C# adalah bahasa pemrograman yang sangat fleksibel yang secara luas digunakan dalam proyek dan aplikasi level perusahaan. Dengan akar dari keluarga C, C# menawarkan efisiensi dan kekuatan, membuatnya menjadi tambahan yang tak ternilai bagi setiap alat pengembang.
Berkat penggunaannya yang luas, C# menawarkan berbagai alat yang memperkuat pengembang untuk menyelesaikan solusi yang rumit, dan web scraping tidak terkecuali.
Dalam tutorial ini, kita akan membimbing Anda melalui pembuatan scraper web yang sederhana menggunakan C# dan pustaka scraping yang ramah pengguna. Selain itu, kita akan mengungkap trik yang berguna untuk membantu Anda menghindari pemblokiran hanya dengan satu baris kode. Apakah Anda siap? Mari kita mulai!
Daftar Isi
Pengenalan tentang Web Scraping
Mengapa Memilih C# Daripada C untuk Web Scraping?
Menyiapkan Lingkungan Anda
Prasyarat
Menginstal Pustaka
Membuat Proyek Web Scraping C# di Visual Studio
Web Scraping Dasar dengan C#
Membuat Permintaan HTTP
Mem-parsing Konten HTML
Mem-parsing HTML Lanjutan
Cara Mengelola Data yang Di-scrap
Menangani CAPTCHA dalam Web Scraping
Mengintegrasikan Penyelesai CAPTCHA
Contoh Kode untuk CapSolver
Kesimpulan
1. Pengenalan tentang Web Scraping
Web scraping adalah proses mengekstrak informasi secara otomatis dari situs web. Ini dapat dilakukan untuk berbagai tujuan, termasuk analisis data, penelitian pasar, dan intelijen kompetitif. Namun, banyak situs web menerapkan mekanisme untuk mendeteksi dan memblokir upaya scraping otomatis, sehingga penting untuk menggunakan teknik yang canggih untuk menghindari pemblokiran.
Mengapa Memilih C# Daripada C untuk Web Scraping?
Web scraping sering melibatkan interaksi dengan elemen web, pengelolaan permintaan HTTP, dan penanganan ekstraksi serta parsing data. Meskipun C adalah bahasa yang kuat dan efisien, C tidak memiliki pustaka bawaan dan fitur modern yang membuat web scraping lebih mudah dan efisien. Berikut beberapa alasan mengapa C# adalah pilihan yang lebih baik untuk web scraping:
Perpustakaan yang Kaya: C# memiliki pustaka yang luas seperti HtmlAgilityPack untuk parsing HTML dan Selenium untuk otomasi browser, mempermudah proses scraping.
Pemrograman Asinkron: Kata kunci async dan await C# memungkinkan operasi asinkron yang efisien, yang penting untuk menangani beberapa permintaan web secara bersamaan.
Kemudahan Penggunaan : Sintaksis C# lebih modern dan ramah pengguna dibandingkan C, membuat proses pengembangan lebih cepat dan kurang rentan terhadap kesalahan.
Integrasi: C# terintegrasi dengan mulus dengan kerangka kerja .NET, menyediakan alat dan layanan kuat untuk membangun aplikasi yang tangguh.
Kesulitan dengan kegagalan berulang dalam menyelesaikan captcha yang mengganggu?
Temukan penyelesaian captcha otomatis yang mulus dengan teknologi Auto Web Unblock berbasis AI Capsolver!
Klaim Kode Bonus Anda untuk solusi captcha terbaik; : WEBS. Setelah mengklaimnya, Anda akan mendapatkan bonus tambahan 5% setiap kali recharge, Tidak Terbatas
2. Menyiapkan Lingkungan Anda
Sebelum kita mulai scraping, kita perlu menyiapkan lingkungan pengembangan kita. Berikut cara melakukannya:
Prasyarat
Visual Studio: versi Community gratis dari Visual Studio 2022 akan cukup.
