エージェンティックブラウザ:ブラウザが能動的に働き始めるとき

Sora Fujimoto
AI Solutions Architect

はじめに
こんなシナリオを想像してください。1時間かけて飛行機の予約をし、価格を繰り返し比較し、フォームを埋めています。一方、アジェンティックブラウザは、1つのコマンドで数分でそのタスクを完了します。「北京から上海へのこの金曜日の午後に窓側の座席を予約してください。」これはもはや単なる表示ツールではなく、意図を理解し、タスクを自律的に実行できる知的なエージェントです。過去2年間、このコンセプトは製品化に向かって進展しており、Google ChromeはAuto Browseをリリースし、OperaはOpera Neonをリリースしました。この記事では、アジェンティックブラウザがどのように機能するのか、そしてCapSolverのようなインフラストラクチャがこのエコシステムにおいて果たす重要な役割について紹介します。
第1章: ブラウザの再構築—「表示ツール」から「アクションエージェント」へ
1.1 伝統的なブラウザの役割と限界
1990年代に登場して以来、ブラウザのコアな使命は「情報の表示とインタラクション」でした。これは本質的に受動的なレンダリングエンジンであり、ユーザーが指示を入力し、ブラウザがDomを解析して視覚的なフィードバックを返します。この「人間が機械を操作する」一方向的なモードにおいて、ブラウザはデジタル世界への「窓」として忠実に機能しています。
しかし、ウェブアプリケーションが指数関数的に複雑化するにつれて、伝統的なブラウザの限界がますます顕著になっています:
- 過度な認知的負荷: ユーザーは膨大なタブ、ポップアップ、ネストされたメニューの中からターゲットを見つける必要があります。タスクの完了よりも「ボタンを探すことに多くのエネルギーを費やす」ことになります。
- 繰り返し操作の自動化の不可: 高頻度のシナリオとして、クロスプラットフォームのデータ移行、一括フォーム入力、マルチステップの承認などは、依然として手動でのコピー&ペーストや面倒なスクリプト設定に依存しています。
- コンテキストの断片化: ブラウザはあなたが「今何をしていたか」や「次に何をしたいか」を覚えていません。各インタラクションは孤立したイベントであり、タスクレベルの継続的な記憶がありません。
- セキュリティと体験の矛盾: ボットのスパムを防ぐために、ウェブサイトは大量のCAPTCHAs、ボットチェック、動的読み込みを導入し、人間ユーザーの操作摩擦をさらに高めています。
伝統的なブラウザの欠点をより明確に比較するため、以下の表のようにインタラクションモード、タスク理解、プロセスの連続性などの次元で整理できます:
| 次元 | 伝統的なブラウザ | 主な課題/限界 |
|---|---|---|
| インタラクションモード | マウス/キーボード駆動、ポイントバイポイント操作 | 操作の断片化、効率の低さ |
