Web Scraping dengan SeleniumBase dan Python di 2024

Emma Foster
Machine Learning Engineer

Web scraping adalah alat yang ampuh untuk ekstraksi data, riset pasar, dan otomatisasi. Namun, CAPTCHA dapat menghambat upaya scraping otomatis. Dalam panduan ini, kita akan menjelajahi cara menggunakan SeleniumBase untuk web scraping dan mengintegrasikan CapSolver untuk menyelesaikan CAPTCHA secara efisien, menggunakan quotes.toscrape.com sebagai situs web contoh kita.
Pengenalan SeleniumBase
SeleniumBase adalah kerangka kerja Python yang menyederhanakan otomatisasi web dan pengujian. Ini memperluas kemampuan Selenium WebDriver dengan API yang lebih ramah pengguna, pemilih canggih, penantian otomatis, dan alat pengujian tambahan.
Menyiapkan SeleniumBase
Sebelum kita mulai, pastikan Anda telah menginstal Python 3 di sistem Anda. Ikuti langkah-langkah ini untuk menyiapkan SeleniumBase:
-
Instal SeleniumBase:
bashpip install seleniumbase -
Verifikasi Instalasi:
bashsbase --help
Scraper Dasar dengan SeleniumBase
Mari kita mulai dengan membuat skrip sederhana yang menavigasi ke quotes.toscrape.com dan mengekstrak kutipan dan penulis.
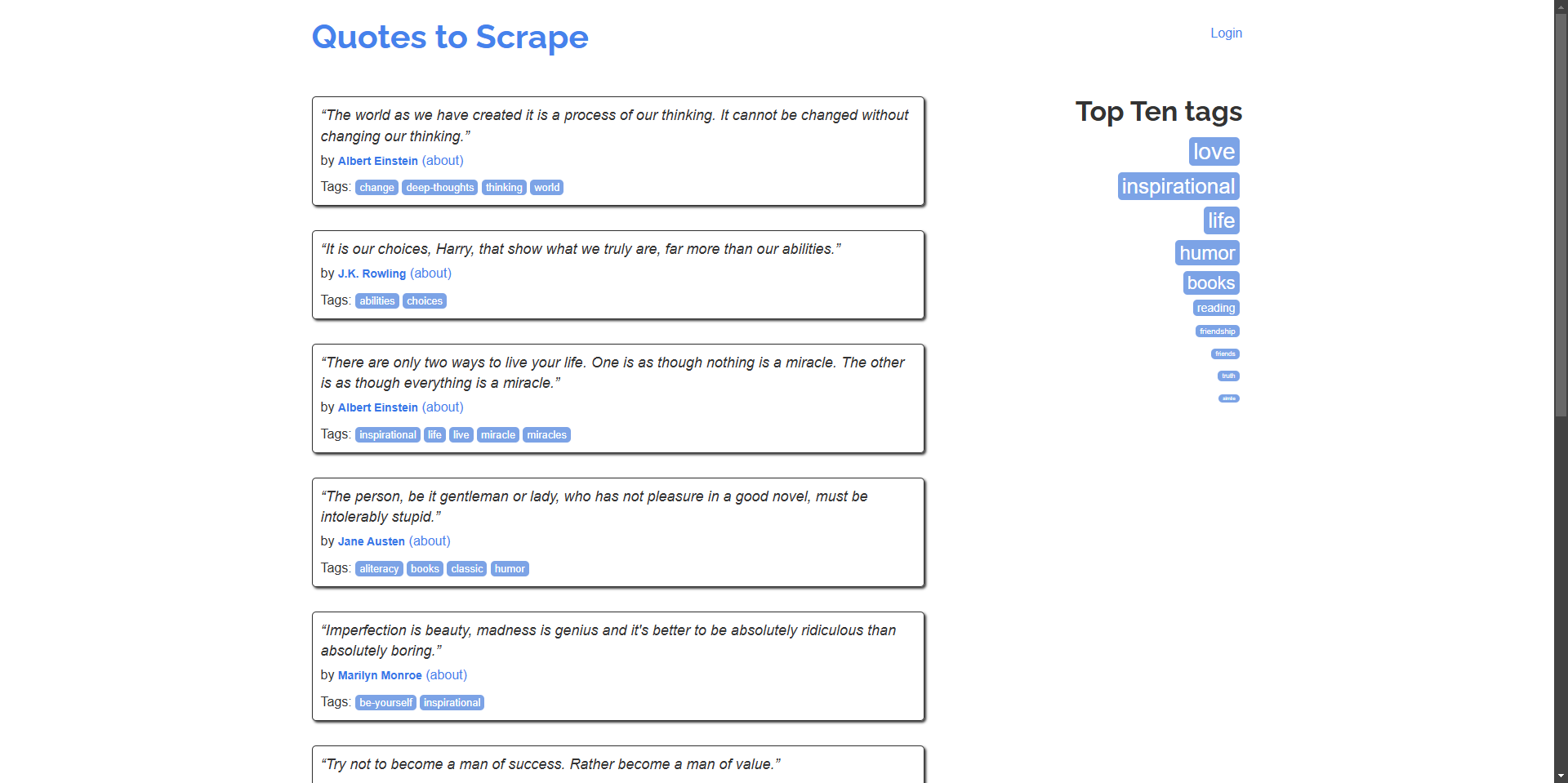
Contoh: Scrap kutipan dan penulisnya dari beranda.
