Penyedotan Web di Node.js: Menggunakan Node Unblocker dan CapSolver

Rajinder Singh
Deep Learning Researcher
TL;Dr
- Web scraping di Node.js menghadapi tantangan meningkat dari deteksi bot yang canggih dan CAPTCHA.
- Node Unblocker secara efektif menangani penghalang dasar seperti pemblokiran IP dan batasan geografis dengan bertindak sebagai middleware proxy.
- CapSolver penting untuk mengatasi tantangan lanjutan, khususnya CAPTCHA, yang tidak dapat diatasi Node Unblocker sendirian.
- Menggabungkan Node Unblocker dengan CapSolver menciptakan solusi web scraping di Node.js yang kuat dan efisien.
- Integrasi yang tepat dari alat-alat ini memastikan pengambilan data yang andal dari situs web yang kompleks.
Pendahuluan
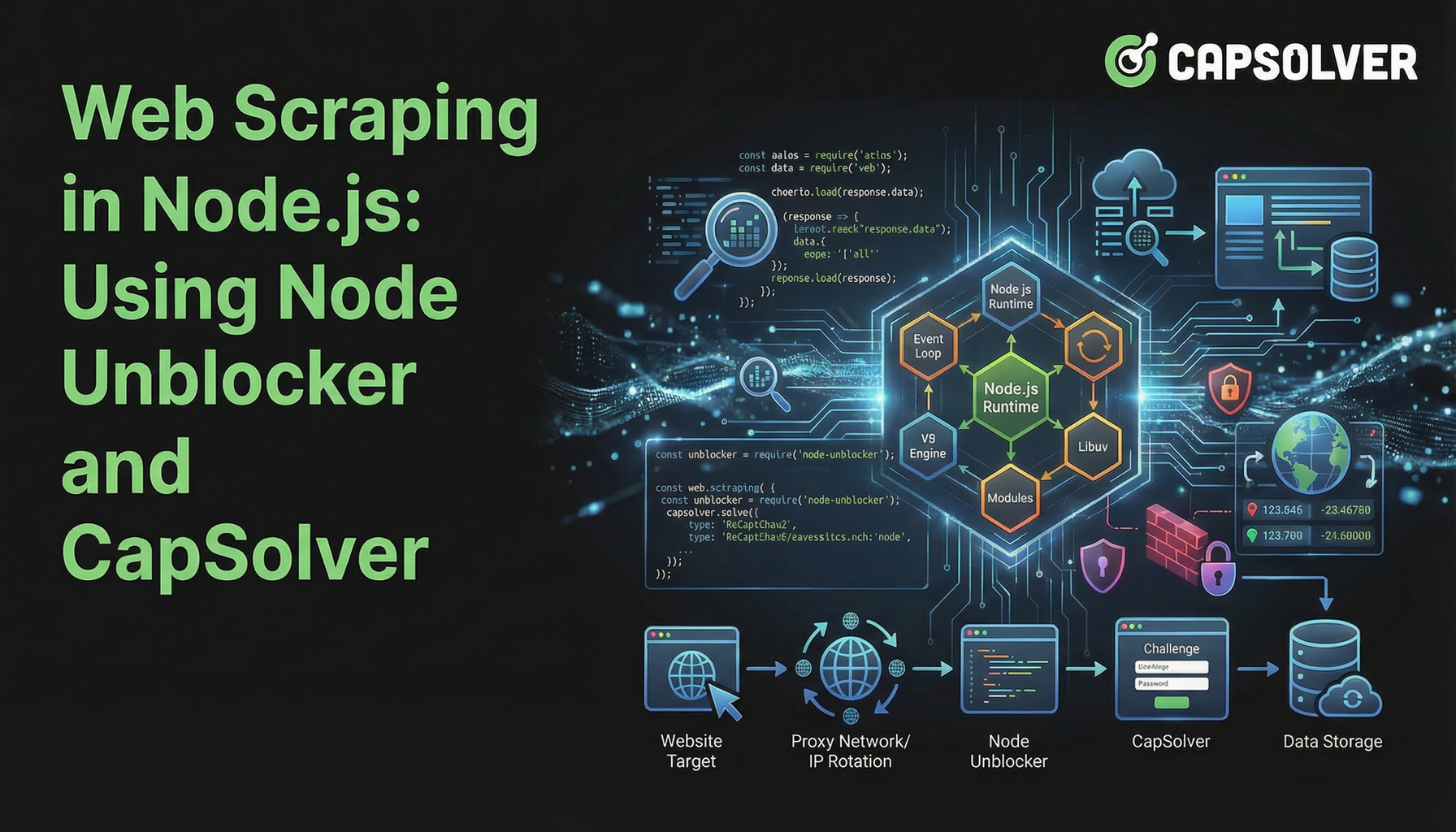
Web scraping di Node.js telah menjadi teknik yang kuat untuk pengumpulan data, tetapi sering menghadapi hambatan signifikan. Situs web semakin menerapkan pertahanan lanjutan untuk mencegah akses otomatis, membuat pengambilan data yang sukses menjadi tugas yang kompleks. Artikel ini menjelaskan cara meningkatkan proyek web scraping di Node.js Anda dengan menggabungkan Node Unblocker, middleware proxy yang fleksibel, dengan CapSolver, layanan penyelesaian CAPTCHA yang khusus. Kami akan memandu Anda melalui pembuatan infrastruktur pengambilan data yang tahan lama yang dapat melewati pembatasan web umum dan memastikan aliran data yang konsisten. Panduan ini ditujukan untuk pengembang yang mencari metode efisien dan andal untuk web scraping di Node.js di lingkungan online yang menantang saat ini.
Memahami Tantangan Landscape Web Scraping
Situs web modern menggunakan berbagai teknik untuk mencegah upaya web scraping otomatis. Pertahanan ini berkisar dari pemblokiran IP sederhana hingga tantangan interaktif yang kompleks. Berhasil melakukan web scraping di Node.js memerlukan pemahaman dan penanganan hambatan ini.
Tantangan umum meliputi:
- Pemblokiran Berbasis IP: Situs web mendeteksi dan memblokir permintaan yang berasal dari alamat IP yang mencurigakan, sering dikaitkan dengan pusat data atau aktivitas scraping yang diketahui.
