पुपेटीयर को बॉट के रूप में पहचाना गया? इसे कैसे ठीक करें

Rajinder Singh
Deep Learning Researcher
TL;DR
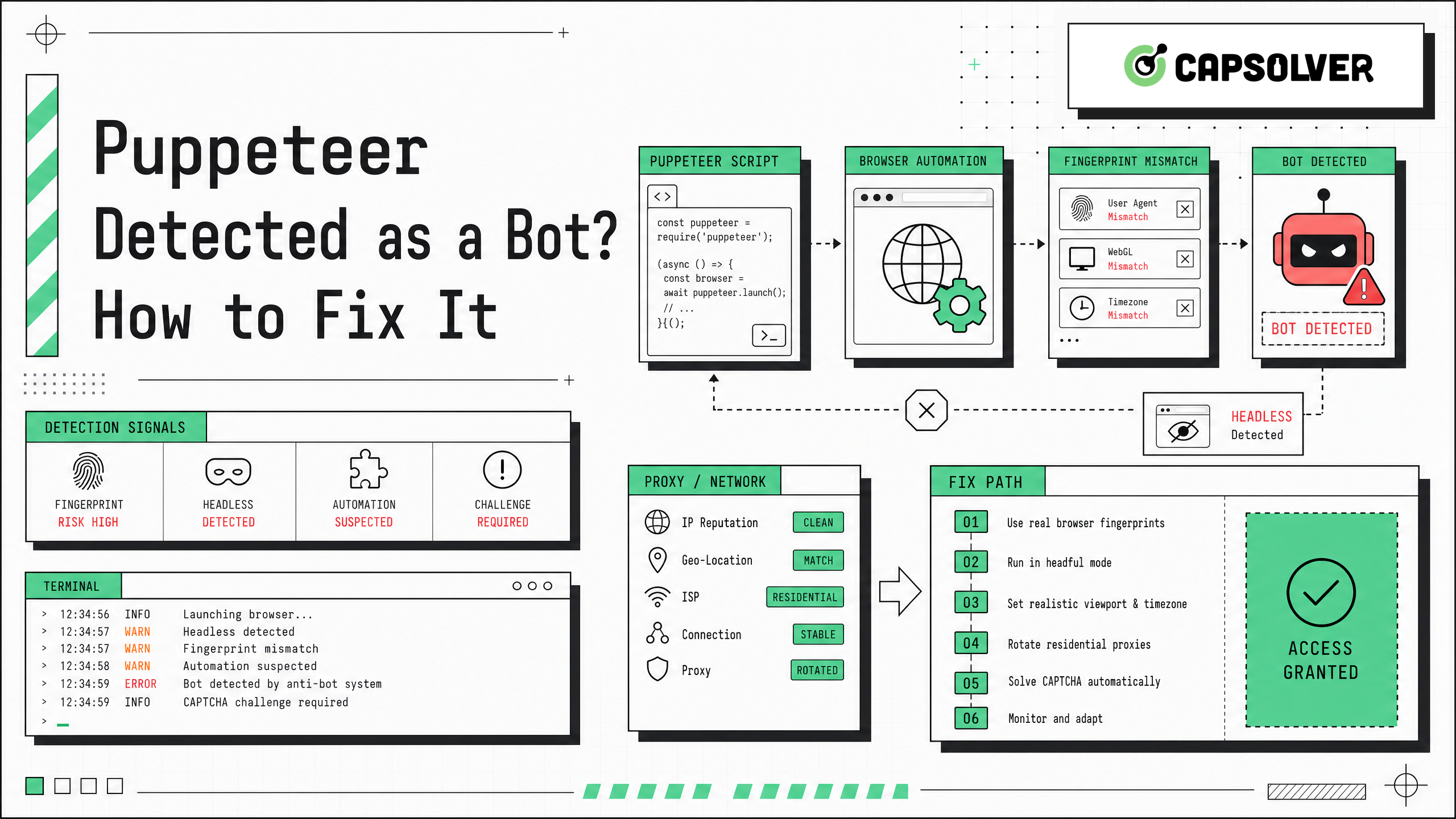
- पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान ब्लॉकर के प्रकार की पहचान करने से शुरू होता है, जैसे ब्राउज़र फिंगरप्रिंटिंग, नेटवर्क प्रतिष्ठा, सत्र बदलाव, क्रिया समय, या CAPTCHA चुनौती।
- पुप्पेटीयर क्रोम या फायरफॉक्स को क्रोम डेवटूल्स प्रोटोकॉल या ड्राइवर बाइडी के माध्यम से नियंत्रित करता है और डिफ़ॉल्ट रूप से हेडलेस चलता है, जो कुछ साइटों द्वारा सत्र के वर्गीकरण पर प्रभाव डाल सकता है।
- पहचान के लक्षण में 403 पृष्ठ, CAPTCHA लूप, लॉगिन विफलता, खाली खोज परिणाम, देरी से पुनर्निर्देशन और हस्तचालित ब्राउजिंग के विपरीत रेंडरिंग वाले पृष्ठ शामिल हैं।
- जिम्मेदार समाधान में स्थायी प्रोफ़ाइल, स्थिर प्रॉक्सी रूटिंग, वास्तविक गति, वातावरण समानता, स्पष्ट लॉग्स, और अनुमत कार्यवाही के लिए दस्तावेज़ी CAPTCHA निपटान शामिल हैं।
- अनुमत उपयोग मामलों में, CAPTCHA-भारित पुप्पेटीयर स्वचालन के लिए CapSolver सहायता कर सकता है।
परिचय
पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान एक सामान्य प्रश्न है क्योंकि कई स्वचालन परियोजनाएं एक कार्य करने वाले स्थानीय स्क्रिप्ट के साथ शुरू होती हैं और फिर वास्तविक वेबसाइट पर विफल हो जाती हैं। समस्या आमतौर पर एक सेटिंग नहीं होती है। वेबसाइटें आमतौर पर ब्राउज़र के गुण, अनुरोध इतिहास, खाता विश्वास, आईपी प्रतिष्ठा, जावास्क्रिप्ट व्यवहार और चुनौती परिणामों के एक साथ मूल्यांकन करती हैं। पुप्पेटीयर की स्वयं की डॉक्यूमेंटेशन इसे एक जावास्क्रिप्ट प per लाइब्रेरी के रूप में वर्णित करती है जो क्रोम डेवटूल्स प्रोटोकॉल या ड्राइवर बाइडी के माध्यम से क्रोम या फायरफॉक्स को नियंत्रित करने के लिए एक उच्च-स्तरीय एपीआई प्रदान करती है, और यह डिफ़ॉल्ट रूप से पुप्पेटीयर की आधिकारिक डॉक्यूमेंटेशन के माध्यम से हेडलेस चलता है। CAPTCHA-भारित कार्यवाही के लिए, CapSolver समर्थित चुनौतियों के साथ सहायता कर सकता है, लेकिन व्यापक समाधान एक स्वच्छ स्वचालन प्रोफ़ाइल से शुरू होता है।
जब पुप्पेटीयर की पहचान होती है तो क्या अर्थ है
पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान यह नहीं है कि हर साइट पुप्पेटीयर के नाम से पहचानती है। आमतौर पर, यह सत्र को एक उच्च-जोखिम वर्ग में रखता है। इस वर्ग में CAPTCHA, एक नरम ब्लॉक, HTTP 403 प्रतिक्रिया, लॉगिन लूप, या एक पृष्ठ शामिल हो सकता है जो चुपके से डेटा छिपा देता है। दृश्य लक्षण केवल कई जांचों के अंतिम परिणाम है।
पुप्पेटीयर लोकप्रिय है क्योंकि यह विकासकर्ताओं को ब्राउज़र नेविगेशन, DOM अंतःक्रिया, स्क्रीनशॉट, पीडीएफ, और नेटवर्क गतिविधि पर सीधा नियंत्रण प्रदान करता है। इसके कारण इसका उपयोग क्वालिटी आश्वासन, मॉनिटरिंग, सामग्री परीक्षण और अनुमत डेटा कार्यवाही में किया जाता है। हालांकि, साफ ब्राउज़र प्रोफ़ाइल, तेज दोहराए गए कार्य, क्लाउड आईपी रेंज और अनुपस्थित सत्र लगातारता एक जीवंत उत्पादन प्रणाली के लिए असामान्य लग सकती है।
सही उत्तर एक यादृच्छिक लॉन्च फ्लैग बदलने के बजाय वातावरण की माप करना है। टीमें कार्यक्षेत्र में ब्राउज़िंग, स्थानीय पुप्पेटीयर, सीआई/सीडी पुप्पेटीयर और उत्पादन बुनियादी ढांचे की तुलना करनी चाहिए। जब इन वातावरण अलग होते हैं, तो डिटेक्शन संकेत आमतौर पर स्पष्ट हो जाता है।
पुप्पेटीयर के चिह्नित होने के मुख्य कारण
पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान आमतौर पर यह है कि स्वचालन वातावरण एक सामान्य वापस आए ब्राउज़र की तरह नहीं दिखता है। पुप्पेटीयर के डिफ़ॉल्ट रूप से हेडलेस व्यवहार के साथ शुरू होता है, और बहुत से स्क्रिप्ट भी ताजा संदर्भ, दोहराए गए नेविगेशन पथ और उच्च-गति क्रियाएं उपयोग करते हैं। एक जोखिम नियंत्रण के लिए तैयार साइट इस पैटर्न को चुनौती दे सकती है।
| संकेत समूह | व्यापक लक्षण | सुधार दिशा |
|---|---|---|
| ब्राउज़र मोड | हाथ से काम करता है लेकिन हेडलेस निष्पादन में विफल रहता है | हेडेड और हेडलेस ट्रेस की तुलना करें, व्यूपोर्ट, भाषा, समय क्षेत्र और अनुमति के साथ समायोजित करें |
| सत्र स्थिति | प्रत्येक चलाना एक नए दर्शक की तरह दिखता है | परीक्षण खातों और अनुमत कार्यवाही के लिए अनुमत कुकीज़ और स्टोरेज स्थिति को स्थायी बनाएं |
| नेटवर्क प्रतिष्ठा | केवल सीआई या कुछ प्रॉक्सी पूल में ब्लॉक दिखाई देते हैं | स्थिर रूटिंग का उपयोग करें, अत्यधिक घूर्णन से बचें और ब्राउज़र से बाहर आउटबाउंड पहचान की पुष्टि करें |