python
# scrape_quotes.py
from seleniumbase import BaseCase
class QuotesScraper(BaseCase):
def test_scrape_quotes(self):
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
if __name__ == "__main__":
QuotesScraper().main()Jalankan skrip:
bash
python scrape_quotes.pyKeluaran:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” - Albert Einstein
...Contoh Web Scraping yang Lebih Canggih
Untuk meningkatkan keterampilan web scraping Anda, mari kita jelajahi contoh yang lebih canggih menggunakan SeleniumBase.
Scraping Beberapa Halaman (Paginasi)
Banyak situs web menampilkan konten di beberapa halaman. Mari kita modifikasi skrip kita untuk menavigasi semua halaman dan mengikis kutipan.
python
# scrape_quotes_pagination.py
from seleniumbase import BaseCase
class QuotesPaginationScraper(BaseCase):
def test_scrape_all_quotes(self):
self.open("https://quotes.toscrape.com/")
while True:
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
# Periksa apakah ada halaman berikutnya
if self.is_element_visible('li.next > a'):
self.click('li.next > a')
else:
break
if __name__ == "__main__":
QuotesPaginationScraper().main()Penjelasan:
- Kami mengulangi halaman dengan memeriksa apakah tombol "Berikutnya" tersedia.
- Kami menggunakan
is_element_visibleuntuk memeriksa tombol "Berikutnya". - Kami mengklik tombol "Berikutnya" untuk menavigasi ke halaman berikutnya.
Menangani Konten Dinamis dengan AJAX
Beberapa situs web memuat konten secara dinamis menggunakan AJAX. SeleniumBase dapat menangani skenario seperti itu dengan menunggu elemen dimuat.
Contoh: Scrap tag dari situs web, yang dimuat secara dinamis.
python
# scrape_dynamic_content.py
from seleniumbase import BaseCase
class TagsScraper(BaseCase):
def test_scrape_tags(self):
self.open("https://quotes.toscrape.com/")
# Klik tautan 'Top Ten tags' untuk memuat tag secara dinamis
self.click('a[href="/tag/"]')
self.wait_for_element("div.tags-box")
tags = self.find_elements("span.tag-item > a")
for tag in tags:
tag_name = tag.text
print(f"Tag: {tag_name}")
if __name__ == "__main__":
TagsScraper().main()Penjelasan:
- Kami menunggu elemen
div.tags-boxuntuk memastikan bahwa konten dinamis dimuat. wait_for_elementmemastikan bahwa skrip tidak berlanjut hingga elemen tersedia.
Mengirimkan Formulir dan Masuk
Terkadang, Anda perlu masuk ke situs web sebelum mengikis konten. Berikut cara Anda menangani pengiriman formulir.
Contoh: Masuk ke situs web dan mengikis kutipan dari halaman pengguna yang diautentikasi.
python
# scrape_with_login.py
from seleniumbase import BaseCase
class LoginScraper(BaseCase):
def test_login_and_scrape(self):
self.open("https://quotes.toscrape.com/login")
# Isi formulir masuk
self.type("input#username", "testuser")
self.type("input#password", "testpass")
self.click("input[type='submit']")
# Verifikasi masuk dengan memeriksa tautan keluar
if self.is_element_visible('a[href="/logout"]'):
print("Logged in successfully!")
# Sekarang kikis kutipan
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
else:
print("Login failed.")
if __name__ == "__main__":
LoginScraper().main()Penjelasan:
- Kami menavigasi ke halaman masuk dan mengisi kredensial.
