Bagaimana Cara Kerja Ekstraksi Data AI: Penyelesaian CAPTCHA, Parsing LLM & Pipeline Data Web Terstruktur
Emma Foster
Machine Learning Engineer
Pengantar: Di Luar Parsing, Ini tentang Pengumpulan
Pengambilan data web tradisional bergantung pada metode pencocokan mekanis seperti selector CSS, XPath, dan ekspresi reguler, yang mengunci posisi tetap dalam DOM untuk mengambil nilai. Menghadapi perubahan desain halaman yang sering, adopsi luas rendering dinamis, dan peningkatan anti-scraping berlapis, paradigma ini telah menunjukkan kelemahan struktural seperti biaya pemeliharaan tinggi dan "kebutaan" terhadap konten asinkron. Kematangan model bahasa besar (LLMs) membawa titik balik: pengambilan data tidak lagi bertanya "di tag mana data berada?", tetapi memahami "pertanyaan apa yang dijawab konten halaman?", memasuki paradigma baru yang didorong oleh pemahaman bahasa alami. Perubahan ini bukan murni teoretis; kerangka seperti AXE, dengan memangkas simpul DOM yang tidak relevan dan menggabungkannya dengan model kecil untuk menghasilkan output struktur, telah melampaui model besar dengan skor F1 88,1% pada dataset SWDE, memvalidasi kelayakan dan efisiensi ekstraksi semantik. Artikel ini akan, dari perspektif implementasi teknik, menganalisis prinsip teknis dan pertukaran kunci setiap tahap sesuai urutan alur data, dari lapisan pengumpulan data yang menangani anti-crawling dan CAPTCHAs, ke lapisan pemrosesan pembersihan konten dan ekstraksi semantik LLM, hingga penyimpanan dan konsumsi data yang struktur.
I. Perubahan Paradigma: Dari Parsing Berbasis Aturan ke Pemrosesan Bahasa Alami
Sebelum mendalami detail teknis pengambilan data AI, penting untuk memahami mengapa paradigma lama yang digantikan telah mencapai batasnya, dan dalam dimensi apa paradigma baru telah mencapai perubahan mendasar.
1.1 Tiga Masalah Era Parsing Berbasis Aturan
Metode inti pengambilan data web tradisional adalah "penentuan jalur": pengembang meninjau node DOM tempat data target berada menggunakan alat pengembang browser, lalu menulis selector CSS atau ekspresi XPath secara manual untuk menentukan node tersebut. Paradigma ini telah mendukung kebutuhan pengumpulan data web sebagian besar selama dekade terakhir, tetapi memiliki tiga kelemahan struktural yang terus meningkat seiring evolusi teknologi web.
1.1.1 Anchor yang Rapuh: Aturan Statis Tidak Mampu Beradaptasi dengan Dunia Dinamis
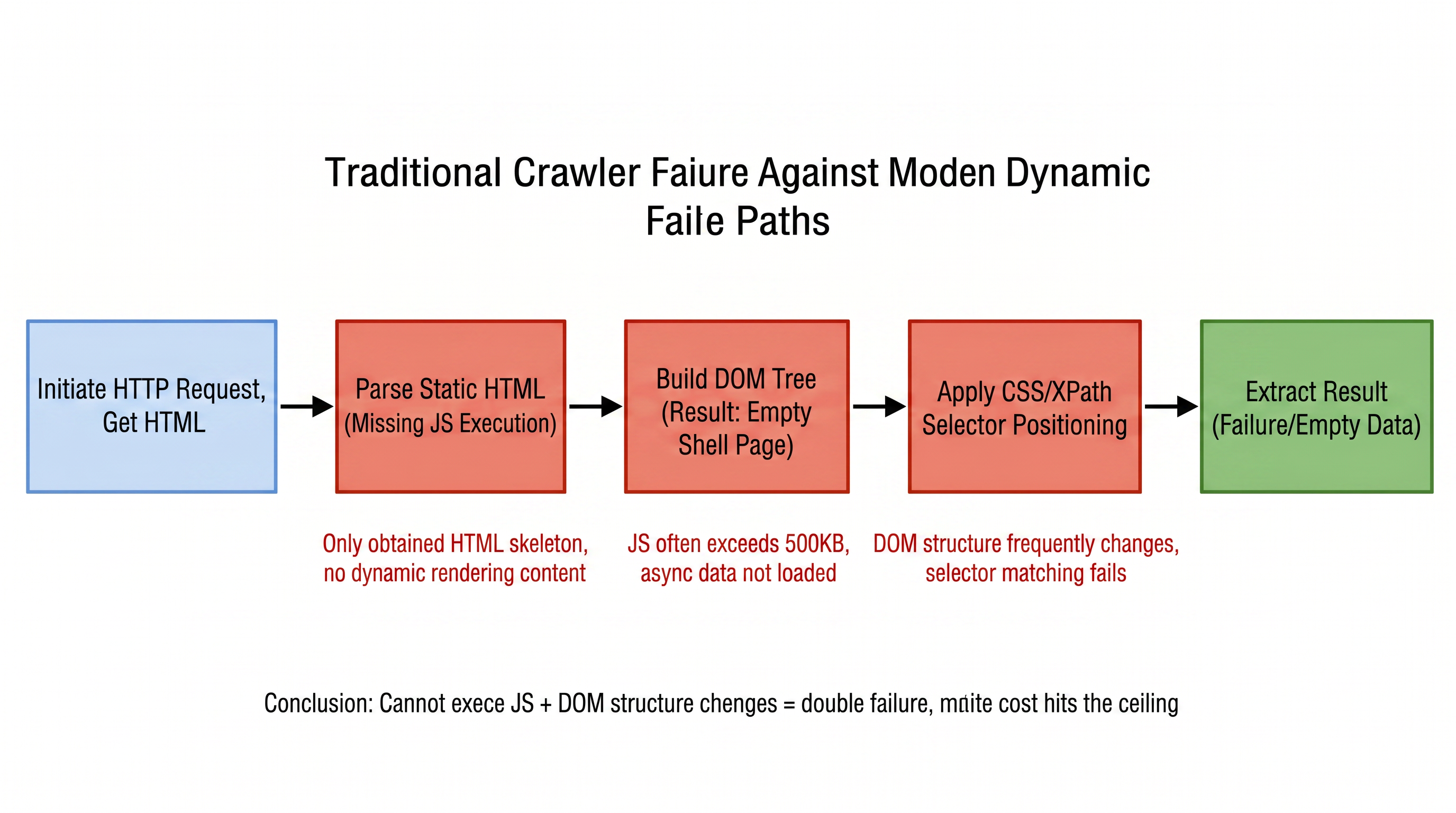
Website modern mengalami perubahan struktur DOM signifikan rata-rata setiap 3 hingga 6 bulan. Setiap desain ulang berarti aturan crawler berbasis jalur tetap menjadi tidak valid. Bagi tim yang mempertahankan ratusan node target secara bersamaan, ini membentuk siklus pemeliharaan "whack-a-mole" yang terus-menerus. Gambar 1-1 mengilustrasikan seluruh alur crawler web tradisional ketika menghadapi website modern, menunjukkan setiap tahap dari permintaan hingga ekstraksi data dan masalah yang dihadapi:
Proses ini mengungkap logika inti dari dilema pertama: ketidaksesuaian antara kemampuan parsing statis dan konten yang dirender secara dinamis. Menurut statistik W3Techs, pada akhir 2025, sekitar X% situs web global akan menggunakan layanan anti-scraping seperti Cloudflare. Berdasarkan deteksi bersama Netcraft terhadap jumlah total situs web, ini melibatkan lebih dari 290 juta situs, dan ukuran JS rata-rata halaman web melebihi 500KB. Crawler tradisional hanya dapat memperoleh kerangka yang tidak dirender, bukan hanya "melihat tidak ada data" tetapi juga, sekali situs web didesain ulang, selector yang ditulis dengan susah payah langsung menjadi tidak valid. "Ketidakmampuan teknis" dan "kerapuhan pemeliharaan" ini saling bertumpuk, terus menyempitkan cakupan parsing berbasis aturan.
1.1.2 Mata Tuli: Pencocokan Sintaks Gagal Memahami Makna
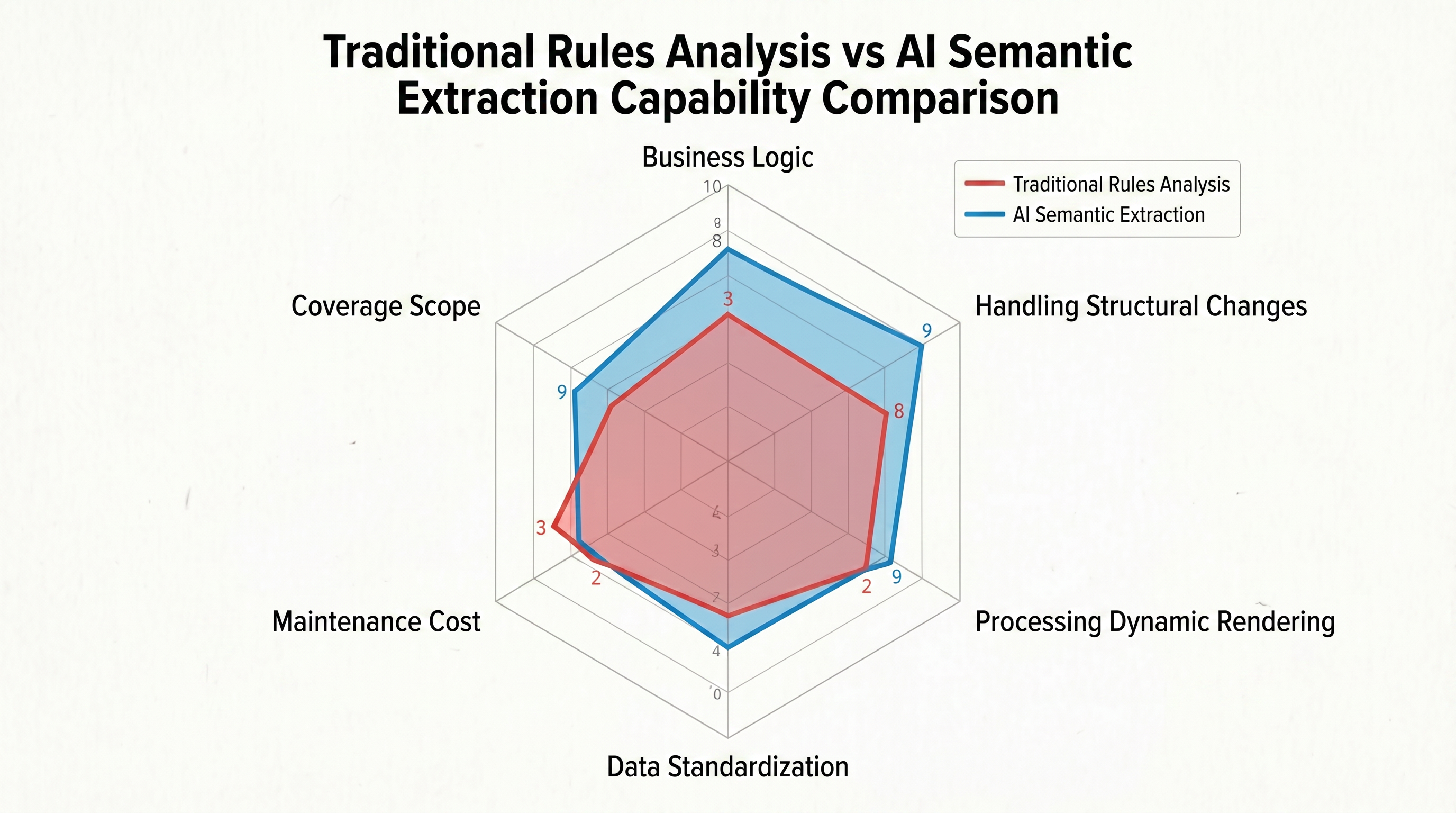
Metode tradisional hanya dapat menjawab "data berada di posisi ini," bukan "apa isi data di posisi ini?" Pada halaman daftar produk yang sama, mungkin ada harga promosi, harga rekomendasi, dan harga produk secara bersamaan—mereka memiliki tag yang sama dalam DOM, membuat aturan tradisional tidak mampu membedakannya. Menghadapi tiga format tanggal yang heterogen seperti "2026-04-28," "April 28, 2026," dan "28/04/2026," parser tradisional perlu menulis ekspresi reguler terpisah untuk setiap format dan tidak mampu menghadapi perubahan format dinamis. Gambar 1-2 menggunakan diagram radar untuk membandingkan secara visual perbedaan antara parsing berbasis aturan tradisional dan ekstraksi semantik AI di enam dimensi inti:
Bentuk diagram radar jelas menunjukkan bahwa parsing berbasis aturan tradisional bergantung pada penentuan jalur DOM yang tepat dalam dimensi "logika kerja", yang merupakan strategi satu-satunya yang dapat dijalankan. Namun, dalam lima dimensi lainnya, kinerjanya dibatasi secara menyeluruh—kemampuannya untuk beradaptasi terhadap perubahan struktur sangat lemah, pemrosesan rendering dinamis bergantung sepenuhnya pada alat eksternal, standarisasi data memerlukan penulisan ekspresi reguler manual, biaya pemeliharaan meningkat secara linear dengan jumlah situs, dan cakupannya terbatas pada satu set aturan per situs. Lima dari enam sumbu ini sangat tertekan, dan grafik tampak sebagai polygon tidak beraturan yang terkompresi.
