Web Scraping di Linux: Alat, Pengaturan & Panduan Praktis

Emma Foster
Machine Learning Engineer
TL;DR
- Linux adalah platform yang dominan untuk pengambilan data web di produksi karena stabilitasnya, jadwal cron, dan beban rendah.
- Alat pengambilan data Python inti — Requests, BeautifulSoup, Scrapy, dan Playwright — masing-masing menangani kasus penggunaan yang berbeda.
- Rotasi proxy penting untuk ekstraksi data skala besar untuk menghindari pembatasan berdasarkan IP.
- Tantangan CAPTCHA adalah penghalang umum dalam pipeline otomatis; API CapSolver menyelesaikannya secara programatis dalam 1–5 detik.
- Pipeline ekstraksi data lengkap di Linux menggabungkan jadwal (cron), penyimpanan (SQLite/PostgreSQL), manajemen proxy, dan penanganan CAPTCHA.
- Selalu ambil data secara bertanggung jawab: hormati
robots.txt, batasi kecepatan permintaan, dan patuhi hukum perlindungan data yang berlaku.
Pendahuluan
Linux adalah platform pilihan bagi pengembang yang menjalankan pengambilan data web skala besar. Keunggulan native cron scheduling, beban sumber daya minimal, dan ekosistem Python yang matang membuatnya jauh lebih praktis daripada Windows atau macOS untuk pipeline ekstraksi data otomatis yang berjalan lama. Panduan ini menjelajahi pengaturan lingkungan, pemilihan alat, konfigurasi proxy, penanganan CAPTCHA, dan arsitektur pipeline — referensi praktis bagi pengembang yang membangun pengambilan data web di Linux pada 2025.
Mengapa Linux adalah Platform yang Disukai untuk Pengambilan Data Web
Linux menguasai lebih dari 80% server web di seluruh dunia, menurut statistik OS server W3Techs. Dominasi ini tidak kebetulan — Linux menawarkan sejumlah kemampuan native yang membuatnya lingkungan yang paling praktis untuk pengambilan data web di Linux dalam skala apa pun.
Keuntungan utama untuk beban kerja pengambilan data:
- Jadwal Cron — otomatisasi skrip pengambilan data pada interval apa pun tanpa alat pihak ketiga.
- Jejak memori rendah — jalankan browser headless dan banyak pekerja secara bersamaan pada perangkat keras yang moderat.
- Manajemen paket —
apt,pip, dancondamenjaga manajemen dependensi bersih dan dapat diulang. - Akses SSH — kelola server pengambilan data jarak jauh tanpa antarmuka grafis.
- Stabilitas — pekerjaan yang berjalan lama jauh lebih sedikit terganggu oleh peristiwa OS.
- Alat CLI native —
wget,curl,grep,sed, danawkmenangani tugas pengambilan data ringan langsung dari terminal, sebagaimana dicatat oleh panduan pengambilan data web Linux.com.
Mayoritas penyedia VPS awan — AWS EC2, DigitalOcean, Linode — default ke Ubuntu atau Debian, menjadikan Linux sebagai target pengembangan alami untuk setiap pipeline ekstraksi data yang serius.
Menyiapkan Lingkungan Pengambilan Data Linux Anda
Sebelum menulis satu baris pun kode pengambilan data, siapkan lingkungan bersih dan terisolasi.
Langkah 1 — Instal Python dan pip
Sebagian besar distribusi Linux modern menyertakan Python 3. Verifikasi versi Anda:
bash
python3 --version
pip3 --versionJika pip tidak ada:
bash
sudo apt update && sudo apt install python3-pip -yLangkah 2 — Buat Lingkungan Virtual
Mengisolasi dependensi mencegah konflik versi antar proyek:
bash
python3 -m venv scraper-env
source scraper-env/bin/activateLangkah 3 — Instal Pustaka Pengambilan Data Inti
bash
pip install requests beautifulsoup4 scrapy playwright lxml
playwright install chromiumLangkah 4 — Instal Alat Pendukung
bash
pip install pandas sqlalchemy psycopg2-binary fake-useragentBasis ini mencakup pengambilan halaman statis, rendering JavaScript, dan penyimpanan data — tiga pilar dari setiap workflow pengambilan data web di Linux.
Alat Pengambilan Data Python: Memilih yang Tepat
Pemilihan alat yang tepat bergantung pada kompleksitas situs target dan kebutuhan throughput Anda. Tabel di bawah ini merangkum alat pengambilan data Python utama yang digunakan dalam lingkungan Linux.