| अंतःक्रिया पैटर्न | फॉर्म तुरंत सबमिट करता है या नेविगेशन बहुत रैखिक है | उपयोगकर्ता-दृश्य सिद्धता की प्रतीक्षा करें और पृष्ठ प्रवाह के आधार पर क्रियाओं की गति निर्धारित करें |
| चुनौती निपटान | CAPTCHA दिखाई देता है लेकिन स्क्रिप्ट अपेक्षित पृष्ठ स्थिति पूरा नहीं कर सकती | चुनौती प्रकार की पहचान करें और केवल दस्तावेज़ी, अनुमत सॉल्वर कार्यवाही के साथ एम्बेड करें |
पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान विशेष रूप से बड़े पैमाने पर स्क्रिप्ट के लिए महत्वपूर्ण है। एक स्थानीय परीक्षण एक आईपी और एक खाता का उपयोग कर सकता है। एक उत्पादन कार्य बहुत सारे ब्राउज़र संदर्भ, समानांतर कार्यकर्ता और छोटे जीवनकाल के सत्र का उपयोग कर सकता है। इस बदलाव एक ही समय में अधिक सख्त ट्रैफिक जांच को ट्रिगर कर सकता है।
पहले जांचने वाले ब्राउज़र स्वचालन संकेत
एक ब्राउज़र सत्र में उपयोगकर्ता एजेंट स्ट्रिंग के बाहर कई संकेत होते हैं। साइटें व्यूपोर्ट, डिवाइस स्केल फैक्टर, भाषा पसंद, समय क्षेत्र, WebGL व्यवहार, अनुमति प्रॉम्प्ट, स्टोरेज उपलब्धता, मीडिया डिवाइस, फॉन्ट और नेविगेशन समय की जांच कर सकती हैं। असमान संयोजन यहां तक कि जब प्रत्येक अकेला मूल्य अहितकर लगता है, तो भी संदेह पैदा कर सकते हैं।
क्रोम डेवटूल्स प्रोटोकॉल महत्वपूर्ण है क्योंकि पुप्पेटीयर ब्राउज़र डीबगिंग और स्वचालन चैनलों के माध्यम से क्रोम को नियंत्रित कर सकता है। आधिकारिक CDP डॉक्यूमेंटेशन बताता है कि प्रोटोकॉल टूल्स के लिए उपकरण, जांच, डीबगिंग और प्रोफाइलिंग के लिए अनुमति देता है, और यह ब्राउज़र लक्ष्य, वेबसॉकेट डीबगर यूआरएल और प्रोटोकॉल मेटाडेटा क्रोम डेवटूल्स प्रोटोकॉल डॉक्यूमेंटेशन के बारे में वर्णन करता है। विकासकर्ताओं को इस वास्तुविज्ञान की समझ होनी चाहिए क्योंकि डीबगिंग एंडपॉइंट, ब्राउज़र फ्लैग्स और सत्र सेटअप के आउटपुट के बारे में जानकारी के कारण एक पृष्ठ द्वारा देखा जा सकता है।
पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान विफल पृष्ठ के ट्रेस से शुरू होना चाहिए। ठीक उत्तर कोड, स्क्रीनशॉट, अंतिम यूआरएल, कंसोल त्रुटियां, समय और चुनौती पृष्ठ की रिकॉर्डिंग करें। यदि ब्लॉक जावास्क्रिप्ट के कोई कार्य शुरू होने से पहले होता है, तो नेटवर्क या प्रारंभिक फिंगरप्रिंट संकेत संभावित हैं। यदि यह फॉर्म सबमिशन के बाद होता है, तो अंतःक्रिया व्यवहार या खाता विश्वास ट्रिगर का कारण बन सकता है।
उन्नत सेटिंग बदलने से पहले सत्र लगातारता की जांच करें
सत्र लगातारता एक अत्यधिक उपेक्षित समाधान है। एक स्क्रिप्ट जो हर कार्य के लिए एक नया ब्राउज़र प्रोफ़ाइल शुरू करता है, वह साइट को बताता है कि हर यात्रा एक पहली यात्रा है। एक परीक्षण खाते के लिए, यह असामान्य लग सकता है यदि एक शुद्ध उपकरण से घंटे में कई बार लॉगिन किया जाता है। एक मॉनिटर किए गए सार्वजनिक पृष्ठ के लिए, दोहराए गए नए दर्शक एक स्थिर प्रोफ़ाइल की तुलना में जल्दी चुनौति प्रणालियों को ट्रिगर कर सकते हैं।
एक बेहतर पैटर्न विनियमन के अनुमति के अनुसार अनुमत कुकीज़ और स्टोरेज स्थिति को स्थायी बनाना है। मालिकता वाली संपत्ति के लिए, विशेष परीक्षण खाते और स्टेजिंग परिवेश बनाएं। सार्वजनिक साइटों के लिए, शर्तों के अनुसार, रोबोट्स दिशानिर्देशों और स्थानीय कानून का पालन करें। CapSolver के [वेब स्क्रैपिंग एफ़क्यूए] (https://www.capsolver.com/faq/web-scraping) और [वेब स्क्रैपिंग कानूनी गाइड] (https://www.capsolver.com/blog/All/web-scraping-legal) उपयोगी संदर्भ हैं क्योंकि कानूनी एक्सेस और तकनीकी एक्सेस एक ही बात नहीं हैं।
पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान खाता-स्तरीय सोच के साथ भी होता है। यदि एक ही खाता कई आईपी, उपकरण और क्षेत्रों से दिखाई देता है, तो खाता समस्या बन सकता है। अपने खाते को एक तार्किक भूगोल और सत्र पैटर्न से जोड़ें। यह एक विश्वसनीयता अभ्यास है, केवल एक डिटेक्शन अभ्यास नहीं।
नेटवर्क और प्रॉक्सी कॉन्फ़िगरेशन निर्णय कर सकता है
बहुत सारे पुप्पेटीयर समस्या नेटवर्क समस्या हैं। क्लाउड डेटा सेंटर आईपी, अत्यधिक भारित प्रॉक्सी, क्षेत्र असंगतता, विफल प्राधिकरण और तेज़ आईपी घूर्णन ब्राउज़र डिटेक्शन के समान लक्षण पैदा कर सकते हैं। एक साइट ट्रैफिक प्रतिष्ठा के कारण CAPTCHA या 403 पृष्ठ दिखा सकती है जब तक कि वह विस्तृत ब्राउज़र व्यवहार का मूल्यांकन नहीं करती।
