Scrapy vs. Selenium: Mana yang Terbaik untuk Proyek Scraping Web Anda?

Emma Foster
Machine Learning Engineer

TL;DR
Scrapy dan Selenium adalah dua alat populer untuk pengambilan data web, masing-masing cocok untuk kasus penggunaan yang berbeda. Scrapy adalah kerangka kerja Python yang cepat, ringan, dan skalabel yang ideal untuk pengambilan data skala besar dari situs web statis. Di sisi lain, Selenium mengotomasi browser nyata dan unggul dalam mengambil data dari halaman dinamis yang berat JavaScript dan memerlukan interaksi pengguna. Pilihan yang tepat bergantung pada kompleksitas proyek, kebutuhan kinerja, dan kebutuhan interaksi, dan kedua alat ini mungkin menghadapi tantangan CAPTCHA yang dapat diatasi dengan layanan seperti CapSolver.
Pendahuluan
Pengambilan data web adalah teknik penting untuk mengumpulkan data dari internet, dan semakin populer di kalangan pengembang, peneliti, dan bisnis. Dua alat paling umum yang digunakan untuk pengambilan data web adalah Scrapy dan Selenium. Masing-masing memiliki kekuatan dan kelemahannya, membuatnya cocok untuk jenis proyek yang berbeda. Dalam artikel ini, kami akan membandingkan Scrapy dan Selenium untuk membantu Anda menentukan alat mana yang terbaik untuk kebutuhan pengambilan data web Anda.
Apa itu Scrapy
Scrapy adalah kerangka kerja pengambilan data web yang kuat dan cepat yang ditulis dalam Python. Dirancang untuk mengambil halaman web dan mengekstrak data terstruktur dari mereka. Scrapy sangat efisien, skalabel, dan dapat dikustomisasi, membuatnya menjadi pilihan yang sangat baik untuk proyek pengambilan data skala besar.
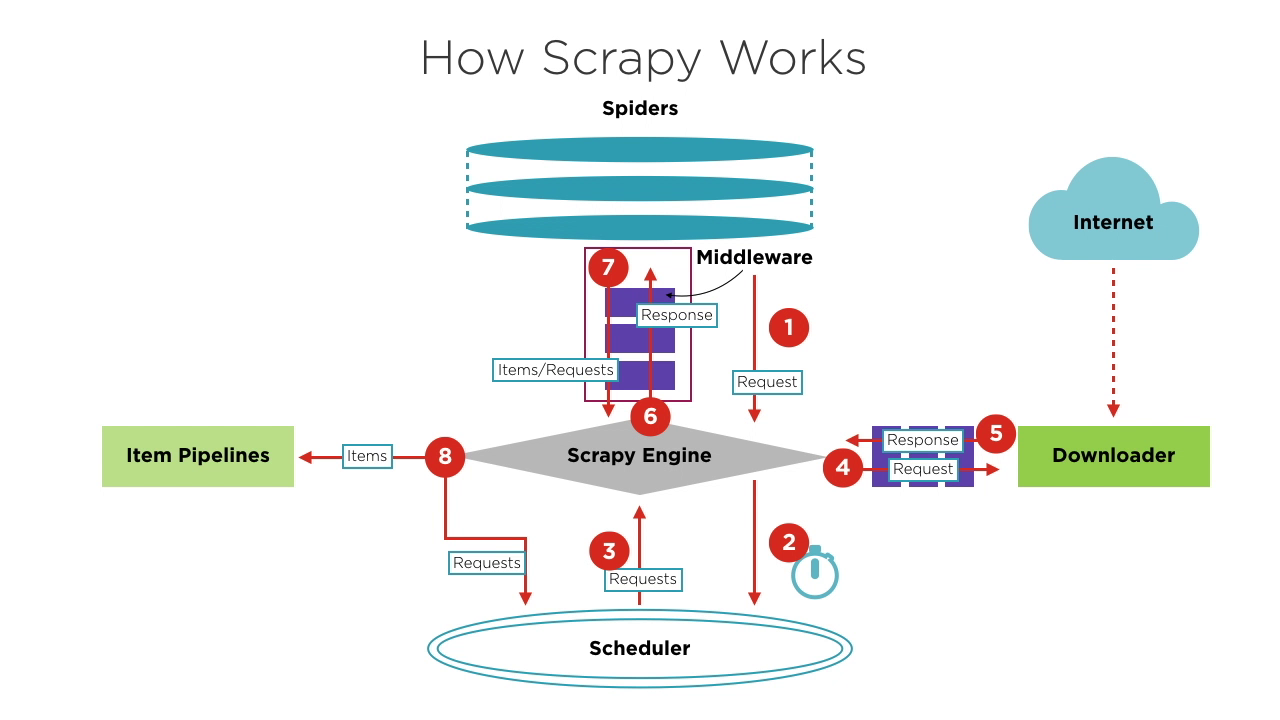
Komponen Scrapy
- Scrapy Engine: Inti dari kerangka kerja, mengelola aliran data dan peristiwa dalam sistem. Seperti otak, menangani transfer data dan pemrosesan logika.
