Teknik Anti-Deteksi Pengambilan Data Web: Ekstraksi Data yang Stabil

Anh Tuan
Data Science Expert
TL;Dr
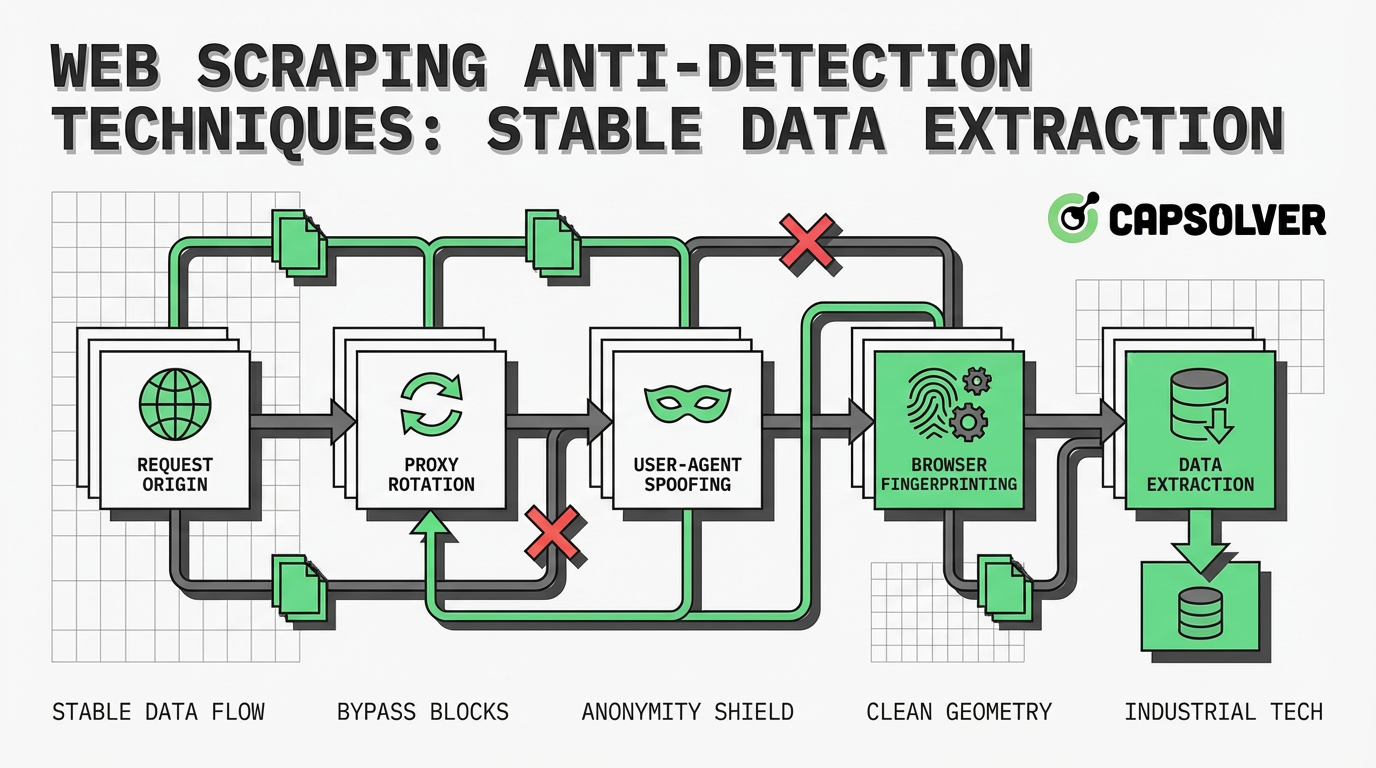
- Rotasi IP & Proksi: Mendistribusikan permintaan melalui proksi residensial atau seluler mencegah pemblokiran dan pembatasan kecepatan berdasarkan IP.
- Optimasi Header: Meniru header browser nyata, terutama User-Agent dan Referer, membantu menghindari filter HTTP dasar.
- Pengurangan Fingerprint Browser: Mengelola fingerprint Canvas, WebGL, dan TLS penting untuk menghindari deteksi perilaku lanjutan.
- Penanganan Tantangan JavaScript: Browser tanpa GUI dapat mengeksekusi JavaScript, tetapi memerlukan konfigurasi yang hati-hati untuk menghindari deteksi.