पुप्पेटीयर पृष्ठ से बाहर आउटबाउंड आईपी की जांच करें। क्षेत्र, एएसएन, डीएनएस व्यवहार की पुष्टि करें और देखें कि क्या प्रॉक्सी सत्र के दौरान बदल जाता है। यदि स्क्रिप्ट एक रास्ता से लॉगिन करता है और एक फॉर्म को दूसरे रास्ते से जमा करता है, तो सत्र चुनौती दे सकता है। CapSolver के [प्रॉक्सी सेटअप] (https://www.capsolver.com/faq/proxies-and-infrastructure) संसाधन तब अहम होता है जब अनुमान कार्यवाही प्रॉक्सी, ब्राउज़र और CAPTCHA निपटान के साथ जुड़े होते हैं।
पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान अक्सर टीमों द्वारा संक्रमण कम करके सुधार होता है। एक कार्यकर्ता, एक खाता, एक प्रोफ़ाइल और एक स्थिर रास्ता के साथ शुरू करें। जब फ्लो विश्वसनीय हो जाता है, तो धीरे-धीरे आवेदन बढ़ाएं और देखें कि चुनौतियां कहां वापस आती हैं। इससे जोखिम संकेत दृश्य हो जाते हैं, न कि अज्ञात।
पुप्पेटीयर कार्यवाही में CAPTCHA निपटान
CAPTCHA आमतौर पर एक चेकपॉइंट होता है, न कि मूल कारण। यदि एक साइट तुरंत CAPTCHA प्रस्तुत करती है, तो नेटवर्क प्रतिष्ठा और ब्राउज़र संदर्भ की समीक्षा करें। यदि यह दोहराए गए खोजों के बाद दिखाई देता है, तो दर और गति की समीक्षा करें। यदि यह खाता बनाने या खरीदारी के दौरान दिखाई देता है, तो यह अपेक्षित जोखिम-नियंत्रण पथ का हिस्सा हो सकता है। CapSolver के [CAPTCHA समाधान एफ़क्यूए] (https://www.capsolver.com/faq/captcha-solving) के लिए एक सामान्य आधार दिया गया है।
जब एक अनुमत पुप्पेटीयर कार्यवाही को CAPTCHA निपटान की आवश्यकता होती है, तो कोड लिखने से पहले चुनौती प्रकार की पहचान करें। कुछ कार्यों में reCAPTCHA होता है, कुछ छवि CAPTCHA होता है, और कुछ Cloudflare Turnstile या अन्य ट्रैफिक वैधता प्रणालियों का उपयोग करता है। CapSolver के पुप्पेटीयर-संबंधित संसाधन जैसे [पुप्पेटीयर एकीकरण] (https://www.capsolver.com/blog/All/how-to-integrate-puppeteer), [पुप्पेटीयर में CAPTCHA निपटान] (https://www.capsolver.com/blog/Extension/how-to-solve-captcha-in-puppeteer-using-capsolver), और [CAPTCHA पैरामीटर पहचान] (https://www.capsolver.com/blog/Extension/identify-any-captcha-and-parameters) हैं।
CapSolver बोनस कोड का उपयोग करें
अपने स्वचालन बजट को तुरंत बढ़ाएं!
