Agen Kecerdasan Buatan dalam Web Scraping & Intelligence Kompetitif Panduan

Emma Foster
Machine Learning Engineer

TL;DR
- Agen AI adalah sistem perangkat lunak yang mandiri yang merencanakan, menjalankan, dan menyesuaikan tugas pengumpulan data multi-langkah tanpa input manusia terus-menerus.
- Dalam industri agen AI, web scraping dan intelijen kompetitif adalah salah satu area penerapan yang paling cepat berkembang.
- Agen AI dapat memantau harga kompetitor, melacak perubahan produk, dan mengekstrak data yang terstruktur dalam skala yang tidak bisa dicapai tim manual.
- Situs web modern menerapkan CAPTCHA, pembatasan kecepatan, dan lapisan deteksi bot yang mengganggu alur otomatis — layanan penyelesaian CAPTCHA seperti CapSolver membantu agen mempertahankan kelancaran.
- Penggunaan yang bertanggung jawab dan sesuai aturan dari agen AI untuk pengumpulan data memerlukan penghormatan terhadap robots.txt, ketentuan layanan, dan regulasi data yang berlaku.
Pendahuluan
Agen AI sedang mengubah cara bisnis mengumpulkan dan bertindak atas data eksternal. Dalam industri agen AI, dua kasus penggunaan telah bergerak dari eksperimental ke produksi lebih cepat daripada hampir yang lain: web scraping dan intelijen kompetitif. Perusahaan sekarang menerapkan agen yang secara mandiri menjelajahi web, mengekstrak informasi yang terstruktur, dan mengirimkannya langsung ke mesin harga, dashboard pasar, dan laporan strategis — semua tanpa seorang manusia mengklik tombol apa pun. Artikel ini menjelaskan apa agen-agen ini, bagaimana mereka bekerja, di mana mereka menambahkan nilai terbesar, dan apa hambatan teknis (termasuk CAPTCHA) yang harus dipertimbangkan tim saat membangun alur kerja yang sesuai aturan dan berkualitas produksi.
Apa Itu Agen AI, dan Mengapa Mereka Penting untuk Pengumpulan Data?
Agen AI adalah program perangkat lunak yang mempersepsikan lingkungannya, merenungkan tujuan, dan mengambil rangkaian tindakan untuk mencapainya — lalu menyesuaikan diri berdasarkan apa yang diamati. Berbeda dengan skrip sederhana yang mengikuti jalur tetap, agen dapat memutuskan halaman mana yang akan dikunjungi berikutnya, bagaimana menangani perubahan tata letak yang tidak terduga, dan kapan mengulang permintaan yang gagal.
IBM mendefinisikan agen AI sebagai sistem yang menggabungkan persepsi, penalaran, dan tindakan dalam loop terus-menerus. Loop ini adalah apa yang membuatnya kuat untuk pengumpulan data: web itu berantakan, dinamis, dan tidak konsisten, dan lapisan penalaran menangani variasi ini jauh lebih baik daripada pengumpul data yang kaku.
Industri agen AI berkembang dengan kecepatan luar biasa. Menurut MarketsandMarkets, pasar agen AI global diperkirakan akan tumbuh dari 7,84 miliar dolar AS pada 2025 menjadi 52,62 miliar dolar AS pada 2030, dengan CAGR 46,3%. Penelitian dan pengumpulan data adalah tiga kasus penggunaan utama yang sudah diterapkan. Laporan LangChain State of AI Agents menemukan bahwa 51% perusahaan yang disurvei telah memiliki agen yang berjalan di produksi sejak 2024, dengan penelitian dan pengumpulan data disebut sebagai aplikasi utama — melebihi layanan pelanggan dan produktivitas pribadi.
Arsitektur Inti: Bagaimana Agen AI Beroperasi dalam Alur Kerja Scraping
Memahami arsitektur membantu tim membangun sistem yang lebih andal. Alur kerja scraping industri agen AI yang umum memiliki empat lapisan:
1. Lapisan perencanaan
Agen menerima tujuan tingkat tinggi — misalnya, "kumpulkan harga harian untuk 50 SKU teratas di tiga situs kompetitor." Ia memecahnya menjadi tugas sub: mengidentifikasi URL, menjadwalkan permintaan, menentukan skema ekstraksi. Dalam pengaturan yang lebih canggih, lapisan perencanaan menggunakan LLM untuk menghasilkan rencana eksekusi langkah demi langkah yang dapat direvisi selama berjalan jika kondisinya berubah.
