SeleniumBase और Python के साथ 2024 में वेब स्क्रैपिंग

Emma Foster
Machine Learning Engineer

वेब स्क्रैपिंग डेटा एक्सट्रैक्शन, मार्केट रिसर्च और ऑटोमेशन के लिए एक शक्तिशाली उपकरण है। हालाँकि, CAPTCHAs स्वचालित स्क्रैपिंग प्रयासों में बाधा डाल सकते हैं। इस गाइड में, हम जानेंगे कि वेब स्क्रैपिंग के लिए SeleniumBase का उपयोग कैसे करें और CapSolver को कुशलतापूर्वक CAPTCHAs को हल करने के लिए एकीकृत करें, हमारे उदाहरण वेबसाइट quotes.toscrape.com का उपयोग करके।
SeleniumBase का परिचय
SeleniumBase एक Python फ़्रेमवर्क है जो वेब ऑटोमेशन और परीक्षण को सरल करता है। यह Selenium WebDriver की क्षमताओं को अधिक उपयोगकर्ता के अनुकूल API, उन्नत चयनकर्ता, स्वचालित प्रतीक्षा और अतिरिक्त परीक्षण उपकरणों के साथ बढ़ाता है।
SeleniumBase स्थापित करना
शुरू करने से पहले, सुनिश्चित करें कि आपके सिस्टम पर Python 3 स्थापित है। SeleniumBase सेट करने के लिए इन चरणों का पालन करें:
-
SeleniumBase स्थापित करें:
bashpip install seleniumbase -
स्थापना सत्यापित करें:
bashsbase --help
SeleniumBase के साथ बेसिक स्क्रैपर
आइए एक सरल स्क्रिप्ट बनाकर शुरू करते हैं जो quotes.toscrape.com पर नेविगेट करता है और उद्धरण और लेखक निकालता है।
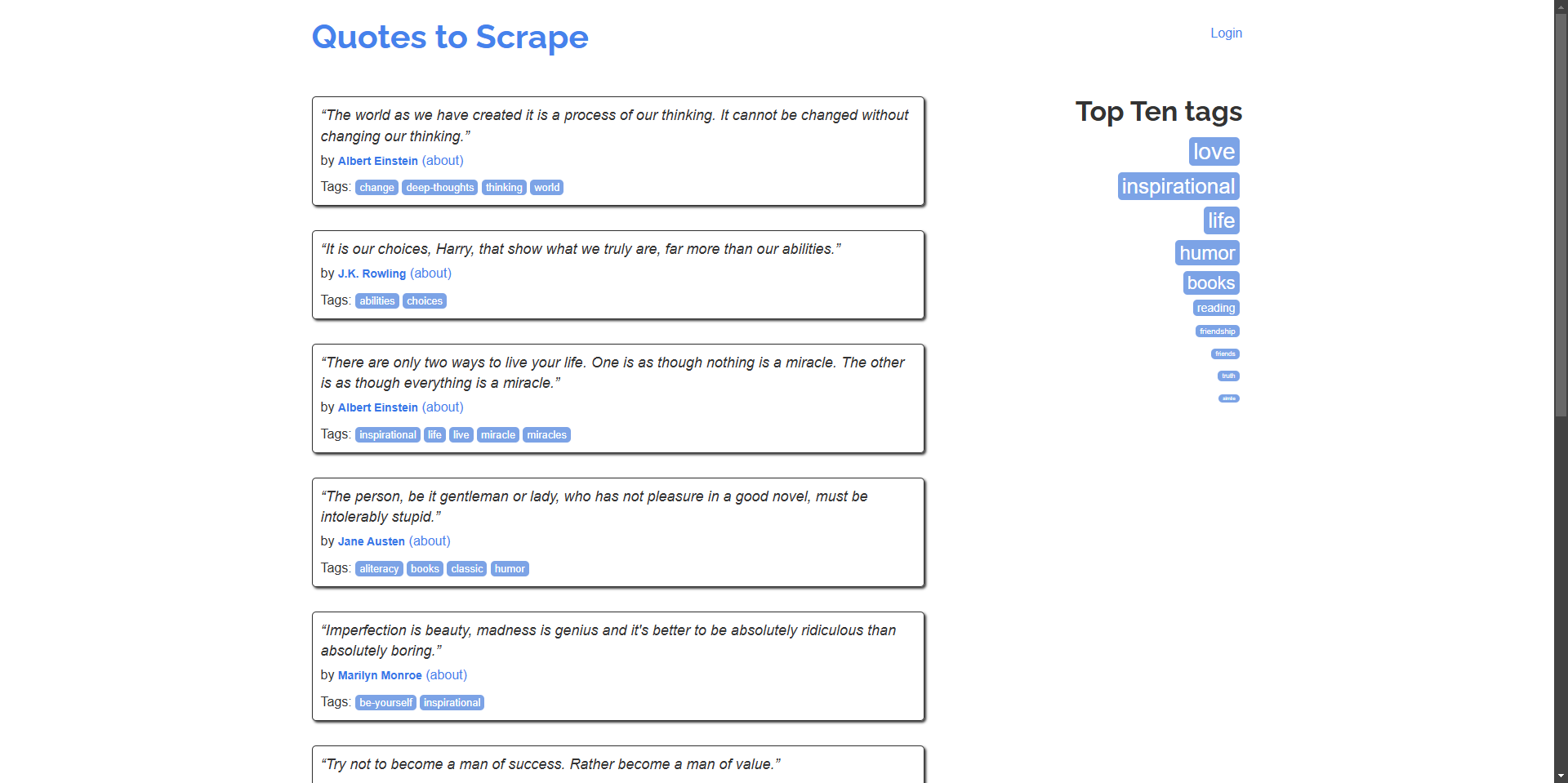
उदाहरण: होमपेज से उद्धरण और उनके लेखक स्क्रैप करें।
python
# scrape_quotes.py
from seleniumbase import BaseCase
class QuotesScraper(BaseCase):
def test_scrape_quotes(self):
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
if __name__ == "__main__":
QuotesScraper().main()स्क्रिप्ट चलाएँ:
bash
python scrape_quotes.pyआउटपुट:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” - Albert Einstein
...अधिक उन्नत वेब स्क्रैपिंग उदाहरण
अपने वेब स्क्रैपिंग कौशल को बढ़ाने के लिए, आइए SeleniumBase का उपयोग करके अधिक उन्नत उदाहरणों का पता लगाएं।
कई पृष्ठ (पृष्ठांकन) स्क्रैपिंग
कई वेबसाइटें कई पृष्ठों पर सामग्री प्रदर्शित करती हैं। आइए सभी पृष्ठों के माध्यम से नेविगेट करने और उद्धरण स्क्रैप करने के लिए अपनी स्क्रिप्ट को संशोधित करें।
python
# scrape_quotes_pagination.py
from seleniumbase import BaseCase
class QuotesPaginationScraper(BaseCase):
def test_scrape_all_quotes(self):
self.open("https://quotes.toscrape.com/")
while True:
