ウェブスクレイピングのブロックの対処法: 実用的な方法

Ethan Collins
Pattern Recognition Specialist

TL;Dr:
- 仕組みを理解する: ウェブサイトはIPトラッキング、ブラウザのファイントプリント、行動分析を使用して自動スクリプトを識別し、ブロックします。
- ローテーションを実装する: ローテーション型の住宅プロキシと多様なUser-Agent文字列を使用して、人間のようなトラフィックパターンを模倣します。
- 課題に対処する: CAPTCHAを解決し、複雑なボット検出システムを効率的に管理する専門ツールを統合します。
- 倫理を守る: always robots.txtのガイドラインに従い、リクエストのスロットリングを実装して、ターゲットサーバーへの影響を最小限に保ちます。
イントロダクション
ウェブスクレイピングは、現代のデータ駆動型意思決定において不可欠な要素となっていますが、自動データ収集の環境はますます困難になっています。ウェブサイトがより高度なセキュリティ対策を採用するにつれて、ウェブスクレイピングのブロックを処理する方法を学ぶことは、成功する抽出プロジェクトにおいて必要なこととなっています。このガイドでは、ブロックが発生する理由、検出メカニズムの裏にある技術、そしてあなたのスクレイパーが動作し続けるための最も効果的で倫理的な戦略について、包括的な概要を提供します。カスタムクローラーを構築している開発者であっても、大規模な運用を管理しているデータアナリストであっても、これらの実用的な方法を理解することで、必要な情報を一貫してアクセスできるようになります。
ウェブスクレイピングブロックの性質を理解する
障害を効果的に管理するためには、まずそれが何で、なぜ存在するのかを理解する必要があります。ウェブスクレイピングブロックは、自動スクリプトがコンテンツにアクセスすることを防ぐための防御的な対策です。これらの対策は、サーバーのリソースを保護し、知的財産権の盗難を防ぎ、ユーザーのデータの整合性を維持するための広範なセキュリティ戦略の一部です。
最近の業界データによると、自動トラフィックはすべてのウェブリクエストの重要な割合を占めています。そのため、多くのプラットフォームが積極的なフィルタリングを採用しています。グローバルなトレンドについては、Statista Bot Traffic Dataレポートをご覧ください。サーバーが通常の人間の行動と異なるパターンを検出すると、CAPTCHAを表示したり、接続を遅くしたり、IPアドレスを完全にブロックしたりすることがあります。このような状況でウェブスクレイピングブロックを処理する方法を学ぶことは、データの継続的なアクセスにとって不可欠です。
技術的背景:検出メカニズムの仕組み
現代のセキュリティシステムは、ボットを識別するために単一の要因に依存していません。代わりに、すべてのイングレスリクエストに対してリスクプロファイルを構築するために、さまざまな技術を組み合わせています。
1. IPベースのトラッキング
これは防御の最も基本的なレイヤーです。サーバーは、特定の時間枠内で同じIPアドレスから送信されるリクエストの数を監視します。頻度が事前に設定されたしきい値を超えると、そのIPアドレスはマークされます。これは、ネットワークレベルでウェブスクレイピングブロックを処理する方法を知ることがなぜ重要なのかの理由の一つです。データセンターは、通常、正当な人間の訪問者にほとんど使用されないため、事前にブロックされることがよくあります。
2. ブラウザのファイントプリント
IPアドレスに加えて、ウェブサイトはブラウザ環境から膨大な情報を収集できます。これは、画面解像度、インストールされたフォント、タイムゾーン、ハードウェア仕様などが含まれます。これらの詳細が一貫性がない、または「クリーン」(ヘッドレスブラウザの典型的な特徴)に見える場合、システムはそのリクエストを自動化されたものと識別します。