CapSolver खाता में रीचार्ज करते समय बोनस कोड CAP26 का उपयोग करके प्रत्येक रीचार्ज पर 5% बोनस प्राप्त करें — कोई सीमा नहीं।
अपने [CapSolver डैशबोर्ड] (https://dashboard.capsolver.com/dashboard/overview/?utm_source=offcial&utm_medium=blog&utm_campaign=puppeteer-detected-as-a-bot-how-to-fix-it) में अब इसे एक्सपोज़ करें
एक सॉल्वर को अच्छे स्वचालन हाइजीन के बजाय एक प्रतिस्थापन के रूप में न लें। सही कार्यवाही के पालन की आवश्यकता है, उचित ट्रैफिक, स्थिर सत्र और स्पष्ट निरीक्षण। CAPTCHA निपटान केवल एक व्यापक संगत प्रणाली में एक संकीर्ण एकीकरण चरण होना चाहिए।
पुप्पेटीयर के लिए जिम्मेदार समाधान सूची
पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान एक दोहराए जा सकने वाले सूची के साथ हो सकता है। पहला, एक ही मशीन और नेटवर्क से हाथ से परीक्षण करें। दूसरा, पुप्पेटीयर को हेडेड मोड में चलाएं और स्क्रीनशॉट की तुलना करें। तीसरा, व्यूपोर्ट, भाषा, समय क्षेत्र, अनुमति और ब्राउज़र संस्करण के साथ समायोजित करें। चौथा, अनुमत सत्र स्थिति को स्थायी बनाएं। पांचवां, संक्रमण कम करें और पृष्ठ तैयारी के अनुसार क्रियाओं की गति निर्धारित करें। छठा, ब्राउज़र से बाहर आउटबाउंड प्रॉक्सी और डीएनएस व्यवहार की पुष्टि करें। सातवां, जब चुनौती अपेक्षित और समर्थित होती है, तो केवल CAPTCHA निपटान जोड़ें।
क्रोम की कॉन्फ़िगरेशन प्रोफ़ाइल का हिस्सा भी है। क्रोमड्राइवर के कैपेबिलिटीज़ डॉक्यूमेंटेशन दर्शाता है कि ब्राउज़र सत्र को कस्टम प्रोफ़ाइल, प्रॉक्सी कैपेबिलिटी, एक्सटेंशन, मोबाइल एमुलेशन, विंडो आकार और क्रोम-विशिष्ट विकल्पों के साथ कॉन्फ़िगर किया जा सकता है क्रोमड्राइवर कैपेबिलिटीज़ डॉक्यूमेंटेशन। पुप्पेटीयर के अलग एपीआई हैं, लेकिन सिद्धांत एक ही है: ब्राउज़र लॉन्च कॉन्फ़िगरेशन कार्यवाही के साथ मेल खाना चाहिए, न कि एक सामान्य डिफ़ॉल्ट।
अंत में, एक एकल-शॉट समाधान जो स्पष्ट नहीं होता है, उसे बचें। यदि कार्यवाही केवल अनुमत फ्लैग्स के एक संग्रह के बाद ही बचती है, तो इसे बनाए रखना कठिन होगा। एक बेहतर पुप्पेटीयर प्रणाली हर चयन को स्पष्ट बनाती है: क्यों इस प्रोफ़ाइल, क्यों इस प्रॉक्सी रास्ता, क्यों इस प्रतीक्षा स्थिति, क्यों इस CAPTCHA फ्लो, और क्यों इस दर सीमा।
निष्कर्ष
पुप्पेटीयर को बॉट के रूप में कैसे पहचाना जाता है? इसका समाधान एक पूर्ण-स्टैक स्वचालन समस्या के रूप में होता है। पुप्पेटीयर वास्तविक ब्राउज़र इंजन को नियंत्रित करता है, लेकिन डिटेक्शन ब्राउज़र स्थिति, नेटवर्क प्रतिष्ठा, सत्र इतिहास, गति, खाता व्यवहार, या चुनौती निपटान से आ सकता है। सबसे पहले साक्ष्य के साथ शुरू करें, ब्राउज़र प्रोफ़ाइल स्थिर करें, सत्र स्थिर रखें, उचित ट्रैफिक पैटर्न का उपयोग करें, और कानूनी और साइट नियमों का सम्मान करें। जब CAPTCHA चुनौती अनुमत कार्यवाही के हिस्सा होती है, तो CapSolver टीमों की मदद कर सकता है जो पुप्पेटीयर के साथ दस्तावेज़ी चुनौती निपटान के साथ एक विश्वसनीय और बनाए रखने योग्य प्रणाली बनाए रखते हैं।
एफ़क्यूए
पुप्पेटीयर को बॉट के रूप में क्यों पहचाना जाता है जब क्रोम स्थापित होता है?