- Scheduler: Menerima permintaan dari mesin, menumpuknya, dan mengirimkannya kembali ke mesin untuk dijalankan oleh downloader. Memelihara logika penjadwalan, seperti FIFO (First In First Out), LIFO (Last In First Out), dan antrean prioritas.
- Spiders: Menentukan logika pengambilan dan parsing halaman. Setiap spider bertanggung jawab atas memproses respons, menghasilkan item, dan permintaan baru untuk dikirim ke mesin.
- Downloader: Menangani pengiriman permintaan ke server dan menerima respons, yang kemudian dikembalikan ke mesin.
- Item Pipelines: Memproses item yang diekstrak oleh spider, melakukan tugas seperti pembersihan data, validasi, dan penyimpanan.
- Middlewares:
- Downloader Middlewares: Berada di antara mesin dan downloader, menangani permintaan dan respons.
- Spider Middlewares: Berada di antara mesin dan spider, menangani item, permintaan, dan respons.
Kesulitan dengan kegagalan berulang dalam menyelesaikan CAPTCHA yang mengganggu? Temukan solusi CAPTCHA otomatis dengan teknologi Web Unblock AI CapSolver!
Kurangi anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAPN saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan tambahan 5% bonus pada setiap pengisian ulang — tanpa batas.
Klaim sekarang di Dashboard CapSolver Anda.
.
Alur Kerja Dasar Proyek Scrapy
-
Ketika memulai proyek penjelajahan, Engine menemukan Spider yang menangani situs target berdasarkan situs yang akan dijelajahi. Spider menghasilkan satu atau lebih permintaan awal yang sesuai dengan halaman yang perlu dijelajahi dan mengirimkannya ke Engine.
-
Engine mendapatkan permintaan ini dari Spider dan kemudian mengirimkannya ke Scheduler untuk menunggu penjadwalan.
-
Engine meminta Scheduler untuk permintaan berikutnya yang akan diproses. Pada titik ini, Scheduler memilih permintaan yang sesuai berdasarkan logika penjadwalannya dan mengirimkannya ke Engine.
-
Engine mengirimkan permintaan dari Scheduler ke Downloader untuk eksekusi unduhan. Proses pengiriman permintaan ke Downloader melewati pemrosesan banyak Downloader Middlewares yang telah ditentukan sebelumnya.
-
Downloader mengirimkan permintaan ke server target, menerima respons yang sesuai, dan kemudian mengembalikannya ke Engine. Proses pengembalian respons ke Engine juga melewati pemrosesan banyak Downloader Middlewares yang telah ditentukan sebelumnya.
-
Respons yang diterima Engine dari Downloader berisi konten situs target. Engine akan mengirimkan respons ini ke Spider yang sesuai untuk diproses. Proses pengiriman respons ke Spider melewati pemrosesan Spider Middlewares yang telah ditentukan sebelumnya.
-
Spider memproses respons, menguraikan isinya. Pada titik ini, Spider akan menghasilkan satu atau lebih item hasil pengambilan atau satu atau lebih permintaan yang sesuai dengan halaman target berikutnya yang akan dijelajahi. Kemudian, Spider mengirimkan item atau permintaan ini kembali ke Engine untuk diproses. Proses pengiriman item atau permintaan ke Engine melewati pemrosesan Spider Middlewares yang telah ditentukan sebelumnya.
-
Engine mengirimkan satu atau lebih item yang dikembalikan oleh Spider ke Pipeline Item yang telah ditentukan untuk serangkaian operasi pemrosesan atau penyimpanan data. Engine juga mengirimkan satu atau lebih permintaan yang dikembalikan oleh Spider ke Scheduler untuk menunggu penjadwalan berikutnya.
Langkah 2 hingga 8 diulang hingga tidak ada lagi permintaan di Scheduler. Pada titik ini, Engine akan menutup Spider, dan seluruh proses penjelajahan berakhir.
