Mengintegrasikan Crawlab dengan CapSolver: Penyelesaian CAPTCHA Otomatis untuk Penjelajahan Terdistribusi

Ethan Collins
Pattern Recognition Specialist

Mengelola crawler web dalam skala besar memerlukan infrastruktur yang kuat yang dapat menangani tantangan anti-bot modern. Crawlab adalah platform manajemen crawler web terdistribusi yang kuat, dan CapSolver adalah layanan penyelesaian CAPTCHA berbasis AI. Bersama-sama, mereka memungkinkan sistem pencarian web tingkat perusahaan yang secara otomatis melewati tantangan CAPTCHA.
Panduan ini menyediakan contoh kode lengkap dan siap pakai untuk mengintegrasikan CapSolver ke dalam spider Crawlab Anda.
Apa yang Akan Anda Pelajari
- Menyelesaikan reCAPTCHA v2 dengan Selenium
- Menyelesaikan Cloudflare Turnstile
- Integrasi middleware Scrapy
- Integrasi Node.js/Puppeteer
- Praktik terbaik untuk penanganan CAPTCHA dalam skala besar
Apa itu Crawlab?
Crawlab adalah platform admin crawler web terdistribusi yang dirancang untuk mengelola spider di berbagai bahasa pemrograman.
Fitur Utama
- Tidak Bergantung Bahasa: Mendukung Python, Node.js, Go, Java, dan PHP
- Fleksibel dalam Kerangka Kerja: Bekerja dengan Scrapy, Selenium, Puppeteer, Playwright
- Arsitektur Terdistribusi: Penskalaan horizontal dengan node master/worker
- Antarmuka Manajemen: Antarmuka web untuk pengelolaan dan penjadwalan spider
Instalasi
bash
# Menggunakan Docker Compose
git clone https://github.com/crawlab-team/crawlab.git
cd crawlab
docker-compose up -dAkses antarmuka UI di http://localhost:8080 (default: admin/admin).
Apa itu CapSolver?
CapSolver adalah layanan penyelesaian CAPTCHA berbasis AI yang menyediakan solusi cepat dan andal untuk berbagai jenis CAPTCHA.
Jenis CAPTCHA yang Didukung
- reCAPTCHA: v2, v3, dan Enterprise
- Cloudflare: Turnstile dan Challenge
- AWS WAF: Bypass perlindungan
- Dan Lebih Banyak
Alur Kerja API
- Kirim parameter CAPTCHA (tipe, siteKey, URL)
- Terima ID tugas
- Periksa hasil
- Sisipkan token ke halaman
Prasyarat
- Python 3.8+ atau Node.js 16+
- Kunci API CapSolver - Daftar di sini
- Browser Chrome/Chromium
bash
# Ketergantungan Python
pip install selenium requestsMenyelesaikan reCAPTCHA v2 dengan Selenium
Skrip Python lengkap untuk menyelesaikan tantangan reCAPTCHA v2:
python
"""
Crawlab + CapSolver: Pemecah reCAPTCHA v2
Skrip lengkap untuk menyelesaikan tantangan reCAPTCHA v2 dengan Selenium
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Konfigurasi
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'KUNCI_API_YOUR_CAPSOLVER')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverClient:
"""Klien API CapSolver untuk reCAPTCHA v2"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def create_task(self, task: dict) -> str:
"""Buat tugas penyelesaian CAPTCHA"""
payload = {
"clientKey": self.api_key,
"task": task
}
response = self.session.post(
f"{CAPSOLVER_API}/createTask",
json=payload
)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Kesalahan CapSolver: {result.get('errorDescription')}")
return result['taskId']
def get_task_result(self, task_id: str, timeout: int = 120) -> dict:
"""Periksa hasil tugas"""
for _ in range(timeout):
payload = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(
f"{CAPSOLVER_API}/getTaskResult",
json=payload
)
result = response.json()
if result.get('status') == 'ready':
return result['solution']
if result.get('status') == 'failed':
raise Exception("Penyelesaian CAPTCHA gagal")
time.sleep(1)
raise Exception("Waktu menunggu solusi habis")
def solve_recaptcha_v2(self, website_url: str, site_key: str) -> str:
"""Selesaikan reCAPTCHA v2 dan kembalikan token"""
task = {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
print(f"Membuat tugas untuk {website_url}...")
task_id = self.create_task(task)
print(f"Tugas dibuat: {task_id}")
print("Menunggu solusi...")