| タスク理解 | URLとDOM構造のみを解析、意図認識なし | 自然言語指示を処理できない |
| プロセスの連続性 | 状態無し; 複数ページ/サイト間の操作には手動で接続が必要 | コンテキストの喪失、マルチステップタスクが簡単に中断される |
| 自動化能力 | プラグインや外部スクリプトに依存 (例: Selenium) | 高い設定のハードル、干渉耐性が弱い |
| 環境認識 | 静的レンダリング、視覚的な意味を理解できない | 動的コンテンツ、CAPTCHAs、アンチスクレイピングメカニズムに無力 |
表1-1: 伝統的なブラウザの性能と限界
全体的に見れば、伝統的なブラウザは「指示に従ってコンテンツを表示する」ことは得意ですが、「タスクを理解し、能動的に支援する」ことは不得意です。この受動的、断片的、状態無しの性質が、アジェンティックブラウザが解決しようとするコア問題です。
1.2 アジェンティックブラウザの定義: あなたのために「行動」するブラウザ
アジェンティックブラウザは伝統的なブラウザに機能を追加しただけのものではありません。LLMとブラウザのコアが深く統合された次世代のインタラクション端末です。そのコア的な定義は次の通りです: 意図理解、環境認識、自律的な計画と実行能力を持つデジタルアクションエージェント。
伝統的なブラウザが「見ているスクリーン」であるなら、アジェンティックブラウザは「あなたのために働くデジタル従業員」です。ユーザーがステップバイステップでクリックを待つ必要はもうありません。例えば、「先週のミーティングの録音を転記し、要約してプロジェクトチームに送信してください」という自然言語の指示を受け取ります。その後、ブラウザ環境でアプリケーションを開き、ファイルを探し、AIツールを呼び出し、ドキュメントを編集し、メールを送信するなどの一連の操作を自律的に完了します。
その下部の動作は完全なエージェントアーキテクチャに依存しています。図1-1はこのアーキテクチャのコアモジュールとデータフローを直感的に示しています:
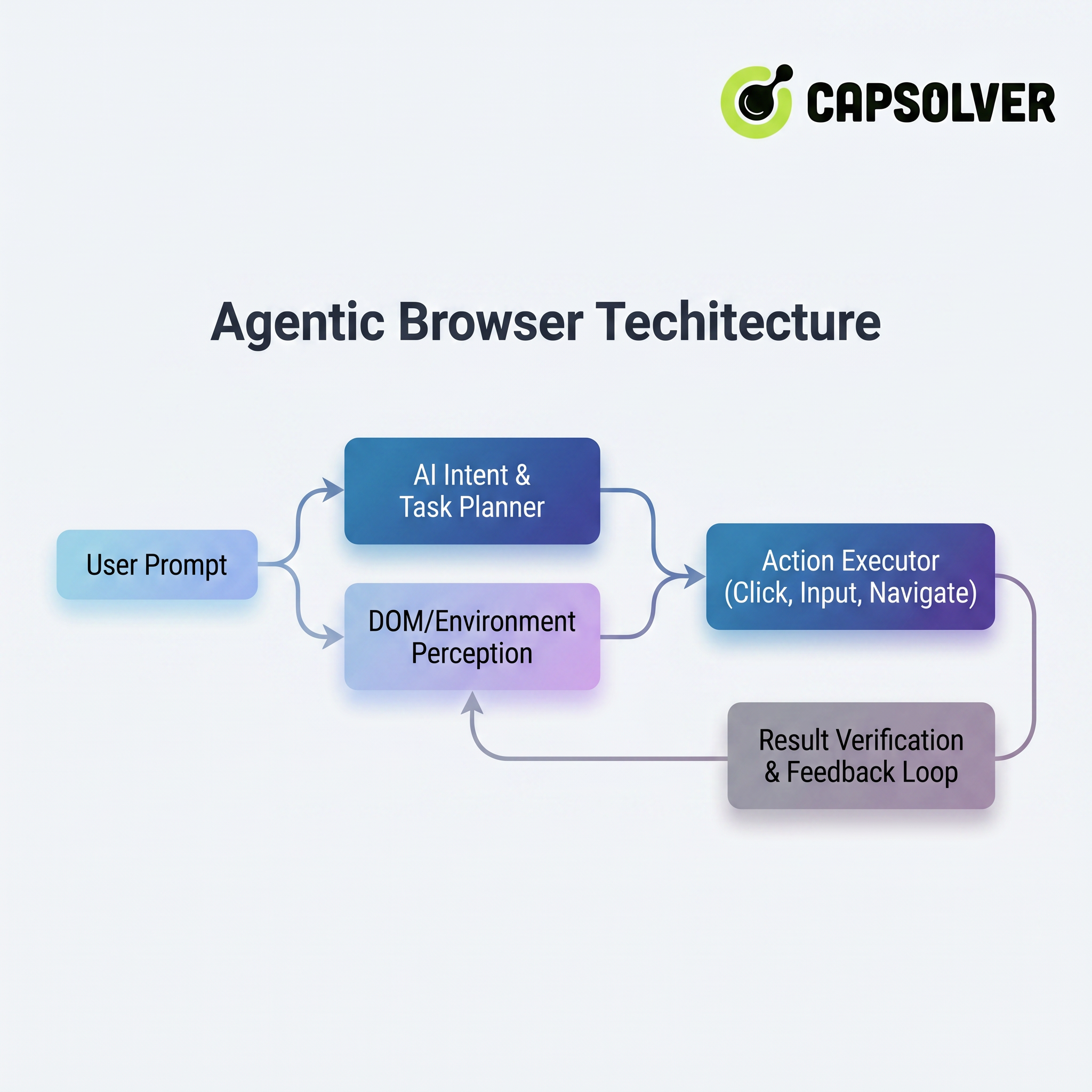
アーキテクチャは上から下へ4つの主要なレイヤーから構成されています(またはプロセス順):
- AI意図とタスクプランナー: 模糊な自然言語を実行可能な原子的な操作シーケンスに分解し、潜在的な経路の分岐を予測します。
- DOM/環境認識: ページ構造をリアルタイムで「読み取り」、マルチモーダルの視覚認識と組み合わせてボタンの機能、フォームの意味、ページ状態の変化を理解します。
- アクションエクセキューター: ブラウザ自動化プロトコルを通じて人間の操作(クリック、タイプ、スライド、ファイルアップロードなど)を正確にシミュレートし、安全に外部APIを呼び出します。