3. 行動分析
高度なプラットフォームは、ユーザーがページとどのように相互作用するかを追跡します。人間は非線形のパターンでマウスを動かし、コンテンツを読むために時間をかけ、クリックのリズムを変化させます。一方、スクリプトは直接URLにジャンプし、ミリ秒単位でデータを抽出する可能性があります。予期される人間の行動から逸脱すると、赤信号が点灯します。この行動ベースの検出は、ウェブスクレイピングブロックを処理する際の最も難しい課題の一つです。
よくあるCAPTCHAの課題
システムが不確実だが疑わしいと判断した場合、通常はCAPTCHAを表示します。これらの種類を理解することは、ウェブスクレイピングブロックを効果的に処理するための鍵です。
| CAPTCHAの種類 | 説明 | 主な検出ロジック |
|---|---|---|
| 画像認識 | ユーザーはグリッドから特定のオブジェクト(例: 信号機)を選択する必要があります。 | 視覚データの処理能力をテストし、人間のようなクリックパターンを識別します。 |
| 非表示CAPTCHA | ユーザーの操作なしでバックグラウンドで動作します。 | ブラウザ環境と歴史的な行動を分析してリスクスコアを割り当てます。 |
| テキスト/数学の課題 | 単純な式の解を求めるか、歪んだテキストを入力する必要があります。 | オールドボットのためのOCR(光学文字認識)の難しさに依存しています。 |
| パズル/スライダー | ユーザーは画像を完成させるためにピースをドラッグする必要があります。 | カーソルの物理的な移動とアクションのタイミングに焦点を当てています。 |
ウェブスクレイピングブロックを処理する実践的な方法
正しい技術的戦略を実装することで、検出される可能性を大幅に減らすことができます。今日のプロフェッショナルが使用する最も効果的な方法を以下に示します。
ローテーション型の住宅プロキシを使用する
IPブロックは一般的であるため、住宅プロキシのプールを使用することは、IPブロックを回避し、高い成功率を確保する最も良い方法の一つです。これらのプロキシは、ウェブスクレイピングのベストプラクティスの柱です。データセンターのIPとは異なり、住宅IPは実際の家庭用インターネット接続に関連しているため、正当なユーザーと区別するのがはるかに困難です。数回のリクエストごとにこれらのIPをローテーションすることで、トラフィックを分散し、目立たずに済ませることができます。
リクエストヘッダーとUser-Agentを管理する
すべてのHTTPリクエストには、クライアントに関する情報をサーバーに伝えるヘッダーが含まれています。一般的なミスは、「python-requests/2.25.1」などのデフォルトのライブラリヘッダーを使用することです。代わりに、現実的なUser-Agent文字列の多様なセットを使用する必要があります。正しい構造を理解するには、MDN User-Agentドキュメントを参照してください。ヘッダーに「Accept-Language」や「Referer」などのフィールドを含めることで、現実的なブラウジングセッションを模倣してください。
リクエストスロットリングを実装する
スピードはボットの最大のヒントです。リクエストの間にランダムな遅延を追加することで、人間のブラウジング行動をシミュレートできます。この技術、いわゆるスロットリングは、ターゲットサーバーを過負荷にしないようにし、レート制限のアラームをトリガーする可能性を減らします。これらのウェブスクレイピングベストプラクティスを実装することで、セキュアなデータへのアクセスを維持し、大規模な運用中にIPブロックを回避するのに役立ちます。
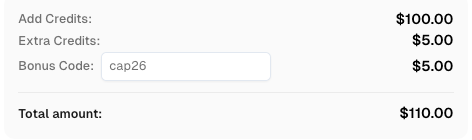
CapSolverにサインアップする際、コード
CAP26を使用してボーナスクレジットを取得してください!
