Python でデータ抽出のために reCAPTCHA v2 ソリューションを統合する方法

Anh Tuan
Data Science Expert
はじめに
インターネットの成長に伴い、Webスクレイピングとデータ抽出は、ビジネスインテリジェンス、コンテンツアグリゲーション、市場分析など、さまざまな目的でウェブサイトから情報を収集するために広く使用されています。しかし、ボットがより洗練されていくにつれて、ウェブサイトは人間のユーザーと自動プログラムを区別するためのツールを実装しました。このようなツールの1つがreCAPTCHAです。このブログでは、reCAPTCHAとは何か、利用可能なさまざまなバージョン、そしてCapsolverを使用してPythonでreCAPTCHA v2の課題を解決する方法について説明します。最後に、reCAPTCHA v2をデータ抽出プロジェクトに統合するための簡単なコード例を紹介します。
reCAPTCHAとは?

reCAPTCHAはGoogleが開発した無料のサービスであり、自動化されたボットではなく、実際の人間がサイトとやり取りしていることを確認することで、ウェブサイトをスパムや不正行為から保護するのに役立ちます。reCAPTCHAを実装したウェブサイトにユーザーがアクセスすると、人間であることを確認するために課題を完了する必要がある場合があります。
reCAPTCHAのさまざまなバージョン
reCAPTCHAには、それぞれ長所とユースケースが異なる、いくつかのバージョンがあります。
-
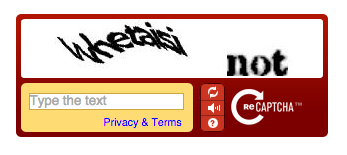
reCAPTCHA v1: 最初のバージョンで、現在は非推奨になっています。ユーザーは画像から歪んだテキストを書き写す必要がありました。
-
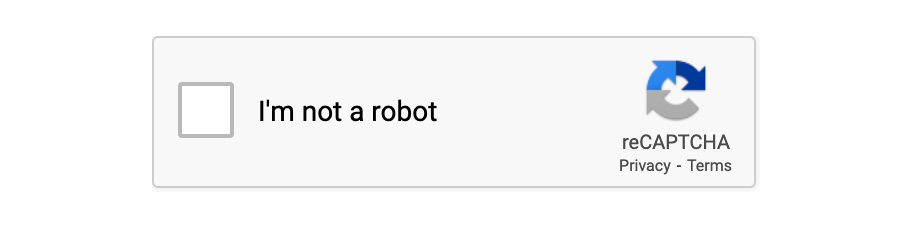
reCAPTCHA v2: ユーザーにチェックボックス(「私はロボットではありません」)を表示する、より高度なバージョンです。必要に応じて、特定の画像(信号機や横断歩道など)を選択する課題も提示されます。このバージョンは、今日最も一般的に使用されています。
-
reCAPTCHA v3: このバージョンは、ユーザーの行動とウェブサイトとのやり取りを分析して、0から1までのスコアを割り当てます。ここで、0はボットを示し、1は人間を示します。対話型チャレンジを必要としないため、ユーザーにとってよりシームレスです。

-
Invisible reCAPTCHA: このバージョンはバックグラウンドで動作し、疑わしいアクティビティが検出された場合にのみ課題を表示します。正当なユーザーに対しては目に見えないように設計されています。
データ抽出とは?