Sebaliknya, diagram radar untuk ekstraksi semantik AI secara merata berkembang baik secara internal maupun eksternal: secara otomatis beradaptasi terhadap perubahan struktur berdasarkan pemahaman semantik, memproses rendering dinamis secara penuh dengan browser, mencapai standarisasi tanpa aturan melalui kemampuan konversi format yang diinternalisasi oleh LLM, biaya pemeliharaan menurun seiring peningkatan kemampuan model, dan satu Schema dapat mencakup halaman serupa di seluruh situs.
Setiap dari keenam kelemahan kemampuan ini bukanlah bottleneck teknis terpisah, tetapi konsekuensi alami dari logika dasar "pencocokan mekanis"—selama pengambilan data tetap berada pada tingkat sintaks, seberapa canggih desain aturannya, batasan struktural ini tidak dapat diatasi. Oleh karena itu, untuk menyelesaikan masalah ini secara menyeluruh, yang diperlukan bukanlah memperbaiki aturan, tetapi mengubah paradigma.
1.1.3 Batas Nyata: Mengapa Paradigma Ini Harus Diganti
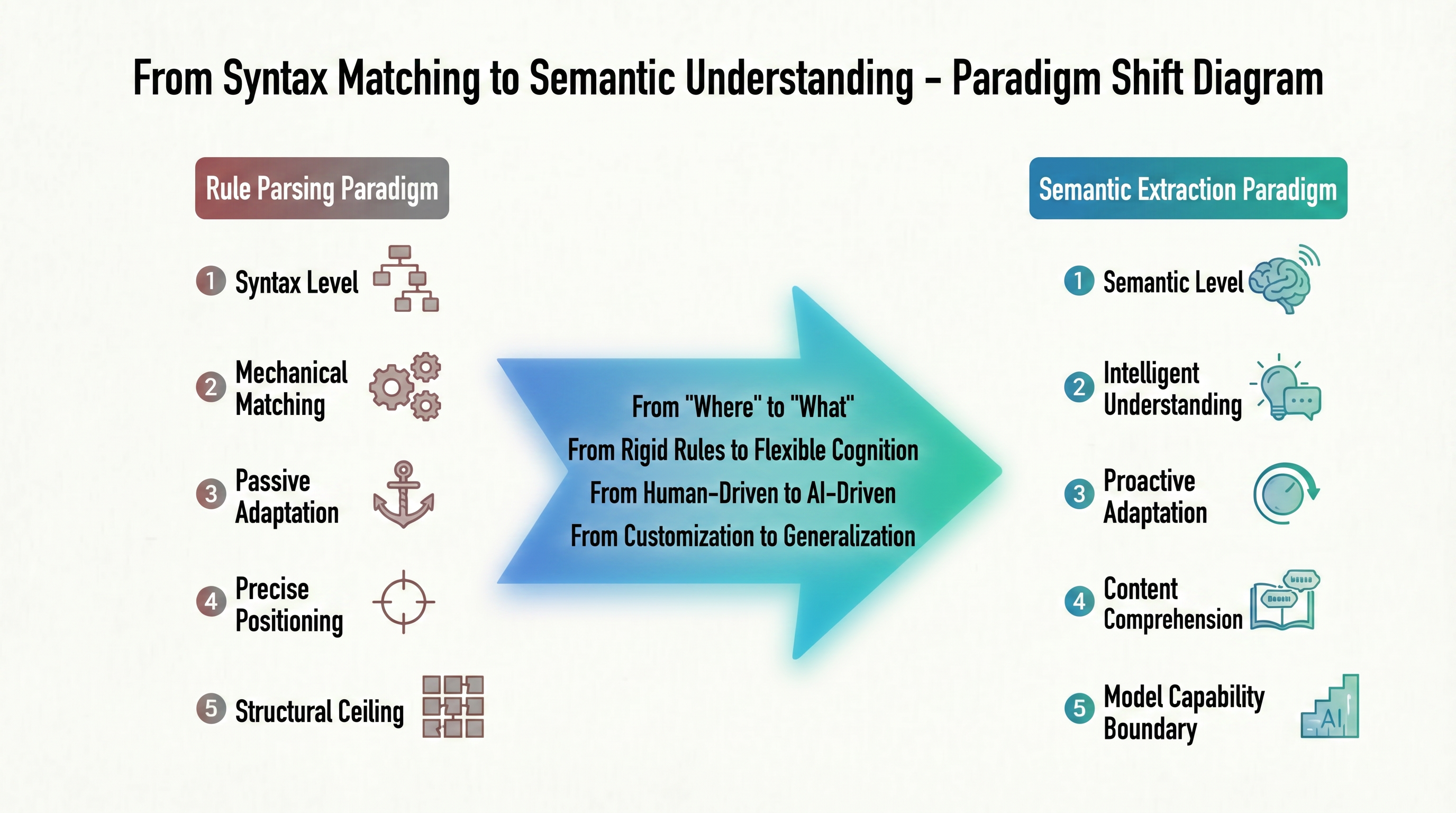
Semua masalah dari era parsing berbasis aturan berasal dari satu sumber: selalu melakukan "pencocokan mekanis" pada tingkat "sintaks". Logika kerja ini menentukan kemampuannya untuk mencapai "penentuan posisi yang tepat"—menemukan jalur DOM data secara akurat—tetapi dengan biaya "menyesuaikan diri secara pasif" terhadap setiap perubahan struktur halaman. Jika situs didesain ulang, aturannya menjadi tidak valid; jika jenis data heterogen, ekspresi reguler baru harus ditulis secara manual. Mode ini yang dipandu oleh situs target membentuk "batas struktural" yang tidak dapat dilampaui oleh parsing berbasis aturan. Gambar 1-3 menunjukkan arah perubahan mendasar dari paradigma ini dalam bentuk evolusi perbandingan.
Dari gambar di atas, jelas bahwa ini bukan peningkatan teknis di jalur yang sama, tetapi dua jalur yang berbeda secara mendasar. Paradigma parsing berbasis aturan di sebelah kiri dibangun di tingkat "sintaks", bertujuan mencapai "penentuan posisi yang tepat", menyesuaikan diri secara pasif terhadap perubahan struktur, dan segera mencapai "batas struktural"—seperti seseorang yang tahu sebuah bagian dalam buku berada di halaman 3, baris 5, tetapi tidak tahu apa isi bagian tersebut. Paradigma ekstraksi semantik di sebelah kanan mengubah tingkat kerja secara mendasar: dari "sintaks" ke "semantik", dari "pencocokan mekanis" ke "pemahaman cerdas". Tujuannya bukan lagi menemukan koordinat node, tetapi memahami konten halaman itu sendiri, dan batas kemampuannya tidak lagi ditentukan oleh perubahan DOM.
Ini juga menjelaskan mengapa tiga masalah era parsing berbasis aturan bukanlah masalah terpisah, tetapi manifestasi berbeda dari logika dasar "pencocokan sintaks". Selama teknologi pengambilan data tetap berada pada tingkat sintaks, seberapa rumit desain aturannya, tidak akan mampu memecahkan paradoks struktural yang bersamaan "penentuan posisi yang tepat" dan "kebutaan makna". Oleh karena itu, munculnya paradigma ekstraksi semantik AI bukanlah percepatan di jalur lama, tetapi revolusi di tingkat kognitif, dari "menemukan posisi" ke "memahami konten". Mekanisme spesifik dan keunggulan paradigma ini akan dijelaskan dalam Bagian 1.2.