- Penyelesaian CAPTCHA: Mengintegrasikan layanan penyelesaian CAPTCHA otomatis seperti CapSolver memastikan alur ekstraksi data yang tidak terganggu.
Pendahuluan
Ekstraksi data adalah komponen kritis dalam kecerdasan bisnis modern, tetapi situs web semakin mengimplementasikan pertahanan canggih untuk memblokir akses otomatis. Memahami teknik anti-pendeteksian web scraping kini bukan lagi pilihan bagi pengembang; ini adalah kebutuhan dasar untuk mempertahankan alur data yang stabil dan andal. Panduan ini menjelajahi mekanisme inti di balik deteksi bot, mulai dari pembatasan kecepatan IP dasar hingga fingerprint browser lanjutan. Dengan mengeksplorasi strategi pertahanan ini, insinyur data dan profesional scraping dapat menerapkan metode yang kuat untuk memastikan akses konsisten terhadap informasi publik. Fokus di sini adalah pada pendekatan praktis dan terstruktur untuk menghindari deteksi sambil mempertahankan praktik scraping yang etis dan sesuai regulasi.
Apa Itu Anti-Pendeteksian dalam Web Scraping?
Teknik anti-pendeteksian web scraping merujuk pada metode dan alat yang digunakan oleh pengembang untuk mencegah skrip otomatis mereka diidentifikasi dan diblokir oleh situs target. Ketika scraper mengakses situs web, ia meninggalkan jejak digital. Jika jejak ini menyimpang dari perilaku pengguna manusia biasa, sistem keamanan situs akan menandai aktivitas tersebut sebagai otomatis.
Tujuan utama anti-pendeteksian adalah meniru interaksi manusia seakurat mungkin. Ini mencakup pengelolaan identifikasi tingkat jaringan, seperti alamat IP, dan karakteristik tingkat aplikasi, seperti header HTTP dan fingerprint browser. Tanpa teknik ini, scraper menghadapi pemblokiran IP langsung, tantangan CAPTCHA, atau respons menipu seperti honeypot. Memahami teknologi dasar deteksi bot adalah langkah pertama dalam membangun sistem ekstraksi data yang tangguh.
Bagaimana Situs Web Mendeteksi Scraper?
Administrator situs web menggunakan pendekatan berlapis untuk mengidentifikasi dan mengurangi lalu lintas otomatis. Pertahanan ini bervariasi dari filter berbasis aturan sederhana hingga algoritma pembelajaran mesin kompleks yang menganalisis perilaku pengguna secara real-time.
Alamat IP dan Pembatasan Kecepatan
Metode deteksi paling dasar melibatkan pemantauan frekuensi dan asal permintaan yang masuk. Jika satu alamat IP menghasilkan volume lalu lintas yang tidak biasa dalam periode singkat, server akan memblokirnya. Ini disebut pembatasan kecepatan. Selain itu, situs web sering kali memiliki daftar hitam rentang IP pusat data, segera menandai lalu lintas yang berasal dari sumber ini sebagai mencurigakan.
Analisis Header HTTP
Setiap permintaan HTTP memiliki header yang menyediakan informasi tentang klien. Sistem keamanan meninjau header ini, terutama User-Agent, yang mengidentifikasi browser dan sistem operasi. Scraper yang menggunakan perpustakaan default sering mengirimkan header yang hilang atau tidak biasa. Misalnya, permintaan yang tidak memiliki header Accept-Language atau menampilkan string User-Agent yang usang adalah indikasi kuat aktivitas otomatis.
Pengenalan Fingerprint Browser
Sistem deteksi lanjutan melampaui header untuk menganalisis karakteristik unik browser klien. Teknik ini, dikenal sebagai pengenalan fingerprint browser, mengumpulkan data tentang resolusi layar, font yang terinstal, plugin yang didukung, dan konkurensi perangkat keras. Metode yang lebih canggih melibatkan fingerprinting Canvas dan WebGL, yang memerintahkan browser untuk merender gambar tersembunyi dan menganalisis perbedaan kecil dalam cara perangkat keras memproses grafik. Perbedaan halus ini menciptakan identifikasi yang sangat akurat untuk perangkat.
