एजेंटिक ब्राउज़र कैप्चा कैसे हल करते हैं: एआई कैप्चा हल करने की बुनियादी ढांचा

Rajinder Singh
Deep Learning Researcher
हमारे पिछले लेख https://www.capsolver.com/blog/ai/agentic-browser में, हमने देखा कि एगेंटिक ब्राउज़र एक निष्क्रिय "प्रदर्शन उपकरण" से सक्रिय "क्रिया एजेंट" में कैसे बदल जाता है। हमने इसकी मुख्य आर्किटेक्चर: इरादा समझ, पर्यावरणीय अवलोकन, और क्रिया के कार्यान्वयन की जांच की। हालांकि, जैसे-जैसे ये डिजिटल एजेंट वास्तविक वेब के माध्यम से घूमते हैं, वे एक शक्तिशाली रास्ता-रोकने वाले तत्व के सामने आते हैं: CAPTCHA। इस लेख में "अदृश्य इंजन" – CAPTCHA हल करने की बुनियादी ढांचा – के बारे में ध्यान केंद्रित करते हैं, जो इन एजेंटों को अवरोध के बिना आपके लिए सक्रिय रूप से काम करने की अनुमति देता है। हम यह भी जांचेंगे कि CAPTCHAs AI के लिए सबसे बड़ा बाधा क्यों हैं और विशेषज्ञ सेवाएं जैसे CapSolver वेब ऑटोमेशन की अगली पीढ़ी के लिए आवश्यक बुनियादी ढांचा प्रदान करती हैं।
अध्याय 1: "अदृश्य इंजन" — CAPTCHA हल करने की बुनियादी ढांचा
इस परिदृश्य की कल्पना करें: आप एगेंटिक ब्राउज़र से एक लोकप्रिय संगीत समारोह के टिकट बुक करने में मदद मांगते हैं। यह सही तरीके से वेबसाइट खोलता है, खरीद बटन की पहचान करता है, और जैसे ही यह "खरीदें" पर क्लिक करने वाला होता है, एक फिसलता पहेली या नौ अस्पष्ट ट्रैफिक लाइट छवियां अचानक दिखाई देती हैं। आपका डिजिटल सहायक तुरंत बंद हो जाता है। CAPTCHA, जो इंटरनेट के शुरुआती दिनों में जन्म ले चुका "ट्यूरिंग परीक्षण" है, अब AI एजेंटों के लिए सबसे सीधा – और सबसे बुरा – शत्रु बन गया है।
1.1 CAPTCHA AI एजेंट के लिए सबसे बड़ी बाधा क्यों है?
CAPTCHA का अर्थ है "पूरी तरह से स्वचालित सार्वजनिक ट्यूरिंग परीक्षण जो कंप्यूटर और मनुष्य के बीच अंतर बताता है।" इसका मूल उद्देश्य सरल था: बॉट्स को बाहर रखें लेकिन मनुष्यों को अंदर आने दें। लेकिन AI के विकास के साथ, CAPTCHAs भी लगातार विकसित होते रहे हैं – सरल विकृत अक्षरों से जटिल स्लाइडर, छवि-चयन कार्य, और व्यवहार विश्लेषण प्रणालियों तक। वे अब केवल एक अक्षर-स्वीकृति समस्या नहीं हैं।

सामान्य ऑटोमेशन स्क्रिप्ट के लिए, CAPTCHAs लगभग मृत्यु के लिए होते हैं। लेकिन एगेंटिक ब्राउज़र के लिए, तीन मुख्य कारणों के कारण ये बराबर गंभीर चुनौती हैं:
-
अपसंसा कठिनाई में एक तीव्र वृद्धि: भले ही सबसे आगे बढ़े बहुमाध्यमिक मॉडल भी भारी विकृत पाठ, अस्पष्ट छवि वस्तुओं, या जटिल पृष्ठभूमि में छिपे स्लाइडर अंतराल की विश्वसनीय रूप से पहचान करने में कठिनाई महसूस करते हैं। AI बस "गलत देख सकता है", और एक गलती एक पूर्ण कार्य प्रक्रिया को टूटने के लिए पर्याप्त हो सकती है।
-
परतदार बॉट-रोकने वाले प्रोत्साहन तंत्र: आधुनिक CAPTCHAs अब केवल अग्रभूमि चुनौतियां नहीं हैं। वेबसाइट माउस ट्रेजेक्टरी, टाइपिंग रिदम, पृष्ठ रहने के समय, और ब्राउज़र फिंगरप्रिंट्स की निगरानी करती हैं। यदि प्रणाली निर्धारित करती है कि ऑपरेटर "मनुष्य की तरह व्यवहार नहीं करता है", तो CAPTCHA कठिनाई तुरंत बढ़ सकती है – एक सामान्य बॉक्स चेक करने से लेकर दस लगातार छवि-स्वीकृति कार्य करने तक।
-
समय संवेदनशीलता और संदर्भ विघटन: CAPTCHAs आमतौर पर अवधि सीमा के साथ आते हैं। जब एगेंटिक ब्राउज़र कई चरणों के कार्य में CAPTCHA पर बहुत लंबे समय तक फंस जाता है, तो लॉगिन सत्र अवधि सीमा पार कर सकते हैं, उत्पाद बिक जा सकते हैं, और पूरी कार्य प्रक्रिया ढह सकती है। यह एक राजमार्ग पर अचानक सेतु ढह जाने जैसा है, जो पूरी ऑटोमेशन पाइपलाइन को रोक देता है।
दूसरे शब्दों में, CAPTCHA के विरुद्ध जीत के बिना, एगेंटिक ब्राउज़र केवल "असुरक्षित पीछे की गलियों" पर यात्रा कर सकते हैं, वास्तविक वेबसाइट के "पूर्ण राजमार्ग प्रणाली" के माध्यम से वास्तविक रूप से नहीं घूम सकते। यही कारण है कि CAPTCHA हल करने वाले बुनियादी ढांचे जैसे कैपसॉल्वर मौजूद हैं।