- Setelah mengirimkan formulir, kami memverifikasi masuk dengan memeriksa keberadaan tautan keluar.
- Kemudian kami melanjutkan untuk mengikis konten yang tersedia untuk pengguna yang masuk.
Catatan: Karena quotes.toscrape.com mengizinkan nama pengguna dan kata sandi apa pun untuk demonstrasi, kita dapat menggunakan kredensial dummy.
Mengekstrak Data dari Tabel
Situs web sering kali menyajikan data dalam tabel. Berikut cara mengekstrak data tabel.
Contoh: Scrap data dari tabel (contoh hipotetis karena situs web tidak memiliki tabel).
python
# scrape_table.py
from seleniumbase import BaseCase
class TableScraper(BaseCase):
def test_scrape_table(self):
self.open("https://www.example.com/table-page")
# Tunggu tabel dimuat
self.wait_for_element("table#data-table")
rows = self.find_elements("table#data-table > tbody > tr")
for row in rows:
cells = row.find_elements("td")
row_data = [cell.text for cell in cells]
print(row_data)
if __name__ == "__main__":
TableScraper().main()Penjelasan:
- Kami menemukan tabel berdasarkan ID atau kelasnya.
- Kami mengulangi setiap baris dan kemudian setiap sel untuk mengekstrak data.
- Karena
quotes.toscrape.comtidak memiliki tabel, ganti URL dengan situs web nyata yang berisi tabel.
Mengintegrasikan CapSolver ke SeleniumBase
Meskipun quotes.toscrape.com tidak memiliki CAPTCHA, banyak situs web dunia nyata memilikinya. Untuk mempersiapkan kasus seperti itu, kita akan menunjukkan cara mengintegrasikan CapSolver ke dalam skrip SeleniumBase kita menggunakan ekstensi browser CapSolver.
Cara menyelesaikan captcha dengan SeleniumBase menggunakan Capsolver
-
Unduh Ekstensi CapSolver:
- Kunjungi halaman rilis CapSolver GitHub.
- Unduh versi terbaru ekstensi browser CapSolver.
- Buka ritsleting ekstensi ke direktori di root proyek Anda, misalnya,
./capsolver_extension.
Mengonfigurasi Ekstensi CapSolver
-
Temukan File Konfigurasi:
- Temukan file
config.jsonyang terletak di direktoricapsolver_extension/assets.
- Temukan file
-
Perbarui Konfigurasi:
- Atur
enabledForcaptchadan/atauenabledForRecaptchaV2ketruetergantung pada jenis CAPTCHA yang ingin Anda selesaikan. - Atur
captchaModeataureCaptchaV2Modeke"token"untuk pemecahan otomatis.
Contoh
config.json:json{ "apiKey": "YOUR_CAPSOLVER_API_KEY", "enabledForcaptcha": true, "captchaMode": "token", "enabledForRecaptchaV2": true, "reCaptchaV2Mode": "token", "solveInvisibleRecaptcha": true, "verbose": false }- Ganti
"YOUR_CAPSOLVER_API_KEY"dengan kunci API CapSolver Anda yang sebenarnya.
- Atur
Memuat Ekstensi CapSolver di SeleniumBase
Untuk menggunakan ekstensi CapSolver di SeleniumBase, kita perlu mengonfigurasi browser untuk memuat ekstensi saat dimulai.
-
Modifikasi Skrip SeleniumBase Anda:
- Impor
ChromeOptionsdariselenium.webdriver.chrome.options. - Atur opsi untuk memuat ekstensi CapSolver.
Contoh:
pythonfrom seleniumbase import BaseCase from selenium.webdriver.chrome.options import Options as ChromeOptions import os class QuotesScraper(BaseCase): def setUp(self): super().setUp() # Path ke ekstensi CapSolver extension_path = os.path.abspath('capsolver_extension') # Konfigurasikan opsi Chrome options = ChromeOptions() options.add_argument(f"--load-extension={extension_path}") options.add_argument("--disable-gpu") options.add_argument("--no-sandbox") # Perbarui pengandar dengan opsi baru self.driver.quit() self.driver = self.get_new_driver(browser_name="chrome", options=options) - Impor
-
Pastikan Path Ekstensi Benar:
- Pastikan
extension_pathmenunjuk ke direktori tempat Anda membuka ritsleting ekstensi CapSolver.