Analisis Perilaku dan Honeypot
Solusi keamanan modern mengevaluasi bagaimana pengguna berinteraksi dengan halaman. Mereka melacak gerakan mouse, pola penggulungan, dan waktu antara klik. Bot biasanya menunjukkan perilaku linear dan prediktif, sedangkan manusia cenderung tidak teratur. Selain itu, situs web menyebar honeypot—tautan atau bidang formulir tersembunyi yang tidak terlihat bagi pengguna manusia tetapi dapat ditemukan oleh scraper yang menganalisis HTML. Berinteraksi dengan honeypot langsung mengungkap keberadaan bot.
Teknik Anti-Pendeteksian Web Scraping Inti
Untuk mempertahankan ekstraksi data yang stabil, pengembang harus menerapkan strategi yang mengatasi setiap lapisan pertahanan situs web. Metode berikut ini membentuk dasar efektif anti-pendeteksian.
Menerapkan Rotasi IP dan Proksi
Mengandalkan satu alamat IP adalah jalan pasti menuju pemblokiran. Untuk menghindari pembatasan kecepatan dan pemblokiran IP, scraper harus menggunakan jaringan proksi. Dengan mengarahkan permintaan melalui alamat IP berbeda, scraper mendistribusikan lalu lintasnya, membuatnya terlihat seperti beberapa pengguna yang mengakses situs.
Meskipun proksi pusat data cepat dan hemat biaya, mereka mudah diidentifikasi. Untuk target keamanan tinggi, proksi residensial diperlukan. Proksi ini mengarahkan lalu lintas melalui perangkat nyata yang disediakan oleh ISP, menawarkan tingkat kredibilitas yang jauh lebih tinggi. Untuk mempelajari lebih lanjut tentang mengelola alamat IP secara efektif, tinjau panduan ini tentang cara menghindari pemblokiran IP.
Mengoptimalkan Header HTTP
Membuat header HTTP yang realistis sangat penting untuk menghindari filter dasar. String User-Agent harus sesuai dengan browser modern yang umum digunakan. Namun, hanya mengganti User-Agent tidak cukup; seluruh profil header harus konsisten.
Misalnya, jika User-Agent menunjukkan mesin Windows, header Sec-Ch-Ua-Platform juga harus mencerminkan Windows. Termasuk header seperti Accept, Accept-Encoding, dan Referer menambahkan otentisitas ke permintaan. Header Referer, yang menunjukkan halaman sebelumnya yang dikunjungi, dapat diatur ke mesin pencari populer untuk meniru lalu lintas organik. Untuk rekomendasi rinci, konsultasikan sumber ini tentang memilih User-Agent terbaik.
Menggunakan Browser Tanpa GUI
Banyak situs web modern sangat bergantung pada JavaScript untuk merender konten secara dinamis. Klien HTTP tradisional tidak dapat mengeksekusi JavaScript, menghasilkan ekstraksi data yang tidak lengkap. Browser tanpa GUI seperti Puppeteer, Playwright, atau Selenium menyelesaikan masalah ini dengan menjalankan lingkungan browser penuh tanpa antarmuka grafis.
Browser tanpa GUI dapat mengeksekusi JavaScript, menangani konten dinamis, dan berinteraksi dengan halaman seperti pengguna nyata. Namun, konfigurasi default browser tanpa GUI mengungkap variabel yang dapat diidentifikasi, seperti navigator.webdriver = true. Pengembang harus menggunakan plugin stealth atau kerangka kerja khusus untuk menyembunyikan indikator ini dan mencegah browser tanpa GUI terdeteksi.
Mengelola Ritme Permintaan
Untuk mengalahkan analisis perilaku, scraper harus meninggalkan pola permintaan yang terduga. Menerapkan penundaan acak antara permintaan meniru jeda alami yang dilakukan manusia saat membaca atau menjelajah situs. Selain itu, menambahkan gerakan mouse dan tindakan penggulungan acak dalam lingkungan browser tanpa GUI dapat membantu menghindari sistem yang memantau interaksi pengguna.