2. Lapisan eksekusi
Agen mengirim permintaan HTTP atau mengontrol browser tanpa tampilan (Playwright, Puppeteer, Selenium). Ia menganalisis HTML, API JSON, atau konten JavaScript yang dirender dan memetakan ke format output yang terstruktur. Lapisan eksekusi harus menangani pagination, scroll tak terbatas, alur login, dan konten dinamis yang dirender di sisi klien — semua skenario di mana pengumpul data statis akan gagal.
3. Lapisan pengamatan dan penyesuaian
Setelah setiap tindakan, agen memeriksa hasilnya. Apakah halaman dimuat dengan benar? Apakah data yang diharapkan hadir? Apakah CAPTCHA muncul? Berdasarkan pengamatan, ia memutuskan langkah berikutnya — mengulang, meningkatkan, atau melanjutkan. Ini adalah lapisan yang membuat agen benar-benar berbeda dari skrip: mereka tidak hanya mengeksekusi, tetapi mengevaluasi.
4. Lapisan memori dan penyimpanan
Data yang dikumpulkan ditulis ke database, warehouse data, atau alur kerja downstream. Beberapa agen mempertahankan memori jangka pendek (konteks sesi) dan jangka panjang (tren harga historis, pola URL yang dikenal). Memori jangka panjang memungkinkan agen mendeteksi anomali — misalnya, harga yang turun 80% semalaman kemungkinan besar adalah kesalahan data, bukan diskon nyata.
Model empat lapisan ini adalah apa yang membedakan alur kerja pengumpulan data modern dari pengumpul data cron-job tradisional. Agen tidak hanya mengambil halaman — ia merenungkan tugas, dan perbedaan ini penting pada skala produksi.
Kasus Penggunaan Utama dalam Intelijen Kompetitif
Intelijen kompetitif adalah salah satu aplikasi bernilai tinggi dari alat industri agen AI. Berikut adalah skenario paling umum di mana tim menerapkan agen hari ini:
Pemantauan Harga
Tim e-commerce menggunakan agen untuk memantau harga kompetitor di ribuan SKU secara real-time. Agen mengunjungi halaman produk, mengekstrak data harga dan ketersediaan, dan menulisnya ke mesin harga yang dapat memicu penyesuaian otomatis. Pemantauan manual pada skala ini tidak layak — seorang analis mungkin memantau 50 produk per hari; agen dapat memantau 50.000.
Lapisan pengamatan agen sangat kritis di sini. Jika halaman produk mengembalikan status 429 (Terlalu Banyak Permintaan), agen akan mundur dan mengulang dengan penundaan eksponensial. Jika tata letak halaman berubah — kejadian umum selama perancangan ulang situs — agen dapat menggunakan LLM untuk mengidentifikasi kembali elemen harga daripada gagal diam-diam.
Pemantauan Produk dan Fitur
Perusahaan SaaS menerapkan agen untuk memantau halaman log perubahan, catatan rilis, dan blog pengumuman fitur. Ketika kompetitor mengirimkan integrasi baru atau mengubah tingkat harga, agen menandai hal itu dalam beberapa jam daripada hari. Manajer produk menerima ringkasan yang terstruktur daripada dump HTML mentah, karena lapisan ekstraksi agen memetakan konten ke skema yang didefinisikan sebelumnya: nama fitur, tanggal rilis, tingkat yang terkena dampak, dan ringkasan.
Jenis pemantauan berkelanjutan ini dulu membutuhkan analis khusus. Dalam industri agen AI saat ini, ini berjalan sebagai proses latar belakang yang dijadwalkan.
Agregasi Ulasan dan Sentimen
Agen mengumpulkan ulasan pelanggan dari platform seperti G2, Trustpilot, dan toko aplikasi. Lapisan pemrosesan bahasa alami kemudian mengklasifikasikan sentimen, mengekstrak tema yang berulang, dan menampilkan kekurangan produk — memberi tim produk sinyal terus-menerus dari pasar. Tim dapat mengidentifikasi bahwa pengguna kompetitor secara konsisten mengeluh tentang onboarding yang lambat, lalu menggunakan wawasan ini untuk memperhalus posisi mereka sendiri.