क्रोम स्थापित करना पर्याप्त नहीं है। साइट ब्राउज़र मोड, प्रोफ़ाइल इतिहास, कुकीज़, नेटवर्क प्रतिष्ठा, समय और खाता व्यवहार का मूल्यांकन कर सकती है। पुप्पेटीयर अगर पर्यावरण हर बार ताजा शुरू होता है या बहुत तेजी से काम करता है, तो अभी भी असामान्य लग सकता है।
क्या मैं हेडलेस पुप्पेटीयर से हेडेड पुप्पेटीयर में बदल दूं?
हेडेड मोड डीबगिंग और तुलना के लिए उपयोगी है, लेकिन यह पूर्ण समाधान नहीं है। यदि हेडेड मोड में भी डिटेक्शन जारी रहता है, तो सत्र लगातारता, प्रॉक्सी प्रतिष्ठा, क्षेत्र सामान्यता और क्रिया समय की जांच करें।
क्या CapSolver पुप्पेटीयर डिटेक्शन को ठीक कर सकता है?
CapSolver कानूनी और अनुमत कार्यवाही में समर्थित CAPTCHA चुनौतियों के साथ मदद कर सकता है। यह हर डिटेक्शन कारण को ठीक नहीं करता। ब्राउज़र सेटअप, प्रॉक्सी, खाते, गति और सुसंगतता को अभी भी सही ढंग से निपटाना आवश्यक है।
पुप्पेटीयर ब्लॉक हो गया है तो पहला चीज क्या जांचनी चाहिए?
ब्लॉक कहां होता है उसकी जांच करें। यदि पहले अनुरोध पर दिखाई देता है, तो नेटवर्क और ब्राउज़र फिंगरप्रिंट संकेतों की जांच करें। यदि कई क्रियाओं के बाद दिखाई देता है, तो समय, खाता स्थिति और आवेदन की जांच करें। यदि CAPTCHA पृष्ठ पर दिखाई देता है, तो चुनौती प्रकार की पहचान करें।
क्या पुप्पेटीयर वेब स्वचालन के लिए अनुमत है?
पुप्पेटीयर एक वैध ब्राउज़र स्वचालन प per लाइब्रेरी है। इसका उपयोग परीक्षण, मॉनिटरिंग और अनुमत स्वचालन के लिए करें। निजी, सीमित, संवेदनशील या अनुमत डेटा के लिए इसका उपयोग न करें।
और देखें
AutomationJul 07, 2026
कैप्चा प्रबंधन कानूनी प्रौद्योगिकी अदालत फाइलिंग स्वचालन
लीगलटेक के लिए अदालत दस्तावेज़ स्वचालन में CAPTCHA के निपटान में सुधार करें: ई-फ़ाइलिंग को सुगम बनाने वाले संगत कार्य प्रक्रियाएं और साधन, त्रुटियों को कम करें और दस्तावेज़ प्रस्तुति को तेज करें।
AutomationJul 07, 2026
कैसे CAPTCHA को ई-कॉमर्स इंवेंटरी ट्रैकिंग प्रणालियों में हल करें
ई-कॉमर्स भंडार ट्रैकिंग में कैप्चा हल करने के तरीके सीखें व्यावहारिक विधियों, स्वचालन टिप्स और सुसंगति के साथ भंडार डेटा को सटीक और स्केलेबल रखें।