Como o Reconhecimento de Imagens por IA Funciona? | Guia Técnico

Adélia Cruz
Neural Network Developer
TL;Dr
- A IA de reconhecimento de imagens traduz pixels visuais em dados numéricos para interpretação por máquinas.
- Redes Neurais Convolucionais (CNNs) são a arquitetura central usada para identificar padrões como bordas e formas.
- O processo envolve uma pipeline estruturada desde a coleta e rotulação de dados até o treinamento e avaliação do modelo.
- Aplicações do mundo real variam desde diagnósticos médicos até sistemas de segurança automatizados como o Vision Engine da CapSolver.
- Fontes éticas de dados e conformidade técnica são essenciais para o desenvolvimento sustentável de IA.
Introdução
A IA de reconhecimento de imagens funciona convertendo informações visuais em matrizes matemáticas que redes neurais analisam para padrões específicos. Essa tecnologia permite que máquinas identifiquem objetos, pessoas e ações em imagens digitais com velocidade e precisão notáveis. Para desenvolvedores e entusiastas de dados, entender como funciona o reconhecimento de imagens com IA é o primeiro passo para construir sistemas avançados de visão computacional.
Ao longo deste texto, a eficácia do reconhecimento de imagens depende da qualidade dos dados de treinamento e da sofisticação da arquitetura neural. Este guia desmistifica as camadas técnicas da IA visual, desde o processamento de pixels brutos até a classificação final de objetos complexos. Exploraremos como sistemas modernos usam matemática para "ver" e interpretar o mundo ao nosso redor.
Entendendo a Base: Pixels e Dados Numéricos
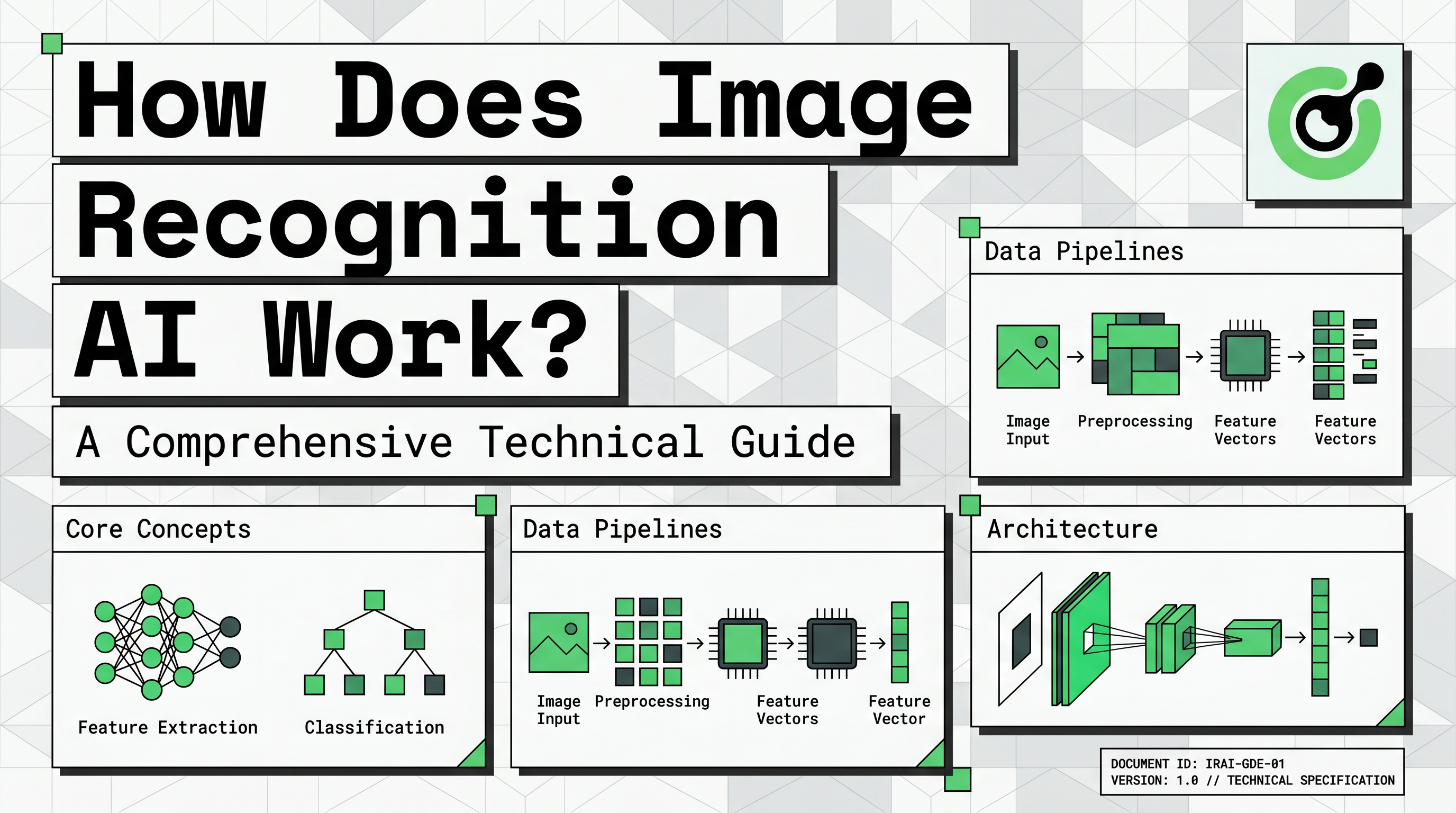
Para entender como funciona o reconhecimento de imagens com IA, devemos primeiro analisar como os computadores percebem imagens. Uma imagem digital é essencialmente uma grade grande de elementos pequenos chamados pixels. Cada pixel contém valores numéricos que representam sua intensidade de luz ou níveis de cor.