- 結果検証とフィードバックループ: 各ステップの結果が期待に沿っているかを自動的に検証します。エラーまたはページ変更が発生した場合、戦略を動的に調整し、再試行することで「自己修正」を実現します。
このアーキテクチャを通じて、アジェンティックブラウザはユーザーのマクロな意図をブラウザのマイクロ操作に変換し、本当に「あなたが一言言うだけで、それを行う」コンセプトを実現します。
1.3 受動から能動へ: ブラウザのパラダイムの根本的な転換
アジェンティックブラウザの登場は、人間とコンピュータのインタラクションのパラダイムにおいて根本的な飛躍を意味します。この転換は効率性だけでなく、コントロールとインタラクションロジックの再構築でもあります。
伝統的なモードでは、人間は機械のロジックに合わせて調整しなければなりません: 面倒なメニュー階層を学び、ショートカットを覚え、手動で異常なポップアップを処理します。アジェンティックモードでは、機械が人間のロジックに合わせて調整し始めます: 普通の指示を理解し、ユーザーの意図を予測し、アプリケーション間のタスクを能動的に調整します。
これらの2つのモードをより直感的に比較するため、以下の図は伝統的な受動的なブラウザとアジェンティックな能動的なブラウザのインタラクションロールの本質的な違いを示しています:
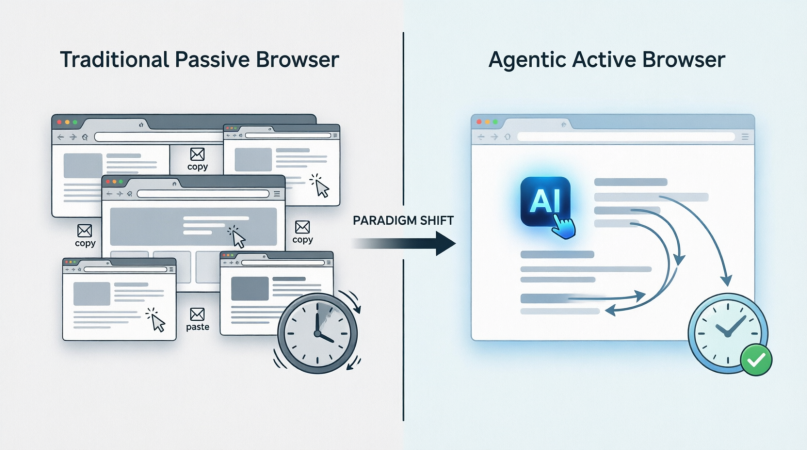
このパラダイムの転換は3つの主要な次元に現れます:
- 「指示駆動」から「目標駆動」へ: ユーザーは「どうするか(How)」ではなく「何をするか(What)」を定義するだけでよくなります。ブラウザは高レベルの目標を低レベルの操作チェーンにダウンスケーリングする責任を担います。
- 「静的インターフェース」から「動的コラボレーション」へ: ページは固定されたUIレイアウトではなく、「データストリーム」になります。AIがリアルタイムで解析、再構成、操作できます。アジェンティックブラウザは、異なるウェブサイトやシステムをスムーズに横断し、データの孤島を打ち破ります。
- 「手動フォールバック」から「インテリジェントな障害耐性」へ: ページの再設計、読み込み遅延、CAPTCHAのブロックに直面した場合、伝統的なスクリプトはクラッシュしますが、アジェンティックブラウザはコンテキストの推論能力を持ち、人間のように「別の方法を試す」ことができ、自動化プロセスの保守コストを大幅に削減します。
一般ユーザーにとって、これはブラウザが「時間の浪費ツール」から「時間の解放レバー」に変化することを意味します。ブラウザが能動的にあなたのために働き始めると、デジタルライフの焦点は本当に創造、意思決定、思考に戻ります。
第2章: アジェンティックブラウザはどのように動作するのか?