solution = self.get_task_result(task_id)
return solution['gRecaptchaResponse']
def get_balance(self) -> float:
"""Dapatkan saldo akun"""
response = self.session.post(
f"{CAPSOLVER_API}/getBalance",
json={"clientKey": self.api_key}
)
return response.json().get('balance', 0)
class RecaptchaV2Crawler:
"""Crawler Selenium dengan dukungan reCAPTCHA v2"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.capsolver = CapsolverClient(CAPSOLVER_API_KEY)
def start(self):
"""Inisialisasi browser"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--window-size=1920,1080")
self.driver = webdriver.Chrome(options=options)
print("Browser dimulai")
def stop(self):
"""Tutup browser"""
if self.driver:
self.driver.quit()
print("Browser ditutup")
def detect_recaptcha(self) -> str:
"""Deteksi reCAPTCHA dan kembalikan kunci situs"""
try:
element = self.driver.find_element(By.CLASS_NAME, "g-recaptcha")
return element.get_attribute("data-sitekey")
except:
return None
def inject_token(self, token: str):
"""Sisipkan token yang telah diselesaikan ke halaman"""
self.driver.execute_script(f"""
// Atur textarea g-recaptcha-response
var responseField = document.getElementById('g-recaptcha-response');
if (responseField) {{
responseField.style.display = 'block';
responseField.value = '{token}';
}}
// Atur semua field respons tersembunyi
var textareas = document.querySelectorAll('textarea[name="g-recaptcha-response"]');
for (var i = 0; i < textareas.length; i++) {{
textareas[i].value = '{token}';
}}
""")
print("Token disisipkan")
def submit_form(self):
"""Kirim formulir"""
try:
submit = self.driver.find_element(
By.CSS_SELECTOR,
'button[type="submit"], input[type="submit"]'
)
submit.click()
print("Formulir dikirim")
except Exception as e:
print(f"Tidak dapat mengirim formulir: {e}")
def crawl(self, url: str) -> dict:
"""Crawl URL dengan penanganan reCAPTCHA v2"""
result = {
'url': url,
'success': False,
'captcha_solved': False
}
try:
print(f"Mengunjungi: {url}")
self.driver.get(url)
time.sleep(2)
# Deteksi reCAPTCHA
site_key = self.detect_recaptcha()
if site_key:
print(f"reCAPTCHA v2 terdeteksi! Kunci situs: {site_key}")
# Selesaikan CAPTCHA
token = self.capsolver.solve_recaptcha_v2(url, site_key)
print(f"Token diterima: {token[:50]}...")
# Sisipkan token
self.inject_token(token)
result['captcha_solved'] = True
# Kirim formulir
self.submit_form()
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
result['error'] = str(e)
print(f"Kesalahan: {e}")
return result
def main():
"""Titik masuk utama"""
# Periksa saldo
client = CapsolverClient(CAPSOLVER_API_KEY)
print(f"Saldo CapSolver: ${client.get_balance():.2f}")
# Buat crawler
crawler = RecaptchaV2Crawler(headless=True)
try:
crawler.start()
# Crawl URL target (ganti dengan target Anda)
result = crawler.crawl("https://example.com/protected-page")
print("\n" + "=" * 50)
print("HASIL:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Menyelesaikan Cloudflare Turnstile
Skrip Python lengkap untuk menyelesaikan Cloudflare Turnstile:
python
"""
Crawlab + CapSolver: Pemecah Cloudflare Turnstile
Skrip lengkap untuk menyelesaikan tantangan Turnstile
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
# Konfigurasi
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'KUNCI_API_YOUR_CAPSOLVER')
CAPSOLVER_API = 'https://api.capsolver.com'
class TurnstileSolver:
"""Klien CapSolver untuk Turnstile"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def solve(self, website_url: str, site_key: str) -> str:
"""Selesaikan CAPTCHA Turnstile"""
print(f"Menyelesaikan Turnstile untuk {website_url}")
print(f"Kunci situs: {site_key}")
# Buat tugas
task_data = {
"clientKey": self.api_key,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
}
response = self.session.post(f"{CAPSOLVER_API}/createTask", json=task_data)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Kesalahan CapSolver: {result.get('errorDescription')}")
task_id = result['taskId']
print(f"Tugas dibuat: {task_id}")
# Periksa hasil
for i in range(120):
result_data = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(f"{CAPSOLVER_API}/getTaskResult", json=result_data)
result = response.json()
if result.get('status') == 'ready':
token = result['solution']['token']
print(f"Turnstile diselesaikan!")