Ringkasan Perbandingan
| Alat | Terbaik Untuk | Rendering JS | Kecepatan | Kurva Pembelajaran |
|---|---|---|---|---|
| Requests | Permintaan HTTP sederhana, halaman statis | ✗ | Cepat | Rendah |
| BeautifulSoup | Parsing HTML/XML (dengan Requests) | ✗ | Cepat | Rendah |
| Scrapy | Crawling skala besar, berulang | ✗ (melalui plugin) | Sangat Cepat | Menengah |
| Playwright | Halaman dinamis, berbasis JS | ✓ | Menengah | Menengah |
| Selenium | Otomasi lama, halaman JS | ✓ | Lambat | Menengah |
Requests + BeautifulSoup adalah titik masuk standar untuk pengambilan data web di Linux. Ini menangani sebagian besar halaman statis dengan setup minimal dan jalur tercepat dari nol ke pengambil data yang berjalan.
Scrapy adalah pilihan yang tepat untuk pipeline ekstraksi data produksi berulang. Ini menangani cookie, sesi, kompresi, autentikasi, cache, dan robots.txt secara default, dan arsitektur middleware-nya mendukung rotasi proxy dan penanganan CAPTCHA kustom. Scrapy adalah salah satu framework pengambilan data Python yang paling banyak digunakan, dengan lebih dari 52.000 bintang GitHub pada 2025 (Scrapy di GitHub). Untuk gambaran yang lebih luas tentang bagaimana alat-alat ini dibandingkan dalam skenario dunia nyata, lihat alat pengambilan data dijelaskan.
Playwright adalah pengganti modern untuk Selenium ketika rendering JavaScript diperlukan. Ini berjalan Chromium headless secara native di Linux, mendukung eksekusi async, dan jauh lebih cepat untuk konten dinamis. Untuk perbandingan mendalam tentang pendekatan otomasi browser, nodriver vs alat otomasi browser tradisional menjelaskan pertukaran secara rinci.
Penggunaan Proxy dalam Pengambilan Data Web Linux
Rotasi proxy penting untuk setup pengambilan data web Linux yang serius. Tanpa itu, IP scraper Anda akan dibatasi atau diblokir setelah jumlah permintaan yang relatif kecil. Proxy residensial statis — alamat IP yang diberikan oleh ISP — terbukti sangat efektif karena meniru perilaku pengguna nyata, mengurangi kemungkinan deteksi, sebagaimana dicatat oleh panduan Linux Security tentang praktik pengambilan data etis.
Jenis Proxy
| Jenis | Risiko Deteksi | Biaya | Terbaik Untuk |
|---|---|---|---|
| Datacenter | Tinggi | Rendah | Target yang sensitif terhadap kecepatan, perlindungan rendah |
| Residensial | Rendah | Menengah | Situs dengan deteksi bot menengah |
| Residensial Berputar | Sangat Rendah | Lebih Tinggi | Pipeline volume tinggi, berkelanjutan |
Mengkonfigurasi Proxy dalam Python Requests
python
import requests
proxies = {
"http": "http://username:password@proxy-host:port",
"https": "http://username:password@proxy-host:port",
}
response = requests.get("https://example.com", proxies=proxies)
print(response.status_code)Mengkonfigurasi Proxy dalam Scrapy
Di settings.py:
python
ROTATING_PROXY_LIST = [
"http://proxy1:port",
"http://proxy2:port",
]Gunakan middleware scrapy-rotating-proxies untuk manajemen pool otomatis.
Praktik Terbaik
- Rotasi string user-agent bersamaan dengan rotasi IP menggunakan
fake-useragent. - Tambahkan jeda acak antar permintaan:
time.sleep(random.uniform(1, 3)). - Pantau kesehatan proxy dan hapus IP mati dari pool Anda secara otomatis.
- Gunakan proxy HTTPS untuk situs yang mewajibkan inspeksi TLS.
Untuk daftar proxy penyedia yang telah diuji dan bekerja baik dengan pengambilan data web di Linux, layanan proxy terbaik untuk pengambilan data adalah titik awal yang berguna.
Penanganan CAPTCHA dalam Pipeline Ekstraksi Data Anda
Tantangan CAPTCHA adalah penghalang paling umum dalam pengambilan data web produksi di Linux. Situs mengimplementasikan reCAPTCHA v2/v3, hCaptcha, Cloudflare Turnstile, dan tantangan lainnya secara khusus untuk mengganggu pipeline ekstraksi data otomatis. reCAPTCHA v2 saja digunakan oleh lebih dari 5 juta situs secara global, menurut panduan integrasi reCAPTCHA v2 CapSolver.