数秒間、シナリオを想像してください: アジェンティックブラウザに「EコマースサイトAでSony WH-1000XM5ヘッドホンを探して、ブラックを選択し、最安値の公式店を発見して、翌日配達で注文し、現金払いを選択してください」と伝えます。この1文は裏で複雑なイベントの連鎖を含んでいます。アジェンティックブラウザは「あなたのニーズを理解」し、それを実行可能なステップに分解し、「ページの内容を認識」し、「それに対して行動」し、ページ変更などの予期せぬ状況を処理する必要があります。
以下の図はこのプロセスを要約しています:
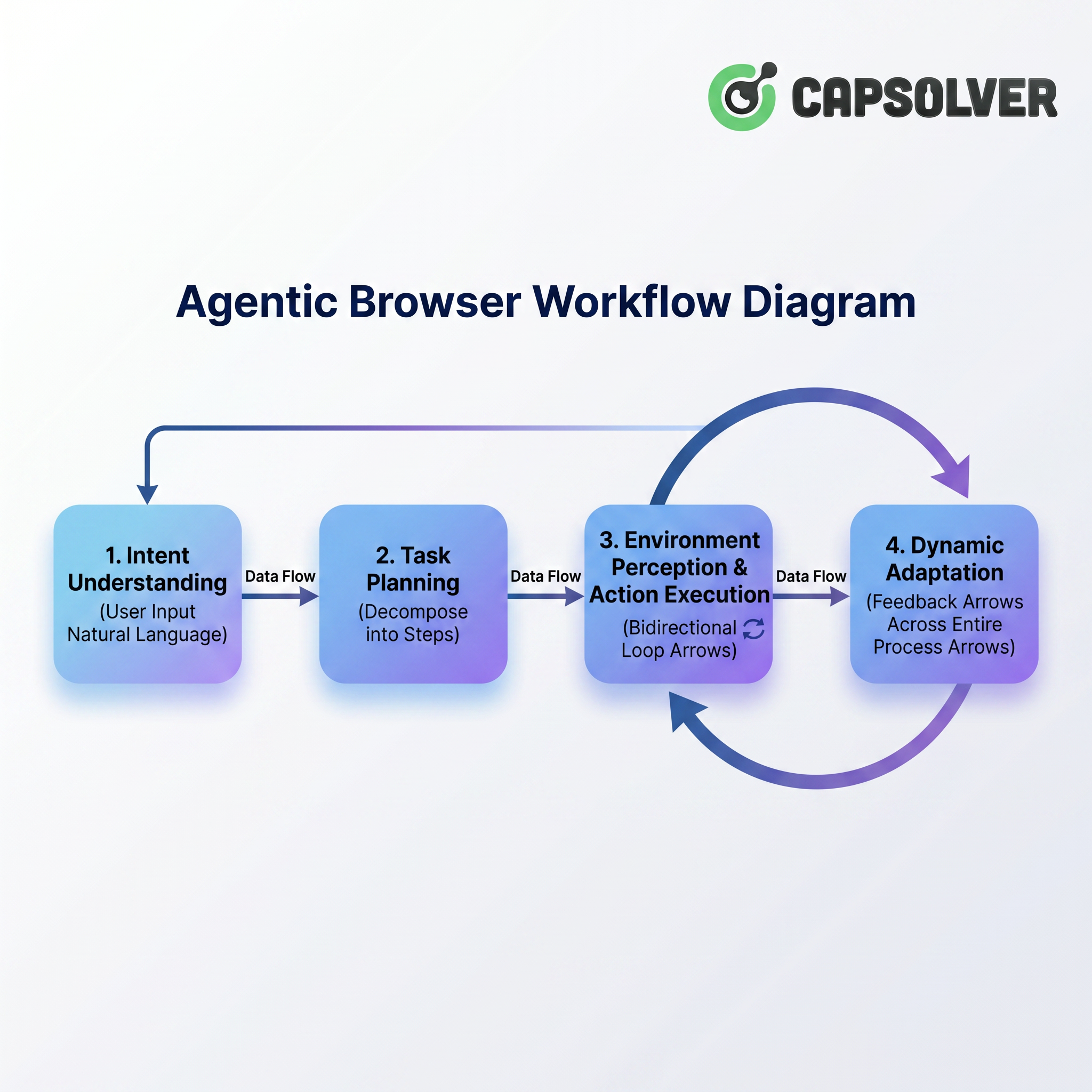
このプロセスはユーザーの自然言語指示から始まり、意図理解とタスク計画を経て、次に「環境認識とアクション実行」のコア段階に入ります。特に、環境認識とアクション実行の間には双方向のループがあります—アジェンティックブラウザはページ状態を観測しながら操作を実行し、実行結果に基づいて次のページ変更を継続的に認識します。一方で、「動的な適応」は全体を通してフィードバック矢印として走り、ポップアップ、CAPTCHA、ページ構造の変更に遭遇した際の戦略調整の柔軟性を確保します。次に、各段階を詳しく掘り下げて、アジェンティックブラウザが「理解し、認識し、行動し、適応する」仕組みを解説します。
2.1 意図理解: 自然言語からタスク計画へ
カジュアルな文がブラウザに投げかけられると、まず明確な構造を持つ「タスクリスト」に変換する必要があります。これは意図理解の段階です。
「ヘッドホンを購入してください」と伝統的なブラウザに伝えると、おそらくデフォルトの検索エンジンを開き、その言葉を正確にタイプするだけです。一方、アジェンティックブラウザは大規模言語モデル(LLM)を使用して深く解析します。その目的は検索ではなく、タスクの分解です。
前の例を用いると、AIは次の点を識別する必要があります:
- ターゲット製品: 「Sony WH-1000XM5ヘッドホン」
- 制約: 「ブラック」、「最安値」、「公式店舗」
- アクションチェーン: 製品を検索 → ブラックをフィルター → 価格でソート → 公式店を特定 → カートに追加 → 配送先住所を入力 → 配送方法を選択(翌日配達) → 支払い方法を選択(代金引換) → 注文を確認
- 隠れた依存関係: ユーザーはログインしている必要があり、アドレス帳に有効なアドレスがあること、支払い方法が代金引換を許可していることなど。
この分解プロセスは単純なテンプレートの適用ではなく、文脈の推論を必要とします。例えば、「翌日配達」に対応する物流オプションを特定し、製品がそれをサポートしているか確認する必要があります。最終的にタスク計画マップが生成されます。以下の図は、このタスクの完全な構造を意思決定木の形で示しています:
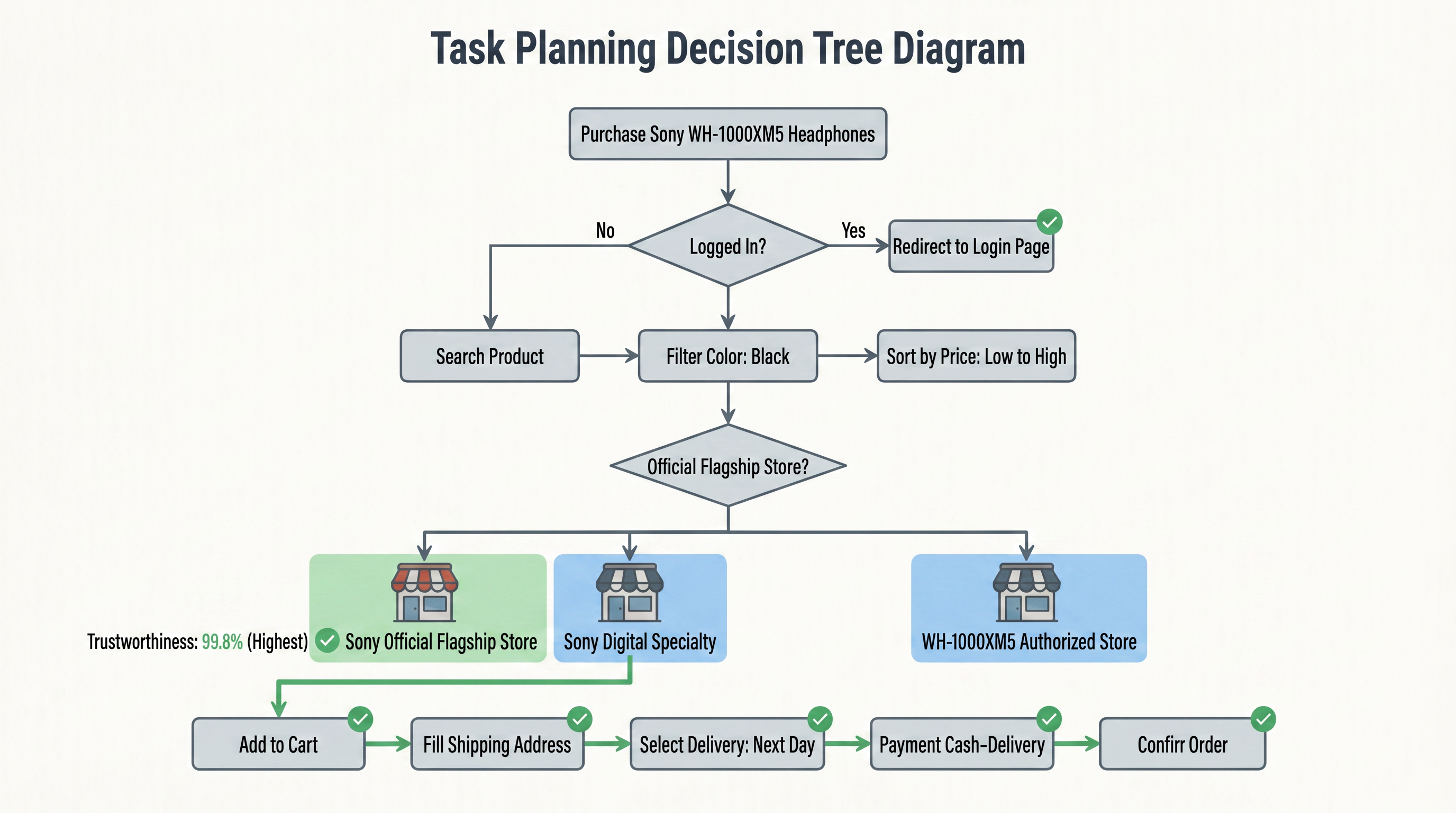
