AIにおけるデータの基盤とは何か?信頼性のあるLLMsの実践的なガイド

Sora Fujimoto
AI Solutions Architect
TL;DR
- データグランドリングは、AIの出力を信頼できる、最新で関連性のある情報ソースに接続します。
- データグランドリングは、推論時に文脈を追加することで、根拠のない回答を減らします。
- グランドリングデータには、ドキュメント、データベース、検索結果、カタログ、ポリシー、許可された記録が含まれる場合があります。
- RAGはデータグランドリングの一般的な手法ですが、それだけでこの分野を網羅するわけではありません。
- 強力なデータグランドリングには、品質チェック、権限、検索評価、出典、モニタリングが必要です。
- 自動化を活用するチームは、データを法的に収集し、CAPTCHAチャレンジは認可されたワークフローでのみ処理する必要があります。
イントロダクション
データグランドリングは、AIの回答を正確で最新かつ検証可能なものにする実践です。モデルが回答する前に適切な文脈を与えることが特徴です。このガイドは、LLMの上にAIツールを開発する製品チーム、SEOチーム、開発者、自動化チーム向けです。AIにおけるデータグランドリングの意味、仕組み、RAGやファインチューニングとの違い、そして責任を持って適用する方法について学びます。価値は実用的です:グランドリングされたAIシステムは、出典を示し、権限を尊重し、古くなった回答を減らすことができます。法的な自動化ワークフローがトラフィック検証やCAPTCHAチャレンジに遭遇した場合、CapSolverはコンプライアンスに合ったテストプロセスをサポートします。
データグランドリングの定義
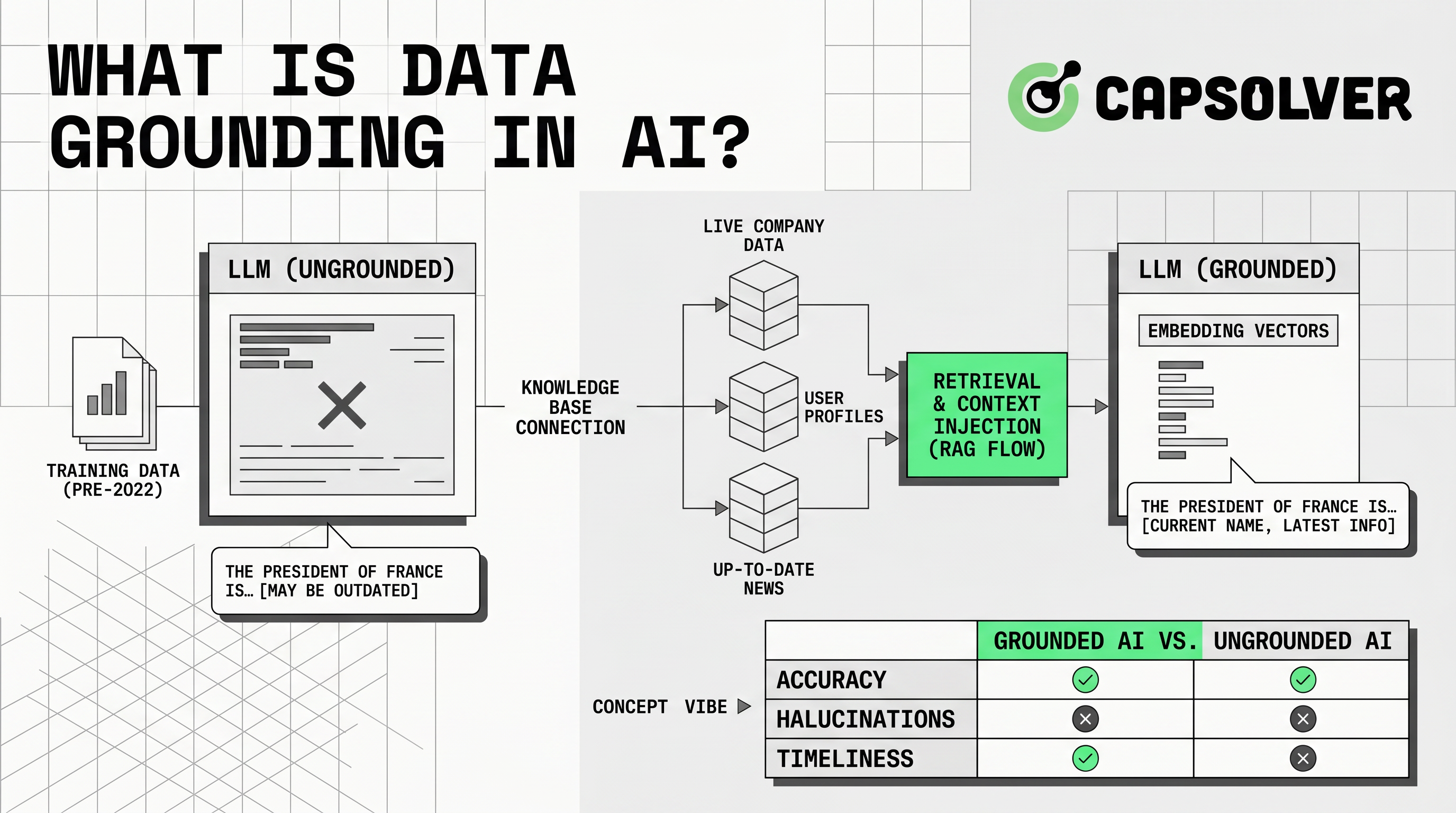
データグランドリングとは、AIの回答を信頼できる外部の文脈に固定することです。ユーザーが質問したときに、アプリケーションが関連情報をモデルに提供します。マイクロソフトは、推論時に言語モデルに提供される情報を「グランドリングデータ」と定義しています。これは、元のトレーニングデータにはない文脈を通じて精度と関連性を向上させるためのものです。Microsoft Azure Well-Architectedガイドラインより。
データグランドリングが重要である理由は、LLMが言語を予測するからです。最新の価格、ポリシー、ドキュメント、顧客記録、または公開市場データを自動的に知っているわけではありません。信頼できる文脈がないと、回答は自信ありそうに見えて実際には事実を欠いている可能性があります。データグランドリングにより、システムはソースマテリアルを検索し、プロンプトに挿入し、そのマテリアルから回答を生成させることができます。
AIデータグランドリングは単なるプロンプトのトリックではありません。これはデータデザインパターンです。ソース選択、クリーニング、インデックス作成、アクセス制御、検索、応答生成、出典、評価、モニタリングを含みます。
AIの正確性においてデータグランドリングが重要な理由
データグランドリングは、モデルの回答範囲を狭めることでAIの信頼性を向上させます。Google Cloudは、企業のグランドリングを、モデルをウェブ情報、企業データ、データベース、アプリケーション、信頼できるソースに接続して、Google Cloud企業の真実を通じて完全性と正確性を向上させることとして説明しています。
これは、頻繁に変化する分野において役立ちます。在庫、サポートポリシー、ドキュメンテーション、価格、イベントスケジュールは頻繁に変化します。数か月前にトレーニングされたモデルは、すべての更新を知っているわけではありません。データグランドリングにより、アプリケーションは毎日モデルを再トレーニングすることなく、最新情報を取得する道が開けます。