Pemantauan SERP dan Konten
Tim SEO dan konten menggunakan agen untuk memantau peringkat kata kunci, memantau profil backlink, dan mengidentifikasi konten baru yang diterbitkan oleh kompetitor. Ini langsung memasok kalender editorial dan strategi pembangunan tautan. Agen juga dapat mendeteksi ketika kompetitor menerbitkan konten yang menargetkan kata kunci yang saat ini mereka peringkat, memicu pemberitahuan sebelum peringkat berubah.
Intelijen Pencarian Pekerjaan
Memantau iklan pekerjaan kompetitor mengungkapkan niat strategis. Lonjakan tiba-tiba dalam perekrutan insinyur data menandai perbaikan platform. Kumpulan peran penjualan perusahaan menunjukkan ekspansi pasar. Agen dapat memantau halaman karier harian dan mengumpulkan sinyal ini secara otomatis, memberi tim strategi indikator awal yang sering kali lebih andal daripada pernyataan pers.
Untuk melihat lebih luas bagaimana alat scraping berkembang untuk mendukung alur kerja ini, lihat Alat Scraping Web Terbaik pada 2026 dan Alat Ekstraksi Data Terbaik.
Perbandingan: Pengumpul Tradisional vs. Agen AI
| Dimensi | Pengumpul Tradisional | Agen AI |
|---|---|---|
| Definisi Tugas | Pemilih tetap, jalur kaku | Berbasis tujuan, adaptif |
| Menangani perubahan tata letak | Gagal, memerlukan perbaikan manual | Mendeteksi dan menyesuaikan |
| Navigasi multi-langkah | Terbatas | Kemampuan bawaan |
| Pemulihan kesalahan | Intervensi manual | Logika ulang otomatis |
| Penanganan CAPTCHA | Menghentikan alur | Dapat mengintegrasikan layanan penyelesaian |
| Skalabilitas | Linear dengan upaya teknis | Skalabel dengan komputasi |
| Kesadaran kepatuhan | Tidak ada yang terintegrasi | Dapat diberi instruksi untuk menghormati aturan |
Masalah CAPTCHA: Di Mana Agen AI Mengalami Kendala
Bahkan alur kerja industri agen AI yang paling canggih akan akhirnya menghadapi CAPTCHA. Situs web menggunakan mereka sebagai pertahanan utama terhadap akses otomatis. Jenis CAPTCHA yang paling umum termasuk:
- reCAPTCHA v2 — tantangan pemilihan gambar ("pilih semua lampu lalu lintas")
- reCAPTCHA v3 — penilaian risiko berbasis skor yang tidak terlihat
- Cloudflare Turnstile — tantangan yang lebih baru dan fokus pada privasi yang menggantikan CAPTCHA tradisional
- GeeTest — tantangan slider dan perilaku umum di platform Asia
Ketika agen menghadapi CAPTCHA, alur kerja terhenti. Agen tidak dapat melanjutkan tanpa token valid atau tantangan yang diselesaikan. Ini adalah masalah struktural, bukan kasus tepi — sumber data bernilai tinggi hampir selalu dilindungi.
Solusi yang sesuai adalah mengintegrasikan API penyelesaian CAPTCHA ke dalam lapisan pengamatan agen. Ketika agen mendeteksi tantangan, ia mengirim parameter yang relevan ke layanan penyelesaian, menerima token, dan menyisipkannya ke dalam permintaan untuk melanjutkan. Agen tidak pernah perlu berhenti.
CapSolver adalah layanan penyelesaian CAPTCHA yang didukung AI yang dirancang khusus untuk pola integrasi ini. Ia mendukung reCAPTCHA v2/v3/Enterprise, Cloudflare Turnstile, GeeTest, dan AWS WAF CAPTCHA. Solusi dikembalikan dalam 1–5 detik melalui API REST, tanpa keterlibatan manusia — seluruh alur tetap otomatis.