1.2 CapSolver AI एजेंट के रास्ता साफ करता है कैसे
CapSolver सामान्य उपयोगकर्ताओं के लिए एक उपकरण नहीं है, बल्कि विकासकर्ताओं के टूलकिट में छिपा "CAPTCHA इंजन" है। इसके केंद्र में, यह एक बुद्धिमान CAPTCHA हल करने वाला प्लेटफॉर्म है जो विशेष रूप से ऑटोमेशन कार्यक्रमों और AI एजेंटों के लिए API इंटरफेस प्रदान करता है।
हम इसे एक 24/7 उपलब्ध CAPTCHA हल करने वाली टीम के रूप में सोच सकते हैं जो कभी थक नहींता है और अत्यधिक तेजी से काम करता है – बस इसके "कर्मचारी" न केवल जटिल AI मॉडल के साथ-साथ अत्यधिक अनुकूलित रणनीति एल्गोरिदम के रूप में बने हुए हैं।
इसकी क्षमताओं को बेहतर ढंग से समझने के लिए, निम्न सारणी एक ही CAPTCHA चुनौतियों के सामने पारंपरिक दृष्टिकोण और CapSolver क्षमताओं के बीच अंतर दर्शाती है:
| तुलना का आयाम | स्थानीय OCR / सरल मॉडल | मानव CAPTCHA-हल करने वाले प्लेटफॉर्म | CapSolver |
|---|---|---|---|
| समर्थित CAPTCHA प्रकार | केवल सरल पाठ CAPTCHA; छवि चयन अधिकांशतः अकार्यकर्ता | सैद्धांतिक रूप से सभी प्रकार का समर्थन करता है, लेकिन धीमा और महंगा | मुख्यधारा CAPTCHA प्रकार को कवर करता है |
| स्वीकृति गति | मिलीसेकंड, लेकिन कम सफलता दर | प्रयास पर 5-15 सेकंड | प्रयास पर 1-3 सेकंड |
| सफलता दर | कम (जटिल CAPTCHAs पर बर्बर) | आपेक्षिक रूप से उच्च, लेकिन कार्यकर्ता थकान और नेटवर्क देरी से प्रभावित होती है | उच्च और स्थिर |
| लागत संरचना | एक बार के विकास लागत | उपयोग के अनुसार भुगतान करें लेकिन उच्च श्रम लागत | उपयोग के अनुसार भुगतान करें लेकिन कम कीमत और कम सीमांत लागत |
| विरोधी-निरीक्षण क्षमता | लगभग कोई नहीं | व्यवहार विश्लेषण प्रणालियों को संभाल नहीं सकता | ब्राउज़र वातावरण के साथ एकीकृत हो सकता है और जोखिम-संगत टोकन या निर्देश वापस कर सकता है |
सारणी 1-1 पारंपरिक CAPTCHA हल करने वाले तरीकों और CapSolver क्षमताओं की तुलना
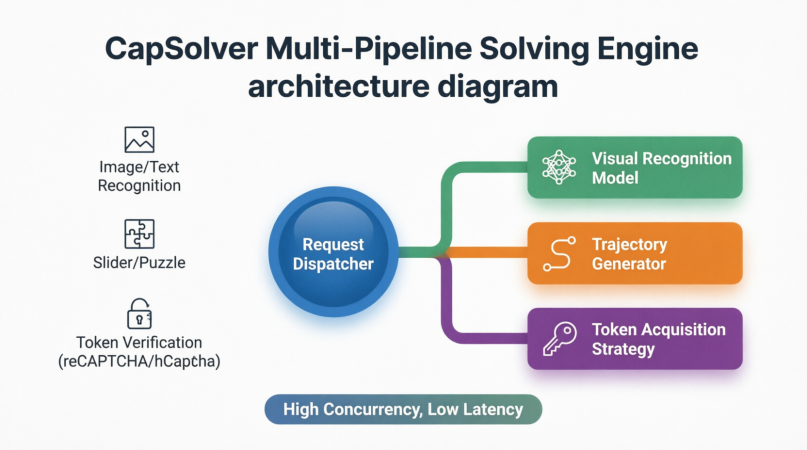
CapSolver का मुख्य कार्य विधि वास्तव में "AI के खिलाफ AI, रणनीति के खिलाफ रणनीति" है। विभिन्न प्रकार के CAPTCHAs के लिए, यह विशिष्ट हल करने वाले पाइपलाइन के साथ एकजुट होता है:
-
छवि और पाठ स्वीकृति CAPTCHAs: अपने विशिष्ट दृश्य मॉडल और विशाल प्रशिक्षण डेटा सेट के साथ, CapSolver भारी विकृत, अतिव्यापी या शोर वाले पाठ की बिना त्रुटि स्वीकृति कर सकता है।
-
स्लाइडर और पहेली CAPTCHAs: बस अंतराल के निर्देशांक के बजाय, यह पर्यावरणीय विश्लेषण के आधार पर चिकनी गति के बराबर गति रेखाएं उत्पन्न करता है जबकि मानव स्पर्श अंतरक्रियाओं के छोटे हाथ के कांपन और त्वरण और मंदी पैटर्न के अनुरूप बनाता है। इन व्यवहार पैरामीटर ऑटोमेशन कार्यक्रमों के लिए स्लाइडर के खिसकाव को प्राकृतिक ढंग से खींचने की अनुमति देते हैं।
-
टोकन-आधारित सत्यापन प्रणालियां (reCAPTCHA v2/v3, Cloudflare आदि): इन CAPTCHAs के लिए स्पष्ट उपयोगकर्ता इनपुट की आवश्यकता नहीं होती है। बजाय इसके, वे पृष्ठभूमि में ब्राउज़र के व्यवहार का मूल्यांकन करते हैं और एक बार के टोकन वापस करते हैं। CapSolver ब्राउज़र फिंगरप्रिंट्स, IP विश्वसनीयता, माउस ट्रेजेक्टरी और अन्य संदर्भ डेटा के साथ विशेष हल करने वाले इंटरफेस के माध्यम से वैध सत्यापन टोकन प्राप्त करता है। अगेंटिक ब्राउज़र केवल टोकन को पृष्ठ पर डालता है ताकि सत्यापन पारित हो जाए।
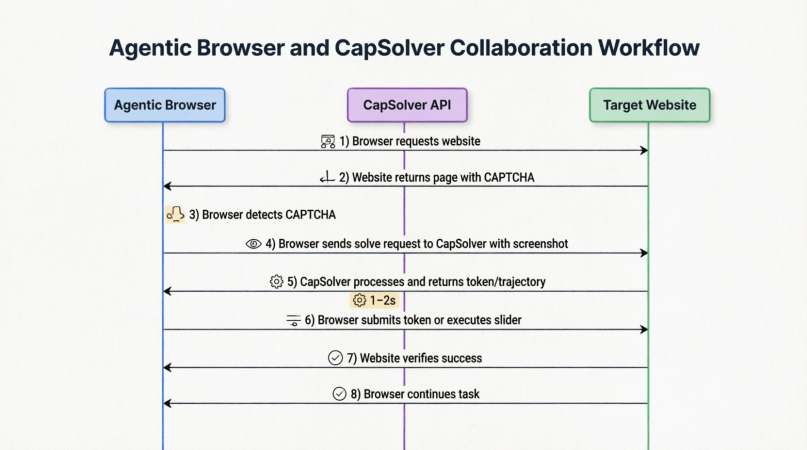
तो CapSolver और अगेंटिक ब्राउज़र वास्तव में कैसे सहयोग करते हैं? निम्न चित्र पूर्ण प्रक्रिया को दर्शाता है:
ब्राउज़र वेबसाइट के लिए अनुरोध भेजता है, CAPTCHA का सामना करता है, स्क्रीनशॉट लेता है, CapSolver API को कॉल करता है, टोकन या व्यवहार अंतराल प्राप्त करता है, सत्यापन प्रस्तुत करता है, और मूल कार्य को बरकरार रखता है – पूरी प्रक्रिया घनिष्ठ रूप से एकीकृत होती है और आमतौर पर 1-2 सेकंड में पूरी हो जाती है।
इसका अर्थ है कि अगेंटिक ब्राउज़र के लिए CAPTCHAs अब AI के स्वयं के "देखने" और "अनुमान लगाने" के समस्या नहीं हैं। बल्कि, ये विशेषज्ञ बुनियादी ढांचा प्रदाताओं को बाहरी कार्य के रूप में मानकीकृत कार्य बन जाते हैं। ब्राउज़र केवल चुनौती को पकड़ता है, संदर्भ को पैक करता है, भेजता है, इस "कुंजी" की प्रतीक्षा करता है, और अपनी यात्रा को जारी रखता है।
1.3 अगेंटिक ब्राउज़र और CapSolver के बीच सहयोग कार्य प्रवाह
अब हम अगेंटिक ब्राउज़र के डायनामिक अनुकूलन मॉड्यूल के साथ CapSolver के संयोजन की जांच करते हैं और देखते हैं कि वे एक बिना रुकावट के "अवरोध पार करने वाले प्रदर्शन" में कैसे काम करते हैं।
जब अगेंटिक ब्राउज़र कार्य कर रहा होता है, तो इसकी पर्यावरणीय अवलोकन परत लगातार वेबपेज की निगरानी करती है। जैसे ही CAPTCHA तत्व की पहचान की जाती है (उदाहरण के लिए, reCAPTCHA iframe वाला पॉप-अप), क्रिया कार्यान्वयन तुरंत रुक जाता है और विशेष CAPTCHA-हल करने वाली उप-प्रक्रिया चालू करता है।
इस प्रक्रिया की बहुत जटिलता होती है और आमतौर पर निम्नलिखित चरणों के साथ होती है:
-
संदर्भ संग्रहण: अगेंटिक ब्राउज़र CAPTCHA क्षेत्र के स्क्रीनशॉट लेता है और वर्तमान URL, साइटकी, ब्राउज़र व्यूपोर्ट आकार, और उपयोगकर्ता-एजेंट के साथ संदर्भिक जानकारी एकत्र करता है।
-
कार्य सबमिशन: स्क्रीनशॉट और पैरामीटर को एक साथ पैक करके, CAPTCHA प्रकार निर्दिष्ट करते हुए API के माध्यम से CapSolver को भेजा जाता है।
-
पृष्ठभूमि हल करना: कार्य प्राप्त करने के बाद, CapSolver इसे संबंधित हल करने वाले पाइपलाइन के माध्यम से राउट करता है। उदाहरण के लिए, reCAPTCHA v2 के सामने आने पर, यह विशेष हल करने वाले को बुलाता है जो वैध
g-recaptcha-responseटोकन वापस करता है। पूरी हल करने की प्रक्रिया आमतौर पर 1-2 सेकंड में पूरी हो जाती है। -
निर्देश वापसी: अगेंटिक ब्राउज़र वापसी परिणाम प्राप्त करता है – जो टोकन स्ट्रिंग हो सकता है या वापसी ट्रेजेक्टरी डेटा के सेट।
-
साइट कार्यान्वयन: अगेंटिक ब्राउज़र टोकन को छिपे फॉर्म क्षेत्र में डालता है और फॉर्म जमा करता है, या वापसी ट्रेजेक्टरी डेटा के अनुसार मानव-जैसा स्लाइडर गति का अनुकरण करता है। CAPTCHA लेयर गायब हो जाता है और मूल कार्य प्रवाह बिना किसी रुकावट के बरकरार रहता है।
-
स्थिति जांच: ब्राउज़र जांचता है कि क्या पृष्ठ सत्यापन सफल रहा है और लक्ष्य तत्व फिर से दिखाई दे रहे हैं जब तक कार्य प्रक्रिया बाधित हो जाती है।
महत्वपूर्ण रूप से, आधुनिक CAPTCHAs कई प्रकार में आते हैं जिनमें विभिन्न स्तर की जटिलता होती है। निम्न चित्र मुख्यधारा CAPTCHA प्रकार को वर्गीकृत करता है और उनके जटिलता स्तर के चिह्न लगाता है:
अंतिम उपयोगकर्ता के लिए, पूरी प्रक्रिया पूरी तरह से पारदर्शी रहती है। अगेंटिक ब्राउज़र के कार्य लॉग में, उपयोगकर्ता केवल एक सरल संदेश देख सकते हैं जैसे:
"reCAPTCHA v2 पाया गया। स्वचालित रूप से 1.2 सेकंड में हल किया गया।"
एक ऐसा बाधा जो पहले पूरी ऑटोमेशन कार्य प्रक्रिया को रोक देती थी, पृष्ठभूमि में चुपके से हल कर दी जाती है।
यह AI-एजेंट क्षमताओं में एक महत्वपूर्ण कूद है: एजेंट अब ऑटोमेशन के विरोधी प्रणालियों से डर नहीं लेता है। CAPTCHA हल करने वाले बुनियादी ढांचा "अदृश्य इंजन" के रूप में काम करता है, अगेंटिक ब्राउज़र को खुले इंटरनेट पर आत्मनिर्भर कार्य करने के लिए आवश्यक ऑपरेशनल स्वतंत्रता प्राप्त करते हैं।
इस इंजन के बिना, सभी बुद्धिमान एजेंट के बारे में दावा बस पहले ही CAPTCHA पॉप-अप पर टूट सकते हैं।
अध्याय 2: आज अगेंटिक ब्राउज़र कहां लागू किए जा रहे हैं?