.NET 6+: versi LTS mana pun yang lebih besar atau sama dengan 6 akan cukup.
pustaka HtmlAgilityPack untuk parsing HTML
pustaka RestSharp untuk membuat permintaan HTTP
Membuat Proyek Web Scraping C# di Visual Studio
Menyiapkan Proyek di Visual Studio
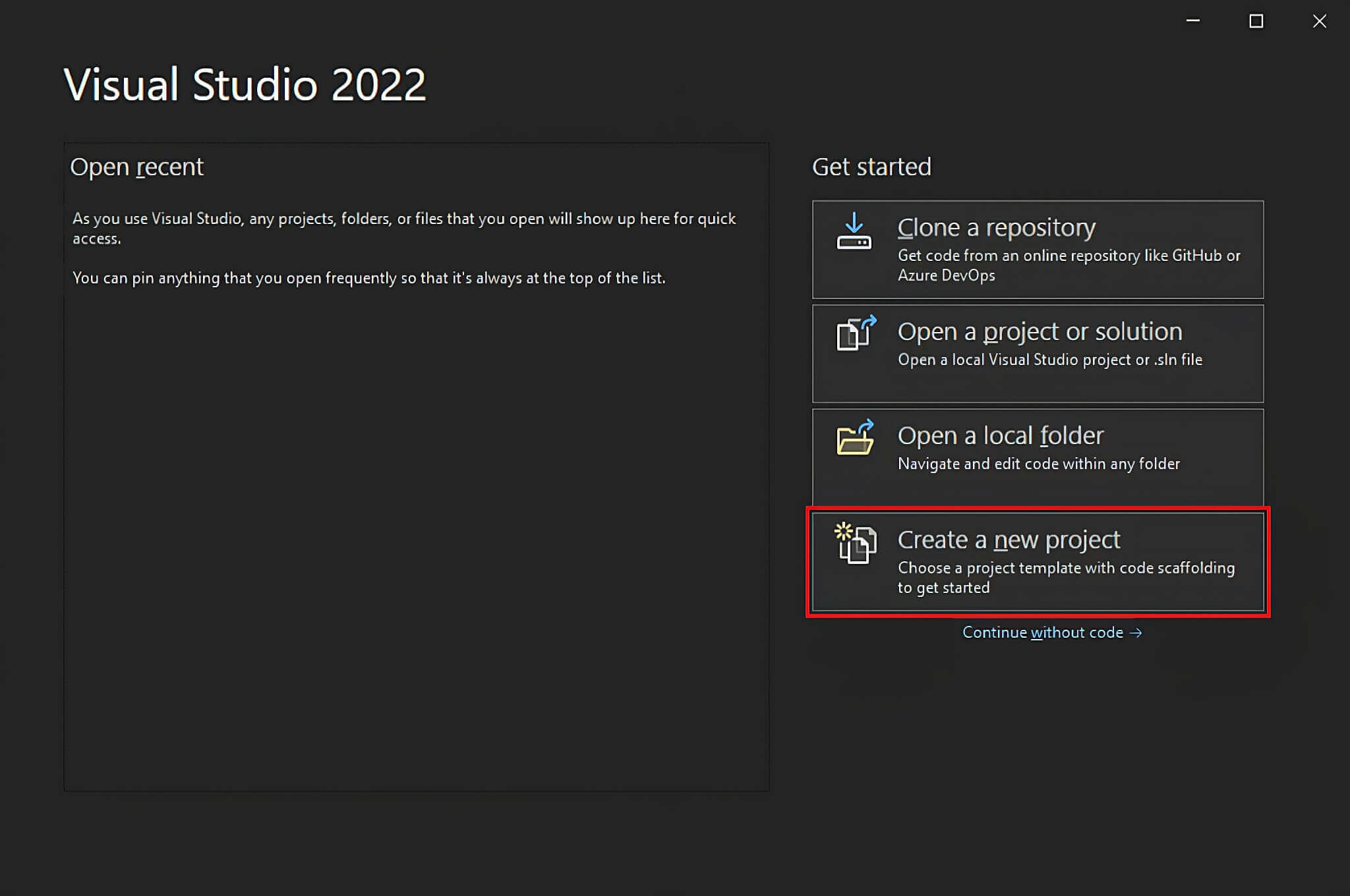
Buka Visual Studio dan klik opsi "Buat proyek baru".