Secara keseluruhan, setiap komponen hanya fokus pada satu fungsi, keterikatan antar komponen sangat rendah, dan sangat mudah diperluas. Engine kemudian menggabungkan berbagai komponen, memungkinkan setiap komponen untuk menjalankan tugasnya, bekerja sama, dan menyelesaikan pekerjaan penjelajahan bersama. Selain itu, dengan dukungan Scrapy untuk pemrosesan asinkron, dapat memaksimalkan penggunaan bandwidth jaringan dan meningkatkan efisiensi pengambilan dan pemrosesan data.
Apa itu Selenium?
Selenium adalah alat otomasi web open-source yang memungkinkan Anda mengontrol browser web secara programatis. Meskipun secara utama digunakan untuk pengujian aplikasi web, Selenium juga populer untuk pengambilan data web karena dapat berinteraksi dengan situs web yang berat JavaScript yang sulit diambil dengan metode tradisional. Penting untuk dicatat bahwa Selenium hanya dapat menguji aplikasi web. Kita tidak dapat menggunakan Selenium untuk menguji aplikasi desktop (perangkat lunak) atau aplikasi seluler.
Inti dari Selenium adalah Selenium WebDriver, yang menyediakan antarmuka pemrograman yang memungkinkan pengembang menulis kode untuk mengontrol perilaku dan interaksi browser. Alat ini sangat populer dalam pengembangan dan pengujian web karena mendukung berbagai browser dan dapat berjalan di berbagai sistem operasi. Selenium WebDriver memungkinkan pengembang untuk mensimulasikan tindakan pengguna di browser, seperti mengklik tombol, mengisi formulir, dan menavigasi halaman.
Selenium WebDriver menawarkan fitur yang kaya, membuatnya menjadi pilihan yang ideal untuk pengujian otomasi web.
Fitur Utama Selenium WebDriver
-
Kontrol Browser: Selenium WebDriver mendukung berbagai browser utama, termasuk Chrome, Firefox, Safari, Edge, dan Internet Explorer. Ini dapat menjalankan dan mengontrol browser ini, melakukan operasi seperti membuka halaman web, mengklik elemen, memasukkan teks, dan mengambil tangkapan layar.
-
Kemampuan Multi-platform: Selenium WebDriver dapat berjalan di berbagai sistem operasi, termasuk Windows, macOS, dan Linux. Ini sangat berguna dalam pengujian multi-platform, memungkinkan pengembang memastikan aplikasi mereka berjalan konsisten di berbagai lingkungan.
-
Dukungan Bahasa Pemrograman: Selenium WebDriver mendukung berbagai bahasa pemrograman, termasuk Java, Python, C#, Ruby, dan JavaScript. Pengembang dapat memilih bahasa yang mereka kuasai untuk menulis skrip pengujian otomatis, sehingga meningkatkan efisiensi pengembangan dan pengujian.
-
Interaksi Elemen Web: Selenium WebDriver menyediakan API yang kaya untuk menemukan dan memanipulasi elemen halaman web. Ini mendukung penemuan elemen melalui berbagai metode seperti ID, nama kelas, nama tag, selector CSS, XPath, dll. Pengembang dapat menggunakan API ini untuk menerapkan operasi seperti mengklik, memasukkan, memilih, dan menyeret serta melempar.
Perbandingan Scrapy dan Selenium
| Fitur | Scrapy | Selenium |
|---|---|---|
| Tujuan | Hanya pengambilan data web | Pengambilan data web dan pengujian web |
| Dukungan Bahasa | Hanya Python | Java, Python, C#, Ruby, JavaScript, dll. |
| Kecepatan Eksekusi | Cepat | Lebih lambat |
| Ekstensibilitas | Tinggi | Terbatas |
| Dukungan Asinkron | Ya | Tidak |
| Rendering Dinamis | Tidak | Ya |
| Interaksi Browser | Tidak | Ya |
| Konsumsi Sumber Daya Memori | Rendah | Tinggi |
Memilih Antara Scrapy dan Selenium
-
Pilih Scrapy jika:
- Tujuan Anda adalah halaman web statis tanpa rendering dinamis.
- Anda perlu mengoptimalkan konsumsi sumber daya dan kecepatan eksekusi.
- Anda membutuhkan pemrosesan data yang luas dan middleware kustom.
-
Pilih Selenium jika:
- Situs web yang Anda tuju melibatkan konten dinamis dan memerlukan interaksi.
- Efisiensi eksekusi dan konsumsi sumber daya kurang menjadi perhatian.
Pemilihan antara Scrapy dan Selenium bergantung pada skenario aplikasi spesifik, membandingkan kelebihan dan kekurangan berbagai pilihan, tentukan yang paling sesuai untuk Anda, tentu saja, jika keterampilan pemrograman Anda cukup baik, Anda bahkan dapat menggabungkan Scrapy dan Selenium secara bersamaan.