1.2 Paradigma AI: Dari Pencocokan Sintaks ke Pemahaman Semantik
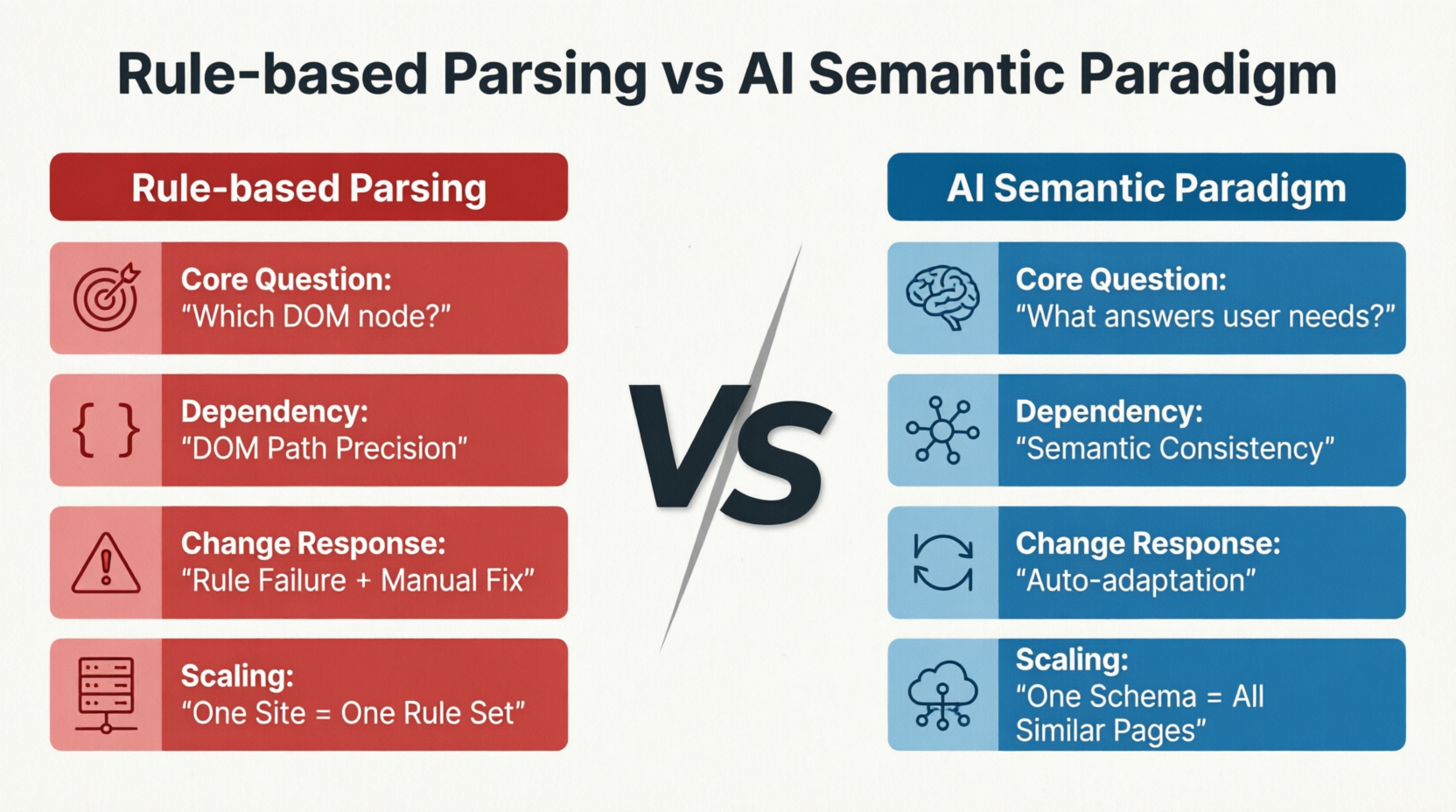
Metode berbasis AI secara total mengubah cara memandang masalah. Gambar 1-4 membandingkan perbedaan mendasar antara paradigma parsing berbasis aturan dan paradigma semantik AI di empat dimensi: masalah inti, faktor ketergantungan, penyesuaian terhadap perubahan, dan mode ekspansi:
Metode tradisional bertanya "di mana data berada dalam node DOM?", sedangkan metode AI bertanya "konten apa di halaman yang merupakan informasi inti yang menarik minat pengguna?" Perbedaan dalam pertanyaan ini menentukan perbedaan jalur teknis selanjutnya: yang pertama bergantung pada presisi jalur DOM, dan sekali halaman didesain ulang atau node bergerak, aturannya menjadi tidak valid dan harus diperbaiki secara manual; yang kedua bergantung pada konsistensi makna halaman. Struktur DOM bisa berubah, posisi data bisa bergerak, tetapi selama konten semantik tetap tidak berubah, model tetap dapat mengenali dan mengekstraknya secara benar. Dalam hal mode ekspansi, parsing berbasis aturan memerlukan penulisan kembali kumpulan aturan untuk setiap situs baru, sedangkan paradigma semantik AI dapat menutupi halaman serupa di seluruh situs dengan Schema yang sama secara horizontal.
Perubahan ini dari "penentuan sintaks yang tepat" ke "pemahaman semantik yang kabur" memberi metode AI ketangguhan yang tidak dimiliki aturan tradisional. Kerangka akademis AXE memberikan contoh insinyur paling jelas dari perubahan paradigma ini. Gambar 1-5 merangkum alur pemrosesan intinya:
Gambar 1-5 menunjukkan rantai lengkap dari HTML mentah ke output struktur: AXE terlebih dahulu memperlakukan DOM HTML sebagai pohon yang perlu dipangkas, menghilangkan node yang tidak relevan seperti bilah navigasi, footer, dan kode boilerplate melalui mekanisme pemangkasan khusus; kemudian DOM dikompresi menjadi beberapa blok semantik padat yang berisi informasi inti; akhirnya, model kecil yang ringan membaca blok semantik ini untuk menghasilkan output JSON yang struktur. Seluruh proses melewati penentuan jalur DOM yang harus diandalkan metode tradisional, dan langsung bertindak pada konten semantik halaman.
Pada dataset SWDE yang mencakup 8 domain vertikal dan lebih dari 80 situs web nyata, AXE mencapai skor F1 88,1%, melampaui beberapa model yang jauh lebih besar dari dirinya. Hasil ini membuktikan fakta yang tidak terduga tetapi penting: kemampuan ekstraksi semantik tidak bergantung pada model besar; model miniatur yang dirancang dengan hati-hati dan dilatih secara khusus juga dapat mencapai akurasi tingkat produksi. Ini adalah bukti inti bahwa paradigma semantik AI kompetitif dalam hal biaya dan kelayakan insinyur.
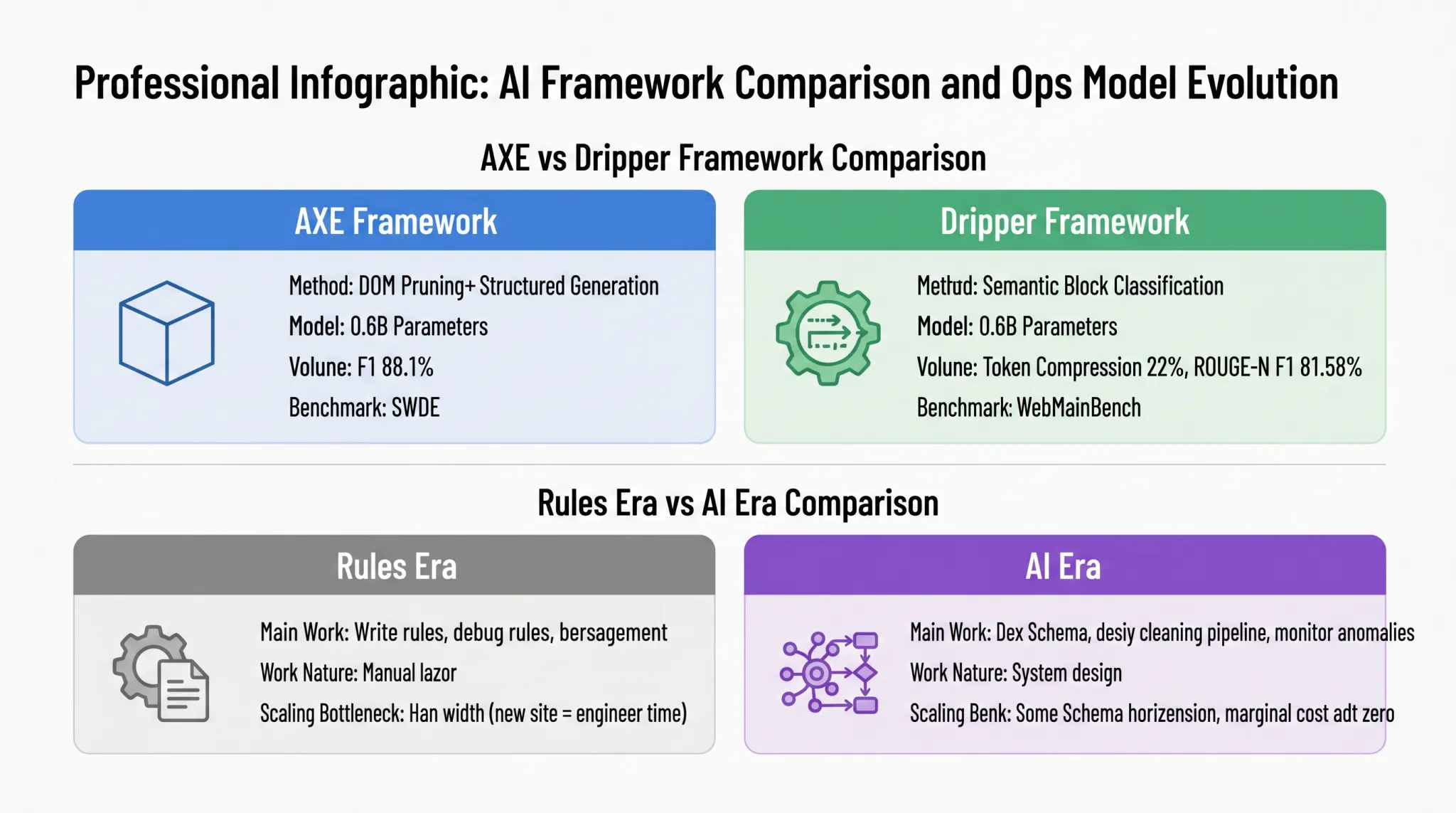
Karya lain yang mewakili, Dripper, mengambil jalur teknis yang berbeda, mengubah ekstraksi konten utama menjadi tugas "klasifikasi urutan blok semantik". Gambar 1-6 menggunakan perbandingan kartu untuk menempatkan perbedaan metode antara AXE dan Dripper, serta evolusi mode operasi dan pemeliharaan antara era aturan dan era AI:
AXE mengambil jalur "pemangkasan DOM + penghasilan struktur", mengompresi DOM HTML menjadi blok semantik padat dan kemudian langsung menghasilkan JSON melalui model kecil; Dripper mengambil jalur "klasifikasi biner blok semantik", mengubah ekstraksi konten utama menjadi tugas klasifikasi untuk menentukan apakah setiap blok semantik termasuk teks utama. Kedua model memiliki skala sekitar 0,6 miliar parameter dan telah mencapai akurasi tingkat produksi pada benchmark masing-masing. AXE mencapai skor F1 88,1% pada dataset SWDE, sementara Dripper memangkas token input hingga 22% dari HTML asli dan mencapai skor ROUGE-N F1 81,58% pada WebMainBench. Kedua jalur berbeda ini menunjukkan kesimpulan yang sama: ekstraksi data AI kompetitif dalam akurasi dan tidak bergantung pada model besar; model miniatur yang dirancang dengan hati-hati juga mampu berkinerja baik.
Setengah kanan mengungkap makna lebih dalam dari perubahan paradigma: tidak hanya mengubah jalur teknis tetapi juga merekonstruksi mode operasi harian tim data. Pekerjaan utama di era aturan adalah menulis aturan, memperbaiki aturan, dan manajemen versi, yang secara esensial adalah pekerjaan manual. Batas ekspansi terletak pada kapasitas manusia: setiap kali situs target baru ditambahkan, waktu insinyur harus diinvestasikan untuk menulis ulang dan menguji aturan. Di era AI, fokus pekerjaan bergeser ke definisi Schemas, desain pipa pembersihan, dan pemantauan kasus abnormal. Sifatnya berubah dari pekerjaan manual ke desain sistem, dan mode ekspansi juga berubah dari "satu set aturan per situs" ke "ekspansi horizontal dengan Schema yang sama". Menambahkan situs serupa memerlukan investasi insinyur hampir nol, dan biaya marginal mendekati nol. Perubahan ini melepaskan kemampuan pengumpulan data dari keterbatasan kapasitas manusia, mengubah ekonomi pengumpulan data.
