Puppeteerがボットとして検出されましたか? 修正方法は?

Sora Fujimoto
AI Solutions Architect
TL;DR
- Puppeteerがボットとして検出された場合の対処法では、ブロッカーがブラウザの指紋検出、ネットワークの評判、セッションの変動、アクションのタイミング、またはCAPTCHAチャレンジであるかどうかを特定することが最初のステップです。
- PuppeteerはChromeまたはFirefoxをChrome DevToolsプロトコルまたはWebDriver BiDiを通じて制御し、デフォルトでヘッドレスモードで動作するため、一部のサイトではセッションの分類に影響を与える可能性があります。
- 検出の兆候には、403ページ、CAPTCHAループ、ログイン失敗、空の検索結果、遅延するリダイレクト、手動ブラウジングとは異なるようにレンダリングされるページが含まれます。
- 責任ある対処法には、永続的なプロファイルの使用、安定したプロキシルーティング、現実的なペーシング、環境の一致、ログの明確化、および許可されたワークフローでのCAPTCHA処理の文書化が含まれます。
- 法的で許可された使用ケースにおいて、CapSolverはCAPTCHAが多いためのPuppeteerの自動化をサポートします。
イントロダクション
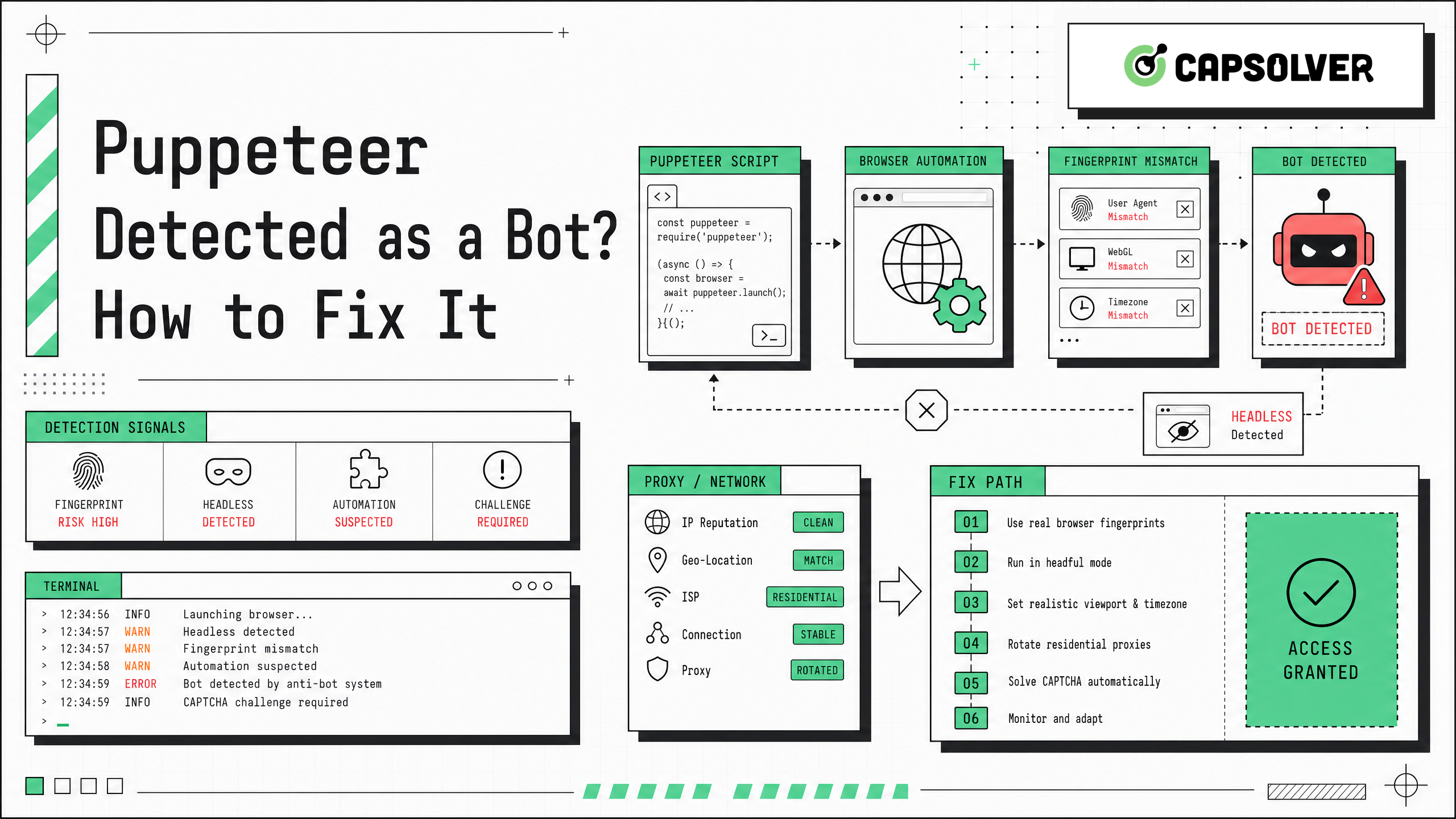
Puppeteerがボットとして検出された場合の対処法は、多くの自動化プロジェクトがローカルスクリプトで動作し、実際のウェブサイトで失敗するため、一般的な質問です。問題はたいてい1つの設定ではありません。ウェブサイトはブラウザのプロパティ、リクエスト履歴、アカウントの信頼性、IPの評判、JavaScriptの動作、およびチャレンジの結果を一緒に評価します。Puppeteerのドキュメント自体では、ChromeまたはFirefoxをChrome DevToolsプロトコルまたはWebDriver BiDiを通じて制御するJavaScriptライブラリとして、PuppeteerはデフォルトでPuppeteerの公式ドキュメントを通じてヘッドレスモードで動作すると説明されています。CAPTCHAが多いためのワークフローでは、CapSolverがサポートされるチャレンジに役立ちますが、より広範な対処法はクリーンな自動化プロファイルから始まります。
Puppeteerが検出される意味
Puppeteerがボットとして検出された場合の対処法は、すべてのサイトがPuppeteerを名前で識別しているわけではありません。これは通常、サイトがセッションをより高いリスクカテゴリに分類したことを意味します。そのカテゴリはCAPTCHA、ソフトブロック、HTTP 403応答、ログインループ、またはデータを静かに非表示にするページを生成する可能性があります。目に見える兆候は、いくつかのチェックの最終的な結果に過ぎません。
Puppeteerは、開発者がブラウザナビゲーション、DOMの相互作用、スクリーンショット、PDF、ネットワークアクティビティを直接制御できるため人気があります。これはQA、モニタリング、コンテンツテスト、および許可されたデータワークフローに役立ちます。しかし、クリーンなブラウザプロファイル、高速な繰り返しのアクション、クラウドIP範囲、およびセッションの継続性の欠如は、本番システムでは異常に見える可能性があります。
正しい対応は、ランダムな起動フラグを変更して何かが通るまで待つことではありません。正しい対応は、環境を測定することです。チームは、手動ブラウジング、ローカルPuppeteer、CI Puppeteer、および本番インフラストラクチャを比較する必要があります。これらの環境が異なる場合、検出信号はしばしば明確になります。
Puppeteerがブロックされる主な理由
Puppeteerがボットとして検出された場合の対処法の最も一般的な理由は、自動化環境が通常の戻りブラウザのように見えないことです。Puppeteerはデフォルトでヘッドレスモードで動作し、多くのスクリプトは新しいコンテキスト、繰り返しのナビゲーションパス、および高速なアクションを使用します。リスク制御に調整されたサイトは、そのパターンをチャレンジする可能性があります。