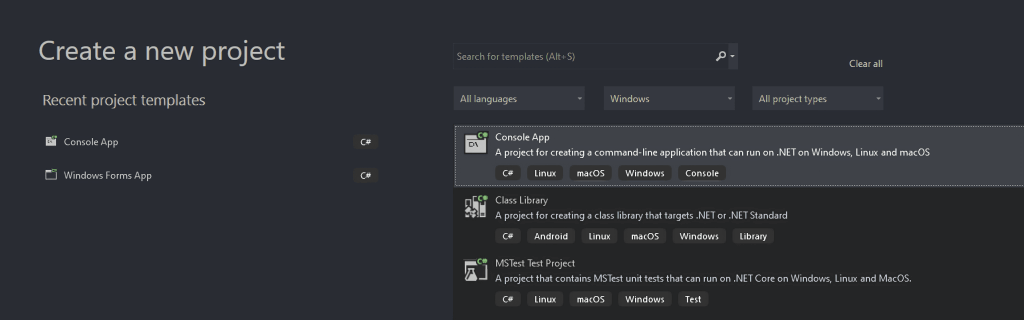
Di jendela "Buat proyek baru", pilih opsi "C#" dari daftar dropdown. Setelah menentukan bahasa pemrograman, pilih template "Console App", lalu klik "Berikutnya".
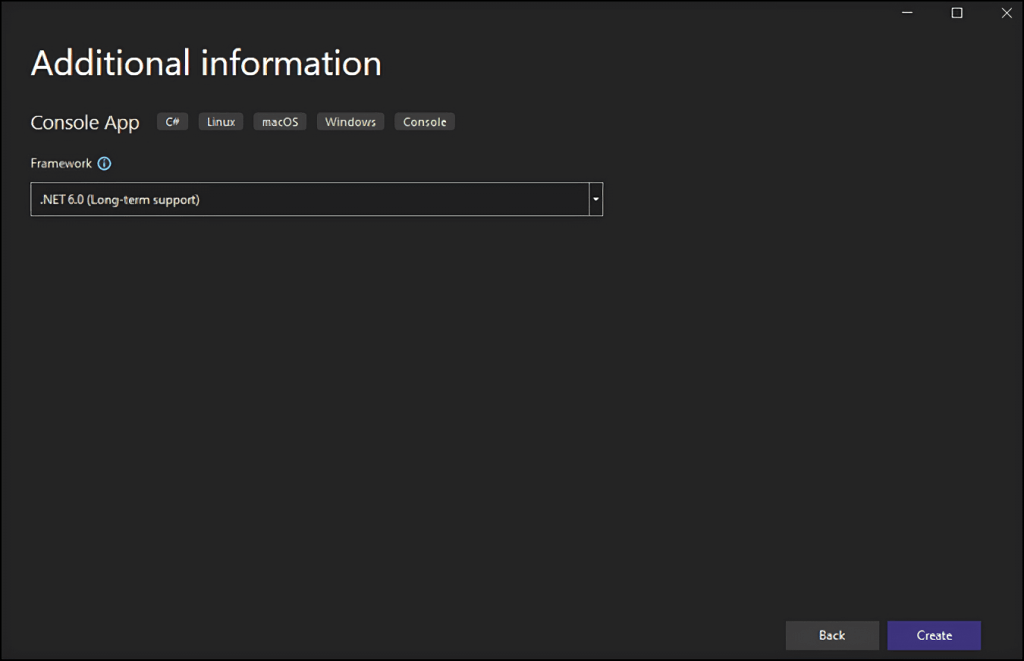
Beri nama proyek Anda StaticWebScraping, klik "Pilih", dan pilih versi .NET. Jika Anda telah menginstal .NET 6.0, Visual Studio seharusnya sudah memilihnya untuk Anda.
