Python में डेटा एक्सट्रैक्शन के लिए reCAPTCHA v2 समाधानों को कैसे एकीकृत करें

Anh Tuan
Data Science Expert
परिचय
जैसे-जैसे इंटरनेट बढ़ता जा रहा है, वेब स्क्रैपिंग और डेटा एक्सट्रैक्शन व्यापक रूप से वेबसाइटों से विभिन्न उद्देश्यों के लिए जानकारी एकत्र करने के लिए उपयोग किए जाते हैं, जिसमें बिजनेस इंटेलिजेंस, कंटेंट एग्रीगेशन और मार्केट एनालिसिस शामिल हैं। हालांकि, जैसे-जैसे बॉट अधिक परिष्कृत होते गए, वेबसाइटों ने मानव उपयोगकर्ताओं और स्वचालित कार्यक्रमों के बीच अंतर करने के लिए उपकरण लागू किए। ऐसा ही एक उपकरण है reCAPTCHA। इस ब्लॉग में, हम यह पता लगाएंगे कि reCAPTCHA क्या है, विभिन्न संस्करण उपलब्ध हैं, और पायथॉन में Capsolver का उपयोग करके reCAPTCHA v2 चुनौतियों को कैसे हल करें। अंत में, हम आपके डेटा एक्सट्रैक्शन प्रोजेक्ट में reCAPTCHA v2 को एकीकृत करने के लिए एक सरल उदाहरण कोड के माध्यम से चलेंगे।
reCAPTCHA क्या है?

reCAPTCHA Google द्वारा विकसित एक मुफ्त सेवा है जो स्पैम और दुर्व्यवहार से वेबसाइटों की सुरक्षा में मदद करती है यह सुनिश्चित करके कि एक वास्तविक व्यक्ति (स्वचालित बॉट के बजाय) साइट के साथ बातचीत कर रहा है। जब उपयोगकर्ता reCAPTCHA को लागू करने वाली वेबसाइट पर जाते हैं, तो उन्हें यह सत्यापित करने के लिए एक चुनौती पूरी करनी पड़ सकती है कि वे मानव हैं।
reCAPTCHA के विभिन्न संस्करण
reCAPTCHA के कई संस्करण हैं, प्रत्येक के अपने स्वयं के फायदे और उपयोग के मामले हैं:
-
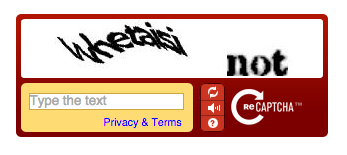
reCAPTCHA v1: सबसे पहला संस्करण, अब अप्रचलित। इसमें उपयोगकर्ताओं को छवियों से विकृत पाठ को ट्रांसक्राइब करने की आवश्यकता थी।
-
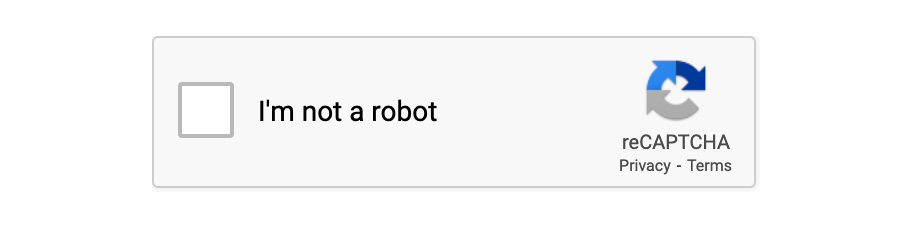
reCAPTCHA v2: एक अधिक उन्नत संस्करण जो उपयोगकर्ताओं को एक चेकबॉक्स ("मैं रोबोट नहीं हूं") के साथ प्रस्तुत करता है। यदि आवश्यक हो, तो यह उन्हें कुछ छवियों (जैसे ट्रैफिक लाइट या क्रॉसवॉक) का चयन करने के लिए भी चुनौती देता है। यह संस्करण आज सबसे अधिक उपयोग किया जाता है।
-
reCAPTCHA v3: यह संस्करण उपयोगकर्ता के व्यवहार और वेबसाइट के साथ बातचीत का विश्लेषण करता है ताकि 0 से 1 तक का स्कोर असाइन किया जा सके, जहां 0 एक बॉट को इंगित करता है और 1 एक मानव को इंगित करता है। यह उपयोगकर्ताओं के लिए अधिक सहज है क्योंकि इसके लिए इंटरैक्टिव चुनौतियों की आवश्यकता नहीं होती है।

-
अदृश्य reCAPTCHA: यह संस्करण पर्दे के पीछे काम करता है और केवल तभी चुनौतियां प्रस्तुत करता है जब संदिग्ध गतिविधि का पता चलता है। इसे वैध उपयोगकर्ताओं के लिए अदृश्य होने के लिए डिज़ाइन किया गया है।
डेटा एक्सट्रैक्शन क्या है?