return token
if result.get('status') == 'failed':
raise Exception("Penyelesaian Turnstile gagal")
time.sleep(1)
raise Exception("Waktu menunggu solusi habis")
class TurnstileCrawler:
"""Crawler Selenium dengan dukungan Turnstile"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.solver = TurnstileSolver(CAPSOLVER_API_KEY)
def start(self):
"""Inisialisasi browser"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
self.driver = webdriver.Chrome(options=options)
def stop(self):
"""Tutup browser"""
if self.driver:
self.driver.quit()
def detect_turnstile(self) -> str:
"""Deteksi Turnstile dan kembalikan kunci situs"""
try:
turnstile = self.driver.find_element(By.CLASS_NAME, "cf-turnstile")
return turnstile.get_attribute("data-sitekey")
except NoSuchElementException:
return None
def inject_token(self, token: str):
"""Sisipkan token Turnstile"""
self.driver.execute_script(f"""
var token = '{token}';
// Cari field cf-turnstile-response
var field = document.querySelector('[name="cf-turnstile-response"]');
if (field) {{
field.value = token;
}}
// Cari semua input Turnstile
var inputs = document.querySelectorAll('input[name*="turnstile"]');
for (var i = 0; i < inputs.length; i++) {{
inputs[i].value = token;
}}
""")
print("Token disisipkan!")
def crawl(self, url: str) -> dict:
"""Crawl URL dengan penanganan Turnstile"""
result = {
'url': url,
'success': False,
'captcha_solved': False,
'captcha_type': None
}
try:
print(f"Mengunjungi: {url}")
self.driver.get(url)
time.sleep(3)
# Deteksi Turnstile
site_key = self.detect_turnstile()
if site_key:
result['captcha_type'] = 'turnstile'
print(f"Turnstile terdeteksi! Kunci situs: {site_key}")
# Selesaikan
token = self.solver.solve(url, site_key)
# Sisipkan
self.inject_token(token)
result['captcha_solved'] = True
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
print(f"Kesalahan: {e}")
result['error'] = str(e)
return result
def main():
"""Titik masuk utama"""
crawler = TurnstileCrawler(headless=True)
try:
crawler.start()
# Crawl target (ganti dengan URL target Anda)
result = crawler.crawl("https://example.com/turnstile-protected")
print("\n" + "=" * 50)
print("HASIL:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Integrasi Scrapy
Spider Scrapy lengkap dengan middleware CapSolver:
python
"""
Crawlab + CapSolver: Spider Scrapy
Spider Scrapy lengkap dengan middleware penyelesaian CAPTCHA
"""
import scrapy
import requests
import time
import os
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'KUNCI_API_YOUR_CAPSOLVER')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverMiddleware:
"""Middleware Scrapy untuk penyelesaian CAPTCHA"""
def __init__(self):
self.api_key = CAPSOLVER_API_KEY
def solve_recaptcha_v2(self, url: str, site_key: str) -> str:
"""Selesaikan reCAPTCHA v2"""Membuat tugas
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": self.api_key,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": url,
"websiteKey": site_key
}
}
)
task_id = response.json()['taskId']
# Memantau hasil
for _ in range(120):
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={"clientKey": self.api_key, "taskId": task_id}
).json()
if result.get('status') == 'ready':
return result['solution']['gRecaptchaResponse']
time.sleep(1)
raise Exception("Waktu habis")class CaptchaSpider(scrapy.Spider):
"""Spider dengan penanganan CAPTCHA"""
name = "captcha_spider"
start_urls = ["https://example.com/protected"]
custom_settings = {
'DELAY_PENGUNDUHAN': 2,
'PERMINTAAN_PARALEL': 1,
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.capsolver = CapsolverMiddleware()
def parse(self, response):
# Periksa reCAPTCHA
site_key = response.css('.g-recaptcha::attr(data-sitekey)').get()