データ抽出とは、Webページ、データベース、その他のデジタル形式など、構造化されていないソースから構造化されたデータを抽出するプロセスです。これは、自動化されたプログラムが分析やアグリゲーションのためにウェブサイトから大量の情報を収集するWebスクレイピングで一般的に使用されます。
データ抽出の一般的なユースケース
-
市場調査: 企業は、競合他社の価格データや顧客レビューを抽出して、マーケティングおよび販売戦略を調整します。
-
ビジネスインテリジェンス: 組織は、財務報告書、ニュース、その他のリソースをスクレイピングして、情報に基づいたビジネス上の意思決定を行います。
-
コンテンツアグリゲーション: 複数のソースから情報をキュレートして表示するウェブサイトは、多くの場合、他のWebページからデータを抽出します。
-
SEO分析: 競合他社のウェブサイトからコンテンツ、キーワード、メタタグを抽出することで、SEO戦略の最適化に役立ちます。
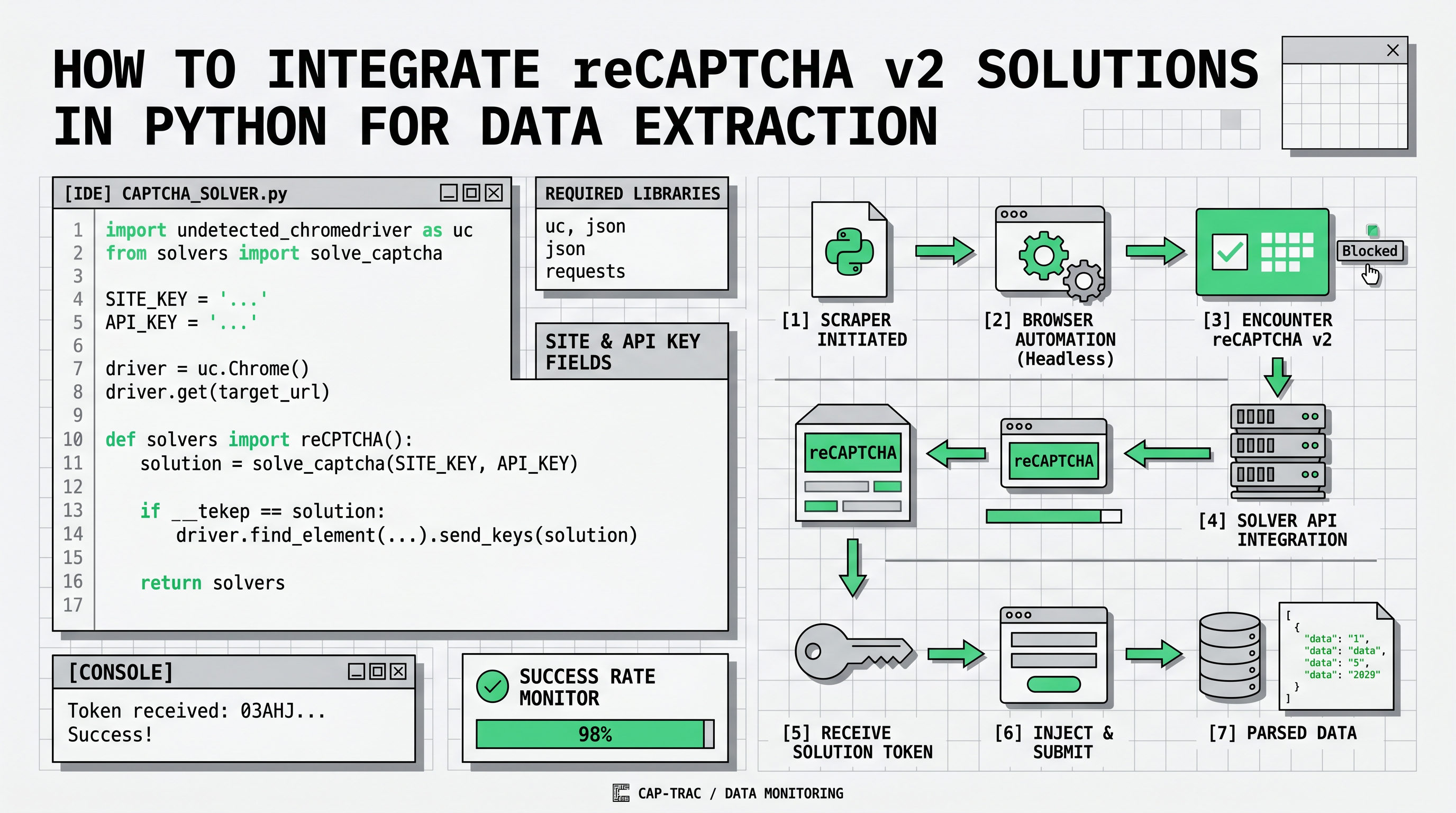
PythonでreCAPTCHA v2ソリューションを統合する
ウェブサイトからデータを抽出する際に、reCAPTCHAの課題に遭遇することがあります。これは、自動化されたスクレイピングにとって障害となります。幸いなことに、Capsolverなどのツールを使用すると、reCAPTCHA v2の課題をプログラムで解決することができ、データ抽出タスクを続けることができます。
以下は、Capsolverパッケージを使用してreCAPTCHA v2を解決するPythonの実装です。
ステップ:
-
次を実行して
capsolverライブラリをインストールします。bashpip install capsolver -
reCAPTCHA v2の課題を解決するために、次のPythonコードを使用します。
python
import capsolver
# 機密情報には環境変数を使用することを検討してください
capsolver.api_key = "Your Capsolver API Key"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": url,
"websiteKey":key,
})
return solution
def main():
print("Solving reCaptcha v2")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("Solution: ", solution)
if __name__ == "__main__":
main()コードの説明
-
Capsolver APIの設定: コードでは、
capsolver.api_keyを定義します。これには、Capsolver APIキーが含まれている必要があります。このキーは、Capsolverサービスへのリクエストを認証します。 -
解決関数: 関数
solve_recaptcha_v2は、ページのurlとsite_key(ウェブサイトにあるreCAPTCHAキー)を受け取ります。これは、CapsolverにreCAPTCHAの課題を解決するようにリクエストを送信します。 -
メイン関数: メイン関数はソルバーを実行し、ソリューションを出力します。
-
環境変数: APIキーなどの機密情報は、セキュリティを強化するために環境変数を使用して格納することをお勧めします。上記の例では、「Your Capsolver API Key」、「PAGE_URL」、「PAGE_SITE_KEY」を実際の値に置き換える必要があります。
ボーナスコード
最高のCAPTCHAソリューションのボーナスコードを取得しましょう。CapSolver: scrape。引き換え後、チャージごとに5%のボーナスを追加で獲得できます。無制限