डेटा एक्सट्रैक्शन असंरचित स्रोतों से संरचित डेटा प्राप्त करने की प्रक्रिया को संदर्भित करता है जैसे वेब पेज, डेटाबेस या अन्य डिजिटल प्रारूप। इसका उपयोग आमतौर पर वेब स्क्रैपिंग में किया जाता है, जहाँ स्वचालित कार्यक्रम विश्लेषण या एकत्रीकरण के लिए वेबसाइटों से बड़ी मात्रा में जानकारी एकत्र करते हैं।
डेटा एक्सट्रैक्शन के सामान्य उपयोग के मामले
-
मार्केट रिसर्च: कंपनियां अपनी मार्केटिंग और सेल्स रणनीतियों को समायोजित करने के लिए प्रतिस्पर्धी मूल्य निर्धारण डेटा और ग्राहक समीक्षाओं का निष्कर्षण करती हैं।
-
बिजनेस इंटेलिजेंस: संगठन सूचित व्यावसायिक निर्णय लेने के लिए वित्तीय रिपोर्ट, समाचार और अन्य संसाधनों को खुरचते हैं।
-
कंटेंट एग्रीगेशन: वेबसाइटें जो कई स्रोतों से जानकारी को क्यूरेट और प्रदर्शित करती हैं, अक्सर अन्य वेब पेजों से डेटा निकालती हैं।
-
SEO विश्लेषण: प्रतिस्पर्धी वेबसाइटों से सामग्री, कीवर्ड और मेटा टैग निकालने से SEO रणनीतियों को अनुकूलित करने में मदद मिलती है।
पायथॉन में reCAPTCHA v2 समाधान को एकीकृत करना
जब वेबसाइटों से डेटा निकालते हैं, तो आप reCAPTCHA चुनौतियों का सामना कर सकते हैं। यह स्वचालित स्क्रैपिंग के लिए एक बाधा उत्पन्न करता है। सौभाग्य से, Capsolver जैसे उपकरण reCAPTCHA v2 चुनौतियों को प्रोग्रामेटिक रूप से हल कर सकते हैं, जिससे आप अपने डेटा एक्सट्रैक्शन कार्यों को जारी रख सकते हैं।
यहां reCAPTCHA v2 को Capsolver पैकेज का उपयोग करके हल करने के लिए एक पायथॉन कार्यान्वयन दिया गया है।
कदम:
-
चलकर
capsolverलाइब्रेरी को इंस्टॉल करें:bashpip install capsolver -
reCAPTCHA v2 चुनौती को हल करने के लिए निम्न पायथॉन कोड का उपयोग करें:
python
import capsolver
# संवेदनशील जानकारी के लिए पर्यावरण चर का उपयोग करने पर विचार करें
capsolver.api_key = "आपकी Capsolver API कुंजी"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": url,
"websiteKey":key,
})
return solution
def main():
print("reCaptcha v2 को हल कर रहा है")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("समाधान: ", solution)
if __name__ == "__main__":
main()कोड की व्याख्या
-
Capsolver API सेटअप: कोड में, हम
capsolver.api_keyको परिभाषित करते हैं जिसमें आपकी Capsolver API कुंजी होनी चाहिए। यह कुंजी Capsolver सेवा के लिए आपके अनुरोधों को प्रमाणित करेगी। -
समाधान फ़ंक्शन: फ़ंक्शन
solve_recaptcha_v2पृष्ठ काurlऔरsite_key(जो वेबसाइट पर मौजूद reCAPTCHA कुंजी है) स्वीकार करता है। यह reCAPTCHA चुनौती को हल करने के लिए Capsolver को एक अनुरोध भेजता है। -
मुख्य फ़ंक्शन: मुख्य फ़ंक्शन सॉल्वर को चलाता है और समाधान प्रिंट करता है।
-
पर्यावरण चर: बेहतर सुरक्षा के लिए API कुंजी जैसी संवेदनशील जानकारी को संग्रहीत करने के लिए पर्यावरण चर का उपयोग करने की अनुशंसा की जाती है। उपरोक्त उदाहरण में, आपको
आपकी Capsolver API कुंजी,PAGE_URL, औरPAGE_SITE_KEYको अपने वास्तविक मानों से बदलना चाहिए।
बोनस कोड
शीर्ष कैप्चा समाधानों के लिए अपने बोनस कोड का दावा करें; CapSolver: scrape. इसे रिडीम करने के बाद, आपको प्रत्येक रिचार्ज के बाद अतिरिक्त 5% बोनस मिलेगा, असीमित

अधिक जानकारी के लिए, यह ब्लॉग पढ़ें
निष्कर्ष
reCAPTCHA बॉट से वेबसाइटों की सुरक्षा के लिए एक अनिवार्य उपकरण है, लेकिन यह डेटा एक्सट्रैक्शन जैसे वैध स्वचालन उद्देश्यों के लिए चुनौतियां पैदा कर सकता है। Capsolver जैसे टूल का उपयोग करने से डेवलपर्स reCAPTCHA v2 चुनौतियों को प्रोग्रामेटिक रूप से हल कर सकते हैं, जिससे निर्बाध डेटा एक्सट्रैक्शन सक्षम हो जाता है। हमेशा सुनिश्चित करें कि आपके डेटा एक्सट्रैक्शन गतिविधियाँ किसी भी समस्या से बचने के लिए वेबसाइट की सेवा की शर्तों और कानूनी दिशानिर्देशों का पालन करती हैं।
उपरोक्त दिए गए समाधान को अपने पायथॉन प्रोजेक्ट में एकीकृत करके, आप reCAPTCHA बाधाओं को पार करते हुए वेबसाइटों से मूल्यवान डेटा एकत्र करना जारी रख सकते हैं।