Tantangan dengan Scrapy dan Selenium
Baik menggunakan Scrapy maupun Selenium, Anda mungkin menghadapi masalah yang sama: tantangan bot. Tantangan bot digunakan secara luas untuk membedakan antara komputer dan manusia, mencegah akses bot jahat ke situs web, dan melindungi data dari pengambilan data. Tantangan bot umum termasuk captcha, reCaptcha, captcha, captcha, Cloudflare Turnstile, captcha, captcha WAF, dan lainnya. Mereka menggunakan gambar kompleks dan tantangan JavaScript yang sulit dibaca untuk menentukan apakah Anda adalah bot. Beberapa tantangan bahkan sulit bagi manusia untuk melewatinya.
Seperti kata pepatah, "Setiap orang punya keahlian masing-masing." Munculnya CapSolver telah membuat masalah ini lebih sederhana. CapSolver menggunakan teknologi web unlock otomatis berbasis AI yang dapat membantu Anda menyelesaikan berbagai tantangan bot dalam hitungan detik. Tidak peduli jenis tantangan gambar atau pertanyaan yang Anda temui, Anda dapat yakin menyerahkan semuanya kepada CapSolver. Jika tidak berhasil, Anda tidak akan dikenakan biaya.
CapSolver menyediakan ekstensi browser yang dapat secara otomatis menyelesaikan tantangan CAPTCHA selama proses pengambilan data berbasis Selenium Anda. Ia juga menawarkan metode API untuk menyelesaikan CAPTCHAs dan mendapatkan token, memungkinkan Anda mengelola berbagai tantangan dalam Scrapy dengan mudah. Semua pekerjaan ini dapat diselesaikan dalam beberapa detik. Lihat dokumentasi CapSolver untuk informasi lebih lanjut.
Kesimpulan
Pemilihan antara Scrapy dan Selenium bergantung pada kebutuhan proyek Anda. Scrapy ideal untuk mengambil data situs statis secara efisien, sementara Selenium unggul dalam halaman dinamis yang berat JavaScript. Pertimbangkan kebutuhan spesifik, seperti kecepatan, penggunaan sumber daya, dan tingkat interaksi. Untuk mengatasi tantangan seperti CAPTCHA, alat seperti CapSolver menawarkan solusi efisien, membuat proses pengambilan data menjadi lebih mulus. Pada akhirnya, pilihan yang tepat memastikan proyek pengambilan data yang sukses dan efisien.
FAQ
1. Apakah Scrapy dan Selenium dapat digunakan bersama dalam satu proyek?
Ya. Pendekatan umum adalah menggunakan Selenium untuk menangani rendering JavaScript atau interaksi kompleks (seperti alur login), lalu mengirimkan HTML yang dirender atau URL yang diekstrak ke Scrapy untuk penjelajahan dan ekstraksi data skala besar dengan kecepatan tinggi. Model hibrid ini menggabungkan fleksibilitas Selenium dengan kinerja Scrapy.
2. Apakah Scrapy cocok untuk situs web modern yang berat JavaScript?
Secara default, Scrapy tidak mengeksekusi JavaScript, yang membuatnya tidak cocok untuk situs yang bergantung pada rendering sisi klien. Namun, Scrapy dapat diperluas menggunakan alat seperti Playwright, Splash, atau Selenium untuk menangani konten JavaScript ketika diperlukan.
3. Alat mana yang lebih efisien dalam penggunaan sumber daya untuk pengambilan data skala besar?
Scrapy jauh lebih efisien dalam penggunaan sumber daya dibandingkan Selenium. Ia menggunakan jaringan asinkron dan tidak memerlukan peluncuran browser, membuatnya lebih cocok untuk tugas pengambilan data skala besar dengan volume tinggi. Selenium mengonsumsi lebih banyak CPU dan memori karena mengontrol browser nyata, yang membatasi skalabilitas.
Lihat Lebih Banyak
Web ScrapingApr 22, 2026
Arsitektur Pengambilan Data Web Rust untuk Ekstraksi Data yang Dapat Diskalakan
Pelajari arsitektur pengambilan data web Rust yang dapat diskalakan dengan reqwest, scraper, pengambilan data asinkron, pengambilan data browser tanpa tampilan, rotasi proxy, dan penanganan CAPTCHA yang sesuai aturan.
Web ScrapingFeb 17, 2026
Cara menyelesaikan Captcha di Nanobot dengan CapSolver
Mengotomasi penyelesaian CAPTCHA dengan Nanobot dan CapSolver. Gunakan Playwright untuk menyelesaikan reCAPTCHA dan Cloudflare secara otomatis.