データグランドリングは、チームが回答を説明するのにも役立ちます。出典、タイムスタンプ、ソースフィールドは、QA、コンプライアンスレビュー、ユーザーの信頼をサポートします。
データグランドリングの仕組み
データグランドリングは、検索と生成のフローを通じて機能します。システムはまず、信頼できるソースを特定します。その後、それらのソースを検索用に準備します。一般的なソースには、ヘルプセンター、マニュアル、API、SQLデータベース、ベクトルインデックス、製品フィード、承認された公開ページが含まれます。
次のステップはインゲスチョンです。チームはドキュメントをクリーニングし、重複を削除し、メタデータを標準化し、コンテンツをチャンクに分割し、検索インデックスに保存します。インデックスにはキーワード検索、ベクトル検索、ハイブリッド検索、またはグラフ検索が使用されることがあります。マイクロソフトは、検索の改善、パフォーマンス、およびソースシステムの保護を目的として、グランドリングデータを外部にエクスポートすることを推奨しています。AIグランドリングデータ設計より。
ユーザーが質問をしたとき、システムは関連する記録を検索します。権限、新鮮さ、言語、地域、製品ラインでフィルタリングします。その後、検索された文脈をモデルのプロンプトに追加します。モデルはその文脈から回答し、出典を返すことがあります。
データグランドリングが成功するためには、検索が正確である必要があります。強力なシステムは、関連性、忠実性、遅延、およびソースカバレッジを測定します。
比較要約
データグランドリングはいくつかのAI手法と重複しています。以下の表は、実用的な違いを示しています。
| メソッド | 主な目的 | 最適な使用ケース | 主な制限 |
|---|---|---|---|
| データグランドリング | 信頼できる文脈に回答を固定する | 現在で出典に基づいた回答 | 強力な検索とガバナンスが必要 |
| RAG | 生成前にドキュメントを検索する | 知識ベースQ&Aとサポートエージェント | 関係ないまたは古くなった文脈を検索する可能性あり |
| ファインチューニング | 例を通じてモデルの挙動を変更する | スタイル、フォーマット、またはドメインの挙動 | 変更された事実には不向き |
| プロンプトエンジニアリング | 指示で挙動をガイドする | 小規模なタスクと応答フォーマット | 単独で欠落した事実を提供できない |
| ガードレール | ポリシーと出力制御を強制する | セーフティ、フォーマット、コンプライアンスチェック | 信頼できるソース文脈を置き換えることはできない |
この比較は、データグランドリングがRAGよりも広範囲である理由を示しています。RAGは一般的な実装パターンです。データグランドリングは、モデル出力を信頼できる証拠に接続する完全な分野です。
一般的なデータグランドリングソース
データグランドリングはソースの質から始まります。チームは、権威、新鮮さ、所有権、および権限レベルでソースをランク付けすべきです。
内部ソースは通常、最も高いビジネス価値を提供します。これらにはCRM記録、チケット、ポリシー、在庫システム、製品仕様、および知識ベースが含まれます。これらには厳格なアクセス制御が必要です。
外部ソースは新鮮さと幅を追加します。これらには公式ドキュメンテーション、政府ガイドライン、公開データセット、標準化団体、および信頼できる市場データが含まれます。NISTは、そのAIリスク管理フレームワークが個人、組織、社会のリスクを管理するのに役立つと述べています。NIST AI RMFより。このようなソースは、信頼できるAIシステムのポリシー作成に役立ちます。
公開ウェブデータは、市場モニタリング、SEOリサーチ、競合分析をサポートします。チームはこれを法的に適切に保つべきです。サイトの利用規約、レートリミット、適用可能なロボットガイドライン、プライバーオブリゲーションを尊重する必要があります。CapSolverのAIと自動化および自動化ワークフローに関するリソースは、責任あるプロセスの出発点として役立ちます。