if site_key:
self.logger.info(f"reCAPTCHA terdeteksi: {site_key}")
# Selesaikan CAPTCHA
token = self.capsolver.selesaikan_recaptcha_v2(response.url, site_key)
# Kirim formulir dengan token
yield scrapy.FormRequest.from_response(
response,
formdata={'g-recaptcha-response': token},
callback=self.setelah_captcha
)
else:
yield from self ekstrak_data(response)
def setelah_captcha(self, response):
"""Proses halaman setelah CAPTCHA"""
yield from self ekstrak_data(response)
def ekstrak_data(self, response):
"""Ekstrak data dari halaman"""
yield {
'judul': response.css('title::text').get(),
'url': response.url,
}Pengaturan Scrapy (settings.py)
"""
BOT_NAME = 'crawler_captcha'
SPIDER_MODULES = ['spiders']
Capsolver
KUNCI_API_CAPSOLVER = 'KUNCI_API_CAPSOLVER_ANDA'
Pembatas kecepatan
DELAY_PENGUNDUHAN = 2
PERMINTAAN_PARALEL = 1
ROBOTSTXT_OBEY = True
"""
---
## Integrasi Node.js/Puppeteer
Skrip Node.js lengkap dengan Puppeteer:
```javascript
/**
* Crawlab + Capsolver: Spider Puppeteer
* Skrip Node.js lengkap untuk menyelesaikan CAPTCHA
*/
const puppeteer = require('puppeteer');
const KUNCI_API_CAPSOLVER = process.env.KUNCI_API_CAPSOLVER || 'KUNCI_API_CAPSOLVER_ANDA';
const CAPSOLVER_API = 'https://api.capsolver.com';
/**
* Klien Capsolver
*/
class Capsolver {
constructor(kunciAPI) {
this.kunciAPI = kunciAPI;
}
async buatTugas(tugas) {
const response = await fetch(`${CAPSOLVER_API}/createTask`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.kunciAPI,
task: tugas
})
});
const hasil = await response.json();
if (hasil.errorId !== 0) {
throw new Error(hasil.errorDescription);
}
return hasil.taskId;
}
async hasilTugas(taskId, timeout = 120) {
for (let i = 0; i < timeout; i++) {
const response = await fetch(`${CAPSOLVER_API}/getTaskResult`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.kunciAPI,
taskId: taskId
})
});
const hasil = await response.json();
if (hasil.status === 'ready') {
return hasil.solution;
}
if (hasil.status === 'gagal') {
throw new Error('Tugas gagal');
}
await new Promise(r => setTimeout(r, 1000));
}
throw new Error('Waktu habis');
}
async selesaikanRecaptchaV2(url, siteKey) {
const taskId = await this.buatTugas({
type: 'ReCaptchaV2TaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solusi = await this.hasilTugas(taskId);
return solusi.gRecaptchaResponse;
}
async selesaikanTurnstile(url, siteKey) {
const taskId = await this.buatTugas({
type: 'AntiTurnstileTaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solusi = await this.hasilTugas(taskId);
return solusi.token;
}
}
/**
* Fungsi utama untuk mengambil data
*/
async function ambilData(url) {
const capsolver = new Capsolver(KUNCI_API_CAPSOLVER);
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
try {
console.log(`Mengambil data: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
// Deteksi jenis CAPTCHA
const informasiCAPTCHA = await page.evaluate(() => {
const recaptcha = document.querySelector('.g-recaptcha');
if (recaptcha) {
return {
jenis: 'recaptcha',
siteKey: recaptcha.dataset.sitekey
};
}
const turnstile = document.querySelector('.cf-turnstile');
if (turnstile) {
return {
jenis: 'turnstile',
siteKey: turnstile.dataset.sitekey
};
}
return null;
});
if (informasiCAPTCHA) {
console.log(`${informasiCAPTCHA.jenis} terdeteksi!`);
let token;
if (informasiCAPTCHA.jenis === 'recaptcha') {
token = await capsolver.selesaikanRecaptchaV2(url, informasiCAPTCHA.siteKey);
// Sisipkan token
await page.evaluate((t) => {
const field = document.getElementById('g-recaptcha-response');
if (field) field.value = t;
document.querySelectorAll('textarea[name="g-recaptcha-response"]')