- Pembatasan Tingkat Permintaan: Server membatasi jumlah permintaan dari satu IP dalam jangka waktu tertentu, menyebabkan pemblokiran sementara atau kesalahan.
- Batasan Geografis: Ketersediaan konten bervariasi berdasarkan lokasi geografis, mencegah akses ke data tertentu dari wilayah tertentu.
- CAPTCHA: Ini dirancang untuk membedakan pengguna manusia dari bot, menyajikan teka-teki visual atau interaktif yang sulit untuk script otomatis.
- Konten Dinamis: Situs web yang merender konten dengan JavaScript memerlukan pengambil data untuk menjalankan JavaScript, menambah kompleksitas.
- Manajemen Sesi: Memelihara status sesi dan menangani cookie dengan benar sangat penting untuk menavigasi bagian situs yang terotentikasi.
Tantangan ini menyoroti kebutuhan alat yang canggih di luar perpustakaan permintaan HTTP dasar saat terlibat dalam web scraping serius di Node.js.
Node Unblocker: Dasar untuk Pengambilan Data yang Tahan Lama
Node Unblocker adalah middleware Node.js open-source yang dirancang untuk memfasilitasi web scraping di Node.js dengan mengatasi pembatasan web umum. Ini bertindak sebagai proxy, mengarahkan permintaan Anda melalui server perantara, dengan demikian menyembunyikan alamat IP asli Anda dan mungkin melewati pembatasan geografis. Kekuatan utamanya terletak pada kemampuannya untuk memodifikasi header permintaan dan respons, menangani cookie, dan mengelola sesi, menjadikannya aset berharga untuk lapisan pertahanan awal.
Keuntungan Utama Node Unblocker:
- Penyembunyian IP: Mengarahkan lalu lintas melalui proxy, menyembunyikan alamat IP asli scraper Anda. Ini membantu dalam menghindari pemblokiran berbasis IP.
- Mengatasi Batasan Geografis: Dengan menggunakan proxy yang berada di berbagai wilayah, Anda dapat mengakses konten yang dibatasi secara geografis.
- Manajemen Header: Memungkinkan modifikasi mudah header HTTP, seperti User-Agent, Referer, dan Accept-Language, untuk meniru permintaan browser yang sah.