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
# जांचें कि क्या कोई अगला पृष्ठ है
if self.is_element_visible('li.next > a'):
self.click('li.next > a')
else:
break
if __name__ == "__main__":
QuotesPaginationScraper().main()व्याख्या:
- हम "अगला" बटन उपलब्ध है या नहीं, इसकी जाँच करके पृष्ठों के माध्यम से लूप करते हैं।
- "अगला" बटन के लिए हम
is_element_visibleका उपयोग करते हैं। - हम अगले पृष्ठ पर नेविगेट करने के लिए "अगला" बटन पर क्लिक करते हैं।
AJAX के साथ गतिशील सामग्री को संभालना
कुछ वेबसाइटें AJAX का उपयोग करके गतिशील रूप से सामग्री लोड करती हैं। SeleniumBase तत्वों को लोड होने की प्रतीक्षा करके ऐसे परिदृश्यों को संभाल सकता है।
उदाहरण: वेबसाइट से टैग स्क्रैप करें, जो गतिशील रूप से लोड होते हैं।
python
# scrape_dynamic_content.py
from seleniumbase import BaseCase
class TagsScraper(BaseCase):
def test_scrape_tags(self):
self.open("https://quotes.toscrape.com/")
# टैग को गतिशील रूप से लोड करने के लिए 'शीर्ष दस टैग' लिंक पर क्लिक करें
self.click('a[href="/tag/"]')
self.wait_for_element("div.tags-box")
tags = self.find_elements("span.tag-item > a")
for tag in tags:
tag_name = tag.text
print(f"Tag: {tag_name}")
if __name__ == "__main__":
TagsScraper().main()व्याख्या:
- हम
div.tags-boxतत्व के लिए प्रतीक्षा करते हैं ताकि यह सुनिश्चित हो सके कि गतिशील सामग्री लोड हो गई है। wait_for_elementयह सुनिश्चित करता है कि स्क्रिप्ट तब तक आगे न बढ़े जब तक कि तत्व उपलब्ध न हो जाए।
फॉर्म जमा करना और लॉग इन करना
कभी-कभी, आपको सामग्री स्क्रैप करने से पहले किसी वेबसाइट पर लॉग इन करने की आवश्यकता होती है। यहां बताया गया है कि आप फॉर्म सबमिशन को कैसे संभाल सकते हैं।
उदाहरण: वेबसाइट पर लॉग इन करें और प्रमाणित उपयोगकर्ता पृष्ठ से उद्धरण स्क्रैप करें।
python
# scrape_with_login.py
from seleniumbase import BaseCase
class LoginScraper(BaseCase):
def test_login_and_scrape(self):
self.open("https://quotes.toscrape.com/login")
# लॉग इन फॉर्म भरें
self.type("input#username", "testuser")
self.type("input#password", "testpass")
self.click("input[type='submit']")
# लॉगआउट लिंक की जांच करके लॉग इन सत्यापित करें
if self.is_element_visible('a[href="/logout"]'):
print("Logged in successfully!")