Menyelesaikan CAPTCHA secara manual tidak skalabel. Solusi praktisnya adalah mengintegrasikan API penyelesaian CAPTCHA secara programatis langsung ke dalam alur kerja pengambilan data Anda. CapSolver adalah layanan yang didukung AI yang menyelesaikan reCAPTCHA, hCaptcha, Cloudflare Turnstile, GeeTest, AWS WAF, dan jenis tantangan lainnya melalui API REST, biasanya mengembalikan token valid dalam 1–5 detik — tanpa intervensi manusia.
Dapatkan Kode Bonus CapSolver Anda
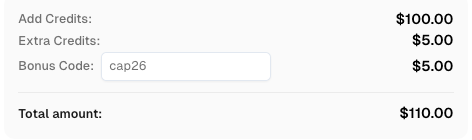
Tingkatkan anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAP26 saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan tambahan 5% bonus pada setiap penambahan — tanpa batas.
Ambil sekarang di Dashboard CapSolver Anda
Cara Kerja CapSolver
- Scraper Anda mendeteksi CAPTCHA di halaman target.
- Anda mengirimkan URL situs dan kunci situs ke endpoint
createTaskCapSolver. - Model AI CapSolver menyelesaikan tantangan dan mengembalikan token.
- Anda menyisipkan token ke dalam bidang formulir atau header permintaan Anda.
- Scraper melanjutkan tanpa gangguan.
Contoh Integrasi Python (reCAPTCHA v2 — Tanpa Proxy)
Contoh berikut berdasarkan dokumentasi API resmi CapSolver:
python
import requests
import time
# Kunci API CapSolver Anda
API_KEY = "YOUR_CAPSOLVER_API_KEY"
WEBSITE_URL = "https://example.com"
WEBSITE_KEY = "YOUR_RECAPTCHA_SITE_KEY"
def create_task():
payload = {
"clientKey": API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": WEBSITE_URL,
"websiteKey": WEBSITE_KEY,
}
}
response = requests.post(
"https://api.capsolver.com/createTask",
json=payload
)
return response.json().get("taskId")
def get_task_result(task_id):
payload = {
"clientKey": API_KEY,
"taskId": task_id,
}
while True:
response = requests.post(
"https://api.capsolver.com/getTaskResult",
json=payload
)
result = response.json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
time.sleep(2)
task_id = create_task()
token = get_task_result(task_id)
print("Token CAPTCHA:", token)Token ini kemudian disisipkan ke bidang g-recaptcha-response formulir, memungkinkan scraper Anda melanjutkan melewati penghalang CAPTCHA. Untuk tugas berbasis proxy, ganti jenis tugas menjadi ReCaptchaV2Task dan tambahkan detail proxy Anda ke payload.
CapSolver mendukung dua mode tugas:
ReCaptchaV2TaskProxyLess— menggunakan infrastruktur CapSolver sendiri; setup lebih sederhana.ReCaptchaV2Task— menggunakan proxy Anda sendiri; lebih baik untuk situs dengan pembatasan geografis ketat.
Untuk daftar lengkap jenis tugas yang didukung — termasuk reCAPTCHA v3, Cloudflare Turnstile, dan AWS WAF — lihat dokumentasi jenis tugas CapSolver.
Membangun Pipeline Ekstraksi Data Lengkap di Linux
Setup pengambilan data web di Linux yang siap produksi lebih dari sekadar skrip tunggal. Ini adalah pipeline dengan tahapan yang berbeda dan dapat dikomposisi.
Arsitektur Pipeline
[Pengatur Waktu: cron]
→ [Scraper: Scrapy / Playwright]
→ [Lapisan Proxy: residensial berputar]
→ [Penangan CAPTCHA: API CapSolver]
→ [Parser: BeautifulSoup / lxml]
→ [Penyimpanan: SQLite / PostgreSQL]
→ [Ekspor: CSV / JSON / REST API]Penjadwalan dengan Cron
Edit crontab Anda untuk menjalankan tugas pengambilan data setiap jam:
bash
crontab -eTambahkan baris berikut:
0 * * * * /home/user/scraper-env/bin/python /home/user/scraper/run.py >> /home/user/scraper/logs/scrape.log 2>&1Menyimpan Data yang Diambil
Untuk proyek kecil, SQLite sudah cukup:
python
import sqlite3
conn = sqlite3.connect("data.db")
cursor = conn.cursor()
cursor.execute(
"CREATE TABLE IF NOT EXISTS products (name TEXT, price TEXT, url TEXT)"
)
cursor.execute(
"INSERT INTO products VALUES (?, ?, ?)", (name, price, url)
)
conn.commit()
conn.close()Untuk pipeline yang lebih besar, PostgreSQL dengan SQLAlchemy memberikan koneksi dan kinerja query yang lebih baik.