Klik tombol "Buat" untuk menginisialisasi proyek web scraping C# Anda. Visual Studio akan menginisialisasi folder StaticWebScraping yang berisi file App.cs. File ini akan menyimpan logika scraping web Anda dalam C#:
csharpCopy
namespace WebScraping {
public class Program {
public static void Main() {
// logika scraping...
}
}
}
Sekarang waktunya untuk memahami bagaimana membangun scraper web dalam C#!
3. Web Scraping Dasar dengan C#
Dalam bagian ini, kita akan membuat aplikasi C# yang membuat permintaan HTTP ke situs web, mengambil konten HTML, dan mem-parsingnya untuk mengekstrak informasi.
Membuat Permintaan HTTP
Pertama, mari kita buat aplikasi C# dasar yang membuat permintaan HTTP ke situs web dan mengambil konten HTML.
csharpCopy
using System;
using RestSharp;
class Program
{
static void Main()
{
// Membuat instance RestClient baru dengan URL target
var client = new RestClient("https://www.example.com");
// Membuat instance RestRequest baru dengan metode GET
var request = new RestRequest(Method.GET);
// Menjalankan permintaan dan mendapatkan respons
IRestResponse response = client.Execute(request);
// Memeriksa apakah permintaan berhasil
if (response.IsSuccessful)
{
// Mencetak konten HTML dari respons
Console.WriteLine(response.Content);
}
else
{
Console.WriteLine("Gagal mengambil konten");
}
}
}
Mem-parsing Konten HTML
Selanjutnya, kita akan menggunakan HtmlAgilityPack untuk mem-parsing konten HTML dan mengekstrak informasi yang kita butuhkan.
csharpCopy
using HtmlAgilityPack;
using System;
using RestSharp;
class Program
{
static void Main()
{
// Membuat instance RestClient baru dengan URL target
var client = new RestClient("https://www.example.com");
// Membuat instance RestRequest baru dengan metode GET
var request = new RestRequest(Method.GET);
// Menjalankan permintaan dan mendapatkan respons
IRestResponse response = client.Execute(request);
// Memeriksa apakah permintaan berhasil
if (response.IsSuccessful)
{
// Memuat konten HTML ke dalam HtmlDocument
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(response.Content);
// Memilih node yang sesuai dengan query XPath yang ditentukan
var nodes = htmlDoc.DocumentNode.SelectNodes("//h1");
// Melalui node yang dipilih dan mencetak teks dalamnya
foreach (var node in nodes)
{
Console.WriteLine(node.InnerText);
}
}
else
{
Console.WriteLine("Gagal mengambil konten");
}
}
}
Mem-parsing HTML Lanjutan
Mari kita lanjutkan dengan mengambil data yang lebih kompleks dari situs web contoh. Asumsikan kita ingin mengambil daftar artikel dengan judul dan tautan dari halaman blog.