CAPTCHAを自動的に解決する
ヘッダーとプロキシが完璧でも、最終的にはチャレンジに遭遇します。これは、専門的なサービスが非常に価値がある場面です。たとえば、CapSolverは、ReCaptchaやFriendlyCaptchaなどのさまざまなチャレンジを解決する強力なAPIを提供し、自動ワークフローが途切れることなく運用されるようにします。これらのツールは、現代の環境でウェブスクレイピングブロックを処理するためのコアな要素です。
cURLやPythonなどのツールを使用している場合、以下のような一般的なワークフローに従って解決策を統合できます。
- タスクを送信する: CAPTCHAの詳細(サイトキー、URL)をサービスに送信します。
- 解決策を取得する: タスクIDを使用してAPIをポーリングし、解決策が準備できるまで待ちます。
- トークンを送信する: 送信されたトークンを使用して、ターゲットサイトのチャレンジをバイパスします。
CapSolverのドキュメントに基づいた簡略化された例を以下に示します:
json
{
"clientKey": "YOUR_API_KEY",
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": "https://www.example.com",
"websiteKey": "6LcR_okUAAAAAPYrPe-z_bx1oYxq6zz_S0vO49zV"
}
}スクレイピング技術の比較概要
正しいアプローチを選ぶために、一般的な方法の比較を以下に示します。
| 方法 | 効果性 | 実装の複雑さ | コスト |
|---|---|---|---|
| 基本的なヘッダー | 低 | 低 | 無料 |
| データセンターのプロキシ | 中 | 中 | 低 |
| 住宅プロキシ | 高 | 中 | 中程度 |
| ヘッドレスブラウザ | 高 | 高 | 高(リソース) |
| CAPTCHAソルバー | 必須 | 低 | 低 |
倫理的およびコンプライアンス上の考慮事項
ウェブスクレイピングブロックを処理する方法を学ぶ際、倫理的な取り組みを強調することが不可欠です。自動データ収集は、ターゲットウェブサイトの利用規約とサーバーの健全性を尊重する形で行われるべきです。常にドメインのrobots.txtファイルをチェックし、制限されている領域を確認してください。これらのウェブスクレイピングベストプラクティスを守ることで、法的な保護だけでなく、データソースの持続可能性も確保できます。
さらに高度なツールを探している人には、最高のデータ抽出ツールを探索することをお勧めします。これにより、耐障害性の高いシステムを構築するための追加の洞察を得ることができます。
解決策への自然な移行
ボット検出技術が進化するにつれて、スクリパーの維持の複雑さが増しています。多くの開発者は、なぜウェブオートメーションがCAPTCHAで失敗し続けるのかが、特定の取り組みがないためであると気づきます。最高のCAPTCHAソルバーを使用することで、破損したスクリプトを常に修正するのではなく、データ分析に集中できます。これらのプロフェッショナルなサービスをスタックに統合することで、最も保護されたプラットフォームでも高い成功確率を確保できます。
結論
ウェブスクレイピングブロックを処理するには、技術的な正確さと倫理的な責任を組み合わせた多層的なアプローチが必要です。検出ロジックを理解し、堅牢なプロキシ管理を実装し、専門的な解決サービスを使用することで、信頼性の高いデータパイプラインを構築できます。単一の障壁を乗り越えることではなく、デジタルエコシステムを尊重しながらビジネスに必要なインサイトを提供する持続可能なシステムを構築することを目指してください。
FAQ
1. プロキシを使用しているにもかかわらず、なぜブロックされているのですか?
ブラウザのファイントプリントや一貫性のないヘッダーが原因である可能性があります。User-Agentがプロキシの認識された場所と一致していることを確認し、WebRTCを通じて実際のIPが漏洩していないか確認してください。
2. ウェブスクレイピングブロックを回避することは合法ですか?
これはあなたの管轄区域と収集しているデータの種類に依存します。一般的に、公開されているデータをスクレイピングすることは合法ですが、著作権や個人データ保護法を尊重する必要があります。
3. User-Agentをどのくらいの頻度でローテーションすべきですか?
新しいセッションごと、または数回のリクエストごとに新しいUser-Agentを使用するのが最善です。特にIPアドレスをローテーションしている場合は特にそうです。
4. ヘッドレスブラウザはすべてのブロックを防ぐことができますか?
役に立ちますが、PuppeteerやPlaywrightなどのヘッドレスブラウザは、特定のプロパティを介して検出される可能性があります。自動化された性質を隠すために「ステルス」プラグインを使用する必要があります。
5. CAPTCHAを処理する最もコスト効率の良い方法は何ですか?
CapSolverなどのAPIベースの解決サービスを使用することは、自前のMLモデルを構築するか、手作業を用いるよりもコスト効率が良いです。これは、タスクあたりの低コストで高速かつ正確な解決を提供するためです。
もっと見る
The Other CAPTCHAMay 15, 2026
高速なCAPTCHA解決API:自動化ワークフロー向け
自動化向け高速CAPTCHA解決API: トークンワークフローを比較、サポートされているチャレンジ、レイテンシチェック、およびCapSolverの適切な統合。

The Other CAPTCHAApr 03, 2026
CAPTCHAを解くAPIの応答時間について説明します: スピードとパフォーマンスの要因
CAPTCHA解決APIの応答時間、自動化への影響、速度に影響を与える重要な要因を理解してください。パフォーマンスを最適化する方法を学び、迅速なCAPTCHA解決のために効率的なソリューションを活用する方法を学びましょう。