# अब उद्धरण स्क्रैप करें
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
else:
print("Login failed.")
if __name__ == "__main__":
LoginScraper().main()व्याख्या:
- हम लॉग इन पेज पर नेविगेट करते हैं और क्रेडेंशियल भरते हैं।
- फॉर्म जमा करने के बाद, हम लॉगआउट लिंक की उपस्थिति की जाँच करके लॉग इन सत्यापित करते हैं।
- फिर हम लॉग इन उपयोगकर्ताओं के लिए उपलब्ध सामग्री को स्क्रैप करने के लिए आगे बढ़ते हैं।
नोट: चूँकि quotes.toscrape.com प्रदर्शन के लिए किसी भी उपयोगकर्ता नाम और पासवर्ड की अनुमति देता है, हम डमी क्रेडेंशियल का उपयोग कर सकते हैं।
तालिकाओं से डेटा निकालना
वेबसाइटें अक्सर तालिकाओं में डेटा प्रस्तुत करती हैं। यहां बताया गया है कि टेबल डेटा को कैसे निकाला जाए।
उदाहरण: एक तालिका से डेटा स्क्रैप करें (काल्पनिक उदाहरण के रूप में वेबसाइट में तालिकाएँ नहीं हैं)।
python
# scrape_table.py
from seleniumbase import BaseCase
class TableScraper(BaseCase):
def test_scrape_table(self):
self.open("https://www.example.com/table-page")
# तालिका लोड होने की प्रतीक्षा करें
self.wait_for_element("table#data-table")
rows = self.find_elements("table#data-table > tbody > tr")
for row in rows:
cells = row.find_elements("td")
row_data = [cell.text for cell in cells]
print(row_data)
if __name__ == "__main__":
TableScraper().main()व्याख्या:
- हम इसकी ID या क्लास द्वारा तालिका का पता लगाते हैं।
- हम प्रत्येक पंक्ति और फिर प्रत्येक सेल पर डेटा निकालने के लिए पुनरावृति करते हैं।
- चूँकि
quotes.toscrape.comमें तालिकाएँ नहीं हैं, इसलिए URL को एक वास्तविक वेबसाइट से बदलें जिसमें तालिका हो।
SeleniumBase में CapSolver को एकीकृत करना
जबकि quotes.toscrape.com में CAPTCHAs नहीं हैं, कई वास्तविक दुनिया की वेबसाइटें करती हैं। ऐसे मामलों के लिए तैयार होने के लिए, हम CapSolver ब्राउज़र एक्सटेंशन का उपयोग करके अपनी SeleniumBase स्क्रिप्ट में CapSolver को एकीकृत करना दिखाएंगे।
Capsolver का उपयोग करके SeleniumBase के साथ कैप्चा कैसे हल करें
-
CapSolver एक्सटेंशन डाउनलोड करें:
- CapSolver GitHub रिलीज़ पृष्ठ पर जाएँ।
- CapSolver ब्राउज़र एक्सटेंशन का नवीनतम संस्करण डाउनलोड करें।
- अपनी प्रोजेक्ट की रूट में एक निर्देशिका में एक्सटेंशन को अनज़िप करें, जैसे,
./capsolver_extension।
CapSolver एक्सटेंशन को कॉन्फ़िगर करना
-
कॉन्फ़िगरेशन फ़ाइल का पता लगाएँ:
capsolver_extension/assetsनिर्देशिका में स्थितconfig.jsonफ़ाइल खोजें।
-
कॉन्फ़िगरेशन अपडेट करें:
enabledForcaptchaऔर/याenabledForRecaptchaV2को आपके द्वारा हल किए जाने वाले CAPTCHA प्रकारों के आधार परtrueपर सेट करें।- स्वचालित रूप से हल करने के लिए
captchaModeयाreCaptchaV2Modeको"token"पर सेट करें।
उदाहरण
config.json:json{ "apiKey": "YOUR_CAPSOLVER_API_KEY", "enabledForcaptcha": true, "captchaMode": "token", "enabledForRecaptchaV2": true, "reCaptchaV2Mode": "token", "solveInvisibleRecaptcha": true, "verbose": false }"YOUR_CAPSOLVER_API_KEY"को अपनी वास्तविक CapSolver API कुंजी से बदलें।