- Penanganan Cookie: Secara otomatis mengelola cookie, penting untuk mempertahankan status sesi di antara permintaan yang berbeda.
- Integrasi Middleware: Dirancang untuk berintegrasi secara mulus dengan kerangka kerja Node.js populer seperti Express.js, menyederhanakan pemasangan dan penggunaan.
- Fleksibilitas Open-Source: Sebagai open-source, ini menawarkan kontrol penuh dan opsi penyesuaian untuk pengembang untuk menyesuaikannya dengan kebutuhan pengambilan data spesifik.
Menyiapkan Node Unblocker untuk Web Scraping di Node.js
Mengintegrasikan Node Unblocker ke dalam proyek web scraping di Node.js Anda sederhana. Pertama, pastikan Anda memiliki Node.js dan npm terpasang. Kemudian, Anda dapat menginstal Node Unblocker dan Express.js:
bash
npm init -y
npm install express unblockerBerikutnya, buat file index.js dan konfigurasikan Node Unblocker sebagai middleware:
javascript
const express = require("express");
const Unblocker = require("unblocker");
const app = express();
const unblocker = new Unblocker({ prefix: "/proxy/" });
app.use(unblocker);
const port = 3000;
app.listen(port).on("upgrade", unblocker.onUpgrade);
console.log(`Proxy berjalan di http://localhost:${port}/proxy/`);Konfigurasi dasar ini menciptakan server proxy lokal. Anda kemudian dapat mengarahkan permintaan pengambilan data Anda melalui http://localhost:3000/proxy/ diikuti oleh URL tujuan. Untuk konfigurasi yang lebih rinci, lihat repo GitHub Node Unblocker.
Bagian yang Hilang: Menyelesaikan CAPTCHA dengan CapSolver
Sementara Node Unblocker unggul dalam menangani pembatasan tingkat jaringan, ia tidak menangani tantangan seperti CAPTCHA. Teka-teki visual atau interaktif ini dirancang khusus untuk membedakan pengguna manusia dari script otomatis. Ketika web scraping di Node.js Anda menemui CAPTCHA, proses pengambilan data berhenti.
Ini adalah saat CapSolver menjadi alat yang tidak tergantikan. CapSolver adalah layanan penyelesaian CAPTCHA yang khusus yang menyediakan API untuk menyelesaikan berbagai jenis CAPTCHA secara programatis, termasuk reCAPTCHA v2, reCAPTCHA v3, dan Cloudflare Turnstile. Mengintegrasikan CapSolver ke dalam alur kerja web scraping di Node.js Anda memungkinkan scraper Anda untuk secara otomatis melewati langkah verifikasi manusia ini, memastikan pengumpulan data yang tidak terganggu.
Gunakan kode
CAP26saat mendaftar di CapSolver untuk mendapatkan kredit tambahan!
Bagaimana CapSolver Meningkatkan Web Scraping di Node.js:
- Penyelesaian CAPTCHA Otomatis: Menyelesaikan CAPTCHA kompleks tanpa intervensi manual.
- Dukungan CAPTCHA Luas: Menangani berbagai jenis CAPTCHA, menawarkan solusi komprehensif.
- Integrasi API: Menyediakan API yang sederhana untuk integrasi yang mudah ke proyek Node.js yang ada.
- Keandalan: Menawarkan tingkat keberhasilan tinggi untuk penyelesaian CAPTCHA, meminimalkan gangguan.
- Kecepatan: Memberikan solusi CAPTCHA yang cepat, mempertahankan efisiensi operasi pengambilan data Anda.
Mengintegrasikan CapSolver ke dalam Pengambil Data Node.js Anda
Untuk mengintegrasikan CapSolver, Anda biasanya akan membuat panggilan API ke CapSolver setiap kali CAPTCHA terdeteksi. Proses ini melibatkan pengiriman detail CAPTCHA ke CapSolver, menerima solusinya, lalu mengirimkan solusi tersebut kembali ke situs tujuan. Ini dapat dilakukan menggunakan klien HTTP seperti Axios dalam aplikasi Node.js Anda.