| シグナルグループ | 一般的な兆候 | 対処方向 |
|---|---|---|
| ブラウザモード | 手動で動作するがヘッドレス実行では失敗 | ヘッド付きとヘッドレスのトレースを比較し、ビューポート、ロケール、タイムゾーン、および権限を一致させる |
| セッション状態 | すべての実行が新しい訪問者のように見える | テストアカウントと許可されたワークフローで許可されたクッキーとストレージ状態を永続化 |
| ネットワーク評判 | CIまたは特定のプロキシプールでのみブロックが表示される | 安定したルーティングを使用し、過度なローテーションを避けて、ブラウザからの送出IDを検証する |
| 交換パターン | フォームが即座に送信されるか、ナビゲーションが線形すぎる | ユーザーが見える準備が整うのを待って、ページフローに応じてアクションのペースを調整する |
| チャレンジ処理 | CAPTCHAが表示されるがスクリプトが期待されるページ状態を完了できない | チャレンジタイプを特定し、文書化された、許可されたソルバーワークフローのみを統合する |
Puppeteerがボットとして検出された場合の対処法は、スケールで実行されるスクリプトにとって特に重要です。ローカルテストでは1つのIPと1つのアカウントを使用するかもしれませんが、本番ジョブでは多くのブラウザコンテキスト、並列ワーカー、および一時的なセッションを使用する可能性があります。この変化自体が、より厳格なトラフィック検証をトリガーする可能性があります。
まず確認すべきブラウザ自動化シグナル
ブラウザセッションにはユーザーエージェント文字列以上のシグナルが含まれます。サイトはビューポート、デバイススケールファクター、言語の好み、タイムゾーン、WebGLの動作、権限のプロンプト、ストレージの利用可能性、メディアデバイス、フォント、およびナビゲーションタイミングを検証する可能性があります。個々の値が無害に見える場合でも、不一致な組み合わせは疑いを引き起こす可能性があります。
Chrome DevToolsプロトコルは重要です。Puppeteerはブラウザのデバッグと自動化チャネルを通じてChromeを制御できるためです。公式のCDPドキュメントでは、プロトコルがChromiumとChromeをインストルメント、インスペクト、デバッグ、プロファイリングするツールを許可し、ブラウザターゲット、WebSocketデバッガーURL、およびプロトコルメタデータを説明しています。Chrome DevToolsプロトコルドキュメント。開発者はこのアーキテクチャを理解する必要があります。デバッグエンドポイント、ブラウザフラグ、およびセッションのセットアップは、ページが観測するものを影響する可能性があります。
Puppeteerがボットとして検出された場合の対処法は、失敗したページのトレースから始める必要があります。正確な応答コード、スクリーンショット、最終URL、コンソールエラー、タイミング、チャレンジページを記録してください。ブロックがJavaScriptアクションの前に発生した場合、ネットワークまたは初期指紋シグナルがおそらく原因です。フォーム送信後に発生した場合、インタラクションの動作またはアカウントの信頼性がトリガーになる可能性があります。
高度な設定を変更する前にセッションの連続性を修正する
セッションの連続性は最も見過ごされがちな修正です。すべてのタスクで新しいブラウザプロファイルを起動するスクリプトは、サイトにすべての訪問が初めての訪問であることを伝えます。クリーンなデバイスから1時間に何回もログインするテストアカウントでは、これは異常に見える可能性があります。モニタリングされている公開ページでは、繰り返しの新規訪問が安定したプロファイルよりも早くチャレンジシステムをトリガーする可能性があります。