csharpCopy
using HtmlAgilityPack;
using System;
using RestSharp;
class Program
{
static void Main()
{
// Membuat instance RestClient baru dengan URL target
var client = new RestClient("https://www.example.com/blog");
// Membuat instance RestRequest baru dengan metode GET
var request = new RestRequest(Method.GET);
// Menjalankan permintaan dan mendapatkan respons
IRestResponse response = client.Execute(request);
// Memeriksa apakah permintaan berhasil
if (response.IsSuccessful)
{
// Memuat konten HTML ke dalam HtmlDocument
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(response.Content);
// Memilih node yang sesuai dengan query XPath yang ditentukan
var nodes = htmlDoc.DocumentNode.SelectNodes("//div[@class='post']");
// Melalui node yang dipilih dan mengekstrak judul dan tautan
foreach (var node in nodes)
{
var titleNode = node.SelectSingleNode(".//h2/a");
var title = titleNode.InnerText;
var link = titleNode.Attributes["href"].Value;
Console.WriteLine("Judul: " + title);
Console.WriteLine("Tautan: " + link);
Console.WriteLine();
}
}
else
{
Console.WriteLine("Gagal mengambil konten");
}
}
}
Dalam contoh ini, kita mengambil halaman blog, memilih judul dan tautan setiap artikel. Query XPath //div[@class='post'] digunakan untuk menemukan artikel individu.
4. Cara Mengelola Data yang Di-scrap
Simpan data tersebut ke dalam database untuk memudahkan pencarian kapan pun diperlukan.
Ubah data menjadi format JSON dan gunakan untuk memanggil berbagai API.
Ubah data menjadi format yang mudah dibaca manusia seperti CSV, yang dapat dibuka dengan Excel.
Ini hanyalah beberapa contoh. Poin utamanya adalah bahwa setelah Anda memiliki data yang di-scrap dalam kode Anda, Anda dapat memanfaatkannya sesuai kebutuhan. Secara umum, data yang di-scrap diubah menjadi format yang lebih berguna bagi tim pemasaran, analisis data, atau penjualan Anda.
Namun, ingatlah bahwa web scraping memiliki tantangan tersendiri.
5. Menangani CAPTCHA dalam Web Scraping
Salah satu tantangan terbesar dalam web scraping adalah menghadapi CAPTCHA, yang dirancang untuk membedakan pengguna manusia dari bot. Jika Anda menemui CAPTCHA, skrip scraping Anda perlu menyelesaikannya untuk melanjutkan. Terutama jika Anda ingin memperluas web scraping Anda, CapSolver hadir untuk membantu Anda melalui akurasi tinggi dan penyelesaian cepat CAPTCHA apa pun yang mungkin Anda temui.