अगर पिछले अध्याय इस तकनीक को दूर लगाते हैं, निम्न उदाहरण आपके दृष्टिकोण को पूरी तरह से बदल सकते हैं। अगेंटिक ब्राउज़र भविष्य में उड़ते अमूर्त अवधारणाएं नहीं हैं – वे तीन प्रमुख क्षेत्रों में तेजी से प्रवेश कर रहे हैं: व्यक्तिगत उत्पादकता, व्यापार ऑटोमेशन और डेटा एकत्रीकरण। प्रत्येक क्षेत्र में, वे अलग-अलग स्तर पर व्यावहारिक समस्याओं को हल कर रहे हैं।
निम्न चित्र अगेंटिक ब्राउज़र के मुख्य अनुप्रयोग परिदृश्य का सारांश प्रस्तुत करता है:
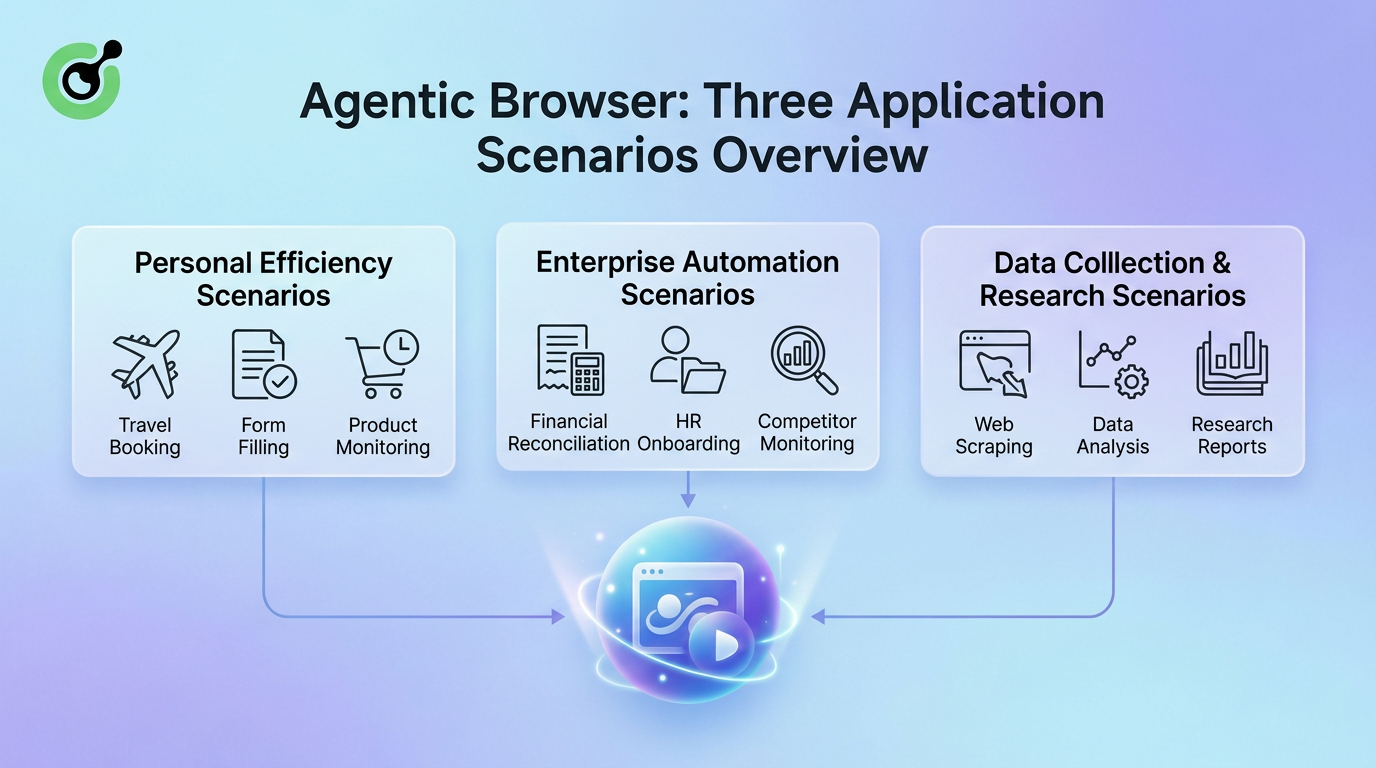
अगेंटिक ब्राउज़र के अनुप्रयोग व्यक्तिगत उपयोगकर्ताओं से लेकर बड़े उद्यमों तक फैले हुए हैं, और दैनिक कार्यों से लेकर व्यावसायिक अनुसंधान कार्य प्रक्रियाओं तक। व्यक्तिगत उत्पादकता के अनुप्रयोग में, अगेंटिक ब्राउज़र उपयोगकर्ताओं की यात्रा बुक करने, दोहराए जाने वाले फॉर्म भरने और उत्पाद मूल्य उतार-चढ़ाव की निगरानी में मदद करते हैं। व्यापार ऑटोमेशन में, वे वित्तीय अनुरूपता, कर्मचारी नियुक्ति और प्रतिद्वंद्वी ट्रैकिंग के कार्य करते हैं। डेटा एकत्रीकरण और अनुसंधान में, वे अकथित खोजकर्ता और बुद्धिमान विश्लेषण सहायक के रूप में काम करते हैं।
अब हम इन तीन परिदृश्यों की विस्तार से जांच करेंगे ताकि हम यह समझ सकें कि अगेंटिक ब्राउज़र वास्तव में कैसे "काम करते हैं।"
2.1 व्यक्तिगत उत्पादकता: दैनिक कार्य के बुद्धिमान अनुबंध
सामान्य उपयोगकर्ताओं के लिए, अगेंटिक ब्राउज़र के सबसे तत्काल मूल्य है: समय बचाना।
हर दिन, लोग ब्राउज़र में बहुत सारे दोहराए जाने वाले और बहु-चरण ऑनलाइन कार्य करते हैं। इन कार्यों के आमतौर पर तीन विशेषताएं होती हैं:
- उद्देश्य स्पष्ट है
- नियम निश्चित हैं
- ऑपरेशन थकाऊ हैं
अगेंटिक ब्राउज़र ठीक इन प्रकार के कार्यों को ले लेते हैं – स्थितियां जहां उपयोगकर्ता यह जानते हैं कि क्या करना है, लेकिन हाथ से ऑपरेशन करना नहीं चाहते हैं।
व्यक्तिगत उत्पादकता के अनुप्रयोग में, अगेंटिक ब्राउज़र निम्नलिखित व्यावहारिक कार्य में सहायता कर सकते हैं:
स्वचालित बुकिंग और खरीदारी
उदाहरण के लिए, उड़ान बुक करना, होटल बुक करना, या सीमित उत्पाद खरीदना। उपयोगकर्ता केवल प्राकृतिक भाषा में अपनी आवश्यकताओं को बताने की आवश्यकता होती है – जैसे समय, पसंद, या बजट – और अगेंटिक ब्राउज़र वेबसाइट के बीच मूल्यों की तुलना कर सकता है, विकल्प फ़िल्टर कर सकता है, जानकारी भर सकता है, और अद्वितीय परिणाम प्रस्तुत कर सकता है।
वेबसाइट के बीच जानकारी एकत्र करना और फॉर्म भरना
वीजा आवेदन, स्कूल आवेदन, या खर्च वापसी कार्य आमतौर पर उपयोगकर्ता को बहुत सारे फॉर्म में एक ही जानकारी दोहराने के लिए मजबूर करते हैं।
एगेंटिक ब्राउज़र एक "जानकारी प्रबंधक" के रूप में काम करता है जो उपयोगकर्ता डेटा को सुरक्षित रूप से याद रखता है, फॉर्म क्षेत्रों की स्वचालित रूप से पहचान करता है, और बुद्धिमान रूप से नक्शा बनाता है। उदाहरण के लिए, यह एक पूरा नाम "पहला नाम" और "अंतिम नाम" में विभाजित कर सकता है।
दैनिक जानकारी निगरानी