この意思決定木はユーザーの自然言語指示を実行可能な操作ツリーに変換します。「ヘッドホンを購入」のルートノードから始まり、各ステップで「はい」の枝に沿って段階的に詳細化し、各ステップには条件判断(例: 公式店かどうか、信用スコアの比較)と原子的なアクション(例: 検索、フィルター、入力)が含まれます。この構造化されたタスク計画により、ブラウザは「最初に何をすべきか、次に何をすべきか、分岐に遭遇した際の選択方法」を明確に知ることができます。この瞬間から、ブラウザは検索ボックスではなく、明確な目標を持ってウェブ世界に向かう実行者になります。
2.2 環境認識: AIがウェブを「見る」方法
計画が完了した後、AIが人間のようにカラフルなウェブページを「見る」ために次のステップが必要です。これは技術的に「環境認識」と呼ばれます。伝統的な自動化スクリプトは要素の位置指定(CSSセレクター、XPath)に依存しており、非常に脆弱です—ウェブページのクラスが変更されると、それらは失敗します。アジェンティックブラウザは、両目と触覚を持つように、マルチセンサー融合アプローチを使用します。
環境認識の3つのレベルは以下の表に要約されています:
| レベル | 説明 | 技術的実装 | 例 |
|---|---|---|---|
| DOM構造と意味解析 | ページのドキュメントオブジェクトモデルを読み取り、タグ、役割、テキストを抽出し、ARIAアクセシビリティラベルと組み合わせて要素の機能を理解します。 | HTML解析、意味ラベリング | 「これはボタンである」と「これは入力ボックスである」と識別でき、実際に「カートに追加」するアクションを含むdivを認識できます。 |
| ビジュアルスクリーンショットの理解 | 現在のビューポートのスクリーンショットを取得し、多モーダルモデルを使用してピクセルを解析し、人間の目のようにレイアウトと視覚的な関係を理解します。 | コンピュータビジョン、画像セグメンテーション | ボタンのHTMLタグが非標準でも、角が丸い、色のブロック、テキストを持つ限り、ボタンを特定できます。 |
| インタラクション状態の推論 | CSSスタイル、フォーカス状態、無効属性などにより、現在のコンポーネントの状態を判断します。 | スタイル分析、状態検出 | ボタンがグレーアウトしてクリック不可か、ハイライトされてクリック可能か、ドロップダウンメニューが折りたたまれているか展開されているかを確認できます。 |
表2-1: 環境認識の3つのレベル
これらの3つの認識は単独で動作するのではなく、同時に発生し、お互いに検証されます。図2-3はこの融合プロセスを直感的に示しています:

どの瞬間でも、アジェンティックブラウザはDOMツリー(構造)を読み取り、ヒートマップ(ビジュアル)を分析し、インタラクションボックス(インタラクション)をマークします。3つの要素が重なって、ウェブページの「包括的な理解」を形成します。この「コードが理解できなければ視覚に頼る」という冗長な設計により、アジェンティックブラウザは極めて頑丈な耐障害性を持っています。ウェブページが「Buy Now」を「Grab Now」に変更しても、ボタンがスタイリッシュな画像リンクになっても、正確に位置を特定し、操作を実行できます。
