Melhores agentes de usuário para web scraping e como usá-los

Adélia Cruz
Neural Network Developer

Ao realizar web scraping, usar o agente de usuário errado pode levar a bloqueios instantâneos. Os sites geralmente contam com agentes de usuário para diferenciar usuários reais de bots. Para evitar a detecção, é crucial usar agentes de usuário bem formados e frequentemente atualizados em seus projetos de web scraping.
Neste guia, você descobrirá:
- O que é um agente de usuário e por que ele importa para web scraping
- Uma lista dos melhores agentes de usuário para scraping
- Como configurar e rotacionar agentes de usuário em Python
- Boas práticas adicionais para evitar ser bloqueado
Vamos mergulhar! 🚀
O que é um agente de usuário?
Um Agente de Usuário (UA) é uma string enviada nos cabeçalhos de solicitação HTTP que identifica o navegador, o sistema operacional e outros detalhes. Os servidores web usam essas informações para renderizar o conteúdo apropriado para o dispositivo do usuário.
Exemplo de uma string de agente de usuário:
plaintext
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36Desmembrando:
Mozilla/5.0– Família do navegador(Windows NT 10.0; Win64; x64)– Detalhes do sistema operacionalAppleWebKit/537.36 (KHTML, like Gecko)– Mecanismo de renderizaçãoChrome/123.0.0.0– Versão do navegadorSafari/537.36– Estrutura de compatibilidade
Ao modificar o agente de usuário, você pode fazer com que seu web scraper pareça um navegador real, reduzindo o risco de detecção.
Por que os agentes de usuário são importantes para web scraping
A maioria dos sites analisa os agentes de usuário para filtrar o tráfego de bots. Se seu scraper enviar um agente de usuário inválido ou desatualizado, ele pode ser bloqueado instantaneamente.
Usando um agente de usuário apropriado, você pode:
- Imitar um navegador real e se misturar ao tráfego normal.
- Contornar as proteções anti-bot que verificam as bibliotecas de scraping padrão.
- Melhorar as taxas de sucesso das solicitações e evitar CAPTCHAs ou bloqueios de IP.
No entanto, usar apenas um agente de usuário repetidamente ainda pode disparar sistemas anti-bot. É por isso que rotacionar os agentes de usuário é crucial.
Melhores agentes de usuário para web scraping (lista atualizada)
Abaixo está uma lista selecionada de agentes de usuário eficazes para web scraping:
Agentes de usuário do Google Chrome:
plaintext
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36Agentes de usuário do Mozilla Firefox:
plaintext
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0
Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:124.0) Gecko/20100101 Firefox/124.0
Mozilla/5.0 (X11; Linux i686; rv:124.0) Gecko/20100101 Firefox/124.0Outros navegadores:
plaintext
Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4.1 Safari/605.1.15
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.2420.81💡 Dica: Você pode verificar seu próprio agente de usuário visitando WhatIsMyUserAgent.
Como definir um agente de usuário personalizado em Python
Muitos sites implementam mecanismos de detecção de bots que bloqueiam solicitações com cabeçalhos de agente de usuário ausentes ou incorretos. Nesta seção, vamos usar diferentes maneiras de definir e rotacionar agentes de usuário de forma eficiente.
1. Usando a biblioteca requests
A maneira mais simples de definir um agente de usuário é modificando os cabeçalhos de uma solicitação usando a popular biblioteca requests.
Exemplo: Definindo um agente de usuário estático
python
import requests
# Define headers with a custom User-Agent
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
# Send a request with the custom User-Agent
response = requests.get("https://httpbin.org/headers", headers=headers)
# Print the response headers
print(response.text)Saída:
json
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
}Isso confirma que o servidor recebe e reconhece corretamente a string do agente de usuário.
2. Rotacionando agentes de usuário para melhor anonimato
Usar um único agente de usuário repetidamente pode levar a bloqueios. Para evitar isso, rotacionar os agentes de usuário usando uma lista predefinida.
Exemplo: Rotacionando agentes de usuário com random
python
import requests
import random
# List of different user agents
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0"
]
# Select a random user agent
headers = {"User-Agent": random.choice(user_agents)}
# Send a request with the randomly chosen user agent
response = requests.get("https://httpbin.org/headers", headers=headers)
print(response.text)Ao rotacionar os agentes de usuário, seu scraper parece mais humano e reduz as chances de detecção.