Ringkasan Perbandingan: Deteksi vs. Mitigasi
| Metode Deteksi | Deskripsi | Strategi Mitigasi |
|---|---|---|
| Pembatasan Kecepatan IP | Memblokir IP yang melebihi ambang batas permintaan tertentu. | Gunakan jaringan proksi residensial atau mobile yang berputar. |
| Filter Header HTTP | Menganalisis header HTTP untuk anomali atau data yang hilang. | Buat header yang konsisten dan modern (User-Agent, Referer, Accept). |
| Pengenalan Fingerprint Browser | Mengidentifikasi perangkat berdasarkan ciri perangkat keras dan perangkat lunak. | Gunakan browser anti-detect atau plugin stealth untuk meniru fingerprint. |
| Tantangan JavaScript | Membutuhkan eksekusi JS untuk mengakses konten atau memverifikasi klien. | Deploy browser tanpa GUI (Playwright, Puppeteer) dengan konfigurasi stealth. |
| Jebakan Honeypot | Elemen HTML tersembunyi yang dirancang untuk menangkap parser otomatis. | Analisis properti visibilitas CSS sebelum berinteraksi dengan elemen. |
Tantangan Lanjutan: CAPTCHA dan Sistem Keamanan
Meskipun rotasi IP dan optimasi header yang sempurna, scraper sering menghadapi CAPTCHA. Tantangan ini dirancang khusus untuk membedakan manusia dari bot dengan meminta pengguna menyelesaikan teka-teki visual atau menganalisis data perilaku kompleks.
Sistem keamanan seperti Cloudflare Turnstile dan DataDome menggunakan analisis risiko lanjutan, mengevaluasi reputasi IP klien, fingerprint TLS, dan riwayat interaksi sebelum memutuskan apakah akan menampilkan CAPTCHA. Ketika scraper menghadapi penghalang ini, intervensi manual tidak mungkin dilakukan dalam skala besar. Ini adalah saat layanan penyelesaian otomatis menjadi penting untuk mempertahankan alur data. Untuk wawasan tentang tren saat ini, baca tentang menyelesaikan CAPTCHA saat web scraping 2025.
Otomatisasi Penyelesaian CAPTCHA dengan CapSolver
Ketika teknik anti-pendeteksian web scraping mencapai batasnya, CapSolver menyediakan solusi yang kuat untuk menangani CAPTCHA kompleks. CapSolver adalah layanan yang didukung AI yang mengotomatisasi penyelesaian berbagai tantangan, termasuk reCAPTCHA, Cloudflare Turnstile, dan teka-teki berbasis gambar.
Dengan mengintegrasikan CapSolver ke dalam arsitektur scraping Anda, Anda dapat secara program mengatasi gangguan ini. Layanan ini menggunakan model pembelajaran mesin canggih untuk menganalisis dan menyelesaikan tantangan dengan cepat dan akurat, memastikan proses ekstraksi data Anda tetap efisien dan tidak terganggu. Pendekatan ini sangat berharga ketika menangani tugas scraping volume tinggi di mana menghadapi CAPTCHA adalah hal yang tak terhindarkan.
Gunakan kode
CAP26saat mendaftar di CapSolver untuk mendapatkan kredit tambahan!
Contoh Integrasi: Menyelesaikan reCAPTCHA v2
Mengintegrasikan CapSolver ke dalam skrip scraping berbasis Python sederhana. Contoh berikut menunjukkan cara menggunakan API CapSolver untuk menyelesaikan tantangan reCAPTCHA v2. Metode ini menggunakan jenis tugas ReCaptchaV2TaskProxyLess, yang memanfaatkan infrastruktur proksi bawaan CapSolver.
python
import requests
import time
# Konfigurasi
API_KEY = "YOUR_CAPSOLVER_API_KEY"
SITE_KEY = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-"
SITE_URL = "https://www.google.com/recaptcha/api2/demo"
def solve_recaptcha():
# Langkah 1: Membuat tugas
payload = {
"clientKey": API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteKey": SITE_KEY,
"websiteURL": SITE_URL
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
task_data = response.json()
task_id = task_data.get("taskId")
if not task_id:
print("Gagal membuat tugas:", response.text)
return None
print(f"Tugas dibuat secara sukses. Task ID: {task_id}")
# Langkah 2: Memantau hasil
while True:
time.sleep(2)
result_payload = {
"clientKey": API_KEY,
"taskId": task_id
}
result_response = requests.post("https://api.capsolver.com/getTaskResult", json=result_payload)
result_data = result_response.json()
status = result_data.get("status")
if status == "ready":
print("CAPTCHA diselesaikan secara sukses!")
return result_data.get("solution", {}).get("gRecaptchaResponse")
elif status == "failed" or result_data.get("errorId"):
print("Gagal menyelesaikan CAPTCHA:", result_response.text)
return None
# Menjalankan solver
token = solve_recaptcha()
if token:
print(f"Token diterima: {token[:50]}...")
# Lanjutkan untuk mengirim token ke situs targetUntuk strategi implementasi yang lebih rinci, eksplor panduan komprehensif tentang cara menyelesaikan reCAPTCHA dalam web scraping menggunakan Python.