II. Proses Inti Ekstraksi Data Berstruktur AI
Seluruh pipeline ekstraksi data AI mencakup 7 tahap, yang dapat dibagi menjadi tiga kelompok fungsional:
Lapisan Pengumpulan Data (Antrian URL → Penyedotan Web → Deteksi Anti-Sedotan): Bertanggung jawab untuk "mengambil" HTML halaman target dalam lingkungan jaringan yang kompleks. Ini adalah zona risiko tertinggi seluruh Pipeline, dengan bottleneck inti 14% yang ditunjukkan pada Gambar 2-2 mengarah ke lapisan ini.
Lapisan Pemrosesan Konten (Pembersihan Konten → Parsing LLM → Validasi Skema): Bertanggung jawab untuk mengubah HTML kasar yang berisik menjadi data terstruktur berkualitas tinggi. Bottleneck akurasi (18%) terutama terpusat pada tahap pembersihan konten dari lapisan ini.
Lapisan Penyimpanan Data (Penyimpanan Data): Output akhir untuk konsumsi downstream, menempati sekitar 5% beban keseluruhan tautan.
Bab ini akan fokus pada detail teknis Lapisan 2, yaitu lapisan pemrosesan konten, menunjukkan bagaimana ekstraksi semantik AI secara mendasar melampaui mesin aturan tradisional. Untuk Lapisan 1, prasyarat kritis yang menentukan apakah data dapat masuk ke lapisan pemrosesan, kami akan melakukan analisis terperinci dan diskusi solusi praktis di Bab 3.
2.1 Pipeline Ekstraksi Data AI
Sebelum memasuki lapisan pemrosesan, mari kita lihat gambaran keseluruhan Pipeline melalui Gambar 2-1 untuk memahami jalur lengkap dari antrian URL ke penyimpanan data dan distribusi lalu lintas aktual di setiap tahap. Ini berfungsi sebagai gambaran umum untuk bab ini dan membentuk dasar untuk mengatasi bottleneck di Bab 3.
Antrian URL adalah titik masuk Pipeline, mengelola daftar URL yang akan dicrawling dan mengontrol ritme permintaan. Seperti yang ditunjukkan pada Gambar 2-1, sekitar 32% permintaan dalam tahap penjadwalan antrian sudah ditandai dengan risiko CAPTCHA sejak awal, sementara 68% dapat langsung memulai permintaan normal. Tahap penyedotan web bertanggung jawab untuk memulai permintaan HTTP atau menggerakkan rendering browser untuk mendapatkan konten mentah halaman. Pada titik ini, 12% permintaan akan langsung diintersepsi oleh CAPTCHA, dan 80% dapat masuk ke tahap downstream secara mulus.
Setelah penyedotan awal, permintaan memasuki tahap deteksi anti-sedotan. Sistem anti-sedotan modern menganalisis sinyal dari empat dimensi secara bersamaan: reputasi IP, sidik jari TLS, karakteristik browser, dan pola perilaku, melakukan validasi lintas lapisan multi-layered. Gambar 2-1 menunjukkan bahwa sekitar 10% lalu lintas dalam tahap deteksi anti-sedotan akan diidentifikasi sebagai permintaan otomatis dan diintersepsi, dan 20% memerlukan ketergantungan pada pool IP proxy dan spoofing sidik jari TLS untuk melewati deteksi. Ini adalah node paling tidak pasti dalam seluruh Pipeline. Jika CAPTCHA diaktifkan dan tidak ditangani, semua sumber daya komputasi tahap berikutnya akan menjadi tidak aktif.
Setelah melewati deteksi anti-sedotan, konten HTML mentah diperoleh. HTML halaman berita biasa dapat melebihi 2MB, mencapai 300.000 hingga 500.000 token setelah diproses dengan tokenizer tiktoken OpenAI, penuh dengan menu navigasi, CSS yang tertanam, pixel pelacakan Base64, dan JavaScript yang dikompresi. Oleh karena itu, pembersihan konten adalah langkah yang penting. Gambar 2-1 menunjukkan bahwa konversi HTML ke Markdown menyumbang 50% dari pekerjaan di tahap ini, dan penyederhanaan DOM serta penghapusan noise menyumbang 30%. Kedua hal ini secara bersamaan memampatkan HTML mentah menjadi teks semantik padat, memastikan bahwa kekuatan komputasi LLM fokus pada informasi daripada noise.
Teks yang telah dibersihkan kemudian memasuki tahap parsing LLM, di mana model mengekstrak bidang terstruktur dari teks sesuai dengan skema yang ditentukan. Gambar 2-1 menggabungkan tahap ini dengan validasi skema berikutnya, menunjukkan tingkat akurasi 94,7%. Artinya, sekitar 1 dari 20 ekstraksi akan gagal melewati pemeriksaan kelengkapan bidang atau konsistensi format. Output yang berhasil menjadi data JSON terstruktur, yang akhirnya disimpan dalam sistem seperti PostgreSQL atau MongoDB untuk konsumsi bisnis downstream.
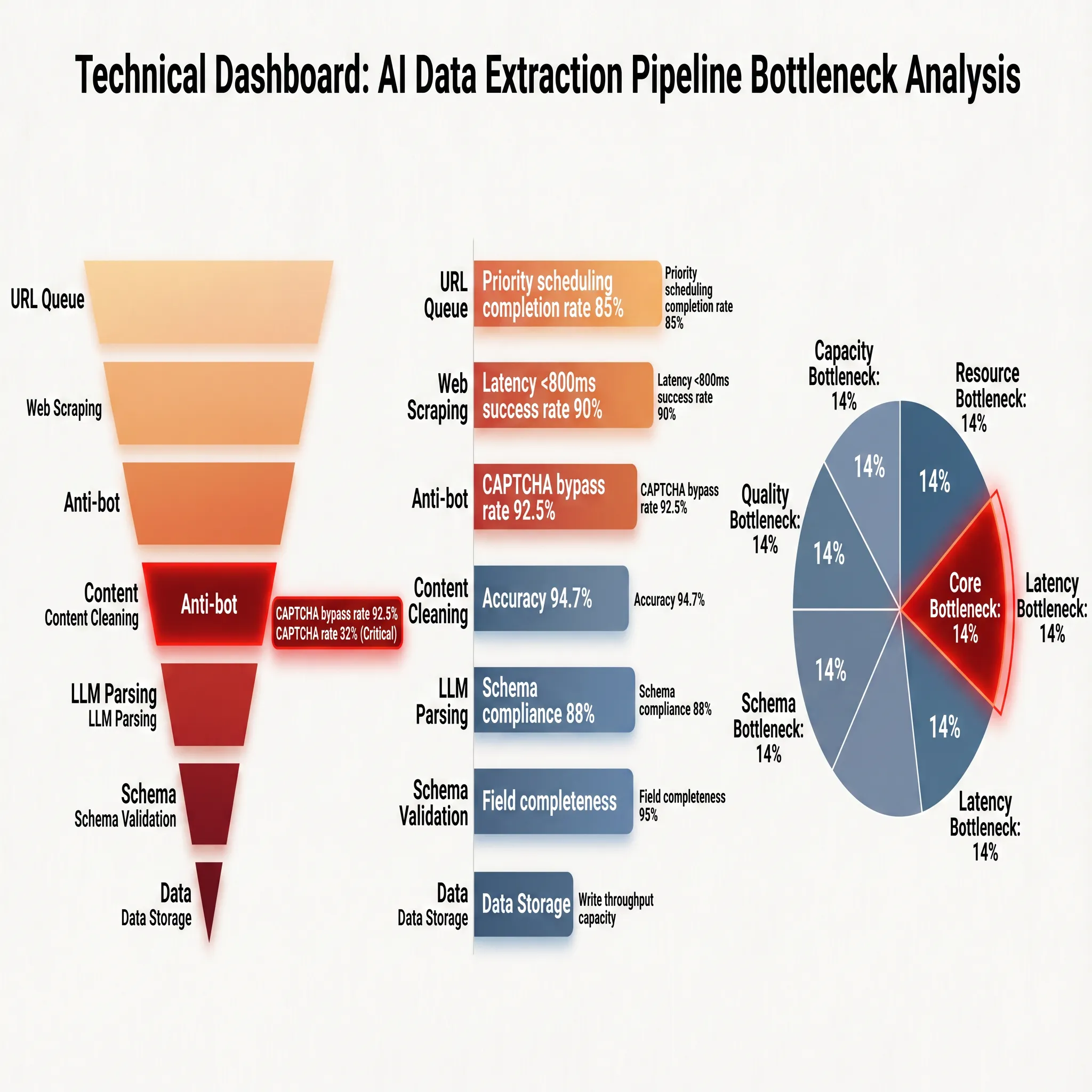
Untuk memecah lebih jelas teknis pembawa, indikator kinerja, dan bottleneck rekayasa dari setiap tahap, Gambar 2-2 menampilkan gambaran menyeluruh dalam bentuk dashboard:
Indikator kinerja di sisi kanan gambar mengungkap baseline operasional sebenarnya dari setiap tahap: tingkat pencapaian penjadwalan prioritas antrian URL adalah 85%, yang berarti sekitar 15% tugas tertunda atau menurun karena persaingan penjadwalan; penyedotan web mencapai tingkat keberhasilan 90% di bawah batas latensi kurang dari 800ms, jelas menunjukkan batas sumber daya jaringan dan rendering; mekanisme anti-sedotan memiliki tingkat akurasi 94,7%, yang berarti sekitar 5 dari setiap 100 permintaan diintersepsi atau memicu verifikasi; setelah pembersihan konten, tingkat kepatuhan skema adalah 88% dan kelengkapan bidang adalah 95%. Dua indikator ini bersama-sama menentukan titik awal kualitas data, dengan sekitar 12% halaman memiliki deviasi dalam identifikasi konten utama dan 5% bidang yang diperlukan hilang.
Bagian bawah Gambar 2-2 secara langsung menunjukkan distribusi bottleneck: titik bottleneck inti mengarah ke mekanisme anti-sedotan (14%), bottleneck akurasi mengarah ke pembersihan konten (18%), bottleneck kapasitas mengarah ke tahap antrian URL dan penyedotan web secara masing-masing, dan bottleneck biaya berada pada beban inspeksi kualitas validasi skema. Data ini sangat sejalan dengan analisis di atas. Deteksi anti-sedotan adalah "tenggorokan" seluruh rantai; jika strategi anti-sedotan diaktifkan dan tidak dapat diatasi secara efektif, tidak peduli seberapa tinggi akurasi tahap berikutnya, semuanya akan gagal karena kurangnya data input. Ini konsisten dengan masalah inti dari crawler berbasis aturan tradisional: di era ekstraksi semantik AI, batas akurasi telah meningkat secara signifikan, tetapi "kualifikasi masuk" untuk mengakses data tetap menjadi rintangan pertama untuk implementasi rekayasa. Untuk alasan ini, Bab 3 akan secara khusus membahas evolusi teknologi konfrontasi anti-sedotan dan tindakan pencegahannya.