Untuk tim yang membangun alur kerja industri agen AI dalam Python, integrasinya mengikuti pola yang didokumentasikan dalam dokumentasi API resmi CapSolver. Agen mengirim tugas, memantau hasilnya, dan menggunakan token yang dikembalikan untuk menyelesaikan permintaan yang dilindungi. Ini menjaga alur kerja tetap berjalan tanpa intervensi manual.
Anda juga dapat menjelajahi cara menyelesaikan CAPTCHA saat web scraping untuk panduan praktis tentang pola integrasi umum.
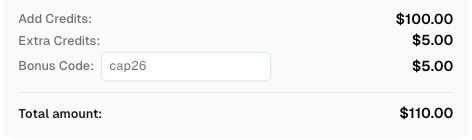
Klaim Kode Bonus CapSolver Anda
Tingkatkan anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAP26 saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan bonus tambahan 5% pada setiap penambahan dana — tanpa batas.
Klaim sekarang di Dashboard CapSolver Anda
Kerangka Agen AI yang Digunakan dalam Alur Kerja Scraping
Beberapa kerangka open-source dan komersial telah muncul khususnya untuk mendukung kasus penggunaan industri agen AI dalam pengumpulan data:
- LangChain / LangGraph — populer untuk membangun agen penalaran multi-langkah dengan penggunaan alat
- AutoGen (Microsoft) — mendukung kolaborasi agen multi, berguna untuk tugas scraping paralel
- CrewAI — orkestrasi agen berbasis peran, cocok untuk alur kerja intelijen kompetitif
- Crawl4AI — dirancang khusus untuk crawling web yang ramah AI dengan output terstruktur
- ScrapeGraph AI — menggabungkan LLM dengan scraping untuk mengekstrak data menggunakan instruksi dalam bahasa alami
Untuk breakdown rinci tentang opsi utama, lihat 9 Kerangka Agen AI Terbaik pada 2026.
Setiap kerangka menangani lapisan perencanaan dan eksekusi secara berbeda, tetapi semua dari mereka akhirnya menghadapi tantangan infrastruktur yang sama: pembatasan kecepatan, blokir IP, dan CAPTCHA. Pemilihan kerangka memengaruhi arsitektur; lapisan penyelesaian CAPTCHA adalah komponen yang terpisah dan dapat diintegrasikan.
Kepatuhan dan Penggunaan yang Bertanggung Jawab
Industri agen AI beroperasi dalam lingkungan hukum dan etika yang harus tim ambil serius. Pengumpulan data otomatis tidak secara inheren ilegal, tetapi harus dilakukan secara bertanggung jawab.
Prinsip utama:
- Hormati robots.txt — file ini memberi tahu jalur mana yang diizinkan oleh pemilik situs untuk akses otomatis. Agen harus memproses dan menghormatinya.
- Tinjau ketentuan layanan — banyak situs secara eksplisit melarang scraping otomatis. Tinjauan hukum diperlukan untuk kasus penggunaan volume tinggi atau sensitif secara komersial.
- Pembatasan kecepatan — agen harus menerapkan penundaan dan menghormati header Retry-After untuk menghindari beban berlebihan pada server target.
- Data pribadi — mengumpulkan informasi yang dapat diidentifikasi pribadi memicu regulasi seperti GDPR, CCPA, dan lainnya. Agen harus dibatasi untuk mengumpulkan hanya apa yang diperlukan.
- Kemutakhiran dan akurasi data — intelijen kompetitif hanya bernilai jika data itu dapat dipercaya. Agen harus menyertakan langkah validasi untuk menandai anomali.
Penelitian Deloitte tentang AI agen menyoroti bahwa tata kelola dan pengawasan adalah kekhawatiran utama bagi tim perusahaan yang menerapkan agen di produksi. Membangun kepatuhan ke dalam instruksi agen sejak awal jauh lebih mudah daripada memperbaikinya nanti.
Kesimpulan
Agen AI telah bergerak dari konsep penelitian menjadi alat produksi di seluruh industri agen AI, dan web scraping dengan intelijen kompetitif adalah salah satu demonstrasi paling jelas tentang nilai mereka. Mereka menangani halaman dinamis, menyesuaikan perubahan tata letak, menjalankan navigasi multi-langkah, dan skalabel ke volume yang tidak bisa dicapai proses manual.