2.3 アクション実行: 実際のブラウザで操作を完了する
タスク計画と環境の理解ができたので、今行動を起こすときです。アクション実行ステージは、抽象的な「ステップ」を現実のブラウザでの基本操作に変換する責任があります。クリック、タイプ、スクロール、ホバー、ポップアップの処理などです。
Agentic Browsersは通常、制御された実際のブラウザインスタンス(例えば、ヘッドフルまたはヘッドレスのChromium)で動作し、ブラウザ自動化プロトコル(例えばCDP)を通じて人間の操作をシミュレートします。しかし、生体模倣実行により、従来の自動化よりもスマートです。
- リズムコントロール: 2つのクリックの間にランダムな遅延を追加し、キャラクター単位でタイプするようにすることで、ウェブサイトの自動化防止メカニズムによってブロックされるのを効果的に回避します。
- マウス軌跡のシミュレーション: 直線的に即座に移動する代わりに、わずかなジャイターやノイズを加えたベジエ曲線のパスを生成します。これは、実際の人の手に似ています。
- インテリジェントな待機: 固定の
sleepを単純に使用する代わりに、DOM変更、ネットワークリクエストの完了、キーパーツの可視性などのイベントを監視します。
より直感的に典型的なインタラクションの完全なアクションシーケンスを示すために、図2-4では「Click Add to Cart」を例に、アクション実行の詳細なステップをマッピングしています。
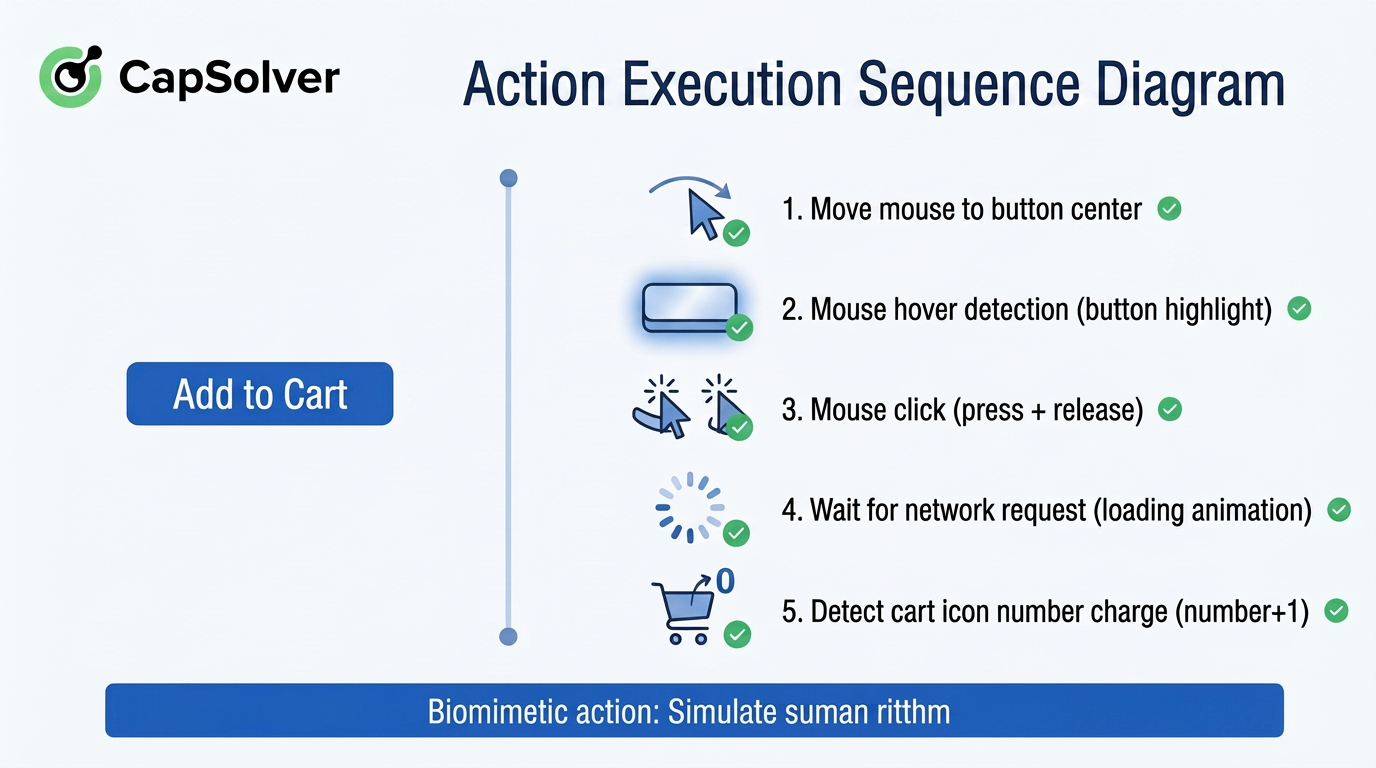
図2-4に示すように、すべてのステップは実際のユーザーの操作習慣に対応しています。ホバーで視覚フィードバックをトリガーし、クリック後のバックエンド応答を待つこと、そしてフロントエンドの状態変化を確認することです。この細かいシーケンス設計により、Agentic Browsersは「正しいアクションを取る」だけでなく、「人間のように振る舞う」ことができます。
さらに、全体のプロセスでリアルタイムのアクションログが生成され、ユーザーはいつでも一時停止、進捗の質問、またはエラーの修正が可能です。Agentic Browsersは一回限りの終了ツールではなく、人間と機械の協働の「セミオートマチック」モードです。重要な決定ポイントで介入できます。例えば、最終的な支払い前にブラウザが停止して確認を待つようにします。「生体模倣実行: 実際の人の操作リズムをシミュレートする」以下は、この一連のアクションの背後にある哲学を要約しています。つまり、機械のすべてのステップに人間の温かさをもたらすことです。
2.4 ページが変化したときの動的適応