2.2 Pembersihan Konten: Dari HTML Berisik ke Teks yang Dapat Dibaca LLM
Mengirimkan HTML mentah langsung ke LLM untuk ekstraksi terstruktur sangat tidak efisien secara rekayasa. Mekanisme perhatian LLM dapat terganggu oleh kode boilerplate DOM, seperti penggulungan dalam tag
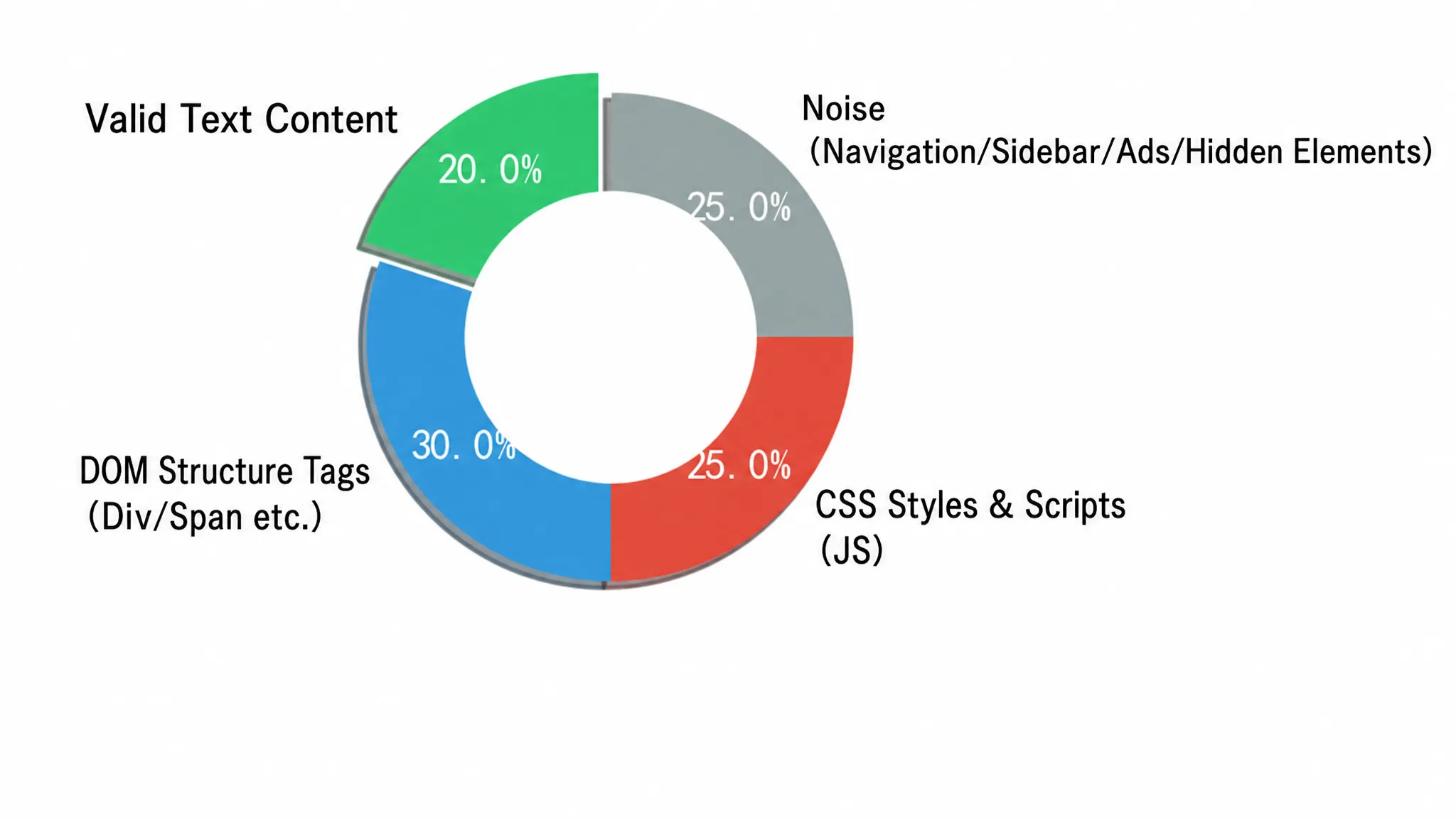
, gaya CSS yang tertanam, skrip pelacakan, menu navigasi, dan tautan footer. Elemen-elemen ini tidak hanya memberikan nilai semantik nol tetapi juga meningkatkan konsumsi token secara drastis. Dalam skenario skala besar yang memproses ribuan halaman per hari, pemborosan ini dengan cepat menjadi tidak berkelanjutan secara finansial. Komposisi HTML halaman berita biasa secara intuitif menggambarkan keparahan masalah. Gambar 2-3 menampilkan proporsi informasi efektif terhadap berbagai noise dalam HTML mentah dalam bentuk diagram lingkaran:
Diagram lingkaran membagi HTML mentah menjadi empat area. Bagian hijau (45%) adalah konten tubuh efektif, termasuk teks dan gambar—ini adalah sinyal yang benar-benar dibutuhkan LLM. Bagian kuning (20%) adalah noise struktural dan gaya, yaitu tag <script>, <style>, <svg>; bagian biru (20%) adalah navigasi dan sidebar; bagian merah (15%) adalah iklan dan pelacak. Tiga bagian noise bersama-sama melebihi 55%, berarti lebih dari setengah token yang dikirim ke LLM dibebankan tanpa memberikan nilai semantik apa pun.
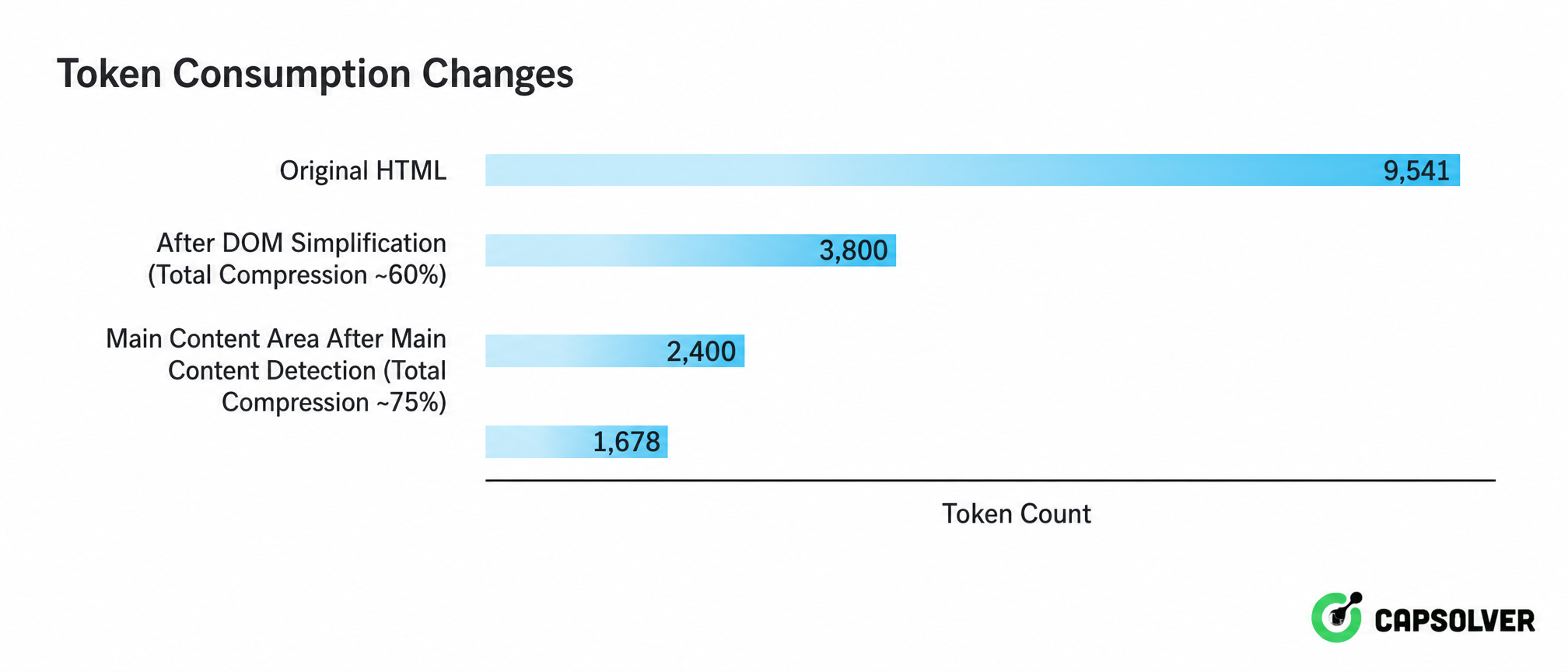
Realitas "sinyal tenggelam dalam noise" telah melahirkan strategi pembersihan bertingkat progresif. Gambar 2-4 menunjukkan rantai pemrosesan lengkap dari HTML mentah ke teks yang dapat dibaca LLM:
Dari perspektif pandangan, jelas terlihat bahwa tiga lapisan pembersihan memampatkan token dari 9.541 menjadi 1.678, hanya 18% dari HTML asli. Rasio kompresi ini berarti dalam pemrosesan skala besar, biaya panggilan API dapat dikurangi menjadi kurang dari sepertiga aslinya, dan pengurangan konteks 10-100 kali yang dicapai oleh filter konteks semantik memastikan bahwa perhatian LLM fokus pada sinyal daripada noise. Ini adalah bagian yang tidak terhindarkan dari implementasi rekayasa ekstraksi data AI.
2.3 Parsing LLM dan Validasi Skema: Dari Teks ke Data Terstruktur
Teks Markdown yang telah dibersihkan melalui pembersihan konten memasuki tahap parsing LLM, dengan tujuan menghasilkan JSON terstruktur yang ketat sesuai dengan skema yang ditentukan. Tergantung pada skenario, saat ini ada tiga jalur teknis utama yang tersedia. Jalur pertama menggunakan model besar umum seperti GPT-4o, yang dengan jendela konteks 128K menawarkan kecepatan inferensi tercepat dan skor kualitas tertinggi, tetapi dengan biaya sedang, cocok untuk verifikasi prototipe cepat dengan bidang sedikit dan format sederhana. Jalur kedua menggunakan model khusus berbasis skema seperti Schematron-3B, berjalan dalam pengoperasian server-side yang kompak, dengan kecepatan sedang-tinggi dan skor kualitas hanya sedikit tertinggal 0,12 poin dari model besar umum, sementara mengurangi biaya ke tingkat terendah, menjadikannya pilihan optimal untuk skenario produksi skala besar. Jalur ketiga memanfaatkan model bahasa multimodal untuk membangun arsitektur hibrida, secara bersamaan memproses screenshot dan HTML, mampu menangani halaman dinamis interaktif tinggi seperti penggulungan tak berujung dan pop-up modal, tetapi dengan kecepatan sedang, biaya tertinggi, dan skor kualitas relatif terendah, menjadikannya hampir satu-satunya jalur yang layak untuk skenario interaktif kompleks. Terlepas dari jalur yang dipilih, JSON terstruktur yang dihasilkan awalnya harus melewati tiga lapisan validasi skema—kelengkapan bidang, kepatuhan tipe, dan konsistensi format—sebelum dioutput sebagai data akhir. Gambar 2-5 mengilustrasikan hubungan lengkap antara ketiga jalur ini dan validasi skema dari perspektif rantai proses dan metrik inti.