Tantangan teknis benar-benar ada — CAPTCHA, pembatasan kecepatan, dan sistem deteksi bot dirancang untuk mengganggu jenis otomatisasi ini. Mengintegrasikan layanan penyelesaian CAPTCHA yang andal seperti CapSolver ke dalam alur kerja agen menghilangkan salah satu titik kegagalan yang paling umum, menjaga pengumpulan data tetap berkelanjutan dan sesuai aturan.
Jika Anda sedang membangun atau mengevaluasi pipa industri agen AI untuk intelijen kompetitif, mulailah dengan tujuan data yang jelas, pilih kerangka kerja yang sesuai dengan kebutuhan orkestrasi Anda, dan rencanakan lapisan infrastruktur — termasuk penanganan CAPTCHA — sebelum memasuki produksi.
FAQ
Q1: Apa perbedaan antara web scraper dan agen AI untuk pengumpulan data?
Web scraper tradisional mengikuti sekumpulan instruksi tetap — pemilih yang spesifik, URL yang ditentukan sebelumnya, dan jalur eksekusi yang kaku. Agen AI menambahkan lapisan pemikiran: ia dapat memahami tujuan, merencanakan langkah-langkah yang diperlukan untuk mencapainya, menyesuaikan diri ketika halaman berubah, dan memulihkan diri dari kesalahan secara otomatis. Kemampuan adaptif adalah perbedaan kritis untuk intelijen kompetitif dalam skala besar.
Q2: Apakah agen AI legal digunakan untuk web scraping?
Pengumpulan data otomatis legal di banyak yurisdiksi ketika menargetkan informasi yang tersedia secara publik dan mematuhi ketentuan layanan situs serta hukum perlindungan data yang berlaku. Kondisi hukum bervariasi tergantung pada negara dan kasus penggunaan. Tim harus meninjau robots.txt, ketentuan layanan, dan regulasi yang relevan (GDPR, CCPA) sebelum mengembangkan agen dalam skala besar.
Q3: Bagaimana agen AI menangani CAPTCHA selama scraping?
Ketika agen menemui CAPTCHA, ia dapat terintegrasi dengan API penyelesaian CAPTCHA. Agen mengirimkan parameter tantangan ke API, menerima token yang valid, dan menyisipkannya ke dalam permintaan untuk melanjutkan. Layanan seperti CapSolver mendukung pola ini untuk reCAPTCHA, hCaptcha, Cloudflare Turnstile, dan jenis tantangan umum lainnya, mengembalikan solusi dalam hitungan detik melalui REST API.
Q4: Framework agen AI mana yang terbaik untuk pipa intelijen kompetitif?
Pilihan yang tepat tergantung pada stack dan kompleksitas alur kerja Anda. LangChain dan LangGraph banyak digunakan dan memiliki dukungan komunitas yang kuat. CrewAI cocok untuk alur kerja multi-agen berbasis peran. Crawl4AI dan ScrapeGraph AI dirancang khusus untuk ekstraksi data web. Kebanyakan tim memulai dengan satu framework dan menambahkan komponen infrastruktur yang dapat dikomposisi — proxy, penyelesaian CAPTCHA, penyimpanan — seiring berkembangnya pipa.
Q5: Seberapa sering agen intelijen kompetitif harus dijalankan?
Frekuensi tergantung pada volatilitas data. Data harga untuk e-commerce mungkin memerlukan pembaruan harian. Pemantauan fitur dan intelijen lowongan kerja dapat dijalankan harian atau mingguan. Pemantauan SERP biasanya dijalankan harian. Agen harus dijadwalkan berdasarkan seberapa cepat data dasar berubah, seimbang dengan beban yang diberikan pada server target dan biaya komputasi.
Lihat Lebih Banyak
AIJun 23, 2026
SDK Pengurai Captcha Asli untuk Agen AI
Panduan yang fokus pada pengembang untuk SDK penyelesaian CAPTCHA native untuk agen AI, dengan batas wrapper, contoh resmi, pemeriksaan sesi, dan penanganan kegagalan.
AIJun 23, 2026
Memilih Layanan Pemecah CAPTCHA untuk Otomasi Agen
Checklist praktis untuk pembeli dan insinyur dalam memilih layanan penyelesaian CAPTCHA untuk otomatisasi agen dalam alur kerja yang terkontrol dan terdokumentasi.