3. Usando fake_useragent para geração dinâmica de agente de usuário
Em vez de manter uma lista estática, você pode gerar dinamicamente agentes de usuário usando a biblioteca fake_useragent.
Instalação:
sh
pip install fake-useragentExemplo: Gerando agentes de usuário aleatórios
python
from fake_useragent import UserAgent
import requests
# Create a UserAgent object
ua = UserAgent()
# Generate a random user agent
headers = {"User-Agent": ua.random}
# Send a request with a dynamically generated user agent
response = requests.get("https://httpbin.org/headers", headers=headers)
print(response.text)Este método fornece uma variedade maior de agentes de usuário, mantendo-os atualizados.
4. Definindo um agente de usuário personalizado em Selenium
Ao usar Selenium para web scraping, definir um agente de usuário requer a modificação das opções do navegador.
Exemplo: Definindo um agente de usuário no Chrome
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# Configure Chrome options
chrome_options = Options()
chrome_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36")
# Start browser with custom user agent
driver = webdriver.Chrome(options=chrome_options)
# Open a test page to verify user agent
driver.get("https://httpbin.org/headers")
# Extract and print page content
print(driver.page_source)
driver.quit()Usando ferramentas de automação de navegador como o Selenium, você pode simular o comportamento do usuário real e contornar medidas anti-bot avançadas.
5. Verificando seu agente de usuário
Para garantir que seu agente de usuário esteja configurado corretamente, use os seguintes métodos:
- Verifique os cabeçalhos de resposta de
https://httpbin.org/headers - Use as ferramentas de desenvolvedor do navegador (F12 > Rede > Cabeçalhos) para inspecionar solicitações
- Use log para confirmar a rotação do agente de usuário em scrapers
Exemplo: Registrando agentes de usuário em um loop
python
import requests
import random
import time
# User agent list
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0"
]
# Loop through requests
for i in range(5):
user_agent = random.choice(user_agents)
headers = {"User-Agent": user_agent}
response = requests.get("https://httpbin.org/headers", headers=headers)
print(f"Request {i+1} - User-Agent: {user_agent}")
time.sleep(2) # Add delay to avoid rate limitingEste script registra diferentes agentes de usuário em várias solicitações, ajudando você a depurar estratégias de rotação.
Como rotacionar agentes de usuário em escala
Em vez de usar um único agente de usuário estático, é melhor rotacioná-los dinamicamente para evitar a detecção. Aqui está como você pode rotacionar agentes de usuário em Python:
python
import requests
import random
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
]
headers = {"User-Agent": random.choice(user_agents)}
response = requests.get("https://httpbin.org/headers", headers=headers)
print(response.text)Este script seleciona aleatoriamente um agente de usuário da lista, tornando seu scraper mais difícil de detectar.
Boas práticas adicionais para evitar ser bloqueado
Mesmo com os melhores agentes de usuário, o web scraping requer técnicas adicionais para permanecer indetectável:
- Use proxies para evitar bloqueios de IP.
- Implemente atrasos e intervalos aleatórios entre as solicitações.
- Rotacionar cabeçalhos e padrões de solicitação para imitar o comportamento humano.
- Evite scraping excessivo para evitar disparar limites de taxa.
- Monitore os códigos de resposta para detectar bloqueios e adaptar-se de acordo.
Mesmo com rotação de agente de usuário e proxy e todas essas dicas, os sites ainda podem implementar técnicas de detecção avançadas, como impressão digital, desafios de JavaScript e verificação de CAPTCHA. É aí que entra o CapSolver.