Matriks ini jelas menunjukkan fakta rekayasa yang tidak terduga tetapi penting: model terbesar tidak selalu menjadi solusi optimal. Schematron-3B, dengan hanya 3B parameter, mendekati skor kualitas model besar seperti GPT-4o sambil secara signifikan mengurangi biaya. Ketika pemrosesan mencapai skala satu juta halaman per hari, biaya inferensinya hanya sekitar 1/80 dari model umum besar, yang merupakan titik kritis dari "secara teknis layak" ke "komersial menguntungkan." Meskipun Webscraper+MLLM memiliki biaya tertinggi dan skor kualitas relatif terendah, itu hampir satu-satunya jalur yang layak untuk skenario interaktif dinamis tinggi, yang secara tepat memverifikasi prinsip: kebenaran pemilihan teknologi bergantung pada batasan skenario, bukan nilai metrik absolut.
Validasi skema adalah titik pemeriksaan terakhir untuk memastikan kegunaan data. Di antaranya, pemeriksaan konsistensi format sangat penting untuk bidang seperti tanggal, mata uang, dan nomor telepon. Solusi ekspresi reguler tradisional memerlukan penulisan aturan secara manual untuk setiap variasi input, sementara kemampuan konversi format yang diinternalisasi LLM dapat mencapai standarisasi dengan nol aturan. Dalam hal akurasi, kerangka kerja AXE telah mencapai skor F1 sebesar 88,1% pada dataset SWDE. Pengalaman dalam lingkungan produksi nyata menunjukkan bahwa mengejar akurasi ekstraksi otomatis 90% dikombinasikan dengan jalur tinjauan manual cepat adalah strategi rekayasa yang lebih pragmatis daripada mengejar akurasi teoritis 100% dengan biaya sepuluh kali lipat. Garis kompromi ini bergantung pada perhitungan spesifik tim tentang "kelanjutan data" dan "batas anggaran," tetapi jelas bahwa akurasi moderat lebih komersial menguntungkan.
III. Tiga Pintu Masuk Ekstraksi Data AI: Deteksi Anti-Sedotan, Pecahan CAPTCHA, dan Kontrol Biaya
Di Bab 2, kita secara menyeluruh mengeksplorasi rantai teknis lapisan pemrosesan konten—dari pembersihan HTML hingga validasi skema—menunjukkan bagaimana ekstraksi semantik AI secara signifikan meningkatkan batas akurasi. Namun, seperti yang diungkapkan pada Gambar 2-2 bagian 2.1, bottleneck inti (14%) dari seluruh Pipeline bukan di lapisan pemrosesan, tetapi di lapisan pengumpulan data sebelumnya. Jika HTML tidak dapat diperoleh, semua pemrosesan cerdas berikutnya dibangun di atas udara. Bab ini akan langsung menangani tahap kritis yang menentukan "kualifikasi masuk."
3.1 Lapisan Pengumpulan Data: Bottleneck Fatal Pertama dari Pipeline
Jika pembersihan konten dan parsing LLM menyelesaikan masalah "bagaimana memproses data," lapisan pengumpulan data menangani masalah yang lebih mendasar dan rumit: "apakah data dapat diperoleh?" Dalam jalur dari antrian URL ke akses normal, sistem anti-sedotan adalah variabel paling tidak terkendali dalam seluruh Pipeline.
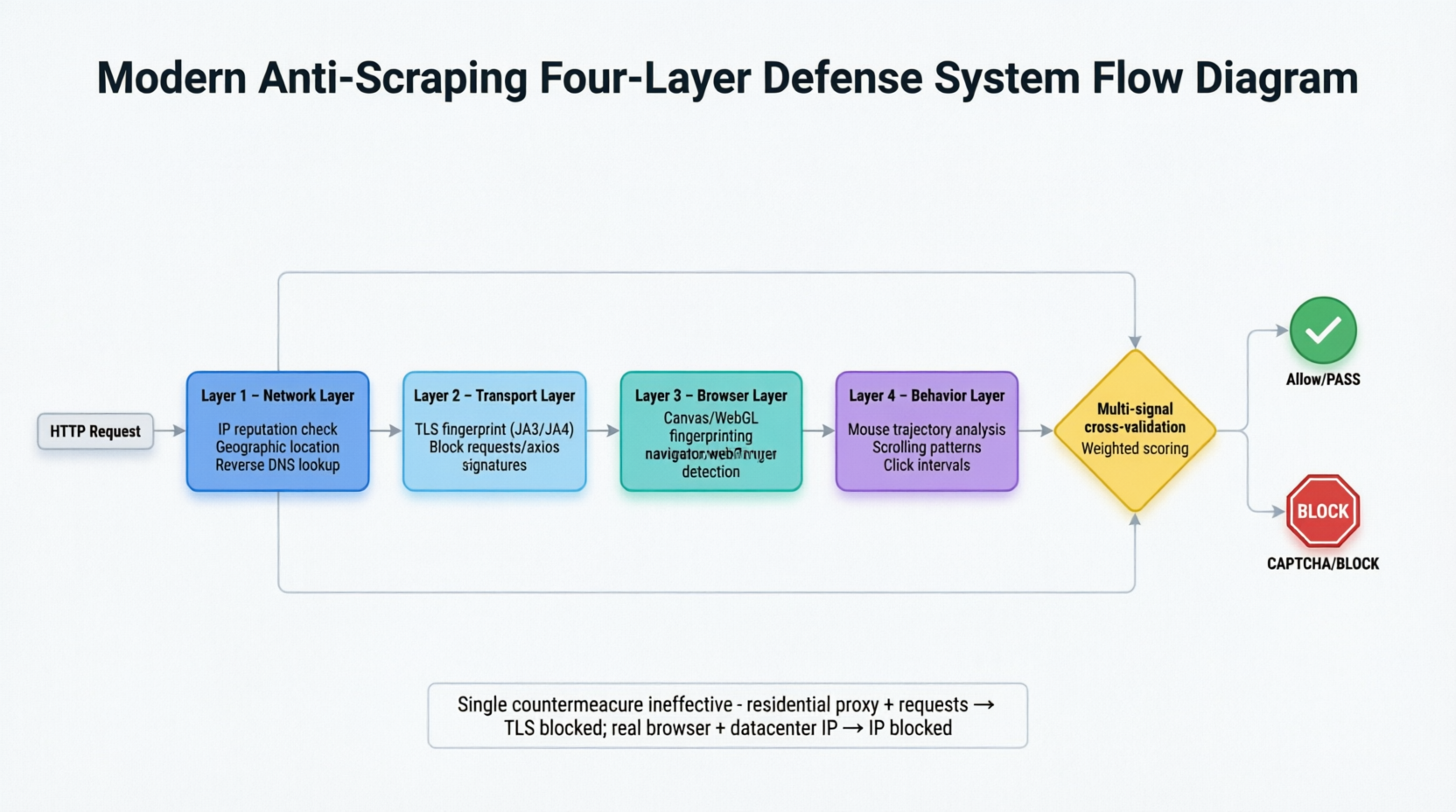
Sistem anti-sedotan modern telah berkembang menjadi arsitektur pertahanan bertingkat empat, menganalisis setiap permintaan secara bersamaan dari lapisan jaringan, transportasi, browser, dan perilaku. Gambar 3-1 memperluas secara horizontal arsitektur deteksi bertingkat ini.
Permintaan melewati empat lapisan filter secara berurutan. Lapisan jaringan memeriksa sinyal statis seperti lokasi IP, apakah termasuk pusat data, dan hilangnya DNS terbalik; lapisan transportasi membandingkan sidik jari TLS; lapisan browser menangkap jejak otomatisasi seperti properti navigator.webdriver dalam mode tanpa kepala, sidik jari canvas, dan informasi renderer WebGL; lapisan perilaku menganalisis karakteristik perilaku manusia yang sulit disimulasikan secara tepat, seperti jalur mouse, pola penggulungan, dan interval klik. Empat lapisan sinyal diverifikasi lintas untuk membentuk skor berbobot, membuat sulit bagi satu lapisan penyamaran untuk melewati. Ketika sistem tidak dapat membuat penentuan yang jelas, lapisan pertahanan terakhir—CAPTCHA—diaktifkan.
Ketika semua metode deteksi pasif tidak dapat menentukan sifat lalu lintas secara jelas, sistem menampilkan CAPTCHA, yang merupakan lapisan pertahanan terakhir dari sistem anti-sedotan. CAPTCHA modern bukan lagi pengenalan karakter yang distorsi sederhana tetapi sistem tantangan cerdas berbasis skor risiko. Tabel 3-1 membandingkan empat sistem CAPTCHA utama yang tersedia saat ini.
Sistem CAPTCHA
Bentuk Interaksi
Mekanisme Penilaian
Kemampuan/fitur Dekoding AI
Ancaman terhadap Crawlers
reCAPTCHA v2
Klik kotak centang / pengenalan gambar
Interaksi pengguna + penilaian perilaku AI
Akurasi 85%–100%
Tinggi, tetapi bisa dipecahkan
reCAPTCHA v3
Sepenuhnya tidak terlihat, tidak ada tantangan visual
Penilaian perilaku kontinu di latar belakang
Tidak dapat "dipecahkan" secara langsung, bergantung pada simulasi perilaku
Sangat tinggi, penilaian yang tidak terlihat
Cloudflare Turnstile
Pemeriksaan konsistensi lingkungan browser
Verifikasi non-interop
Memverifikasi integritas browser
Tinggi, alternatif untuk reCAPTCHA
AWS WAF CAPTCHA
Berbasis risiko, tantangan yang dapat dikonfigurasi
Penilaian lingkungan terintegrasi AWS
Lingkungan cloud khusus
Sedang, ekosistem khusus
CAPTCHA berada di akhir rantai pertahanan keseluruhan. Jika diaktifkan dan tidak ditangani, semua tahap pembersihan konten dan pemrosesan LLM berikutnya menjadi sepenuhnya tidak efektif. Ini adalah alasan mendasar mengapa lapisan pengumpulan data disebut sebagai "bottleneck fatal pertama dari Pipeline": mekanisme anti-scraping menentukan apakah data dapat masuk ke sistem, dan itu sendiri adalah variabel yang dikendalikan secara mendalam oleh situs web target. Di era di mana ekstraksi semantik AI telah meningkatkan efisiensi pemrosesan data secara signifikan, pertarungan di sisi pengambilan data tetap menjadi titik kritis untuk keberhasilan rekayasa.