より良いパターンは、ポリシーが許す限り許可されたクッキーとストレージ状態を永続化することです。所有するプロパティでは、専用のテストアカウントとステージング環境を作成してください。公開サイトでは、利用規約、ロボットのガイドライン、および現地の法律に従ってください。CapSolverのウェブスクレイピングのFAQとウェブスクレイピングの法的ガイドは、法的アクセスと技術的アクセスが同じではないため、役立つ参考になります。
Puppeteerがボットとして検出された場合の対処法は、アカウントレベルの思考も必要です。同じアカウントが多くのIP、デバイス、および地域から表示されると、アカウント自体が問題になる可能性があります。各アカウントを現実的な地理とセッションパターンに結びつけてください。これは検出の実践だけでなく、信頼性の実践です。
ネットワークとプロキシ構成が結果を決定する
多くのPuppeteerの問題はネットワークの問題です。クラウドデータセンターのIP、過負荷のプロキシ、地域の不一致、認証の失敗、および急速なIPローテーションは、ブラウザ検出と同じ症状を引き起こす可能性があります。サイトがブラウザの詳細な動作を評価する前に、トラフィックの評判によってCAPTCHAまたは403ページを表示する可能性があります。
実際のPuppeteerページから送出IPを確認してください。地域、ASN、DNSの動作、およびプロキシがセッション中に変化するかどうかを確認してください。スクリプトが1つのルートでログインし、別のルートでフォームを送信すると、セッションがチャレンジされる可能性があります。CapSolverのプロキシ設定リソースは、プロキシ、ブラウザ、およびCAPTCHA処理を組み合わせた自動化ワークフローで関連しています。
Puppeteerがボットとして検出された場合の対処法は、チームが並列処理を減らすことで改善することがよくあります。1つのワーカー、1つのアカウント、1つのプロファイル、1つの安定したルートから始めます。フローが信頼性があることを確認した後、徐々にボリュームを増やし、チャレンジが戻る場所を観察してください。これにより、リスクシグナルが観測可能になります。
PuppeteerワークフローでのCAPTCHA処理
CAPTCHAは通常、チェックポイントであり、元の原因ではありません。サイトが即座にCAPTCHAを表示する場合、ネットワークの評判とブラウザコンテキストを確認してください。繰り返しの検索後に表示される場合、レートとペーシングを確認してください。アカウント作成やチェックアウト時に表示される場合、それは予期されるリスク制御パスの一部である可能性があります。CapSolverのCAPTCHA解決のFAQは、これらのワークフローの一般的な基盤を提供します。
許可されたPuppeteerワークフローでCAPTCHA処理が必要な場合、コードを書く前にチャレンジタイプを特定してください。いくつかのタスクではreCAPTCHAを使用し、他のタスクでは画像CAPTCHAを使用し、一部ではCloudflare Turnstileまたは他のトラフィック検証システムを使用します。CapSolverにはPuppeteer関連のリソースがあり、Puppeteerの統合、PuppeteerでのCAPTCHA処理、CAPTCHAパラメータの識別が含まれます。
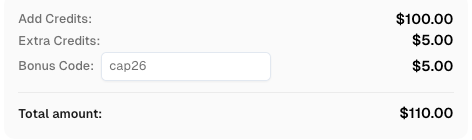
CapSolverのボーナスコードを取得する
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、すべてのチャージで5%のボーナスが追加されます — 限度はありません。
今すぐCapSolverダッシュボードで取得してください
ソルバーを良い自動化の衛生状態の代替として扱わないでください。正しいワークフローには、許可、合理的なトラフィック、安定したセッション、およびクリーンな観測性が必要です。CAPTCHA処理は、より広範なコンプライアンスシステムにおける狭い統合ステップでなければなりません。
Puppeteerの責任ある修正チェックリスト