एगेंटिक ब्राउज़र पृष्ठभूमि में उत्पाद भंडार की निगरानी, मूल्य परिवर्तन, या उत्पाद निर्माण के नए उत्पाद जारी करना कर सकते हैं। जब निर्धारित शर्तों के संतुष्ट हो जाते हैं – उदाहरण के लिए, मूल्य गिरावट या भंडार बहाल करना – ब्राउज़र तुरंत उपयोगकर्ता को सूचित करता है या अपने आप आर्डर लगा सकता है।
इस उपयोगकर्ता अनुभव में परिवर्तन को बेहतर ढंग से समझने के लिए, निम्न सारणी पारंपरिक कार्य प्रक्रिया के साथ अगेंटिक ब्राउज़र कार्य प्रक्रिया की तुलना करता है:
| कार्य प्रकार | पारंपरिक कार्य प्रक्रिया समय लागत | अगेंटिक ब्राउज़र कार्य प्रक्रिया | उपयोगकर्ता भूमिका परिवर्तन |
|---|---|---|---|
| उड़ान की तुलना और बुक करना | 15-30 मिनट (कई वेबसाइटों के ब्राउज़ करने के माध्यम से हाथ से काम करना) | 1 मिनट (आवश्यकता बताने और सिफारिश की पुष्टि करना) | निष्पादक से निर्णय लेने वाला |
| जटिल ऑनलाइन फॉर्म भरना | 20-40 मिनट (एक ही जानकारी दोहराना) | 2 मिनट (ऑटोफिल के परिणामों की समीक्षा करना और छोटे अंतर के सुधार करना) | डेटा-प्रविष्टि ऑपरेटर से समीक्षक |
| उत्पाद बहाली या मूल्य गिरावट की निगरानी | अत्यधिक समय लेता है (हाथ से रीफ्रेश करना और लगातार ध्यान रखना) | 0 मिनट (अटूट निगरानी के साथ स्वचालित सूचना प्राप्त करना) | निगरानक से प्राप्तकर्ता |
| अंतर-प्लेटफॉर्म डेटा संगठन | 1-2 घंटे (कॉपी-पेस्टिंग और फॉर्मेटिंग) | 5 मिनट (स्वचालित निकास और फॉर्मेटिंग) | एक्सीक्यूटर से विश्लेषक में |
तालिका 2-1 पारंपरिक व्यक्तिगत कार्यों और एजेंट ब्राउजर की क्षमता की तुलना
ऊपर दिखाए गए अनुसार, एजेंट ब्राउजर एक व्यक्तिगत सहायक के रूप में काम करता है। इससे उपयोगकर्ता को "वर्कफ्लो के ऑपरेटर" बने रहने से मुक्त करता है और उन्हें "लक्ष्य निर्धारित करने वाले" और "परिणामों के समीक्षक" में बदल देता है।
2.2 एंटरप्राइज ऑटोमेशन: प्रणालियों के बीच बुद्धिमान समन्वय
अगर व्यक्तिगत उत्पादकता में सुधार "परिश्रम कम करना" है, तो एजेंट ब्राउजर के एंटरप्राइज परिदृश्य में मूल्य जुड़ाव है।
बड़ी संगठन अक्सर अनेक अलग-अलग पुराने प्रणालियों, SaaS प्लेटफॉर्म और आपूर्तिकर्ता पोर्टल पर निर्भर करते हैं जो एपीआई के माध्यम से आसानी से एकीकृत नहीं होते हैं। कर्मचारियों को "मानव चिपकाने वाला" बनाने के लिए मजबूर किया जाता है, जो पुनः प्रणालियों के बीच जानकारी के हस्तचालित स्थानांतरण के लिए बाध्य होते हैं।
यहीं पर एजेंट ब्राउजर अपने सबसे मजबूत फायदे दिखाते हैं।
पारंपरिक एंटरप्राइज उपयोग मामले
- वित्तीय और आपूर्ति श्रृंखला समायोजन
एक एजेंट ब्राउजर बैंकिंग पोर्टल में स्वचालित लॉगिन कर सकता है, बयान डाउनलोड कर सकता है, इसकी ईएमएस प्रणालियों के साथ तुलना कर सकता है, असंगति रिपोर्ट बना सकता है, और यहां तक कि अधिसूचना ईमेल भी तैयार कर सकता है।
- पूर्ण कर्मचारी ओनबोर्डिंग कार्य प्रक्रियाएं
संगठन ओनबोर्डिंग कार्य पैकेज पूर्व निर्धारित कर सकते हैं। एजेंट ब्राउजर स्वचालित रूप से एचआर प्रणालियों, आईटी प्रणालियों, मेलिंग सूचियों और एक्सेस-नियंत्रण प्रणालियों में खाते बनाता है, शून्य लापरवाही और शून्य देरी सुनिश्चित करता है।