CapSolver é especializado em resolver desafios de Capttcha, garantindo web scraping ininterrupto. Ao integrar o CapSolver, você pode resolver CAPTCHAs automaticamente e manter seu scraper funcionando sem problemas
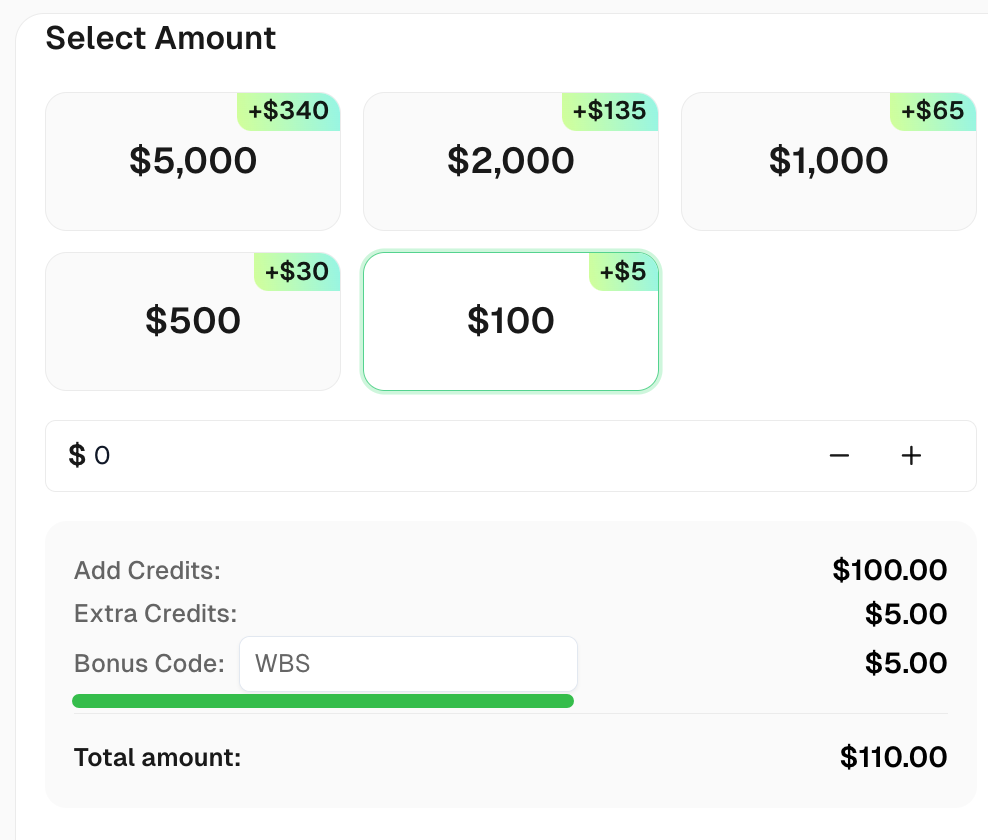
Solicite seu Código Bônus para as melhores soluções de captcha -CapSolver: CAPTCHA. Após resgatá-lo, você receberá um bônus extra de 5% após cada recarga, ilimitado
Conclusão
Usar os agentes de usuário corretos é uma etapa crítica no web scraping. Neste guia, abordamos:
✅ O que é um agente de usuário e como ele funciona
✅ Uma lista de agentes de usuário eficazes para scraping
✅ Como configurar e rotacionar agentes de usuário em Python
✅ Boas práticas adicionais para permanecer indetectável
Ao combinar rotação de agente de usuário com outras técnicas anti-detecção, você pode raspar dados com sucesso sem ser bloqueado.
FAQ
1. O que é um agente de usuário em web scraping?
Um agente de usuário é uma string que identifica o navegador ou o software cliente para um servidor web. No web scraping, ele é usado para imitar a atividade de um usuário real e evitar a detecção.
2. Web scraping para uso pessoal é ilegal?
Web scraping geralmente é legal para uso pessoal, mas você deve respeitar os termos de serviço de um site e evitar raspar dados confidenciais ou protegidos por direitos autorais.
3. Qual é o objetivo da rotação do agente de usuário em web scraping?
A rotação do agente de usuário ajuda a evitar a detecção e o bloqueio, fazendo com que as solicitações pareçam vir de diferentes navegadores ou dispositivos.
4. Como posso evitar ser bloqueado durante o web scraping?
Para evitar bloqueios, use rotação de IP, solução de CAPTCHA, atrasos entre as solicitações e garanta a conformidade com o robots.txt do site.
5. Web scraping pode afetar o desempenho de um site?
Sim, raspar com muita frequência pode sobrecarregar o servidor de um site. É importante raspar de forma responsável, com solicitações limitadas.
Ver mais
AIJun 18, 2026
Escolhendo um Solucionador de CAPTCHA para Sua Infraestrutura de Agentes
Um quadro de decisão para escolher um solucionador de CAPTCHA para infraestrutura de agente, focado em mapeamento de desafios, vinculação de sessão, observabilidade, controles de taxa e uso responsável.
AIJun 18, 2026
Melhor CAPTCHA API para Agentes de IA em 2026
Um guia prático de avaliação para escolher uma API de CAPTCHA para agentes de IA em 2026, focado em cobertura de tarefas documentadas, contratos de polling, validação de tokens e controles operacionais.