データグランドリングのプロダクションワークフロー
データグランドリングは明確な運用モデルで最も効果的です。まず、回答の境界を定義します。AIが回答できる範囲、使用できるソース、拒否またはエスカレーションするタイミングを決定します。
第二に、データを準備します。重複、古くなった記録、プライベートフィールド、ノイズの多いテンプレートを削除します。所有者、日付、地域、製品、言語、権限レベルなどのメタデータを追加します。これにより、検索がより正確になります。
第三に、検索を設計します。正確な語句にはキーワード検索を使用し、意味的な類似性にはベクトル検索を使用し、許可された記録にはフィルターを使用します。
第四に、パフォーマンスを評価します。実際の質問のテストセットを作成します。検索の関連性、回答の忠実性、出典の正確性、遅延をスコアリングします。ドメインエキスパートとエッジケースをレビューします。モデルの信頼度にのみ頼らないでください。
第五に、ドリフトをモニタリングします。ドキュメントが古くなり、インデックスが破損し、権限が変更され、ユーザーの意図が変化すると、データグランドリングは失敗する可能性があります。重要なシステムには自動的な新鮮さチェックと人間のレビュー経路が必要です。
コンプライアンスとセキュリティの考慮事項
データグランドリングは、法的、プライバシー、セキュリティの境界を尊重する必要があります。技術的なアクセスは権限を意味しません。グランドリングされたAIシステムは、組織が明確な法的根拠とユーザーの許可を持っている場合を除き、プライベート、制限、機密、または不許可のデータを避けるべきです。
セキュリティリスクも重要です。OWASPは、LLMアプリケーションの主要なリスクとしてプロンプトインジェクション、機密情報の漏洩、過度なエージェンシー、過度な依存 amongを挙げています。OWASP LLMアプリケーションのトップ10より。データグランドリングは、根拠のない主張を減らすことができますが、検索が悪意のあるコンテンツを受け入れたり、保護された記録を暴露したりすると、リスクを導入する可能性があります。
チームは、権限に注意を払った検索を使用すべきです。信頼できないテキストをサニタイズし、ソースIDを機密記録ではなくログに記録し、データを分類ごとに分離する必要があります。
自動化チームは追加の注意が必要です。ウェブデータ収集は、許可された公開データ、適切なリクエストレート、文書化されたビジネス目的に焦点を当てるべきです。認可されたQA、モニタリング、またはデータワークフローでCAPTCHAチャレンジが表示された場合、チームはこれをトラフィック検証の一部として扱うべきです。CapSolverの公開ウェブデータ収集に関する記事とCAPTCHAチャレンジに関するガイドは、チームが運用文脈を理解するのに役立ちます。
CapSolverが責任あるAIワークフローに適合する場所
CapSolverは、データグランドリングが法的な自動化ワークフローに依存する場合に役立ちます。一部のチームは、価格モニタリング、SEOチェック、広告検証、QAテスト、または研究のために公開データを収集します。これらのワークフローは、通常のブラウジングやテスト中にCAPTCHAチャレンジに遭遇する可能性があります。
CapSolverは、自動化環境向けのサービスを通じて、これらのチャレンジをチームが処理するのを支援します。推奨は狭く、コンプライアンスを最優先にしています。許可がある場合、適用可能なルールを尊重し、制限または機密データを避ける場合にのみ使用してください。チームは、CapSolver製品を確認して、サポートされるシナリオを理解し、承認されたワークフローに一致させることができます。
CapSolverボーナスコードを取得する
すぐに自動化予算を増やす!