SeleniumBase में CapSolver एक्सटेंशन लोड करना
SeleniumBase में CapSolver एक्सटेंशन का उपयोग करने के लिए, हमें ब्राउज़र को शुरू होने पर एक्सटेंशन को लोड करने के लिए कॉन्फ़िगर करने की आवश्यकता है।
-
अपनी SeleniumBase स्क्रिप्ट संशोधित करें:
selenium.webdriver.chrome.optionsसेChromeOptionsइम्पोर्ट करें।- CapSolver एक्सटेंशन को लोड करने के लिए विकल्प सेट करें।
उदाहरण:
pythonfrom seleniumbase import BaseCase from selenium.webdriver.chrome.options import Options as ChromeOptions import os class QuotesScraper(BaseCase): def setUp(self): super().setUp() # CapSolver एक्सटेंशन का पथ extension_path = os.path.abspath('capsolver_extension') # Chrome विकल्पों को कॉन्फ़िगर करें options = ChromeOptions() options.add_argument(f"--load-extension={extension_path}") options.add_argument("--disable-gpu") options.add_argument("--no-sandbox") # नए विकल्पों के साथ ड्राइवर को अपडेट करें self.driver.quit() self.driver = self.get_new_driver(browser_name="chrome", options=options) -
सुनिश्चित करें कि एक्सटेंशन पथ सही है:
- सुनिश्चित करें कि
extension_pathउस निर्देशिका को इंगित करता है जहाँ आपने CapSolver एक्सटेंशन को अनज़िप किया है।
- सुनिश्चित करें कि
CapSolver एकीकरण के साथ उदाहरण स्क्रिप्ट
यहां एक पूर्ण स्क्रिप्ट है जो स्वचालित रूप से CAPTCHAs को हल करने के लिए SeleniumBase में CapSolver को एकीकृत करती है। हम अपने उदाहरण साइट के रूप में https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php का उपयोग करना जारी रखेंगे।
python
# scrape_quotes_with_capsolver.py
from seleniumbase import BaseCase
from selenium.webdriver.chrome.options import Options as ChromeOptions
import os
class QuotesScraper(BaseCase):
def setUp(self):
super().setUp()
# CapSolver एक्सटेंशन फ़ोल्डर का पथ
# सुनिश्चित करें कि यह पथ CapSolver Chrome एक्सटेंशन फ़ोल्डर को सही ढंग से इंगित करता है
extension_path = os.path.abspath('capsolver_extension')
# Chrome विकल्पों को कॉन्फ़िगर करें
options = ChromeOptions()
options.add_argument(f"--load-extension={extension_path}")
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
# नए विकल्पों के साथ ड्राइवर को अपडेट करें
self.driver.quit() # किसी भी मौजूदा ड्राइवर इंस्टेंस को बंद करें
self.driver = self.get_new_driver(browser_name="chrome", options=options)
def test_scrape_quotes(self):
# लक्ष्य साइट पर नेविगेट करें जिसमें reCAPTCHA है
self.open("https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php")
# CAPTCHA उपस्थिति की जांच करें और आवश्यकतानुसार हल करें
if self.is_element_visible("iframe[src*='recaptcha']"):
# CapSolver एक्सटेंशन को स्वचालित रूप से CAPTCHA को संभालना चाहिए
print("CAPTCHA detected, waiting for CapSolver extension to solve it...")