Mengintegrasikan Penyelesai CAPTCHA
Ada beberapa layanan penyelesai CAPTCHA yang tersedia yang dapat diintegrasikan ke dalam skrip scraping Anda. Di sini, kita akan menggunakan layanan CapSolver. Pertama, Anda perlu mendaftar untuk CapSolver dan mendapatkan kunci API Anda.
Langkah. 1: Daftar ke CapSolver
Sebelum Anda siap menggunakan layanan CapSolver, Anda perlu pergi ke panel pengguna dan daftar akun Anda.
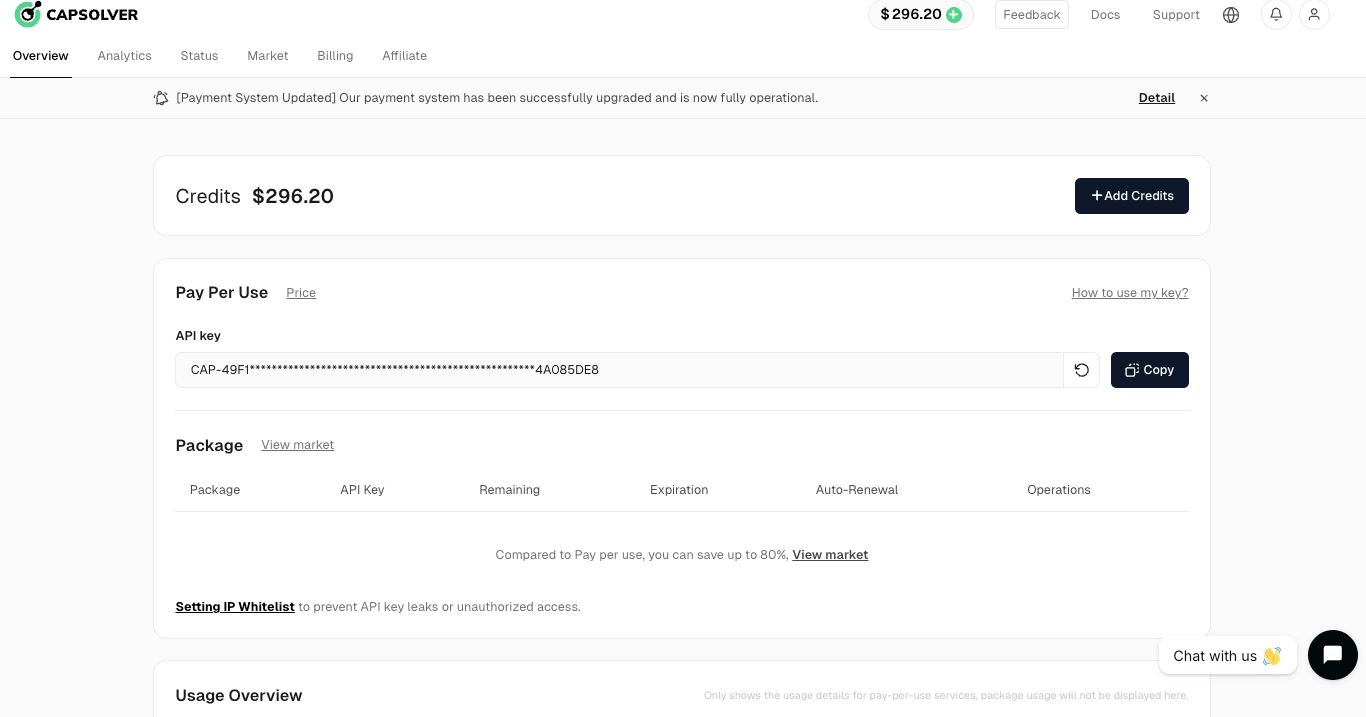
Langkah. 2: Dapatkan Kunci API Anda
Setelah Anda mendaftar, Anda dapat mendapatkan kunci API Anda dari panel beranda
Contoh Kode untuk CapSolver
Menggunakan CapSolver dalam proyek web scraping atau otomasi Anda sangat sederhana. Berikut contoh cepat dalam Python untuk menunjukkan bagaimana Anda dapat mengintegrasikan CapSolver ke dalam alur kerja Anda:
pythonCopy
# pip install requests
import requests
import time
# TODO: atur konfigurasi Anda
api_key = "KUNCI_API_ANDA" # kunci API CapSolver Anda
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # site key dari situs target Anda
site_url = "" # URL halaman dari situs target Anda
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("Gagal membuat tugas:", res.text)
return
print(f"Dapatkan taskId: {task_id} / Mendapatkan hasil...")
while True:
time.sleep(3) # jeda
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("Penyelesaian gagal! respons:", res.text)
return
token = capsolver()
print(token)
Dalam contoh ini, fungsi capsolver mengirim permintaan ke API CapSolver dengan parameter yang diperlukan dan mengembalikan solusi CAPTCHA. Integrasi sederhana ini dapat menghemat banyak jam dan usaha dalam menyelesaikan CAPTCHA secara manual selama tugas web scraping dan otomasi.
6. Kesimpulan
Web scraping dalam C# memberdayakan pengembang dengan kerangka kerja yang kuat untuk mengekstrak data dari situs web secara efisien. Dengan memanfaatkan pustaka seperti HtmlAgilityPack dan RestSharp, serta layanan penyelesai CAPTCHA seperti CapSolver, pengembang dapat menavigasi halaman web, mem-parsing konten HTML, dan menangani tantangan secara mulus. Kemampuan ini tidak hanya menyederhanakan proses pengumpulan data tetapi juga memastikan kepatuhan terhadap praktik scraping etis, meningkatkan keandalan dan skalabilitas proyek web scraping dalam berbagai aplikasi.