CapSolverアカウントのチャージ時にボーナスコード CAP26 を使用すると、すべてのチャージで 5%のボーナス を受け取れます — 制限なし。
今すぐCapSolverダッシュボードで取得してください
データグランドリングとCAPTCHA処理は、簡単に混ぜてはいけません。グランドリング層は、AIが使用できる証拠を決定します。自動化層は、承認されたルールに基づいてデータを収集またはチェックします。これらの層を分離することで、監査が簡単になり、運用リスクが低減されます。
グランドリングされたAIシステムの実用的なメトリクス
データグランドリングには測定可能な品質基準が必要です。検索の関連性は、返された文脈が質問に答えているかどうかを尋ねます。低いスコアは、モデルが弱い証拠で作業していることを示します。
回答の忠実性は、回答が検索されたソース内にとどまっているかどうかを尋ねます。これは、流暢な回答でもサポートされていない詳細を追加する可能性があるため重要です。
出典の正確性は、すべての出典が続く文をサポートしているかどうかを確認します。新鮮さはドキュメントの年齢、インデックスの更新時間、ソースの更新頻度を追跡します。拒否の品質は、証拠が欠如しているときにシステムが言うかどうかをチェックします。
結論とCTA
データグランドリングは、AIシステムをより信頼性高くする最も実用的な方法の一つです。回答を信頼できる文脈に接続し、新鮮さを向上させ、出典をサポートし、チームがリスクを管理するのを助けます。RAGはしばしば解決策の一部ですが、プロダクショングレードのデータグランドリングには、クリーンなデータ、強力な権限、評価、モニタリング、責任ある自動化の実践も必要です。
AIワークフローが公開データモニタリング、ブラウザ自動化、QAテスト、または研究に依存している場合、データパイプラインを慎重に計画してください。ソースアクセスを法的に保ち、機密データを保護してください。重要な決定に使用する前に出力をレビューしてください。承認されたワークフローでCAPTCHAチャレンジに遭遇した場合、CapSolverをコンプライアンスに合った自動化スタックの一部として評価することを検討してください。
FAQ
AIにおけるデータグランドリングとは何ですか?
データグランドリングは、AIの回答を信頼できる文脈に接続するプロセスです。文脈はドキュメント、データベース、API、検索インデックス、または承認された公開ソースから来る可能性があります。モデルがトレーニングデータにのみ依存するのではなく、証拠から回答するのを助けます。
データグランドリングはRAGと同じですか?
いいえ。RAGはデータグランドリングを実装する一般的な方法です。データグランドリングはより広範囲です。ソースガバナンス、インデックス作成、権限、検索評価、出典、モニタリング、エスカレーションルールを含みます。
なぜデータグランドリングは根拠のないAIの回答を減らすのでしょうか?
データグランドリングは、推論時にモデルに関連する証拠を提供するため、根拠のない回答を減らします。モデルは最新の文脈から回答することができ、統計的なパターンだけでギャップを埋めるのではなくなります。
LLMのためのデータグランドリングにどのデータを使用すべきですか?
正確で、許可され、最新で、関連性のあるデータを使用してください。良い例には、公式ドキュメンテーション、製品記録、サポートポリシー、知識ベース、公開データセット、および承認されたビジネスデータベースが含まれます。適切な許可なしにプライベートまたは制限されたデータを避けてください。
チームはどのように責任を持ってデータグランドリングを適用すべきですか?
チームはソースルールを定義し、アクセス制御を強制し、検索品質をモニタリングし、高影響力の出力をレビューする必要があります。自動化チームは、データを法的に収集し、サイトルールを尊重し、CAPTCHA関連のサービスは認可されたワークフローでのみ使用する必要があります。
もっと見る
Web ScrapingJul 22, 2026
サイテクニカルSEOレグレッション監視: 自動化パイプライン
技術的SEOの回帰モニタリングをバージョン付きのベースライン、セマンティックな差分、検証済みアラート、およびオプションの認証済みCAPTCHA復元ステップを用いて構築してください。
CloudflareJul 22, 2026
MCP CAPTCHAソルバー:Cloudflare Turnstile 統合ガイド
ポリシー制限付きのMCP Cloudflare TurnstileワークフローをCapSolver、制限付きリトライ、ロギングをマスキングしたセッションチェック、および結果の検証を含むように構築してください。