# CAPTCHA हल होने की प्रतीक्षा करें
self.sleep(10) # औसत समाधान समय के आधार पर समय समायोजित करें
# CAPTCHA हल होने के बाद स्क्रैपिंग क्रियाओं के साथ आगे बढ़ें
# उदाहरण क्रिया: किसी बटन पर क्लिक करना या टेक्स्ट निकालना
self.assert_text("reCAPTCHA demo", "h1") # पृष्ठ सामग्री की पुष्टि करें
def tearDown(self):
# परीक्षण के बाद ब्राउज़र को साफ़ करें और बंद करें
self.driver.quit()
super().tearDown()
if __name__ == "__main__":
QuotesScraper().main()व्याख्या:
-
setUp विधि:
- हम प्रत्येक परीक्षण से पहले CapSolver एक्सटेंशन के साथ Chrome ब्राउज़र को कॉन्फ़िगर करने के लिए
setUpविधि को ओवरराइड करते हैं। - हम CapSolver एक्सटेंशन के पथ को निर्दिष्ट करते हैं और इसे Chrome विकल्पों में जोड़ते हैं।
- हम मौजूदा ड्राइवर को छोड़ देते हैं और अपडेट किए गए विकल्पों के साथ एक नया बनाते हैं।
- हम प्रत्येक परीक्षण से पहले CapSolver एक्सटेंशन के साथ Chrome ब्राउज़र को कॉन्फ़िगर करने के लिए
-
test_scrape_quotes विधि:
- हम लक्ष्य वेबसाइट पर नेविगेट करते हैं।
- CapSolver एक्सटेंशन स्वचालित रूप से किसी भी CAPTCHA का पता लगाएगा और उसे हल करेगा।
- हम सामान्य रूप से स्क्रैपिंग कार्य करते हैं।
-
tearDown विधि:
- हम यह सुनिश्चित करते हैं कि परीक्षण के बाद संसाधनों को मुक्त करने के लिए ब्राउज़र बंद हो गया है।
स्क्रिप्ट चलाना:
bash
python scrape_quotes_with_capsolver.pyनोट: भले ही quotes.toscrape.com में CAPTCHAs नहीं हैं, CapSolver को एकीकृत करना आपके स्क्रैपर को उन साइटों के लिए तैयार करता है जो करते हैं।
बोनस कोड
CapSolver पर शीर्ष कैप्चा समाधानों के लिए अपना बोनस कोड क्लेम करें: scrape. इसे रिडीम करने के बाद, आपको प्रत्येक रिचार्ज के बाद 5% अतिरिक्त बोनस मिलेगा, असीमित बार।

निष्कर्ष
इस गाइड में, हमने SeleniumBase का उपयोग करके वेब स्क्रैपिंग कैसे करें, यह पता लगाया है, जिसमें मूल स्क्रैपिंग तकनीकें और अधिक उन्नत उदाहरण शामिल हैं जैसे पृष्ठांकन, गतिशील सामग्री और फॉर्म सबमिशन को संभालना। हमने यह भी दिखाया है कि स्वचालित रूप से CAPTCHAs को हल करने के लिए अपनी SeleniumBase स्क्रिप्ट में CapSolver को कैसे एकीकृत करें, जिससे निर्बाध स्क्रैपिंग सत्र सुनिश्चित होता है।
और देखें
AIJun 18, 2026
अपने एजेंट इंफ्रास्ट्रक्चर के लिए CAPTCHA हल करने वाला चुनें
एक निर्णय ढांचा, एजेंट इंफ्रास्ट्रक्चर के लिए CAPTCHA सॉल्वर चुनने के लिए, चुनौती मैपिंग, सत्र बांधना, पर्यवेक्षणीयता, दर नियंत्रण और जिम्मेदार उपयोग पर केंद्रित।

AIJun 18, 2026
2026 में कृत्रिम बुद्धिमता एजेंट्स के लिए सर्वश्रेष्ठ CAPTCHA एपीआई
एक व्यावहारिक मूल्यांकन गाइड 2026 में एआई एजेंट्स के लिए कैप्चा एपीआई का चयन करने के लिए, दस्तावेजीकृत कार्य कवरेज, पॉलिंग अनुबंध, टोकन सत्यापन और संचालन नियंत्रण पर केंद्रित है।