詳細については、ブログをご覧ください。
まとめ
reCAPTCHAは、ウェブサイトをボットから保護するための不可欠なツールですが、データ抽出などの正当な自動化の目的では課題となる可能性があります。Capsolverなどのツールを使用すると、開発者はreCAPTCHA v2の課題をプログラムで解決できるため、データ抽出を中断せずに続けることができます。データ抽出活動がウェブサイトの利用規約と法的ガイドラインに準拠していることを常に確認して、問題を回避してください。
上記のソリューションをPythonプロジェクトに統合することで、reCAPTCHAの障害を克服しながら、ウェブサイトから貴重なデータを収集し続けることができます。
もっと見る
reCAPTCHAApr 16, 2026
reCAPTCHA 無効なサイトキーまたはトークン? 原因と解決方法のガイド
「reCAPTCHA 無効なサイトキー」や「無効なreCAPTCHAトークン」のエラーに直面していますか?一般的な原因、ステップバイステップの修正手順、トラブルシューティングのヒントを確認してください。reCAPTCHAの検証失敗の問題を解決する。reCAPTCHAの検証失敗を修正する方法を学びましょう。もう一度試してください。

reCAPTCHAMar 25, 2026
reCAPTCHA v2を解く方法 PythonとAPI
PythonとAPIを使用してreCAPTCHA v2を解決する方法を学びましょう。この包括的なガイドでは、プロキシとプロキシレスな方法をカバーし、自動化に使用可能な本番環境対応のコードを提供しています。