Sebagai contoh, setelah menyiapkan proxy Node Unblocker Anda, logika pengambilan data Anda akan mencakup pemeriksaan CAPTCHA. Jika ditemukan, Anda akan memulai panggilan ke CapSolver. Anda dapat menemukan contoh dan dokumentasi rinci tentang cara mengintegrasikan CapSolver untuk berbagai jenis CAPTCHA di artikel kami, seperti Bagaimana Menyelesaikan reCAPTCHA dengan Node.js dan Bagaimana Menyelesaikan CAPTCHA Cloudflare Turnstile dengan NodeJS.
Perbandingan: Node Unblocker Sendirian vs. Node Unblocker + CapSolver
Memahami peran berbeda Node Unblocker dan CapSolver penting untuk web scraping yang efektif di Node.js. Sementara Node Unblocker menyediakan kemampuan proxy dasar, CapSolver menangani tantangan khusus yang lebih lanjut.
| Fitur/Alat | Node Unblocker Sendirian | Node Unblocker + CapSolver |
|---|---|---|
| Penyembunyian IP | Ya | Ya |
| Mengatasi Batasan Geografis | Ya | Ya |
| Manajemen Header/Kuki | Ya | Ya |
| Penyelesaian CAPTCHA | Tidak | Ya |
| Deteksi Bot (Dasar) | Sebagian (melalui perubahan IP/header) | Ditingkatkan (menyelesaikan CAPTCHA, mengurangi skor bot) |
| Kompleksitas Pemasangan | Sedang | Sedang hingga Tinggi (memerlukan integrasi API CapSolver) |
| Biaya | Gratis (open-source) | Gratis (open-source) + biaya layanan CapSolver |
| Keandalan untuk Situs yang Kompleks | Terbatas | Tinggi |
| Kasus Penggunaan Ideal | Situs sederhana, pengumpulan data dasar, pengujian awal | Situs kompleks dengan CAPTCHA, ekstraksi data skala besar, lingkungan produksi |
Perbandingan ini jelas menunjukkan bahwa untuk web scraping di Node.js yang kuat terhadap pertahanan web modern, pendekatan kombinasi lebih unggul. Node Unblocker menangani pengiriman dan penipuan dasar, sementara CapSolver memberikan kecerdasan untuk mengatasi CAPTCHA.
Strategi Lanjutan untuk Web Scraping di Node.js
Di luar hanya menggunakan Node Unblocker dan CapSolver, beberapa strategi lanjutan dapat meningkatkan proyek web scraping di Node.js Anda. Teknik-teknik ini fokus pada meniru perilaku manusia dan mengelola sumber daya secara efisien.
- Rotasi User-Agent: Mengganti header User-Agent secara berkala membantu menghindari deteksi. Kumpulan User-Agent yang beragam membuat permintaan Anda tampak berasal dari browser dan perangkat yang berbeda. Pelajari lebih lanjut tentang mengelola user agent di artikel kami tentang User-Agent Terbaik.
- Penundaan dan Randomisasi Permintaan: Memasukkan penundaan acak antara permintaan mencegah scraper Anda menabrak batas tingkat permintaan. Pola penjelajahan manusia jarang konsisten sempurna.
- Browser Tanpa Akses: Untuk situs web yang bergantung berat pada JavaScript, menggunakan browser tanpa akses seperti Puppeteer atau Playwright sangat penting. Alat-alat ini dapat menjalankan JavaScript dan merender halaman seperti browser nyata. Anda dapat mengintegrasikan CapSolver dengan alat-alat ini; lihat panduan kami tentang Cara Mengintegrasikan Puppeteer dan Cara Mengintegrasikan Playwright.
- Rotasi Proxy: Meskipun Node Unblocker menyediakan lapisan proxy tunggal, berputar melalui kumpulan proxy yang berbeda (residen, seluler) dapat mengurangi kemungkinan pemblokiran IP secara signifikan. Ini terutama penting untuk operasi web scraping di Node.js skala besar.
- Penanganan Kesalahan dan Pengulangan: Implementasikan penanganan kesalahan yang kuat dengan mekanisme pengulangan untuk permintaan yang gagal. Ini membuat scraper Anda lebih tahan terhadap masalah jaringan sementara atau pemblokiran lembut.
Dengan menggabungkan strategi-strategi ini dengan Node Unblocker dan CapSolver, Anda membangun solusi web scraping di Node.js yang sangat canggih dan efektif. Untuk saran umum tentang menghindari pemblokiran, lihat artikel kami tentang Menghindari Pemblokiran IP.