Puppeteerがボットとして検出された場合の対処法は、繰り返し可能なチェックリストで対処できます。まず、同じマシンとネットワークから手動でテストしてください。次に、headedモードでPuppeteerを実行し、スクリーンショットを比較してください。次に、ビューポート、ロケール、タイムゾーン、権限、およびブラウザバージョンを一致させます。次に、許可されたセッション状態を永続化します。次に、並列処理を減らし、ページの準備に応じてアクションのペースを調整します。次に、ブラウザ内のプロキシとDNSの動作を検証してください。最後に、チャレンジが予期され、サポートされている場合にのみCAPTCHA処理を追加してください。
Chromeの設定もプロファイルの一部です。ChromeDriverの能力ドキュメントでは、ブラウザセッションがカスタムプロファイル、プロキシ能力、拡張機能、モバイルエミュレーション、ウィンドウサイズ、およびChrome固有のオプションで構成できることを示しています。ChromeDriver能力ドキュメント。Puppeteerには異なるAPIがありますが、原則は同じです:ブラウザ起動の設定はワークフローに合わせる必要がありますが、一般的なデフォルトではなくてです。
最後に、説明できないワンショットの修正を避けてください。文書化されていないフラグのコレクションの後にワークフローが通る場合、保守が難しくなります。より良いPuppeteerシステムでは、すべての選択が明確になります:なぜこのプロファイル、なぜこのプロキシルート、なぜこの待機条件、なぜこのCAPTCHAフロー、なぜこのレートリミットなのか。
結論
Puppeteerがボットとして検出された場合の対処法は、フルスタックの自動化問題として解決するのが最善です。Puppeteerは実際のブラウザエンジンを制御しますが、検出はブラウザ状態、ネットワーク評判、セッション履歴、速度、アカウント行動、またはチャレンジ処理から来る可能性があります。証拠から始め、ブラウザプロファイルを安定させ、セッションを一貫させ、合理的なトラフィックパターンを使用し、法的およびサイトルールを尊重してください。CAPTCHAチャレンジが許可されたワークフローの一部である場合、CapSolverはチームが文書化されたチャレンジ処理を統合するのを支援し、Puppeteerを信頼性があり、保守可能な状態に保つことができます。
FAQ
Chromeをインストールしているにもかかわらず、Puppeteerがボットとして検出されるのはなぜですか?
Chromeをインストールしているだけでは不十分です。サイトはブラウザモード、プロファイル履歴、クッキー、ネットワーク評判、タイミング、およびアカウント行動を評価する可能性があります。環境が毎回新規に開始されるか、または速すぎると、Puppeteerは依然として異常に見える可能性があります。
ヘッドレスPuppeteerからヘッド付きPuppeteerに切り替えるべきですか?
ヘッド付きモードはデバッグと比較に役立ちますが、完全な解決策ではありません。ヘッド付きモードでも検出が続く場合、セッションの連続性、プロキシの評判、地域の一致、およびアクションタイミングを確認してください。
CapSolverはPuppeteerの検出を修正できますか?
CapSolverは、法的で許可されたワークフローでサポートされるCAPTCHAチャレンジに役立ちます。すべての検出原因を修正するわけではありません。ブラウザの設定、プロキシ、アカウント、ペーシング、およびコンプライアンスは依然として適切に処理する必要があります。
Puppeteerがブロックされた場合に最初に確認すべきことは何ですか?
ブロックがどこで発生するかを確認してください。最初のリクエストで表示される場合、ネットワークとブラウザの指紋シグナルを検証してください。いくつかのアクション後に表示される場合、タイミング、アカウント状態、およびボリュームを検証してください。CAPTCHAページで表示される場合、チャレンジタイプを特定してください。
Puppeteerはウェブ自動化に許可されていますか?
Puppeteerは正当なブラウザ自動化ライブラリです。テスト、モニタリング、および許可された自動化に使用してください。プライベート、制限付き、機密、または許可されていないデータへのアクセスには使用しないでください。