- प्रतिद्वंद्वी निगरानी और बाजार जागरूकता
एजेंट ब्राउजर "बाजार रडार" प्रणालियों के रूप में कार्य कर सकते हैं, जो स्वचालित रूप से प्रतिद्वंद्वी वेबसाइट, ई-कॉमर्स दुकानों और सोशल-मीडिया पृष्ठों का दौरा करते हैं, महत्वपूर्ण जानकारी बदलावों की पहचान करते हैं, और उन्हें संरचित डेटाबेस में संग्रहीत करते हैं।
एंटरप्राइज ऑटोमेशन में एजेंट ब्राउजर की विशिष्ट स्थिति को बेहतर ढंग से समझाने के लिए, निम्न तालिका पारंपरिक कार्यों और सामान्य एपीआई एकीकरण की तुलना करती है:
| आयाम | हाथ से संचालित कार्य | एपीआई एकीकरण विकास | एजेंट ब्राउजर |
|---|---|---|---|
| लागू प्रणालियां | कोई भी प्रणाली | केवल खुले एपीआई वाली प्रणालियां | कोई भी वेब-आधारित प्रणाली, पुराने आंतरिक प्रणालियों सहित |
| डिप्लॉयमेंट चक्र | कोई विकास की आवश्यकता नहीं, लेकिन समय लेता है | हफ्तों से महीनों (विकास संसाधनों पर निर्भर करता है) | घंटों से दिनों (कार्य सेटिंग और परीक्षण) |
| लचीलापन | उच्च (मानव डायनामिक रूप से अनुकूलित होते हैं) | कम (बदलाव के बाद इंटरफेस पुनः लिखने की आवश्यकता होती है) | उच्च (AI डायनामिक रूप से पृष्ठ परिवर्तनों के अनुकूल होता है) |
| CAPTCHA/लॉगिन प्रबंधन | हाथ से प्रबंधन की आवश्यकता होती है | आमतौर पर सीधे हल करना कठिन होता है | स्वचालित रूप से हल करने वाले इंजन का उपयोग करता है |
| विस्तारयोग्यता | खराब | अत्यधिक मजबूत | मजबूत (समांतर कार्य क्रियान्वयन संभव है) |
| सामान्य विफलता की स्थिति | मानव थकावट और लापरवाही | एपीआई दर सीमा या संस्करण असंगति | अत्यधिक बिखरे पृष्ठ की स्थिति में मानव पुष्टि की आवश्यकता हो सकती है |
तालिका 2-2 एंटरप्राइज क्रॉस-सिस्टम ऑटोमेशन समाधान की तुलना
ऊपर दिखाए गए अनुसार, एजेंट ब्राउजर को एपीआई के स्थान पर डिज़ाइन नहीं किया गया है। बल्कि, एपीआई उपलब्ध न होने या विकास की लागत अधिक होने के मामलों में वे एक हल्का एकीकरण परत प्रदान करते हैं।
एआई की लचीलापन और अनुकूलन क्षमता का उपयोग करके, एजेंट ब्राउजर पारंपरिक ऑटोमेशन दृष्टिकोण द्वारा छोड़े गए अंतर को पूरा करते हैं, बिना पुरानी बुनियादी ढांचा फिर से बनाए बिना एंटरप्राइज को बुद्धिमान क्रॉस-सिस्टम समन्वय प्राप्त करने में सक्षम बनाते हैं।
2.3 डेटा संग्रह और अनुसंधान: हस्तचालित एकत्रीकरण से बुद्धिमान निकास
डेटा को डिजिटल युग के तेल के रूप में वर्णित किया जाता है, लेकिन स्पष्ट सार्वजनिक वेब डेटा के अत्यधिक एकत्रीकरण में लगभग हमेशा कठिनाई रही है।
पारंपरिक वेब क्रॉलर निश्चित पारस्परिक नियमों पर निर्भर करते हैं। जब लक्ष्य वेबसाइट अपने लेआउट को बदल देते हैं या विरोधी-स्क्रैपिंग उपायों को शामिल करते हैं, तो क्रॉलर आमतौर पर पूरी तरह से विफल हो जाते हैं। वैज्ञानिक अनुसंधानकर्ता, बाजार अनुसंधान कंपनियां, और जांच पत्रकारी टीमें अक्सर बड़ी संख्या में विविध वेबपेजों से विशिष्ट जानकारी के निकास की आवश्यकता होती है, जिसके कारण पारंपरिक दृष्टिकोण खर्च और समय लेने वाला होता है।
एजेंट ब्राउजर डेटा संग्रह के लिए एक पूरी तरह से नई परंपरा पेश करते हैं:
"कोड नियमों पर आधारित निकास से अर्थपूर्ण लक्ष्यों पर आधारित निकास तक की ओर बदलाव।"
उनका कार्यप्रणाली आमतौर पर इस प्रकार कार्य करती है:
अनुसंधानकर्ता प्राकृतिक भाषा में आवश्यक डेटा आयामों और नमूना परास का वर्णन करते हैं। उदाहरण के लिए:
"ऊपरी 100 ई-कॉमर्स उत्पाद पृष्ठों से उत्पाद शीर्षक, कीमत, रेटिंग और रिव्यू गिनती के निकास करें और स्पॉन्सर्ड उत्पादों को छोड़ दें।"
एजेंट ब्राउजर स्वचालित रूप से वेबपेजों पर नेविगेट करता है, पर्यावरणीय अवलोकन के माध्यम से संबंधित जानकारी ब्लॉक की पहचान करता है, बुद्धिमानी से डेटा निकालता है और संरचित करता है, और जटिल अंतरक्रियाओं जैसे पृष्ठांतरण, अंतहीन स्क्रॉलिंग और पॉप-अप के साथ निपटता है।
जब लक्ष्य वेबसाइट अपने लेआउट को बदल देते हैं, तो पारंपरिक क्रॉलर तुरंत विफल हो जाते हैं। विपरीत, एजेंट ब्राउजर दृश्य आधार पर जानकारी की पुनः स्थिति का प्रयास करते हैं और कार्यक्रम जारी रखते हैं।
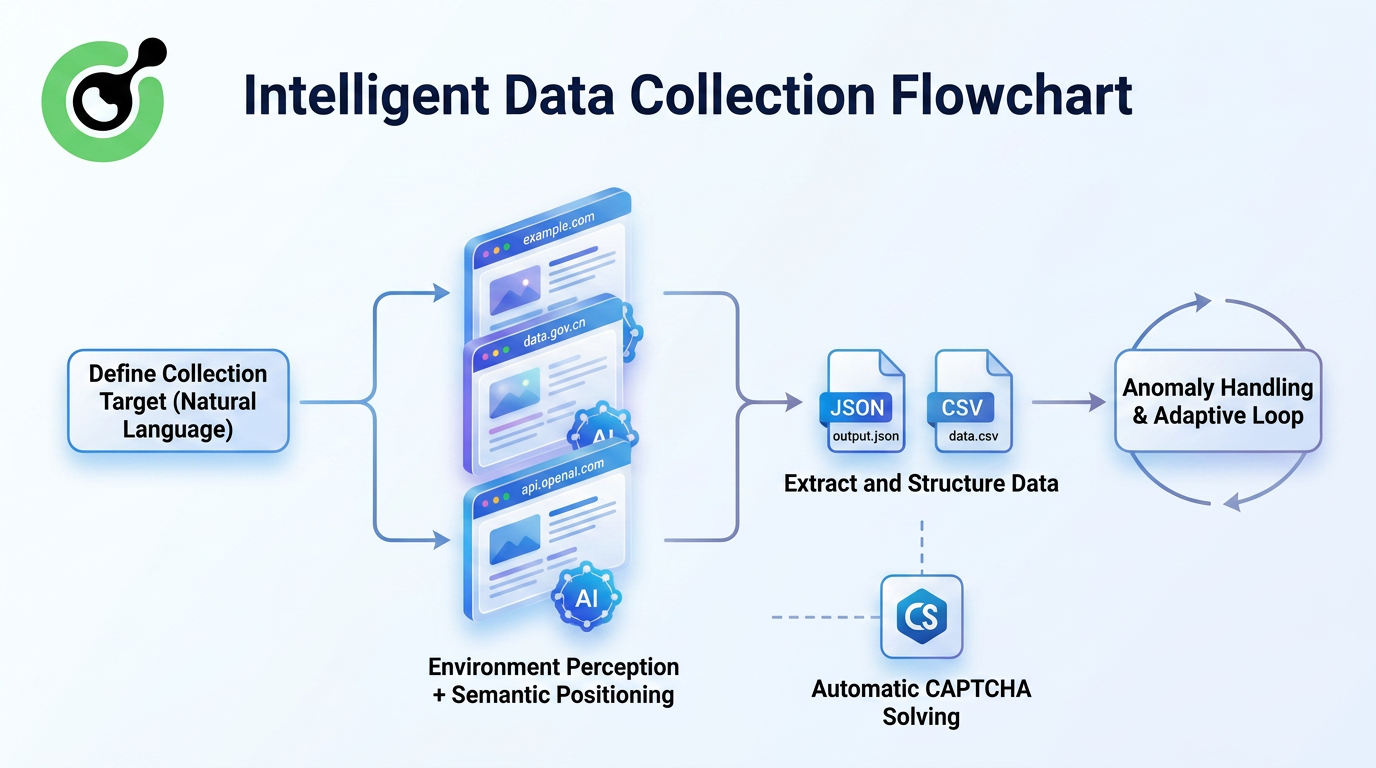
इस प्रकार के दृष्टिकोण में कई मूलभूत सुधार शामिल हैं:
- कोई भी पारस्परिक नियमों के रखरखाव की आवश्यकता नहीं होती है
एआई समझता है कि "कीमत" कैसी दिखती है, निश्चित HTML वर्ग नामों पर निर्भर नहीं होता है।
- वेबसाइट पुनर्डिज़ाइन के लिए अधिक मजबूती
छोटे लेआउट बदलाव अब तक निकास पाइपलाइन को तुरंत तोड़ नहीं देते हैं।
- जटिल अंतरक्रियाओं के साथ निपटने की क्षमता
लॉगिन की आवश्यकता वाले वेबसाइटों, अंतहीन स्क्रॉलिंग या टैब बदलाव के लिए, एजेंट ब्राउजर वास्तविक उपयोगकर्ता के समान इंटरफेस से अंतरक्रिया कर सकते हैं और फिर जानकारी निकालते हैं।
- पुनर्उत्पादन अनुसंधान कार्यप्रणाली
कार्य सेटिंग बचाए जा सकते हैं और साझा किए जा सकते हैं, जिससे डेटा संग्रह मानकीकृत और पुनर्उत्पादन योग्य बन जाता है।
एजेंट ब्राउजर के डेटा संग्रह कार्यों में विफलता के लिए बर्दाश्त करने के लाभ को बेहतर ढंग से दर्शाने के लिए, निम्न चित्र पारंपरिक क्रॉलर और एजेंट ब्राउजर के बीच विभिन्न वेबसाइट पुनर्डिज़ाइन के बाद तुलना करता है:
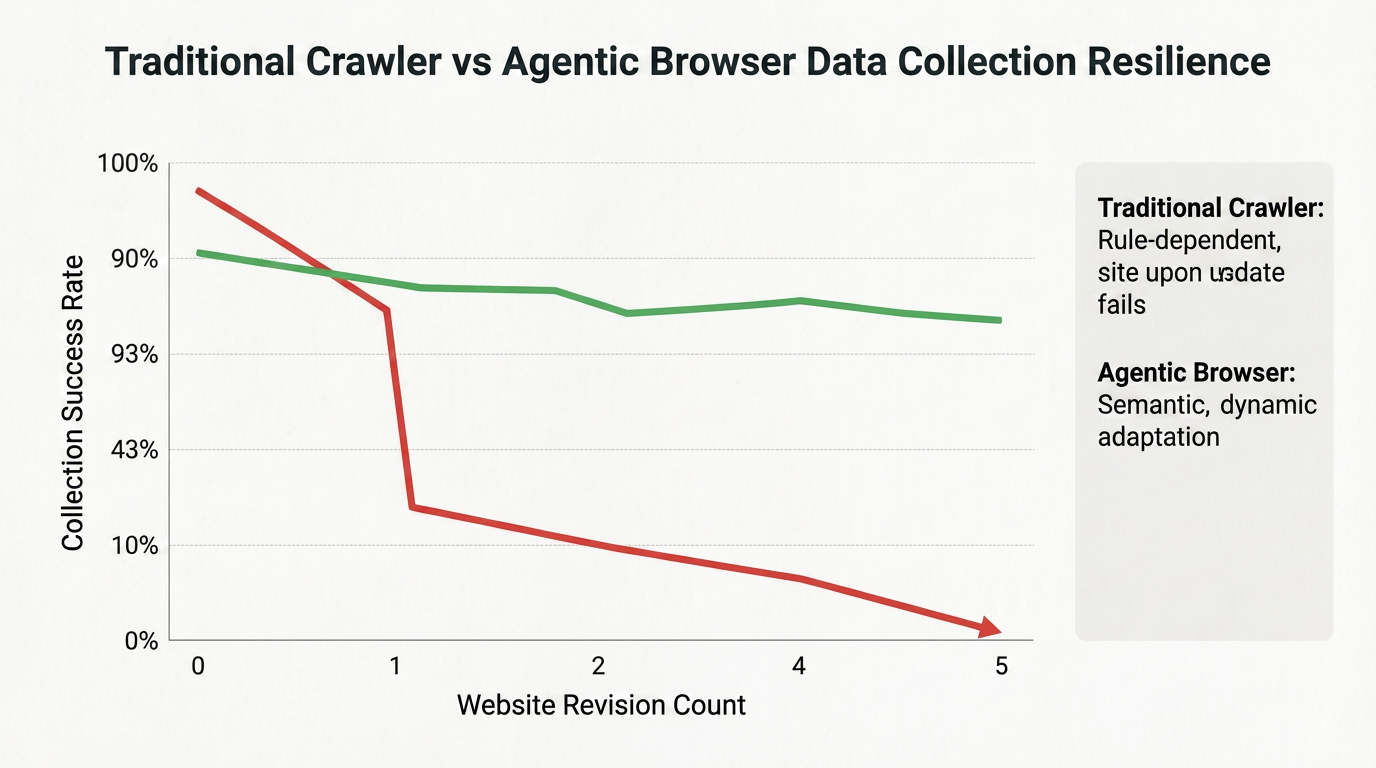
पारंपरिक क्रॉलर पहले वेबसाइट पुनर्डिज़ाइन के बाद बड़े पैमाने पर सफलता दर में गिरावट दर्ज करते हैं, जबकि एजेंट ब्राउजर दृश्य अवस्थिति और अर्थपूर्ण समझ क्षमताओं के कारण बार-बार पुनर्डिज़ाइन के बाद भी अपेक्षाकृत उच्च निकास सफलता दर बरकरार रखते हैं।
इस प्रतिरोधकता के कारण वे लंबे समय तक, बड़े पैमाने पर डेटा संग्रह परियोजनाओं के लिए आदर्श हैं।
उदाहरण के लिए, एक सामाजिक विज्ञान अनुसंधान टीम की कल्पना करें जिसे 30 देशों में 200 नीति वेबसाइटों पर विशिष्ट नीति वाक्यांशों की तुलना करने की आवश्यकता होती है। पारंपरिक रूप से, इसके लिए अनुसंधान सहायकों को महीनों तक हाथ से जानकारी कॉपी करने और संगठित करने में लग जाएगा।
अब, अनुसंधानकर्ता एक एजेंट ब्राउजर कार्य की व्यवस्था कर सकते हैं जो इन वेबसाइटों का स्वचालित रूप से चक्कर लगाता है, लक्ष्य की शब्दों वाले पृष्ठों की स्थिति ढूंढता है, संबंधित वाक्यांश निकालता है और उन्हें स्वचालित रूप से वर्गीकृत करता है।