Logging dan Penanganan Kesalahan
Selalu catat aktivitas pengambilan data. Gunakan modul logging bawaan Python:
python
import logging
logging.basicConfig(
filename="scrape.log",
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s"
)
logging.info("Pengambilan data dimulai")Logging yang terstruktur membuatnya jauh lebih mudah untuk memperbaiki kegagalan dalam pekerjaan pengambilan data web di Linux yang berjalan lama — terutama ketika kesalahan proxy dan timeout CAPTCHA terlibat.
Kepatuhan dan Pengambilan Data yang Bertanggung Jawab
Pengambilan data web di Linux adalah kemampuan yang kuat, tetapi harus digunakan secara bertanggung jawab.
- Periksa
robots.txt— selalu tinjauhttps://example.com/robots.txtsebelum mengambil data. Hormati arahanDisallow. - Pembatasan kecepatan — jangan menyerang server. Tambahkan jeda antar permintaan untuk menghindari penurunan kinerja situs.
- Ketentuan Layanan — tinjau ToS situs target. Beberapa situs secara eksplisit melarang pengumpulan data otomatis.
- Data Pribadi — hindari mengumpulkan informasi yang dapat diidentifikasi secara pribadi (PII) tanpa dasar hukum di bawah regulasi yang berlaku seperti GDPR.
- Hak Cipta — konten yang diambil mungkin dilindungi hak cipta. Gunakan data untuk analisis, bukan pemublikasian kembali.
Pengambilan data yang bertanggung jawab bukan hanya pertimbangan etis — itu semakin menjadi pertimbangan hukum. Kerangka kerja seputar pengumpulan data otomatis terus berkembang, dan membangun kepatuhan ke dalam pipeline Anda dari awal jauh lebih murah daripada mengintegrasikannya nanti.
Kesimpulan
Pengambilan data web di Linux memberikan dasar yang stabil, dapat diprogram, dan hemat biaya untuk ekstraksi data dalam skala apa pun. Kombinasi alat pengambilan data Python seperti Scrapy dan Playwright, lapisan proxy yang dikonfigurasi dengan baik, dan layanan penyelesaian CAPTCHA secara programatis mencakup seluruh rentang tantangan yang akan Anda temui dalam produksi. Mulailah dengan lingkungan virtual yang bersih, pilih alat Anda berdasarkan kompleksitas situs target, dan bangun pipeline Anda secara bertahap — termasuk penjadwalan, penyimpanan, dan penanganan kesalahan.
Jika tantangan CAPTCHA menghambat alur kerja scraping Anda, mulai dengan CapSolver dan integrasikan penyelesaian CAPTCHA berbasis AI ke dalam alur kerja Anda dalam beberapa menit.
FAQ
Q1: Apa perpustakaan Python terbaik untuk scraping web di Linux?
Tergantung pada kasus penggunaan. Untuk halaman statis, Requests dikombinasikan dengan BeautifulSoup adalah pilihan tercepat dan paling sederhana. Untuk pengambilan data skala besar yang berulang, Scrapy adalah standar industri. Untuk halaman yang berat JavaScript, Playwright adalah pilihan yang direkomendasikan di Linux.
Q2: Bagaimana cara menjalankan scraper web secara otomatis di Linux?
Gunakan cron jobs. Edit crontab Anda dengan crontab -e dan tambahkan baris yang menentukan jadwal dan jalur ke skrip Python Anda. Ini menjalankan scraper Anda pada interval apa pun tanpa intervensi manual.
Q3: Bagaimana cara menangani CAPTCHA dalam alur kerja scraping web?
Integrasikan API penyelesaian CAPTCHA seperti CapSolver. Scraper Anda mengirimkan URL situs dan kunci situs ke API, menerima token yang telah diselesaikan, dan menyisipkannya ke dalam permintaan. Proses ini sepenuhnya otomatis dan hanya menambahkan beberapa detik latensi per pengenalan CAPTCHA.
Q4: Apakah proxy diperlukan untuk scraping web di Linux?
Untuk tugas scraping kecil dan jarang, proxy mungkin tidak diperlukan. Untuk pengambilan data skala besar atau alur kerja ekstraksi berkelanjutan, proxy yang berputar sangat penting untuk menghindari pembatasan laju berdasarkan IP dan pemblokiran.
Q5: Apakah scraping web di Linux legal?
Scraping web secara umum legal ketika diterapkan pada data yang dapat diakses publik. Namun, Anda harus mematuhi robots.txt situs target, ketentuan layanan, dan hukum perlindungan data yang berlaku. Scraping data pribadi atau konten berhak cipta tanpa izin membawa risiko hukum.