- Pastikan
Contoh Skrip dengan Integrasi CapSolver
Berikut adalah skrip lengkap yang mengintegrasikan CapSolver ke SeleniumBase untuk menyelesaikan CAPTCHA secara otomatis. Kami akan terus menggunakan https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php sebagai situs contoh kami.
python
# scrape_quotes_with_capsolver.py
from seleniumbase import BaseCase
from selenium.webdriver.chrome.options import Options as ChromeOptions
import os
class QuotesScraper(BaseCase):
def setUp(self):
super().setUp()
# Path ke folder ekstensi CapSolver
# Pastikan path ini menunjuk ke folder ekstensi Chrome CapSolver dengan benar
extension_path = os.path.abspath('capsolver_extension')
# Konfigurasikan opsi Chrome
options = ChromeOptions()
options.add_argument(f"--load-extension={extension_path}")
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
# Perbarui pengandar dengan opsi baru
self.driver.quit() # Tutup instance pengandar yang ada
self.driver = self.get_new_driver(browser_name="chrome", options=options)
def test_scrape_quotes(self):
# Arahkan ke situs target dengan reCAPTCHA
self.open("https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php")
# Periksa keberadaan CAPTCHA dan selesaikan jika perlu
if self.is_element_visible("iframe[src*='recaptcha']"):
# Ekstensi CapSolver seharusnya menangani CAPTCHA secara otomatis
print("CAPTCHA detected, waiting for CapSolver extension to solve it...")
# Tunggu CAPTCHA terselesaikan
self.sleep(10) # Sesuaikan waktu berdasarkan waktu penyelesaian rata-rata
# Lanjutkan dengan tindakan scraping setelah CAPTCHA terselesaikan
# Contoh tindakan: mengklik tombol atau mengekstrak teks
self.assert_text("reCAPTCHA demo", "h1") # Konfirmasi konten halaman
def tearDown(self):
# Bersihkan dan tutup browser setelah pengujian
self.driver.quit()
super().tearDown()
if __name__ == "__main__":
QuotesScraper().main()Penjelasan:
-
Metode setUp:
- Kami menimpa metode
setUpuntuk mengonfigurasi browser Chrome dengan ekstensi CapSolver sebelum setiap pengujian. - Kami menentukan path ke ekstensi CapSolver dan menambahkannya ke opsi Chrome.
- Kami menutup pengandar yang ada dan membuat yang baru dengan opsi yang diperbarui.
- Kami menimpa metode
-
Metode test_scrape_quotes:
- Kami menavigasi ke situs web target.
- Ekstensi CapSolver akan secara otomatis mendeteksi dan menyelesaikan CAPTCHA apa pun.
- Kami melakukan tugas scraping seperti biasa.
-
Metode tearDown:
- Kami memastikan browser ditutup setelah pengujian untuk membebaskan sumber daya.
Menjalankan Skrip:
bash
python scrape_quotes_with_capsolver.pyCatatan: Meskipun quotes.toscrape.com tidak memiliki CAPTCHA, mengintegrasikan CapSolver mempersiapkan scraper Anda untuk situs yang memilikinya.
Kode Bonus
Klaim Kode Bonus Anda untuk solusi captcha teratas di CapSolver: scrape. Setelah menukarkannya, Anda akan mendapatkan bonus tambahan 5% setelah setiap pengisian ulang, tanpa batas.

Kesimpulan
Dalam panduan ini, kita telah menjelajahi cara melakukan web scraping menggunakan SeleniumBase, membahas teknik scraping dasar dan contoh yang lebih canggih seperti menangani paginasi, konten dinamis, dan pengiriman formulir. Kami juga telah menunjukkan cara mengintegrasikan CapSolver ke dalam skrip SeleniumBase Anda untuk menyelesaikan CAPTCHA secara otomatis, memastikan sesi scraping tanpa gangguan.
Lihat Lebih Banyak
AIJun 18, 2026
Memilih Penyelesai CAPTCHA untuk Infrastruktur Agent Anda
Kerangka keputusan untuk memilih pemecah CAPTCHA untuk infrastruktur agen, yang berfokus pada pemetaan tantangan, pengikatan sesi, observabilitas, kontrol laju, dan penggunaan yang bertanggung jawab.
AIJun 18, 2026
API CAPTCHA terbaik untuk Agen AI pada tahun 2026
Panduan evaluasi praktis untuk memilih API CAPTCHA untuk agen AI pada 2026, berfokus pada cakupan tugas yang didokumentasikan, kontrak polling, validasi token, dan kontrol operasional.