現実世界のウェブページは生きています: A/Bテストにより、今回は青いボタンを表示し、次は赤いボタンを表示するかもしれません。プロモーションシーズン中にページレイアウトが大きく変化したり、「クーポンを取得」のモーダルやCAPTCHAチャレンジが突然表示されることがあります。これはAgentic Browsersが従来のRPAと異なるところです。動的適応能力です。
動的適応には3つのレベルの反応があります。
- 異常検出と回復: 予期された要素が表示されない場合(例: ボタンのテキストが変更された、セレクターが失敗した)、システムはすぐに視覚的位置決めモードに切り替えたり、検索範囲を拡大して意味的に最も近い代替ターゲットを見つける。繰り返し失敗した場合、エラー報告を生成し、ユーザーに尋ねます。
- ポップアップと中断の処理: AIは「突然の出来事が閉じる必要があるかどうか」を人間のように識別します。プロモーションのポップアップの場合、通常は閉じるをクリックします。ログインの期限切れのポップアップの場合、再ログインサブタスクをトリガーします。
- CAPTCHA応答(事前統合): ページにCAPTCHA(グラフィックスライダー、reCAPTCHAなど)が検出された場合、Agentic Browsersは現在のタスクを一時停止し、専門的な「インビジブルエンジン」にCAPTCHAのシナリオを渡します。これは第3章の主役であるCapSolverが解決しようとするコア問題です。成功した場合、元のタスクフローをシームレスに再開します。
全体の適応プロセスを継続的な自己修正ループとして見ることができます。
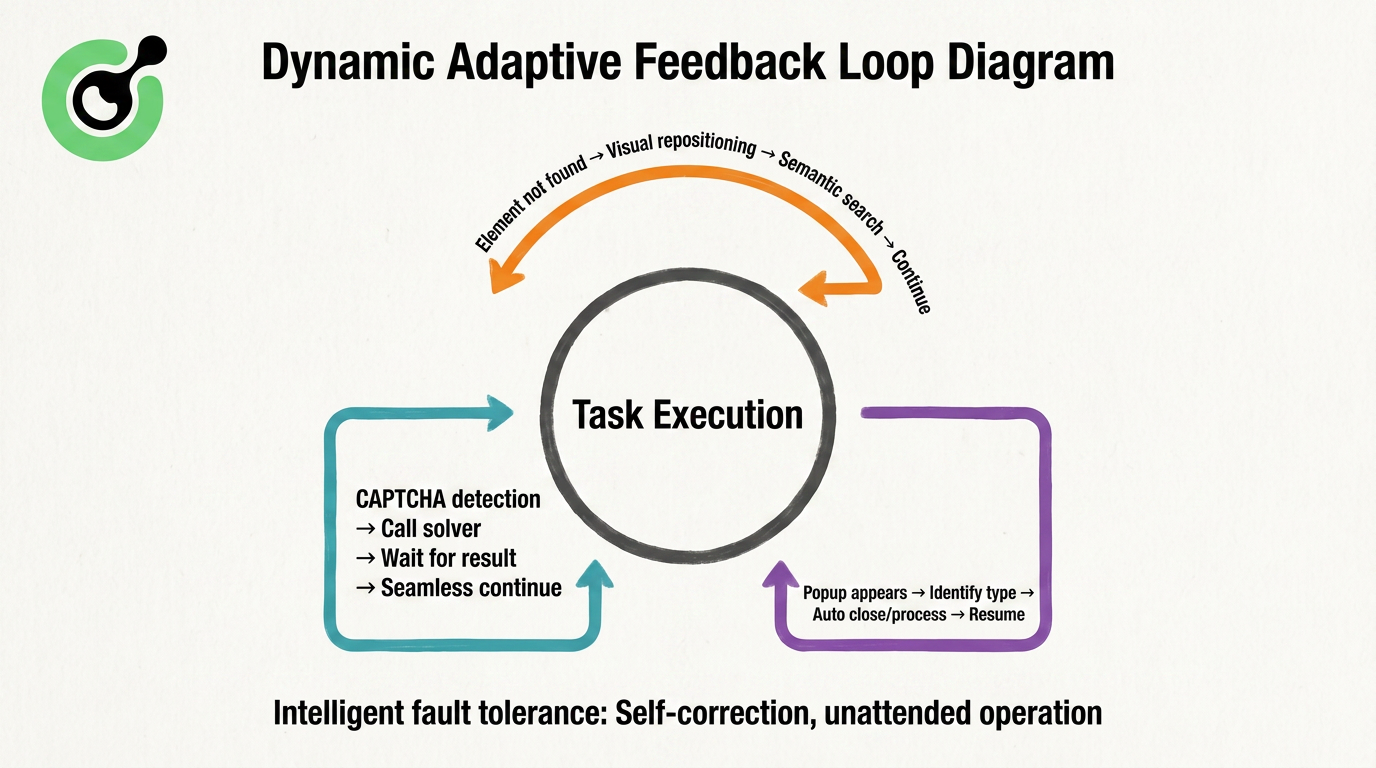
全体のクローズドループは「タスク実行」を中心に回っています。CAPTCHAに遭遇した場合、システムは外部の解決リソースを自動的に呼び出し、結果を待ってシームレスに再開します。ポップアップに遭遇した場合、識別して処理し、メインのタスクフローに戻ります。このメカニズムは下部の「インテリジェントフォールトトレラントメカニズム」と補完し、以前は「確実に失敗する」はずだった複雑なウェブページプロセスを監視なしで完了できるようにします。このクローズドループがAgentic Browsersが変化を恐れず、人間のように適応できるようにしているのです。
权威ある外部ソース
Agentic Browsersおよびウェブ自動化の開発と技術的な状況に関するより詳しい情報については、以下の権威あるソースを参照してください:
- Anthropic: Claude 3.5 Sonnetのコンピュータ使用の導入
- Opera: Opera Neon、最初のAI Agenticブラウザ
- Snowplow: Agenticブラウザとは何か?
結論