Pertimbangan Etis dan Kepatuhan
Meskipun memahami teknik anti-pendeteksian web scraping penting untuk keberhasilan teknis, ini harus seimbang dengan pertimbangan etis. Ekstraksi data harus selalu menghormati infrastruktur situs target dan ketentuan layanannya.
Pengembang harus mematuhi panduan yang ditentukan dalam file robots.txt, yang menjelaskan area yang diizinkan dan dilarang untuk crawling. Selain itu, menerapkan batas kecepatan yang wajar memastikan aktivitas scraping tidak mengurangi kinerja situs bagi pengguna sah. Scraping yang bertanggung jawab fokus pada ekstraksi data yang tersedia secara publik tanpa menyebabkan kerusakan atau melanggar regulasi privasi.
Kesimpulan
Berhasil menghadapi kompleksitas ekstraksi data memerlukan pemahaman mendalam tentang teknik anti-pendeteksian web scraping. Dengan menerapkan rotasi IP yang kuat, mengoptimalkan header HTTP, dan mengelola fingerprint browser, pengembang dapat mengurangi kemungkinan pemblokiran secara signifikan. Namun, seiring berkembangnya sistem keamanan, menghadapi CAPTCHA tetap menjadi tantangan yang terus-menerus. Mengintegrasikan solusi otomatis seperti CapSolver memastikan infrastruktur scraping Anda tetap tangguh, memungkinkan pengumpulan data yang stabil dan terus-menerus di lingkungan digital yang semakin terbatas.
Pertanyaan Umum
Apa teknik anti-pendeteksian web scraping yang paling umum?
Teknik yang paling umum termasuk rotasi alamat IP menggunakan jaringan proksi, meniru header HTTP (terutama User-Agent), menggunakan browser tanpa GUI dengan plugin stealth, dan menerapkan penundaan acak antara permintaan untuk meniru perilaku manusia.
Website memblokir scraper untuk melindungi sumber daya server mereka dari beban lalu lintas otomatis, melindungi data properti atau hak cipta, dan mencegah kompetitor dari memantau strategi harga atau konten mereka. Menurut Cloudflare, bot jahat dapat menghabiskan bandwidth yang signifikan dan mengurangi pengalaman pengguna.
Bagaimana cara fingerprint browser bekerja dalam deteksi bot?
Fingerprint browser mengumpulkan detail spesifik tentang perangkat pengguna, seperti resolusi layar, sistem operasi, font yang terpasang, dan kemampuan perangkat keras. Dengan menggabungkan titik data ini, sistem keamanan menciptakan identifikasi unik yang dapat melacak dan memblokir scraper bahkan jika mereka mengganti alamat IP atau menghapus cookie mereka.
Apakah browser headless dapat melewati semua sistem deteksi?
Tidak. Meskipun browser headless dapat mengeksekusi JavaScript dan menangani konten dinamis, konfigurasi default mudah dideteksi oleh sistem keamanan canggih seperti DataDome, yang menganalisis teknik deteksi bot termasuk variabel WebDriver. Pengembang harus menggunakan modifikasi stealth untuk menyembunyikan sifat otomatis dari browser tersebut.
Bagaimana saya harus menangani CAPTCHA selama ekstraksi data?
Ketika menghadapi CAPTCHA, pendekatan yang paling efisien untuk scraping skala besar adalah mengintegrasikan API penyelesaian otomatis seperti CapSolver. Layanan ini menggunakan pembelajaran mesin untuk menyelesaikan tantangan secara programatis, memungkinkan skrip scraping melanjutkan operasinya tanpa intervensi manual.
Lihat Lebih Banyak
Web ScrapingApr 22, 2026
Arsitektur Pengambilan Data Web Rust untuk Ekstraksi Data yang Dapat Diskalakan
Pelajari arsitektur pengambilan data web Rust yang dapat diskalakan dengan reqwest, scraper, pengambilan data asinkron, pengambilan data browser tanpa tampilan, rotasi proxy, dan penanganan CAPTCHA yang sesuai aturan.

Web ScrapingFeb 17, 2026
Cara menyelesaikan Captcha di Nanobot dengan CapSolver
Mengotomasi penyelesaian CAPTCHA dengan Nanobot dan CapSolver. Gunakan Playwright untuk menyelesaikan reCAPTCHA dan Cloudflare secara otomatis.