.forEach(el => el.value = t);
}, token);
} else if (informasiCAPTCHA.jenis === 'turnstile') {
token = await capsolver.selesaikanTurnstile(url, informasiCAPTCHA.siteKey);
// Sisipkan token
await page.evaluate((t) => {
const field = document.querySelector('[name="cf-turnstile-response"]');
if (field) field.value = t;
}, token);
}
console.log('CAPTCHA selesai dan disisipkan!');
}
// Ekstrak data
const data = await page.evaluate(() => ({
judul: document.title,
url: window.location.href
}));
return data;
} finally {
await browser.close();
}
}
// Eksekusi utama
const urlTarget = process.argv[2] || 'https://example.com';
ambilData(urlTarget)
.then(result => {
console.log('\nHasil:');
console.log(JSON.stringify(result, null, 2));
})
.catch(console.error);Praktik Terbaik
1. Penanganan Kesalahan dengan Pengulangan
python
def selesaikan_dengan_pengulangan(solver, url, site_key, max_pengulangan=3):
"""Selesaikan CAPTCHA dengan logika pengulangan"""
for percobaan in range(max_pengulangan):
try:
return solver.selesaikan(url, site_key)
except Exception as e:
if percobaan == max_pengulangan - 1:
raise
print(f"Percobaan {percobaan + 1} gagal: {e}")
time.sleep(2 ** percobaan) # Backoff eksponensial2. Pengelolaan Biaya
- Deteksi sebelum menyelesaikan: Hanya panggil Capsolver ketika CAPTCHA terdeteksi
- Simpan token: Token reCAPTCHA berlaku selama ~2 menit
- Pantau saldo: Periksa saldo sebelum menjalankan tugas besar
3. Pembatas Kecepatan
python
# Pengaturan Scrapy
DELAY_PENGUNDUHAN = 3
PERMINTAAN_PARALEL_PER_DOMAIN = 14. Variabel Lingkungan
bash
export KUNCI_API_CAPSOLVER="kunci-api-anda-disini"Troubleshooting
| Kesalahan | Penyebab | Solusi |
|---|---|---|
KESALAHAN_SALDO_NOL |
Tidak ada kredit | Top up akun Capsolver |
KESALAHAN_CAPTCHA_TIDAK_SELESAI |
Parameter tidak valid | Verifikasi ekstraksi site key |
TimeoutError |
Masalah jaringan | Tingkatkan waktu tunggu, tambahkan pengulangan |
WebDriverException |
Browser crash | Tambahkan flag --no-sandbox |
FAQ
Q: Berapa lama token CAPTCHA berlaku?
A: Token reCAPTCHA: ~2 menit. Turnstile: bervariasi tergantung situs.
Q: Berapa waktu rata-rata penyelesaian?
A: reCAPTCHA v2: 5-15 detik, Turnstile: 1-10 detik.
Q: Bolehkah saya menggunakan proxy sendiri?
A: Ya, gunakan tipe tugas tanpa akhiran "ProxyLess" dan berikan konfigurasi proxy.
Kesimpulan
Mengintegrasikan Capsolver dengan Crawlab memungkinkan penanganan CAPTCHA yang andal di seluruh infrastruktur crawling terdistribusi Anda. Skrip lengkap di atas dapat langsung dicopy ke spider Crawlab Anda.
Siap memulai? Daftar di Capsolver dan tingkatkan kemampuan crawler Anda!
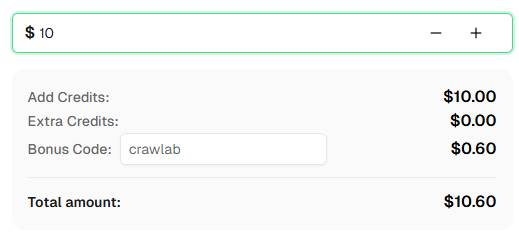
💡 Bonus Khusus untuk Pengguna Integrasi Crawlab:
Untuk merayakan integrasi ini, kami menawarkan kode bonus 6% — Crawlab untuk semua pengguna Capsolver yang mendaftar melalui tutorial ini.
Masukkan kode saat recharge di Dashboard untuk mendapatkan kredit tambahan 6% secara instan.
13. Dokumentasi
- 13.1. Dokumentasi Crawlab
- 13.2. GitHub Crawlab
- 13.3. Dokumentasi Capsolver
- 13.4. Referensi API Capsolver
Lihat Lebih Banyak
Web ScrapingApr 22, 2026
Arsitektur Pengambilan Data Web Rust untuk Ekstraksi Data yang Dapat Diskalakan
Pelajari arsitektur pengambilan data web Rust yang dapat diskalakan dengan reqwest, scraper, pengambilan data asinkron, pengambilan data browser tanpa tampilan, rotasi proxy, dan penanganan CAPTCHA yang sesuai aturan.

Web ScrapingFeb 17, 2026
Cara menyelesaikan Captcha di Nanobot dengan CapSolver
Mengotomasi penyelesaian CAPTCHA dengan Nanobot dan CapSolver. Gunakan Playwright untuk menyelesaikan reCAPTCHA dan Cloudflare secara otomatis.