Kesimpulan
Web scraping di Node.js pada tahun 2026 membutuhkan pendekatan multi-faset untuk mengatasi pertahanan web yang semakin kompleks. Node Unblocker menyediakan dasar yang kuat dan open-source untuk mengelola koneksi proxy, menyembunyikan IP, dan menangani kekhasan HTTP dasar. Namun, untuk tantangan terberat, khususnya CAPTCHA, layanan khusus seperti CapSolver sangat penting. Sintesis antara Node Unblocker dan CapSolver menciptakan infrastruktur pengambilan data yang kuat dan andal, memungkinkan pengembang untuk mengekstrak data secara konsisten dan efisien.
Dengan mengintegrasikan alat-alat ini dan mengadopsi strategi pengambilan data lanjutan, Anda dapat membangun aplikasi web scraping di Node.js yang tahan terhadap mekanisme deteksi bot modern. Persenjatai proyek Anda dengan kombinasi alat yang tepat untuk memastikan upaya pengumpulan data Anda berhasil dan berkelanjutan.
Pertanyaan yang Sering Diajukan (FAQ)
Q: Apa yang digunakan Node Unblocker dalam web scraping?
A: Node Unblocker terutama digunakan sebagai middleware proxy dalam web scraping di Node.js untuk menyembunyikan alamat IP scraper, mengatasi batasan geografis, dan mengelola header HTTP dan cookie. Ini membantu dalam melewati penghalang dasar dan membuat permintaan tampak lebih sah.
Q: Apakah Node Unblocker dapat menyelesaikan CAPTCHA?
A: Tidak, Node Unblocker sendiri tidak dapat menyelesaikan CAPTCHA. Fungsinya fokus pada proxy tingkat jaringan dan modifikasi permintaan. Untuk menyelesaikan CAPTCHA yang ditemui selama web scraping di Node.js, Anda perlu mengintegrasikan layanan penyelesaian CAPTCHA khusus seperti CapSolver.
Q: Mengapa saya harus menggunakan CapSolver dengan Node Unblocker?
A: Anda harus menggunakan CapSolver dengan Node Unblocker untuk menciptakan solusi web scraping di Node.js yang komprehensif. Node Unblocker menangani penyembunyian IP dan penipuan dasar, sementara CapSolver menyediakan kemampuan penting untuk secara otomatis menyelesaikan CAPTCHA, yang merupakan penghalang umum bagi scraper otomatis di situs web yang dilindungi.
Q: Apakah ada alternatif untuk Node Unblocker dalam pengelolaan proxy?
A: Ya, ada beberapa alternatif untuk pengelolaan proxy dalam web scraping di Node.js, termasuk skrip rotasi proxy kustom, layanan proxy komersial, atau perpustakaan open-source lainnya. Namun, Node Unblocker menawarkan pendekatan middleware yang nyaman untuk aplikasi Express.js.
Q: Apa pertimbangan hukum untuk web scraping?
A: Pertimbangan hukum untuk web scraping di Node.js termasuk menghormati file robots.txt, mematuhi syarat dan ketentuan situs web, serta mematuhi regulasi perlindungan data seperti GDPR atau CCPA. Selalu pastikan aktivitas scraping Anda etis dan legal.
Lihat Lebih Banyak
AIMar 27, 2026
Meningkatkan Otomatisasi Perusahaan: Infrastruktur Berbasis LLM untuk Pengenalan CAPTCHA yang Mulus & Efisiensi Operasional
Ketahui bagaimana Infrastruktur Otomatisasi AI yang didukung LLM mengubah pengenalan CAPTCHA, meningkatkan efisiensi proses bisnis dan mengurangi intervensi manual. Optimalkan operasi otomatis Anda dengan solusi verifikasi canggih.

AIMar 27, 2026
Memperluas Pengumpulan Data untuk Pelatihan LLM: Menyelesaikan CAPTCHA Secara Skala
Pelajari cara meningkatkan pengumpulan data untuk pelatihan LLM dengan menyelesaikan CAPTCHA dalam jumlah besar. Temukan strategi otomatis untuk membangun dataset berkualitas tinggi untuk model AI.