अनुसंधानकर्ता केवल बाद में संग्रहित परिणामों की समीक्षा और विश्लेषण करने के लिए आवश्यक है, जिससे मूल्यवान मानव प्रयास को वास्तविक "अनुसंधान" पर केंद्रित करने के लिए बर्बाद होने वाले "हाथ से परिवहन कार्य" से मुक्त कर दिया जाता है।
निष्कर्ष
एजेंट ब्राउजर एक नई उत्पाद के साथ-साथ ऑनलाइन होने के एक पूरी तरह से नई दृष्टिकोण का प्रतिनिधित्व करता है। इसकी मूल तार्किकता यह है: ब्राउजर केवल आपके क्लिक के लिए एक इंटरफेस नहीं होना चाहिए, बल्कि एक बुद्धिमान एजेंट होना चाहिए जो आपके इरादे को समझता है और आपकी कार्य पूर्ण करने में मदद करता है। तकनीकी कार्यान्वयन के दृष्टिकोण से, यह बड़े भाषा मॉडल की तार्किक क्षमता पर निर्भर करता है जो कार्यों की योजना बनाता है, बहु-माध्यमीय अवलोकन के माध्यम से वेब पृष्ठों की समझ करता है, वास्तविक ब्राउजर वातावरण में कार्य करता है, और सुविधाओं जैसे CapSolver के बुनियादी ढांचे के माध्यम से ऑटोमेशन के रास्ते में बाधाओं को दूर करता है। इन तकनीकों के संयोजन ने हमारे द्वारा तीन दशकों तक उपयोग किए गए "जानकारी के खिड़की" को एक वास्तविक "क्रिया प्लेटफॉर्म" में अपग्रेड कर दिया है।
एफ़एक्यू
प्रश्न 1: सामान्य एआई मॉडल क्यों खुद-ब-खुद कैप्चा हल नहीं कर सकते?
उत्तर 1: जबकि सामान्य एआई मॉडल शक्तिशाली होते हैं, कैप्चा विशेष रूप से विरोधी और निरंतर बदलते होते हैं। उन्हें विश्वसनीय रूप से और तेजी से हल करने के लिए विशेषज्ञ सुविधा जैसे कैप्सोलर की आवश्यकता होती है जो इस एक ही कार्य पर ध्यान केंद्रित करती है।
प्रश्न 2: कैप्सोलर एजेंट ब्राउजर की कैसे मदद करता है?
उत्तर 2: कैप्सोलर एक "अदृश्य इंजन" के रूप में कार्य करता है जो एक सरल एपीआई के माध्यम से कैप्चा चुनौतियों का समाधान करता है। इससे एजेंट ब्राउजर को सुरक्षा बाधाओं को बिना मानव हस्तक्षेप के सुलझाने में सक्षम बनाता है।
प्रश्न 3: क्या एजेंट ब्राउजर मानव कार्यों को बदल देंगे?
उत्तर 3: वे "कार्यों" को बदल देते हैं, लेकिन "कार्यों" को नहीं। पुनरावर्ती डिजिटल श्रम को हटाकर, वे मानवों को उच्च-स्तरीय रचनात्मकता और रणनीतिक निर्णय लेने पर ध्यान केंद्रित करने की अनुमति देते हैं।
प्रश्न 4: आज एजेंट ब्राउजर का उपयोग कैसे शुरू कर सकते हैं?
उत्तर 4: कई प्रयोगात्मक ब्राउजर और एक्सटेंशन पहले से ही उपलब्ध हैं। हालांकि, सबसे अच्छा अनुभव प्राप्त करने के लिए, सुनिश्चित करें कि आपके पास कैप्चा हल करने वाली विश्वसनीय सेवा जैसे कैप्सोलर के साथ एक विश्वसनीय कैप्चा हल करने वाली सेवा के साथ एकीकृत है।
और देखें
Web ScrapingJul 23, 2026
कैसे स्कीमा रिच परिणामों को मॉनिटर करें: एक ऑटोमेशन मार्गदर्शिका
जेसॉन-एलडी निकास, अर्थपूर्ण आधारभूत मान, सत्यापन, सर्च कॉन्सोल डेटा और उपयोगी चेतावनियों के साथ स्कीमा रिच रिजल्ट मॉनिटरिंग कैसे स्वचालित करें जानें।
Web ScrapingJul 22, 2026
तकनीकी एसईओ रिग्रेशन निगरानी: स्वचालन पाइपलाइन
तकनीकी एसईओ रिग्रेशन निगरानी के साथ संस्करणबद्ध आधाररेखा, अर्थपूर्ण अंतर, सत्यापित चेतावनी और वैकल्पिक अधिकृत CAPTCHA पुनर्प्राप्ति चरण।