Em uma imagem colorida padrão, cada pixel é representado por três valores: vermelho, verde e azul (RGB). Esses valores geralmente variam de 0 a 255. Uma máquina vê uma foto de um carro não como um veículo, mas como uma matriz massiva de números. Essa representação numérica é a entrada bruta que um sistema de reconhecimento de imagens processa para encontrar padrões significativos.
| Componente | Representação da Máquina | Função |
|---|---|---|
| Pixel | Valor Numérico (0-255) | Unidade básica de dados visuais |
| Canal de Cor | Matriz RGB | Fornece informações de cor e profundidade |
| Tensor de Imagem | Matriz Multidimensional | A estrutura de dados completa para entrada de IA |
Essa transição da entrada visual para tensores legíveis por máquinas é crítica. Permite que a IA execute operações matemáticas nos dados para identificar características que humanos reconhecem de forma instintiva.
O Motor da IA Visual: Redes Neurais Convolucionais (CNNs)
A tecnologia principal por trás dos sistemas visuais modernos é a Rede Neural Convolucional (CNN). Essa arquitetura foi especificamente projetada para processar estruturas de dados semelhantes a grades, como imagens. Ao explorar como funciona o reconhecimento de imagens com IA, as CNNs são o componente técnico mais importante a entender.
Uma CNN consiste em várias camadas que executam funções diferentes. A primeira camada é a camada convolucional, que aplica filtros à imagem para extrair características de baixo nível. Essas características incluem elementos simples como linhas horizontais, bordas verticais e texturas básicas.
Em seguida, as camadas de pooling reduzem a dimensionalidade dos dados, preservando as informações mais importantes. Este passo torna o sistema mais eficiente e ajuda a se concentrar nas características mais relevantes. Finalmente, as camadas totalmente conectadas tomam as informações processadas e realizam a classificação final. É nesse momento que a IA decide se as características identificadas representam um gato, um carro ou um tipo específico de texto.
De acordo com IBM: O que é Reconhecimento de Imagens?, essas camadas trabalham juntas para construir um entendimento hierárquico da imagem. O sistema começa com linhas simples e gradualmente constrói objetos complexos. Essa abordagem hierárquica é o motivo pelo qual as CNNs são tão eficazes no tratamento de tarefas visuais diversas.
A Pipeline de Reconhecimento de Imagens: Do Dado à Implantação
Construir um sistema bem-sucedido envolve uma pipeline estruturada que vai além apenas da rede neural. A primeira etapa é a coleta de dados, onde os desenvolvedores reúnem milhares de imagens relevantes para sua tarefa alvo. Por exemplo, um sistema projetado para identificar anomalias médicas requer um grande conjunto de dados de imagens clínicas.
A rotulação de dados é o próximo passo crítico. Anotadores humanos devem etiquetar as imagens com classificações corretas ou desenhar caixas delimitadoras ao redor de objetos específicos. Esses dados rotulados servem como a "verdade real" que a IA usa para aprender durante a fase de treinamento. Sem rótulos de alta qualidade, até mesmo as melhores CNNs falharão em produzir resultados precisos.
Pré-processamento e aumento de dados também são essenciais. Isso envolve redimensionar imagens, normalizar valores de cor e criar variações dos dados existentes. O aumento ajuda o modelo a se tornar mais robusto, treinando-o com versões giradas, invertidas ou ligeiramente desfocadas das imagens originais. Isso garante que a IA possa reconhecer objetos em diferentes condições do mundo real.
Finalmente, o modelo é avaliado usando métricas como precisão, recall e acurácia. Essa fase de teste determina se o sistema está pronto para implantação. Os desenvolvedores devem garantir que a IA performe de forma confiável em novos dados não vistos antes de integrá-la a um aplicativo em tempo real.
Aplicações Práticas: Resolvendo Desafios Visuais Complexos
O reconhecimento de imagens é usado em muitas indústrias para automatizar tarefas que antes eram manuais. Na saúde, ajuda radiologistas a identificar sinais iniciais de doenças em radiografias. No varejo, impulsiona sistemas de checkout automatizados e ferramentas de busca visual que ajudam os clientes a encontrar produtos usando fotos.
Uma aplicação especializada dessa tecnologia é encontrada em segurança e automação. Por exemplo, CapSolver utiliza reconhecimento de imagens avançado para resolver desafios visuais complexos como CAPTCHAs. Seu Vision Engine é um exemplo primordial de como funciona o reconhecimento de imagens com IA em ambientes de alta precisão.