従来のブラウザからAgenticブラウザへの進化は、デジタル世界とどのように関わるかという点で画期的な変化を表しています。LLM、マルチモーダルな認識、生体模倣実行を統合することで、Agenticブラウザは単なる受動的な窓ではなく、複雑な意図を理解し、動的なウェブ環境をナビゲートできる能動的で知的なアシスタントになりました。繰り返しで退屈なタスクを処理し、人間ユーザーがより高次の意思決定や創造に集中できるようにします。しかし、これらのエージェントがより高度になると、ウェブの最終的なゲートキーパーであるCAPTCHAに必然的に遭遇します。Agenticブラウザの潜在能力を本当に解放するには、これらの障壁をシームレスに乗り越えるための堅牢なインフラストラクチャが必要です。
推奨: Agenticブラウザまたは自動化スクリプトが複雑なCAPTCHAによってブロックされずにスムーズに動作することを確保するには、CapSolverを統合することを強くお勧めします。CapSolverは、さまざまなCAPTCHAチャレンジをシームレスに回避する信頼性の高いAI駆動型インフラストラクチャを提供し、自動化ワークフローの完璧な「インビジブルエンジン」として機能します。
ボーナスコード
CapSolverボーナスコードを引き換える
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコードCAP26を使用すると、毎回チャージで5%のボーナスが追加されます—制限なし。
今すぐCapSolverダッシュボードで引き換えましょう
このシリーズの第2部を読む: Agenticブラウザのインビジブルエンジン: 専門的なインフラストラクチャでCAPTCHAを乗り越える
FAQ
Q1: 伝統的なブラウザとAgenticブラウザの主な違いは何ですか?
A1: 伝統的なブラウザは、クリックやタイプなどのステップバイステップの手動入力によってナビゲートし、タスクを実行するための受動的なツールです。Agenticブラウザは、自然言語コマンドを理解し、タスクを自律的に計画し、あなたの代わりに実行する能動的なデジタルエージェントです。
Q2: Agenticブラウザはウェブページで何をすべきかをどのように理解しますか?
A2: DOM構造の分析、ビジュアルスクリーンショットの理解(コンピュータビジョンを使用)、および相互作用状態の推論を組み合わせて、ウェブページを人間のように「見る」そして理解することができ、UI変更に対して非常に耐性があります。
Q3: Agenticブラウザはウェブサイトの予期せぬポップアップや変更を処理できますか?
A3: はい、動的適応能力があります。予期せぬポップアップを検出でき、知的に処理し、クラッシュすることなく実行戦略をリアルタイムで調整できます。
Q4: AgenticブラウザがCAPTCHAに遭遇した場合、どうなりますか?
A4: CAPTCHAが検出されると、Agenticブラウザは現在のタスクを一時停止し、専門的なインフラストラクチャ(例: CapSolver)に解決プロセスを委譲します。解決されると、タスクをシームレスに再開します。