最適なウェブスクレイピング対APIの選択:自動化チーム向け

Sora Fujimoto
AI Solutions Architect
TL;DR
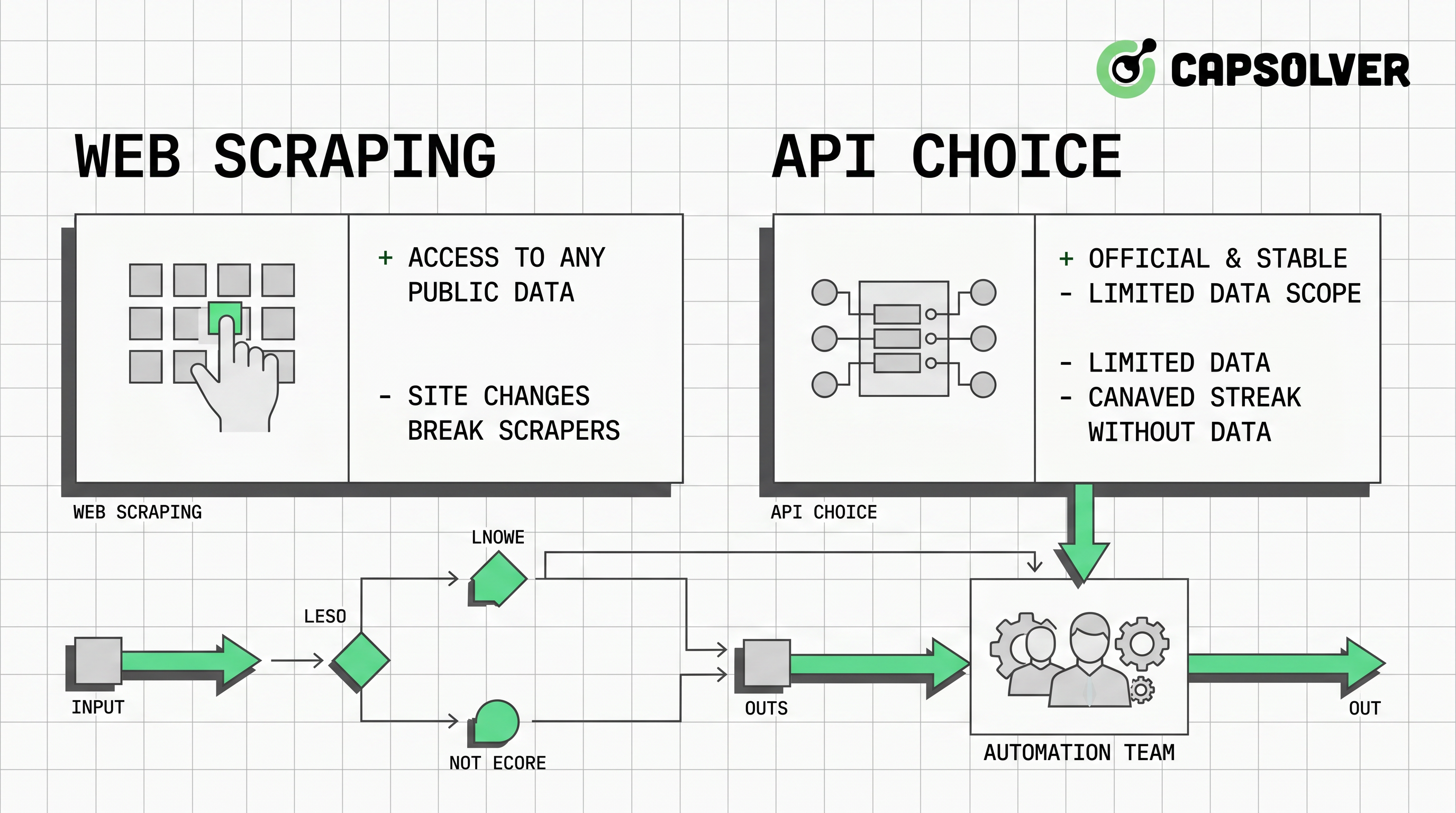
- 最適なウェブスクレイピングとAPIの選択は、データの権利、ソースの可用性、信頼性の要件、保守コストから始めるべきです。
- APIは、スキーマ、レートリミット、認証、バージョン管理が文書化しやすいため、統制された本番システムにおいて通常は優れています。
- 公開データに適切なAPIが存在しない場合、ウェブスクレイピングは有用です。ただし、robots.txtの確認、レート制御、ページ変更の監視、コンプライアンスチェックが必要です。
- ブラウザ自動化は動的ページに価値をもたらし、CAPTCHAやトラフィック検証イベントが発生した場合、CapSolverは承認されたワークフローをサポートできます。
- 最も耐障害性の高いアーキテクチャは、APIを第一に、次にスクレイピング、必要に応じてブラウザ自動化、CAPTCHA解決は制御された例外パスとして扱います。
イントロダクション
ウェブスクレイピングとAPIの選択は、どちらの方法がより強力かという問題ではなく、チームが必要とするデータに対して信頼性があり、許可されており、保守可能で監査可能な方法であるかどうかにかかっています。APIは、必要なフィールド、最新性、および利用条件を提供する場合、通常最初に選択すべきです。許可された公開ページが唯一の実用的なソースである場合、またはチームがプレゼンテーションレイヤーの変更を監視する必要がある場合、ウェブスクレイピングが有用になります。承認されたスクレイピングまたはブラウザ自動化フローがCAPTCHAチャレンジに遭遇した場合、CapSolverのスクレイピング時のCAPTCHA解決ガイドが、より広範な自動化プロセスに適合する文書化された解決パスを提供します。
API-firstがデフォルトの選択肢であるべき
APIは通常、デフォルトの選択肢であり、プロバイダーがサポートする契約を示します。適切に設計されたAPIは、チームに予測可能なフィールド、認証、レートリミット、エラーコード、バージョン管理を提供します。これらの特性により、エンジニアリングレビューが容易になり、脆弱なパースの必要性が減少します。APIはまた、データの履歴を簡略化します。各レコードはエンドポイント、タイムスタンプ、リクエストID、または文書化されたスキーマに関連付けられます。
REST APIチュートリアルとリファレンスは、リソース、メソッド、および表現などの一般的なAPI設計のアイデアを説明しています。 GitHub REST APIのレートリミットドキュメンテーションは、レートリミットが障害ではなく、運用契約である理由を示しています。多くの自動化プログラムでは、遅い公式APIが、高速なスクレイパーよりも優れています。これは、監査で防御が容易であり、データ消費者が増加したときに保守が容易だからです。
| 決定要因 | APIの利点 | ウェブスクレイピングの利点 |
|---|---|---|
| データ契約 | 安定したスキーマと文書化されたエラー | エンドポイントで公開されていない表示フィールドを収集できる |