Ao usar o Vision Engine da CapSolver, os desenvolvedores podem automatizar o reconhecimento de quebra-cabeças visuais com precisão extrema. Isso é especialmente útil para tarefas de raspagem da web e extração de dados, onde a automação tradicional pode ser bloqueada. Para aqueles que desejam implementar essas tecnologias, um guia prático sobre IA e LLMs na automação pode fornecer estratégias de implementação valiosas. Abaixo está um exemplo conceitual de como interagir com uma API de reconhecimento visual:
python
import requests
# Exemplo de uso de um engine de visão para reconhecimento de imagens
def resolver_tarefa_visual(caminho_imagem, chave_api):
url = "https://api.capsolver.com/createTask"
payload = {
"clientKey": chave_api,
"task": {
"type": "ImageToTextTask",
"body": "string_codificada_em_base64_da_imagem"
}
}
response = requests.post(url, json=payload)
return response.json()
# Isso demonstra o uso prático do reconhecimento de imagens na automaçãoO papel da IA na resolução de CAPTCHAs destaca a maturidade técnica do reconhecimento de imagens moderno. Mostra que a IA agora pode lidar com tarefas visuais subjetivas que antes eram consideradas apenas solucionáveis por humanos. Essa evolução faz parte de uma tendência mais ampla onde IA e LLMs estão mudando o cenário de CAPTCHAs ao fornecer capacidades de raciocínio mais sofisticadas.
Tarefas Objetivas vs. Subjetivas na IA Visual
Não todas as tarefas de reconhecimento de imagens são iguais em complexidade. Os desenvolvedores frequentemente categorizam tarefas com base no nível de subjetividade e na precisão necessária.
| Categoria de Tarefa | Descrição | Exemplo |
|---|---|---|
| Objetiva | Critérios claros com respostas binárias | Tem um cachorro nesta foto? |
| Subjetiva | Requer interpretação sutil | Esta imagem médica mostra um crescimento benigno ou maligno? |
| Quantitativa | Envolve contagem ou medição | Quantos carros há neste estacionamento? |
| Qualitativa | Avalia a qualidade de uma imagem | Esta foto do produto é clara o suficiente para um site de comércio eletrônico? |
Entender essas categorias ajuda os desenvolvedores a escolher os modelos e estratégias de treinamento certos. Tarefas objetivas são geralmente mais fáceis para a IA dominar, enquanto tarefas subjetivas exigem conjuntos de dados mais extensos e supervisão humana.
Perguntas Frequentes
Qual é a diferença entre reconhecimento de imagens e detecção de objetos?
O reconhecimento de imagens identifica o assunto principal de uma imagem, enquanto a detecção de objetos encontra e etiqueta múltiplos objetos dentro de um único quadro. A detecção de objetos é geralmente mais complexa, pois requer identificar a localização de cada objeto.
Por que as CNNs são preferidas para tarefas relacionadas a imagens?
As CNNs são preferidas porque podem aprender automaticamente hierarquias espaciais de características. Elas usam camadas convolucionais para identificar padrões simples como bordas e gradualmente os combinam em objetos complexos. Isso as torna mais eficientes do que redes neurais tradicionais para dados visuais.
Quantos dados são necessários para treinar um modelo de reconhecimento de imagens confiável?
A quantidade de dados depende da complexidade da tarefa. Para classificação simples, alguns milhares de imagens podem ser suficientes. No entanto, para sistemas de alta precisão em áreas como veículos autônomos, milhões de imagens rotuladas são frequentemente necessárias para garantir segurança e confiabilidade.
A IA de reconhecimento de imagens pode funcionar em tempo real?
Sim, hardware moderno e arquiteturas de redes neurais otimizadas permitem reconhecimento de imagens em tempo real. Isso é essencial para aplicações como reconhecimento facial de segurança e navegação de veículos autônomos, onde decisões devem ser tomadas em milissegundos.
Conclusão
Dominar como funciona o reconhecimento de imagens com IA requer um entendimento profundo tanto da arquitetura neural quanto da gestão de dados. Combinando CNNs poderosas com conjuntos de dados de alta qualidade, os desenvolvedores podem criar sistemas que interpretam o mundo visual com precisão impressionante. Essa tecnologia continua evoluindo, abrindo novas possibilidades para automação e tomada de decisões inteligentes.
Se você está buscando integrar visualização de IA avançada aos seus fluxos de trabalho, explore a CapSolver hoje. Nossas soluções são projetadas para lidar com as tarefas mais desafiadoras de reconhecimento de imagens com facilidade.
Ver mais
Web ScrapingJul 22, 2026
Monitoramento de Regressão do SEO Técnico: Pipeline de Automação
Construa um monitoramento de regressão de SEO técnico com bases versionadas, diferenças semânticas, alertas verificados e uma etapa opcional de recuperação CAPTCHA autorizada.
CloudflareJul 22, 2026
Solução de CAPTCHA MCP: Guia de Integração do Cloudflare Turnstile
Construa um fluxo de trabalho MCP Cloudflare Turnstile com gate de política, retries limitados, logs redatados, verificações de sessão e validação de resultados.