolver.
Como resolver captchas com SeleniumBase usando Capsolver
-
Baixe a Extensão CapSolver:
- Visite a página de lançamentos do CapSolver no GitHub.
- Baixe a versão mais recente da extensão do navegador CapSolver.
- Descompacte a extensão em um diretório na raiz do seu projeto, por exemplo,
./capsolver_extension.
Configurando a Extensão CapSolver
-
Localize o Arquivo de Configuração:
- Encontre o arquivo
config.jsonlocalizado no diretóriocapsolver_extension/assets.
- Encontre o arquivo
-
Atualize a Configuração:
- Defina
enabledForcaptchae/ouenabledForRecaptchaV2comotruedependendo dos tipos de CAPTCHA que você deseja resolver. - Defina
captchaModeoureCaptchaV2Modecomo"token"para resolução automática.
Exemplo
config.json:json{ "apiKey": "YOUR_CAPSOLVER_API_KEY", "enabledForcaptcha": true, "captchaMode": "token", "enabledForRecaptchaV2": true, "reCaptchaV2Mode": "token", "solveInvisibleRecaptcha": true, "verbose": false }- Substitua
"YOUR_CAPSOLVER_API_KEY"por sua chave de API CapSolver real.
- Defina
Carregando a Extensão CapSolver no SeleniumBase
Para usar a extensão CapSolver no SeleniumBase, precisamos configurar o navegador para carregar a extensão quando ele iniciar.
-
Modifique seu Script SeleniumBase:
- Importe
ChromeOptionsdeselenium.webdriver.chrome.options. - Configure as opções para carregar a extensão CapSolver.
Exemplo:
pythonfrom seleniumbase import BaseCase from selenium.webdriver.chrome.options import Options as ChromeOptions import os class QuotesScraper(BaseCase): def setUp(self): super().setUp() # Caminho para a extensão CapSolver extension_path = os.path.abspath('capsolver_extension') # Configure as opções do Chrome options = ChromeOptions() options.add_argument(f"--load-extension={extension_path}") options.add_argument("--disable-gpu") options.add_argument("--no-sandbox") # Atualize o driver com as novas opções self.driver.quit() self.driver = self.get_new_driver(browser_name="chrome", options=options) - Importe
-
Certifique-se de que o Caminho da Extensão esteja Correto:
- Certifique-se de que
extension_pathaponte para o diretório onde você descompactou a extensão CapSolver.
- Certifique-se de que
Script de Exemplo com Integração CapSolver
Aqui está um script completo que integra o CapSolver ao SeleniumBase para resolver CAPTCHAs automaticamente. Continuaremos usando https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php como nosso site de exemplo.
python
# scrape_quotes_with_capsolver.py
from seleniumbase import BaseCase
from selenium.webdriver.chrome.options import Options as ChromeOptions
import os
class QuotesScraper(BaseCase):
def setUp(self):
super().setUp()
# Caminho para a pasta da extensão CapSolver
# Certifique-se de que este caminho aponte corretamente para a pasta da extensão do Chrome CapSolver
extension_path = os.path.abspath('capsolver_extension')
# Configure as opções do Chrome
options = ChromeOptions()
options.add_argument(f"--load-extension={extension_path}")
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
# Atualize o driver com as novas opções
self.driver.quit() # Feche qualquer instância de driver existente
self.driver = self.get_new_driver(browser_name="chrome", options=options)
def test_scrape_quotes(self):
# Navegue para o site de destino com reCAPTCHA
self.open("https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php")
# Verifique se o CAPTCHA está presente e resolva-o se necessário
if self.is_element_visible("iframe[src*='recaptcha']"):
# A extensão CapSolver deve lidar com o CAPTCHA automaticamente
print("CAPTCHA detectado, aguardando a extensão CapSolver para resolvê-lo...")
# Espere o CAPTCHA ser resolvido
self.sleep(10) # Ajuste o tempo com base no tempo médio de resolução
# Prossiga com as ações de raspagem após o CAPTCHA ser resolvido
# Ação de exemplo: clicando em um botão ou extraindo texto
self.assert_text("reCAPTCHA demo", "h1") # Confirme o conteúdo da página
def tearDown(self):
# Limpe e feche o navegador após o teste
self.driver.quit()
super().tearDown()
if __name__ == "__main__":
QuotesScraper().main()Explicação:
-
Método setUp:
- Subscrevemos o método
setUppara configurar o navegador Chrome com a extensão CapSolver antes de cada teste. - Especificamos o caminho para a extensão CapSolver e a adicionamos às opções do Chrome.
- Encerramos o driver existente e criamos um novo com as opções atualizadas.
- Subscrevemos o método
-
Método test_scrape_quotes:
- Navegamos para o site de destino.
- A extensão CapSolver detectaria e resolveria automaticamente qualquer CAPTCHA.
- Realizamos as tarefas de raspagem como de costume.
-
Método tearDown:
- Garantimos que o navegador seja fechado após o teste para liberar recursos.
Executando o Script:
bash
python scrape_quotes_with_capsolver.pyObservação: Embora quotes.toscrape.com não tenha CAPTCHAs, a integração do CapSolver prepara seu scraper para sites que o possuem.
Conclusão
Neste guia, exploramos como realizar web scraping usando SeleniumBase, cobrindo técnicas básicas de raspagem e exemplos mais avançados como lidar com paginação, conteúdo dinâmico e envio de formulários. Também demonstramos como integrar o CapSolver em seus scripts SeleniumBase para resolver CAPTCHAs automaticamente, garantindo sessões de raspagem ininterruptas.
Ver mais
AIJun 18, 2026
Escolhendo um Solucionador de CAPTCHA para Sua Infraestrutura de Agentes
Um quadro de decisão para escolher um solucionador de CAPTCHA para infraestrutura de agente, focado em mapeamento de desafios, vinculação de sessão, observabilidade, controles de taxa e uso responsável.

AIJun 18, 2026
Melhor CAPTCHA API para Agentes de IA em 2026
Um guia prático de avaliação para escolher uma API de CAPTCHA para agentes de IA em 2026, focado em cobertura de tarefas documentadas, contratos de polling, validação de tokens e controles operacionais.