| メンテナンス | バージョン管理とサポートチャネル | 適切なAPIが存在しない場合に動作する |
| 新鮮さ | 予測可能なポーリングとレートリミット | ページレベルの更新を迅速に反映できる |
| 動的ページ | ブラウザのオーバーヘッドが少ない | ブラウザ自動化でレンダリングされた状態を検査できる |
| チャレンジイベント | 通常回避される | 制御されたCAPTCHA解決ワークフローが必要になる場合がある |
重要なのは、スクレイピングを拒否することではなく、運用の複雑さを追加する前にスクレイピングが必要であることを証明することです。
ウェブスクレイピングがより適している場合
データが公開されており、許可されており、適切なAPIで利用できない場合、そしてモニタリングする価値がある場合、ウェブスクレイピングがより適しています。一般的な例には、公開価格ページ、製品在庫ページ、公開求人情報、公開ディレクトリ、ウェブサイト変更のモニタリングが含まれます。それでも、チームはデータフィールド、ソースページ、クロール頻度、排除ルール、およびワークフローの責任者であるビジネスオーナーを文書化する必要があります。
RFC 9309 ロボット排除プロトコルは、ウェブサイトが自動クライアントにクローリングルールを伝える方法を定義しています。 MDN URLリファレンスは、URLの正規化に役立ち、これは重複削除とクロール境界の基本的な要件です。これらのリファレンスは、実用的なルールをサポートしています:ウェブスクレイピングは、非公式なスクリプトではなく、許可と境界を持つエンジニアリングシステムとして扱われるべきです。
ウェブスクレイピングは、レイヤードデザインからも恩恵を受けます。静的ページは通常、HTTPリクエストとパーサーで処理できます。JavaScriptが豊富なページはブラウザ自動化が必要です。トラフィック検証があるページは、文書化されたチャレンジ処理ポリシーが必要です。自動化レイヤーに抽出と制御されたチャレンジ処理が必要な場合、CapSolverのPlaywright統合ガイドは役立ちます。
CAPTCHA解決が決定にどのように関与するか
CAPTCHA解決は、ウェブスクレイピングとAPIの決定ツリーで最後に位置付けられます。APIが存在し、必要を満たす場合、それを使用してください。許可された静的抽出で公開ページを収集できる場合、それを使用してください。ブラウザ自動化が必要な場合、レンダリングとインタラクションコントロールを追加してください。これらの選択の後、チームはサポートされるCAPTCHAまたはトラフィック検証イベントをどのように処理するかを決定する必要があります。
CapSolverのreCAPTCHA用語集とCAPTCHA用語のガイドラインは、解決パスを選択する前に一般的なチャレンジのグループを特定するのに役立ちます。決定には承認範囲、サポートドメイン、リトライ制限、ロギング、プロキシポリシー、ページレベルの成功チェックが含まれます。解決されたチャレンジだけでは不十分です。ワークフローは、承認されたタスクが正しく完了したことを確認する必要があります。
承認されたデータ自動化パイロットのボーナスコード
CapSolverボーナスコードを取得する
自動化予算を即座に増やす!