3.2 Menyelesaikan Teka-Teki: Jalur Teknis untuk Pemecahan CAPTCHA Modern
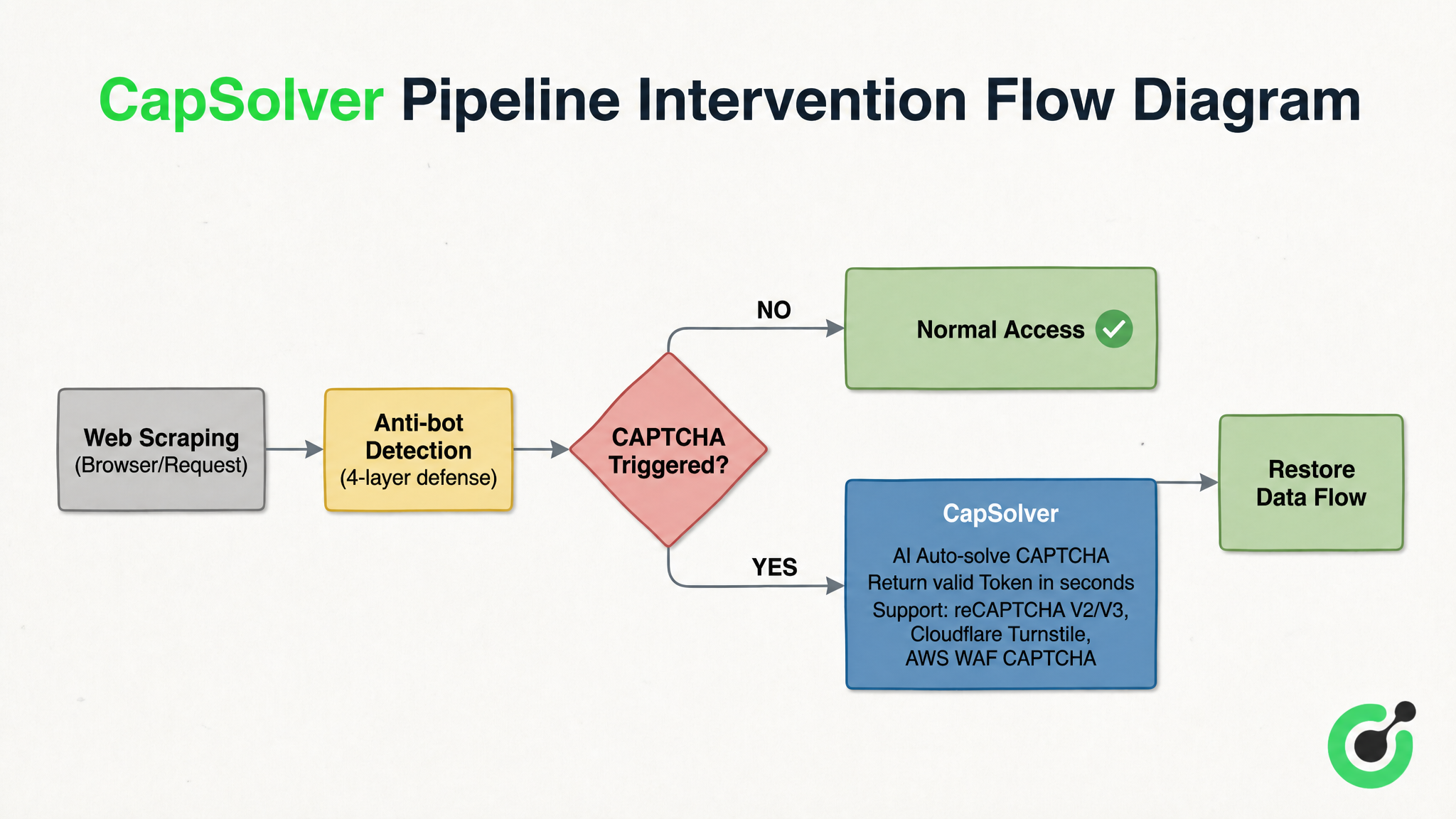
Dalam sistem pertahanan anti-scraping berlapis empat, CAPTCHA adalah penghalang terakhir dan paling sulit untuk dipecahkan secara otomatis. Solusi pengenalan CAPTCHA yang diwakili oleh CapSolver memainkan peran seperti "fuser" dalam seluruh Pipeline—dia tersemat antara "deteksi anti-scraping" dan "akses normal." Ketika crawler menghadapi tantangan seperti reCAPTCHA v2/v3, Cloudflare Turnstile, atau AWS WAF CAPTCHA, ia melakukan pengenalan dalam hitungan detik dan mengembalikan Token yang valid, melanjutkan aliran data. Gambar 3-2 menggunakan CapSolver sebagai contoh untuk mengilustrasikan posisi intervensi dan logika pemrosesan solusi jenis ini:
Dari Gambar 3-2, mekanisme kerja solusi jenis ini jelas: setelah permintaan scraping dideteksi oleh sistem pertahanan berlapis empat, jika CAPTCHA tidak diaktifkan, maka langsung dilepaskan untuk akses normal; begitu tantangan CAPTCHA diaktifkan, layanan pengenalan segera melakukan intervensi dan mengirimkan jenis CAPTCHA dan parameter. AI melakukan pengenalan dalam hitungan detik dan mengembalikan Token yang valid, sehingga aliran data kembali terhubung di titik pemutusan. Ini tidak menggantikan komponen apa pun yang ada, tetapi berperilaku seperti fuser dalam sistem listrik, mencegah seluruh sistem crash saat anomali terjadi.
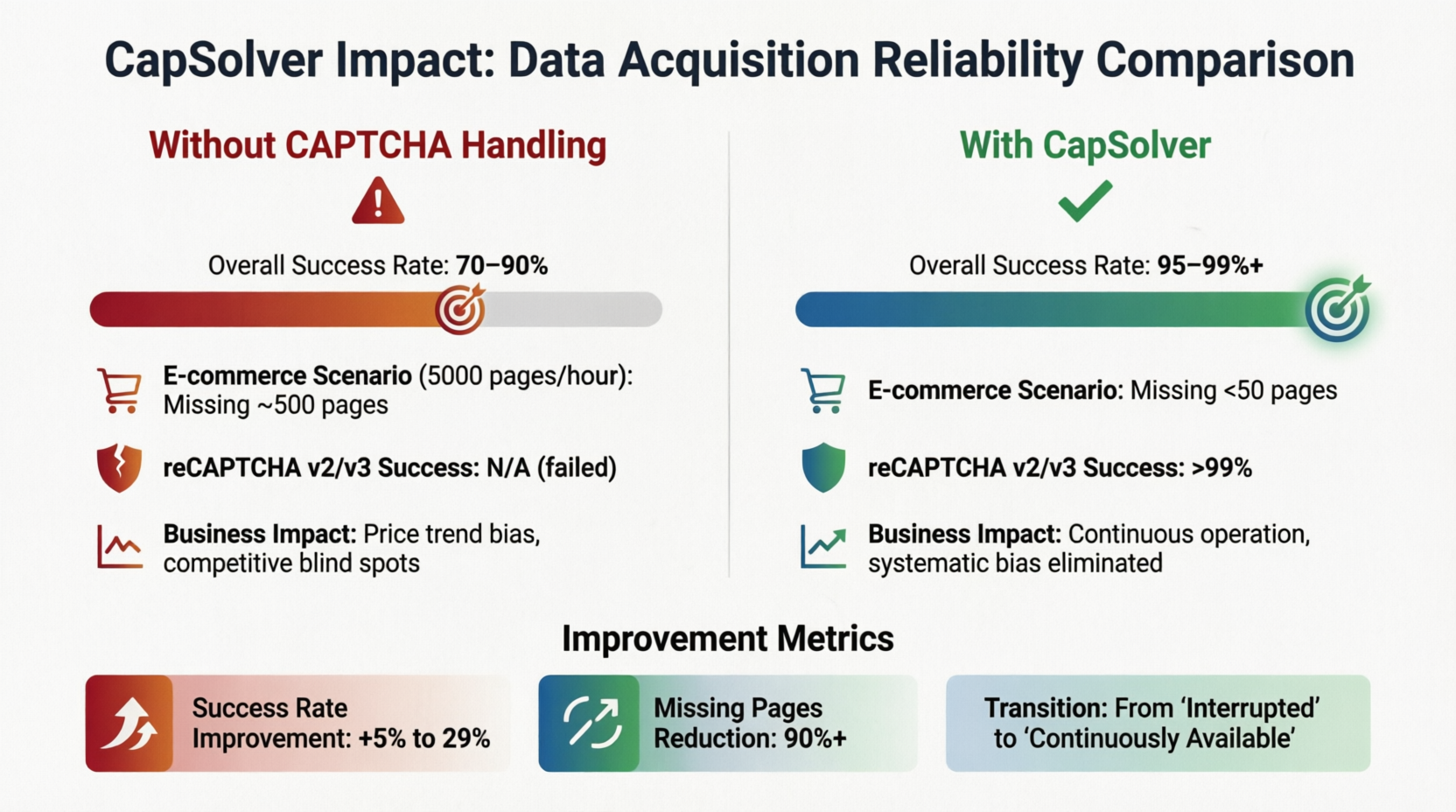
CapSolver adalah salah satu solusi yang mewakili di bidang ini. Layanan serupa seperti 2Captcha dan Anti-Captcha juga menyediakan kemampuan yang sama, dan pengembang dapat memilih penyedia yang paling sesuai berdasarkan persyaratan latensi, jenis yang didukung, dan model harga. Pemasangan ini secara langsung mengubah model keandalan lapisan pengumpulan data. Gambar 3-3 menggunakan CapSolver sebagai studi kasus untuk mengukur perubahan indikator kunci sebelum dan sesudah memperkenalkan pengenalan CAPTCHA:
Tanpa mekanisme penanganan CAPTCHA, tingkat keberhasilan keseluruhan bervariasi antara 70%–90%. Selama situs target menerapkan CAPTCHA, ada kemungkinan 10%–30% aliran data akan terblokir. Dalam sistem pemantauan harga e-commerce yang mengumpulkan 5.000 halaman produk per jam, bahkan dengan tingkat keberhasilan dasar 90%, sekitar 500 halaman data akan hilang per jam, yang cukup untuk menyebabkan penyimpangan arah dalam analisis tren harga dan kebutaan sistem dalam strategi kompetitor. Namun, setelah memperkenalkan solusi pengenalan CAPTCHA, tingkat keberhasilan melonjak ke atas 95%–99%, dan halaman yang hilang berkurang menjadi dalam 50. Tingkat keberhasilan pengenalan reCAPTCHA v2/v3 melebihi 99% ketika parameter dikonfigurasi dengan benar. Bagian bawah kartu merangkum peningkatan: tingkat keberhasilan meningkat 5%–29%, dan halaman yang hilang berkurang lebih dari 90%. "Kontinuitas adalah nilai bisnis" bukan hanya slogan dalam skenario besar tetapi praktik rekayasa yang dikonfirmasi oleh angka-angka ini.
Platform uji benchmark AI dan skenario pengumpulan data pelatihan LLM juga menghadapi tantangan ini: peneliti membutuhkan pengumpulan data yang beragam secara terus-menerus, dan situs yang menyimpan data ini sering menggunakan reCAPTCHA untuk mencegah akses otomatis, menciptakan paradoks di mana "tim penelitian AI terhambat oleh teknologi yang mereka pelajari." Layanan pengenalan CAPTCHA memberikan cara programatik untuk menangani tantangan ini, memastikan pengumpulan data yang tidak terganggu dan hasil uji benchmark yang lengkap.