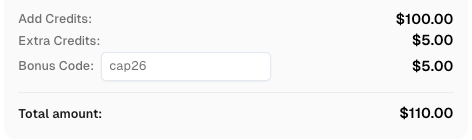
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、すべてのチャージで 5%のボーナス を受け取れます — 限度はありません。
今すぐCapSolverダッシュボードで取得してください
自動化チームのアーキテクチャパターン
強力なアーキテクチャは、アクセス方法、実行、検証、ガバナンスを分離します。アクセス方法はAPI、静的スクレイパー、ブラウザ自動化スクリプト、またはハイブリッドワークフローである可能性があります。実行はレートリミット、リトライ、安全な停止条件を適用すべきです。検証はレコード数、必要なフィールド、ソースタイムスタンプ、スキーマの変更を比較すべきです。ガバナンスは誰がソースを承認したか、どのデータが許可されているか、ワークフローが再レビューされるべきタイミングを記録すべきです。
ブラウザが重いワークフローの場合、Playwrightドキュメンテーションは制御されたページレンダリングとインタラクションの実用的な出発点を提供します。クローラーが重いワークフローの場合、Scrapyドキュメンテーションはスパイダー、アイテム、パイプラインを説明しています。チャレンジが重い承認されたワークフローの場合、CapSolverのブラウザ拡張ガイドは、ワークフローを設計する前に実際のページ動作を診断するのに役立ちます。
| アーキテクチャパターン | 使用するとき | このコントロールを追加 |
|---|---|---|
| APIのみ | 必須フィールドが利用可能で、利用条件が許可されている | エンドポイントモニタリングとレートリミット処理 |
| 静的スクレイピング | 公開ページが安定しており許可されている | robots.txtのレビューとセレクターのテスト |
| ブラウザ自動化 | レンダリングまたはインタラクションが必要 | タイムアウト予算とページ状態の検証 |
| ハイブリッドAPIとスクレイピング | APIが大部分のフィールドをカバーしているが、ページが文脈を追加 | ソースオブトラースルールと重複削除 |
| スクレイピングとCapSolver | 承認されたページにCAPTCHAチャレンジが表示される | 承認チケット、ロギングの非表示、リトライ制限 |
この構造により、ウェブスクレイピングとAPIの選択が透明になります。また、チームが単純な方法がビジネス要件を満たせないことを証明する前にブラウザ自動化やCAPTCHA解決を追加するリスクを減らします。
責任ある使用チェックリスト
責任ある自動化プログラムは、ソースのレビューから始まります。データが公開されているか、または他の方法で許可されているか、収集目的が正当か、または法的根拠とセキュリティ制御が存在しない限り、機密個人データや制限付きデータは対象外であるかを確認してください。次に、robots.txt、サイトの利用規約、APIドキュメンテーション、契約上の義務をレビューしてください。最後に、低容量でテストし、予期せぬログイン壁、権限の変更、チャレンジの急増、スキーマのずれが現れた場合にワークフローを停止してください。
OWASP 自動化された脅威プロジェクトは、同じ自動化技術が誤用される可能性があることを思い出させてくれます。あなたの内部基準は、許可、比例したリクエストレート、適切な識別、ワークフローの変更時に人間のレビューを要求する必要があります。CapSolverは、チャレンジ処理が正当な自動化プロセスの一部である所有、ステージング、クライアント承認、または他の許可されたターゲットでのみ使用されるべきです。
結論
ウェブスクレイピングとAPIの最善の選択は、単純な階層に従って行われるべきです。要件を満たすAPIを使用し、許可された静的スクレイピングを使用しない場合はそれを使用し、レンダリングが必要な場合はブラウザ自動化を追加し、CAPTCHA解決は文書化された例外パスとしてのみ追加します。承認された自動化で信頼性のあるチャレンジ処理が必要なチームは、CapSolverのウェブスクレイピングの法的ガイドが、API、クローラー、ブラウザ自動化、モニタリング、コンプライアンスレビューとともに、ガバナンスされたワークフロー内で解決を配置するのに役立ちます。
FAQ
ウェブスクレイピングとAPIの最善のルールは何ですか?
最善のルールはAPIを優先することです。APIが許容可能な条件下でデータを提供する場合はそれを使用し、許可されたページが実用的なソースである場合のみスクレイピングを使用します。
ウェブスクレイピングがAPIよりも良いのはいつですか?
公開され、許可されたページデータが適切なAPIで利用できない場合、またはチームが必要とするデータそのものがページのプレゼンテーションである場合、ウェブスクレイピングが優れています。
ブラウザ自動化を追加すべきタイミングはいつですか?
静的HTTP抽出ではレンダリングされたコンテンツ、ユーザーのインタラクション、または承認されたワークフローに必要なロード後のデータをキャプチャできない場合にのみ、ブラウザ自動化を追加してください。
CapSolverはウェブスクレイピングとAPIのワークフローにどのように適合しますか?
承認されたウェブスクレイピングまたはブラウザ自動化ワークフローがサポートされるCAPTCHAまたはトラフィック検証チャレンジに遭遇し、文書化された解決パスが必要な場合、CapSolverが適合します。
スクレイピングを行う前にチームが確認すべきことは何ですか?
チームは許可、robots.txt、利用規約、データの機密性、リクエストレート、モニタリングルールを確認する必要があります。チャレンジ処理が承認された計画の一部である場合、CapSolverのウェブスクレイピングFAQを参照してください。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