Pada tingkat integrasi, solusi ini dapat bekerja sama dengan kerangka kerja otomasi browser, layanan jaringan proxy, dan platform otomasi low-code. Pengembang hanya perlu mengirimkan jenis CAPTCHA dan parameter ke API, dan sistem akan mengembalikan Token dalam hitungan detik. Platform seperti n8n menyediakan node khusus, memungkinkan staf bisnis mengkonfigurasi pengenalan CAPTCHA langsung dalam alur kerja tanpa menulis kode. Pengembang dapat fokus pada logika bisnis dan desain Schema, meninggalkan konfrontasi anti-scraping kepada alat profesional.
Dari perspektif arsitektur, solusi pengenalan CAPTCHA tidak menggantikan komponen apa pun yang ada tetapi memberikan lapisan "jaminan ketersediaan" untuk titik masuk seluruh Pipeline. Ketika pengenalan CAPTCHA dapat diselesaikan secara otomatis dalam hitungan detik, pengumpulan data beralih dari "celah sementara" menjadi "pasokan data berkelanjutan," yang merupakan prasyarat untuk operasi stabil seluruh rantai ekstraksi data terstruktur AI.
3.3 Akurasi dan Biaya: Perdagangan Terakhir dalam Penerapan Rekayasa
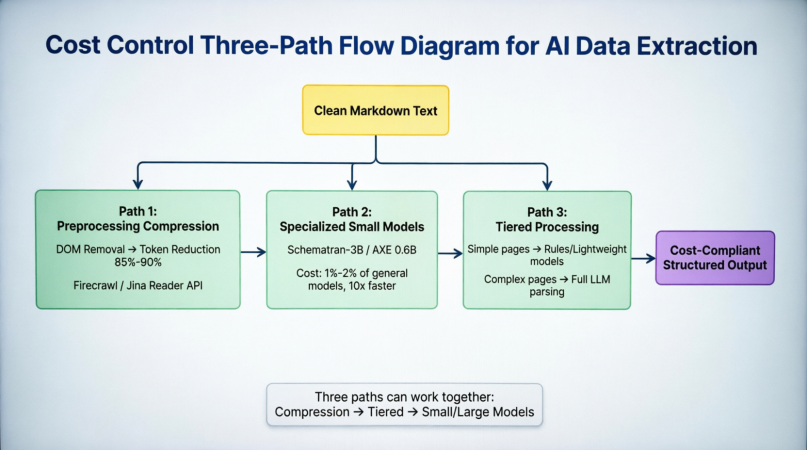
Ketika mendorong ekstraksi data AI ke lingkungan produksi, variabel keputusan akhir seringkali bukan "apakah akurasinya cukup baik?" tetapi "apakah biayanya bisa ditanggung?" Konsumsi Token berada di inti masalah ini: halaman produk yang cukup kompleks, bahkan setelah dibersihkan, mungkin menghabiskan 8.000 hingga 15.000 token. Berdasarkan harga API model yang umum saat ini, biaya per ekstraksi berkisar antara $0,001 hingga $0,01. Ini hampir tidak signifikan dalam tahap prototipe, tetapi ketika skala ekstraksi meningkat menjadi jutaan halaman per hari, biaya bulanan akan mencapai puluhan ribu dolar, pada titik ini pengendalian biaya bukan lagi item optimisasi tetapi persyaratan penerimaan. Saat ini, ada tiga jalur paralel di industri untuk mengurangi biaya. Gambar 3-4 menunjukkan posisi dan hubungan sinergisnya dalam seluruh rantai pemrosesan:
Sebelum Markdown yang dibersihkan memasuki tahap pemrosesan, jalur pertama mengurangi token hingga 85%–90% melalui penghapusan DOM dan deteksi konten utama di frontend. Firecrawl dan Jina Reader telah mengemas ini menjadi API, menghilangkan kebutuhan pengembang untuk membangun pipeline pembersihan sendiri. Jalur kedua mengganti model besar umum dengan model khusus tugas seperti Schematron-3B dan AXE 0.6B di lapisan model, mempertahankan akurasi sambil memampatkan biaya inferensi menjadi 1%–2% dan meningkatkan kecepatan lebih dari 10 kali. Jalur ketiga menggunakan aturan atau model ringan untuk halaman dengan struktur sederhana di lapisan penjadwalan, hanya menyerahkan halaman kompleks ke model besar penuh untuk pemrosesan. Ini sangat efektif dalam skenario seperti pemantauan kategori e-commerce, di mana sebagian besar halaman dalam situs yang sama memiliki struktur yang sangat konsisten, dan hanya beberapa halaman tidak biasa yang memerlukan intervensi model penuh. Ketiga jalur ini tidak saling eksklusif tetapi dapat diimposisi secara sinergis: pertama mengompresi token, lalu mengklasifikasikan berdasarkan kompleksitas, dan akhirnya memproses dengan model yang sesuai tugas. Gambar 3-5 lebih lanjut mengkuantifikasi tiga strategi dari prinsip inti, pengurangan token, solusi representatif, dan besarnya penghematan biaya, serta mencakup tiga pemeriksaan kualitas data:
Pengurangan pra-pemrosesan langsung mengurangi volume input dengan menghilangkan noise DOM, mencapai pengurangan token 85%–90%, yang sesuai dengan penghematan biaya 80%–90%. Model kecil khusus mengurangi biaya inferensi tunggal dengan mengurangi ukuran model, dengan parameter berkurang dari miliaran menjadi rentang 0,6B–3B, menghemat sekitar 98% biaya inferensi. Pemrosesan bertingkat mengoptimalkan efisiensi keseluruhan dengan alokasi sumber daya komputasi yang berbeda, dengan penghematan tergantung pada proporsi halaman sederhana. Ketiga pendekatan ini, dari "mengirimkan lebih sedikit," "menghitung lebih sedikit," dan "menghitung dengan cerdas," membentuk sistem penghematan biaya lengkap yang mencakup lapisan input, lapisan model, dan lapisan penjadwalan.
Bagian belakang beralih ke jaminan kualitas. Pemeriksaan kualitas data adalah aspek yang sering diabaikan tetapi sama pentingnya dengan pengendalian biaya. Biaya memperbaiki data berkualitas rendah yang mengalir ke bisnis bawahannya sering kali jauh melebihi investasi dalam pemeriksaan di tahap ekstraksi. Dalam lingkungan produksi, setidaknya tiga pemeriksaan otomatis harus ditempatkan: pemeriksaan tingkat pengisian bidang memastikan bahwa bidang yang diperlukan dalam Schema tidak kosong, menandai catatan yang tidak biasa untuk tinjauan manual daripada langsung dibuang; pemeriksaan rentang numerik memvalidasi aturan bisnis seperti harga yang tidak negatif dan persediaan dalam rentang wajar, menolak masukan yang melebihi ambang batas; pemeriksaan konsistensi format menyederhanakan bidang seperti tanggal, mata uang, dan nomor telepon, dengan ekspresi reguler dan kemampuan konversi format yang diintegrasikan dalam LLM saling melengkapi, memproses otomatis apa yang dapat dikonversi dan menandai apa yang tidak dapat dikonversi untuk intervensi manual. Tiga pemeriksaan ini menjaga keseimbangan dinamis antara biaya dan kualitas, mengalihkan catatan yang tidak biasa daripada menghapuskannya, memastikan kelengkapan sambil menghindari kebutaan data.
Strategi seimbang ini juga berlaku dalam skala yang lebih besar. Dalam praktik rekayasa nyata, mencapai akurasi ekstraksi otomatis 90% dikombinasikan dengan proses tinjauan manual yang formal sering kali lebih komersial daripada mencoba mencapai akurasi teoritis 100% tetapi dengan biaya implementasi yang puluhan kali lebih tinggi. Pemilihan penyimpanan data target juga bergantung pada penggunaan bawahannya: jika digunakan untuk permintaan API real-time dan tampilan frontend, PostgreSQL atau MongoDB adalah pilihan yang sesuai; jika digunakan untuk pencarian teks penuh dan analisis log, Elasticsearch adalah pilihan yang lebih baik; jika digunakan sebagai korpus pelatihan LLM, JSON terstruktur biasanya perlu diubah ulang ke format yang dibutuhkan oleh kerangka pelatihan dan disimpan di penyimpanan objek. Tujuannya bukan mencari solusi penyimpanan "satu ukuran cocok untuk semua", tetapi menyesuaikan mesin yang paling sesuai berdasarkan metode penggunaan data dan pola pencarian. Prinsip ini berlaku dalam semua keputusan rekayasa dari biaya token hingga pemilihan penyimpanan.
Klaim Kode Bonus CapSolver Anda
Tingkatkan anggaran otomasi Anda secara instan!
Gunakan kode bonus CAP26 saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan bonus tambahan 5% untuk setiap penambahan dana — tanpa batas.
Klaim sekarang di Dasbor CapSolver Anda
Kesimpulan
Dari HTML mentah hingga JSON terstruktur, seluruh rantai ekstraksi data AI dapat dirangkum menjadi lima tahap berurutan: pengumpulan, pembersihan, pemrosesan, validasi, dan penyimpanan. Setiap tahap menyelesaikan masalah tertentu, dan efektivitas setiap tahap bergantung pada penyelesaian sukses tahap sebelumnya.
Dalam rantai ini, lapisan pengumpulan data memainkan peran sebagai "pintu masuk," menentukan apakah seluruh Pipeline beroperasi normal atau benar-benar tidak aktif. Pertahanan berlapis empat dari sistem anti-scraping modern dan mekanisme CAPTCHA yang terus ditingkatkan membuat pengumpulan data menjadi tahap yang paling tidak terkendali dan berisiko tinggi dalam seluruh rantai. Ketika pembersihan konten dapat memampatkan HTML lebih dari 80%, model kecil khusus dapat melakukan ekstraksi terstruktur yang akurat dalam hitungan detik, dan validasi Schema dapat memastikan kepatuhan format output, "apakah data dapat dikumpulkan secara stabil" menjadi masalah utama yang menentukan keberhasilan proyek.
Ini adalah tepatnya nilai infrastruktur CapSolver dalam tumpukan teknologi ekstraksi data AI. Ia tidak menggantikan tahap pembersihan, pemrosesan, atau validasi tetapi menyediakan lapisan jaminan ketersediaan berkelanjutan di pintu masuk seluruh Pipeline. Ketika pengenalan CAPTCHA dapat diselesaikan secara otomatis dalam hitungan detik, dengan tingkat keberhasilan yang konsisten di atas 99%, pengumpulan data beralih dari gangguan sementara menjadi output berkelanjutan, dan sumber daya komputasi serta investasi rekayasa tahap berikutnya menghasilkan keuntungan yang berarti. Untuk bisnis yang bergantung pada pasokan data yang stabil, kontinuitas Pipeline itu sendiri adalah nilai bisnis, dan memastikan kontinuitas ini adalah penghalang terakhir yang harus diatasi oleh ekstraksi data AI dalam perjalanannya dari eksperimen ke penggunaan skala besar.